Command Palette
Search for a command to run...
인공지능이 118개의 새로운 외계행성을 발견했습니다! 워릭 대학교 연구팀은 각 오탐지 시나리오와 행성 존재 시나리오를 일대일로 비교할 수 있는 RAVEN이라는 도구를 제안했습니다.

천문학 연구의 지속적인 발전과 함께 외계행성 발견은 급속한 발전 단계에 접어들었습니다. 특히 NASA의 외계행성 탐사 위성(TESS) 임무에서 제공되는 광도 곡선 데이터 덕분에 과학자들은 매일 수많은 통과 신호 후보를 얻을 수 있게 되었습니다.
하지만 후보 천체의 행성 특성을 확인하거나 반증하는 것은 길고 어려운 과정입니다. 현재까지 외계행성 아카이브(Exoplanet Archive)에는 7,658개의 TESS(관심 대상 원격 행성체) 목표물(TOI)이 등록되어 있으며, 그중 5,152개는 여전히 후보로 지정되어 있습니다.지금까지 666개만이 진정한 외계행성으로 확인되었으며, 나머지 558개는 TESS에 의해 탐지되었지만 이전에 이미 외계행성으로 확인된 것들입니다.한편, TESS 후보 1,185개가 "위양성(FP)"으로, 97개가 "위경보(FA)"로 분류되었습니다. 이처럼 높은 수치는 외계행성 후보를 확인하는 것이 얼마나 어려운지를 보여줍니다.
후보 행성 선정보다 한 단계 더 나아간 것이 바로 "검증 파이프라인"인데, 이는 통계적 방법을 통해 후보 행성들이 실제 행성인지 확인하는 것을 목표로 합니다.기존의 검증 방법은 주로 수동 분석과 후속 관측(시선 속도(RV) 측정 및 지상 망원경 추적 포함)에 의존합니다.이러한 방법들은 신뢰할 만하지만, 시간이 많이 걸리고 비용이 많이 듭니다.
이에 대한 응답으로, 데이비드 J. 암스트롱 등이 제안한 케플러 과정을 기반으로 워릭 대학교의 연구팀은 다음과 같은 연구를 진행했습니다.TESS 후보 물질에 대한 새로운 선별 및 검증 프로세스인 RAVEN(RAnking and Validation of ExoplaNets)이 더욱 개발되었습니다.새로운 프로세스에서 가장 중요한 변화는 합성 학습 데이터셋의 도입입니다. 이제 더 이상 작업 자체에서 생성된 임계값 초과(TCE) 이벤트 데이터에만 의존하지 않습니다. 이러한 개선을 통해 기계 학습 모델이 다룰 수 있는 행성 및 오탐 시나리오의 매개변수 공간이 크게 확장되고 향상되었습니다.
결과는 다음과 같습니다이 절차는 모든 오탐 시나리오에서 971 TP3T 이상의 AUC 점수를 달성했으며, 한 시나리오에서만 991 TP3T를 초과했습니다.1,361개의 사전 분류된 TESS 후보를 포함하는 독립적인 외부 테스트 세트에서 워크플로는 91%의 전반적인 정확도를 달성하여 TESS 후보를 자동으로 순위 매기는 데 효과적임을 입증했습니다.
연구진은 이 과정을 통해 118개의 새로운 외계행성을 확인했으며, 2,000개 이상의 우수한 행성 후보를 식별했는데, 그중 거의 1,000개는 이전에 발견된 적이 없는 행성이었습니다.
"RAVEN: ExoplaNets의 순위 지정 및 검증"이라는 제목의 관련 연구 결과는 arXiv에 사전 공개 논문으로 게시되었습니다.
연구 하이라이트:
* RAVEN은 합성 데이터 세트를 활용하여 행성 시나리오와 각 오탐 시나리오 간의 일대일 비교를 가능하게 합니다. 이는 이전에는 일반적으로 모델 적합에 의존하는 검증 프레임워크에서만 볼 수 있었던 기능입니다.
새로운 프로세스는 합성 학습 데이터셋을 도입하여 더 이상 작업 자체에서 생성된 TCE 데이터에만 의존하지 않습니다.
새로운 프로세스는 높은 운영 효율성을 유지합니다. 일반적인 후보자를 처리하는 데 약 1분밖에 걸리지 않으며, 다중 프로세스 지원을 통해 확장성도 뛰어납니다.
서류 주소:https://arxiv.org/abs/2509.17645*
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "TESS"라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
데이터셋: 입력 데이터부터 훈련 샘플까지의 전체 구성 경로
입력 데이터: 광도 곡선을 핵심으로 하는 다중 소스 정보 융합.
RAVEN 워크플로는 현재 TESS 과학 처리 운영 센터에서 공개한 TESS 전체 프레임 영상(FFI)에서 생성된 광도 프로파일을 사용합니다. 이러한 광도 프로파일은 조리개 측광법을 이용하여 각 관측 영역의 FFI 데이터에서 추출되며, 1~27번 영역은 30분 간격, 28~55번 영역은 10분 간격으로 샘플링됩니다. TESS 2차 확장 임무(56번 영역부터 시작)에서 공개한 FFI 데이터는 200초 간격의 샘플링 속도를 가지고 있습니다. 본 연구에서 사용된 광도 프로파일은 55번 영역에서 끝납니다.
훈련 데이터: 행성의 체계적인 모델링 및 오탐지
RAVEN 프로세스는 기존에 분류된 후보 광도 곡선 데이터에 의존하는 대신, 머신 러닝 모델 학습을 위해 합성 광도 곡선 데이터를 도입합니다.
초기 합성 이벤트 세트는 모의 통과 또는 식 현상을 사용하여 SPOC 광도 곡선에 통합했습니다. 모의 이벤트는 연구진의 PASTIS 소프트웨어 수정 버전을 사용하여 생성되었으며, 초기에는 통과 행성(Planet), 식쌍성(EB), 층상 식쌍성(HEB), 층상 통과 행성(HTP), 배경 식쌍성(BEB), 배경 통과 행성(BTP) 등의 시나리오를 포함했습니다. 합성 데이터가 실제 TESS 관측 대상 집단과 최대한 유사하도록 각 시나리오의 주성은 특성이 완벽하게 파악된 TESS 입력 카탈로그(TIC) 샘플에서 무작위로 선택되었습니다. 최종적으로 목표 샘플에는 1,200,520개의 SPOC FFI 별이 포함되었습니다.
이를 바탕으로 오탐지 데이터의 구성은 더욱 복잡하고 중요해집니다. 근접 오탐지(NFP)의 경우, 연구자들은 다음과 같은 NFP 시나리오를 고려합니다. 근접 통과 행성(NTP): 행성이 모항성을 통과하여 모항성의 스펙트럼을 희석시키는 경우; 근접 식쌍성(NEB): 근처의 희석 원인이 식쌍성인 경우; 근접 성층 식쌍성(NHEB): 근처의 희석 원인이 성층 식쌍성인 경우.
테스트 데이터: TOI를 중심으로 한 실제 적용 시나리오
이 프로세스의 성능은 기존 사전 분류가 있는 TOI(즉, 관심 있는 TESS 목표물) 세트를 대상으로 최종적으로 테스트되었습니다.테스트에 사용된 TOI 목록 및 분류 정보는 2025년 2월 3일자 NASA 외계행성 아카이브에서 가져왔습니다. 당시 사전 분류된 TOI는 총 2,134개였으며, 그중 548개는 알려진 행성(KP), 485개는 TESS로 확인된 행성(CP), 1,113개는 FP, 96개는 FA로 분류되었습니다. 그러나 SPOC FFI 광도 곡선이 공개된 TOI는 1,918개뿐이었습니다. 최종적으로,나머지 샘플에 깊이 및 주기 제약 조건을 적용한 후 처리해야 할 TOI의 총 개수는 1,589개입니다.
모든 TOI는 전체 파이프라인 처리 단계를 거쳤지만, TIC에서 대상 별이 "중복"으로 표시된 FP TOI 하나는 예외였습니다. 최종 결과에서 68개의 TOI는 대상 별의 TIC에 항성 반지름 정보가 없어서, 87개는 TESS 등급이 13.5를 초과해서, 그리고 22개는 Gaia 등급이 14를 초과해서 제외되었습니다.
본 연구에 사용된 훈련 데이터 세트에는 목표 별의 밝기가 13.5 Tmag 또는 14 Gmag보다 큰 이벤트는 포함되지 않았습니다. 또한, 특징 생성 과정에서 계산된 MES 값이 0.8 미만인 28개의 TOI가 제외되었고, 특징 생성에 실패한 2개의 TOI도 제외되었습니다. 마지막으로, 중심점 데이터로 인해 위치 확률을 생성할 수 없어 사후 확률을 제공할 수 없었던 21개의 TOI는 추가 분석에서 제외되었습니다.
그러므로,이번 테스트에서 사전 분류된 TOI의 최종 수는 1,361개였으며, 그중 705개는 알려진 또는 확인된 행성, 630개는 FP, 26개는 FA였습니다.
두 가지 머신러닝 모델(GBDT+GP)을 결합합니다.
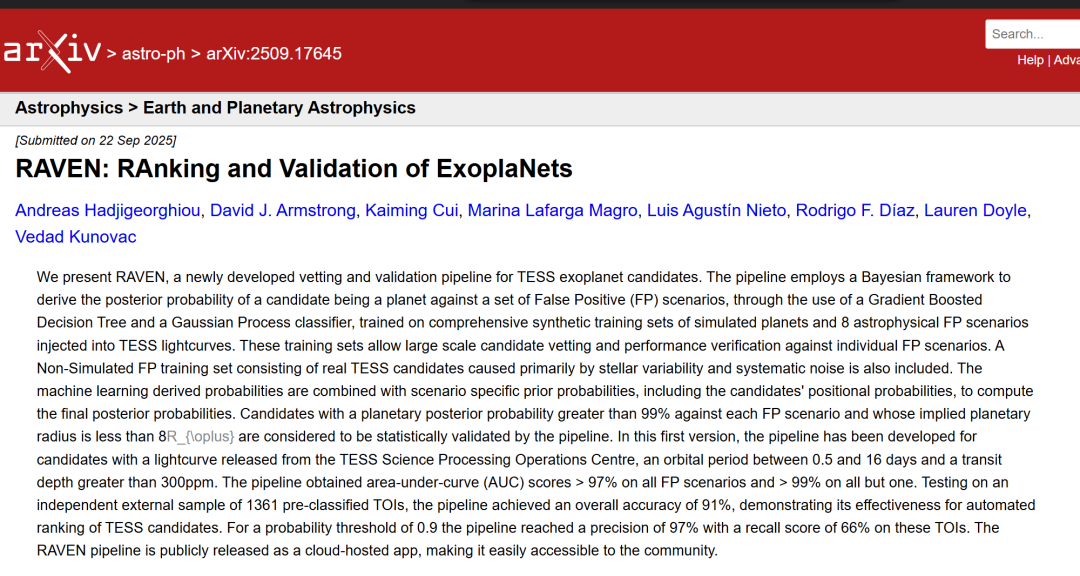
RAVEN 워크플로는 2021년 David J. Armstrong 등이 Kepler 임무 후보를 위해 제안한 통계적 검증 프레임워크(이하 A21)를 기반으로 합니다. 이 프레임워크는 외계행성 탐사 위성(TES) 데이터에 맞게 조정되었으며, 확장 및 업그레이드되었습니다. 전체 워크플로의 구현 및 운영은 여러 단계를 거치는 비교적 복잡한 과정입니다. 간략화된 흐름도는 아래 그림에 나와 있습니다.
머신러닝 훈련
RAVEN은 본질적으로 그래디언트 부스팅 결정 트리(GBDT)와 가우시안 프로세스(GP)라는 두 가지 머신러닝 모델을 결합한 것입니다.이 과정은 각 후보 행성에 대해 8개의 오탐 시나리오에 대한 사후 확률을 생성하고, 최소값을 취하여 후보의 진위성에 대한 가장 낮은 신뢰도를 나타내는 RAVEN 확률을 얻습니다.
① 그래디언트 부스팅 결정 트리(GBDT)
의사결정 트리는 단순하면서도 강력한 머신러닝 모델 유형입니다. 특히 해석력이 뛰어나다는 장점이 있습니다. 그러나 단일 의사결정 트리는 견고성에 한계가 있으며, 트리의 깊이가 너무 깊어지면 과적합되기 쉽습니다. 이러한 문제를 해결하기 위해 여러 개의 "약한" 트리로 구성된 앙상블 기법이 일반적으로 사용됩니다. 그래디언트 부스팅 의사결정 트리(GBDT)는 이러한 앙상블 기법 중 하나로, 여러 개의 의사결정 트리를 순차적으로 구축하여 최종적으로 더 강력한 모델을 만듭니다.
GBDT의 핵심 기능은 다음과 같습니다.새롭게 생성된 각 트리는 원래 레이블을 사용하여 직접 학습하는 것이 아니라, 이전 단계에서 모델 예측으로 인해 발생한 잔여 오류를 통해 학습합니다.즉, 각 새로운 모델의 목표는 전체 모델의 손실 함수를 최소화하는 것이며, 이는 본질적으로 경사 하강법과 유사한 과정입니다. 앙상블 처리 과정에서 각 하위 모델의 출력은 학습률로 스케일링된 후 합산되어 최종 예측값을 얻습니다.
모델 손실은 미리 정의된 손실 함수를 사용하여 계산되며, 잔차는 해당 손실 함수의 기울기를 통해 결정됩니다. 본 연구에서는 Chen과 Guestrin이 제안한 XGBoost를 사용하여 GBDT 분류기를 구현했습니다.
② 가우시안 프로세스 분류기
가우시안 프로세스(GP)는 확률 변수의 분포인 가우시안 확률 분포를 함수의 분포로 일반화한 확률 과정입니다. GP 분류의 목표는 0과 1 사이의 이산적인 클래스 레이블 또는 클래스 확률을 출력하는 것입니다. 이를 위해 GP 출력에 응답 함수를 적용하여 결과를 0에서 1 사이의 구간으로 매핑합니다. 그런 다음 이 응답 함수에 확률 우도 함수(예: 베르누이 우도 함수)를 결합합니다.
본 연구에서는 James Hensman 등이 제안한 변분 근사법을 사용합니다. 이 방법은 데이터의 대표적인 부분집합인 "유도점" 집합을 활용하여 모델의 확장성을 향상시키고 계산 복잡성을 줄입니다.
교육 및 교정
두 분류기를 학습 및 최적화하기 위해 반복적인 접근 방식을 채택했습니다. 다양한 하이퍼파라미터 조합으로 합성 학습 데이터셋을 학습시키고 검증 데이터셋에서 성능을 평가하여 최적의 파라미터를 선택했습니다. 파라미터 튜닝은 주로 가장 흔한 오탐지 사례인 EB, NEB, NSFP의 세 가지 주요 시나리오에 집중했습니다. 동시에 특정 시나리오에 대한 과도한 최적화와 그로 인한 과적합을 방지하기 위해 가능한 한 모든 시나리오에서 파라미터의 일관성을 유지했습니다.
모든 모델에는 "조기 종료" 메커니즘이 활성화되어 있습니다. 검증 세트의 손실 함수가 20회 연속 반복 동안 최소 0.0001 이상 감소하지 않으면 학습이 종료되고 검증 세트에서 손실 함수가 마지막으로 개선된 시점의 모델 상태로 되돌아갑니다.
통계적 검증
이 과정의 마지막 단계는 기계 학습을 통해 도출된 각 행성-FP 범주의 확률과 해당 시나리오별 사전 확률을 결합하여 행성 가설의 사후 확률을 도출하는 것입니다. 이 사후 확률은 후보가 행성이거나 특정 FP 시나리오일 확률만을 나타냅니다. 따라서 연구진의 통계적 검증 방법은 8개의 행성-FP 범주 각각에 대한 후보의 사후 확률이 0.99를 초과해야만 검증된 것으로 간주합니다.
RAVEN은 실제 행성 후보를 선별, 순위 지정 및 검증하는 데 뛰어난 성능을 보여줍니다.
RAVEN의 성능을 평가하기 위해 연구진은 훈련 세트와 테스트 세트 모두에 대해 다음과 같은 검증을 수행했습니다.
연구진은 먼저 훈련 데이터셋에서 무작위로 선택된 101개의 TP3T 이벤트로 구성된, 훈련 전에 독립적으로 분리된 데이터셋의 미사용 하위 집합을 사용하여 모델 성능을 테스트했습니다. 모델 성능은 정확도, ROC 곡선 아래 면적(AUC), 정밀도, 재현율의 네 가지 주요 지표를 사용하여 평가했습니다. 성능 테스트 결과는 아래 표에 나와 있습니다.
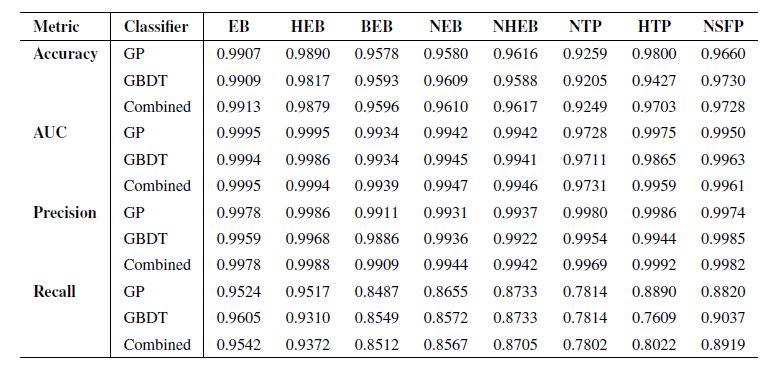
결과는 두 분류기 모두 모든 FP 시나리오에서, 특히 정확도 측면에서 탁월한 성능을 보임을 보여줍니다. RAVEN 파이프라인의 주요 목표는 실제 행성 후보를 선별하고 검증하는 것이므로, 정확도는 파이프라인이 오분류 없이 FP를 정확하게 식별하는 능력을 반영하는 가장 중요한 지표입니다.두 분류기의 결과를 결합하면 모든 시나리오에서 정확도가 거의 99%에 도달합니다.
RAVEN 프로세스의 성능은 사전 분류가 된 TOI 세트를 사용하여 최종적으로 테스트되었습니다. 샘플에 포함된 1,361개 TOI 모두에 대한 RAVEN 확률은 다음 그림에 나와 있습니다.
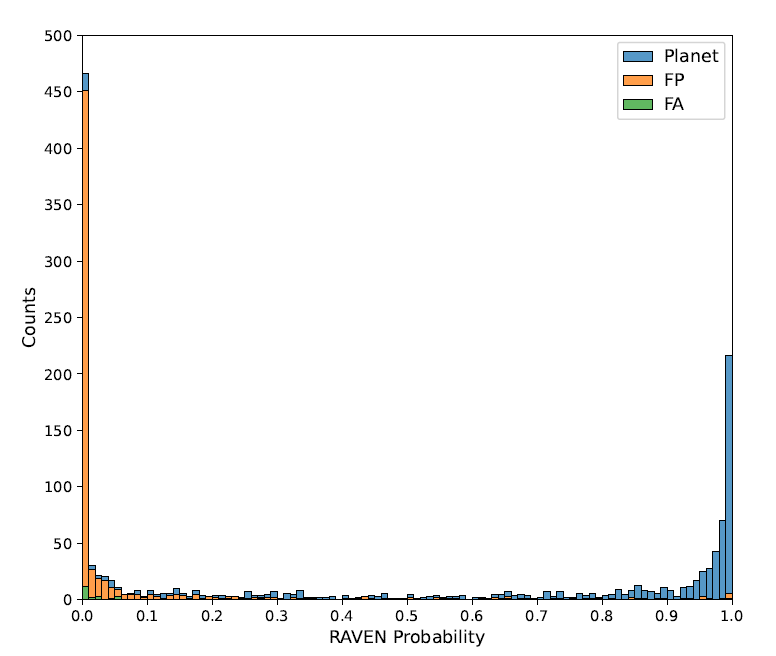
히스토그램은 세 클래스 간의 확률 차이가 유의미하고, 분포가 양호하며, 극단값이 뚜렷하게 나타남을 보여줍니다.이는 RAVEN이 FP 사건을 식별하고 해당 사건에 낮은 행성 사후 확률을 할당하는 데 효과적임을 보여줍니다.구체적으로, 93.8%의 경우 FP 사건의 최소 사후 확률은 0.5 미만이고, 69.7%의 경우 0.01 미만입니다. FP 사건의 평균 확률은 0.076이고, 중앙값은 0.00022입니다.
마찬가지로, 26개의 FA TOI 중 23개는 확률이 0.5 미만이었으며, 전체 범주의 중앙값은 0.016이었습니다. 전반적으로, FP 및 FA TOI에 대한 결과는 TESS 후보를 선별하는 파이프라인의 효율성을 확인시켜주며, 대부분의 FP 이벤트를 제거하는 데 사용할 수 있습니다.
다음으로 연구진은 RAVEN의 오탐(FP) 식별 능력을 검증했으며, 아래 표에는 확률이 0.9보다 큰 12개의 오탐 사례가 추가로 나열되어 있습니다.
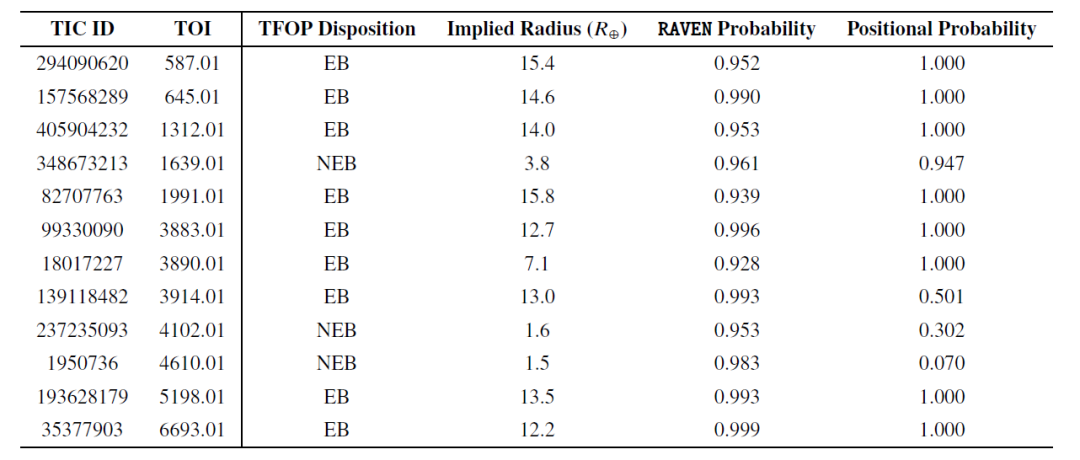
이러한 높은 확률의 오탐지(FP) 사건 중 대부분은 식쌍성(EB)이었으며, 근접 식쌍성(NEB)은 단 세 개뿐이었습니다. NEB가 샘플에서 가장 흔한 FP 유형이었지만, 이는 RAVEN이 NEB를 효과적으로 식별했음을 시사합니다. 실제로 두 개의 NEB 사건(TOI-4102.01 및 TOI-4610.01)에서 RAVEN 절차는 위치 정보 확률이 낮다고 판단하고 후속 관측을 통해 확인된 실제 숙주에 가장 높은 확률을 정확하게 할당했습니다.
또한 TOI-4102.01도 문제가 있는 이벤트로 표시되었습니다. 이 두 TOI는 후보를 평가할 때, 특히 검증 과정에서 RAVEN 프로세스의 전체 출력과 위치 정보 확률을 함께 고려하여 사후 확률이 유효하지 않을 수 있는 상황을 식별해야 함을 나타냅니다.
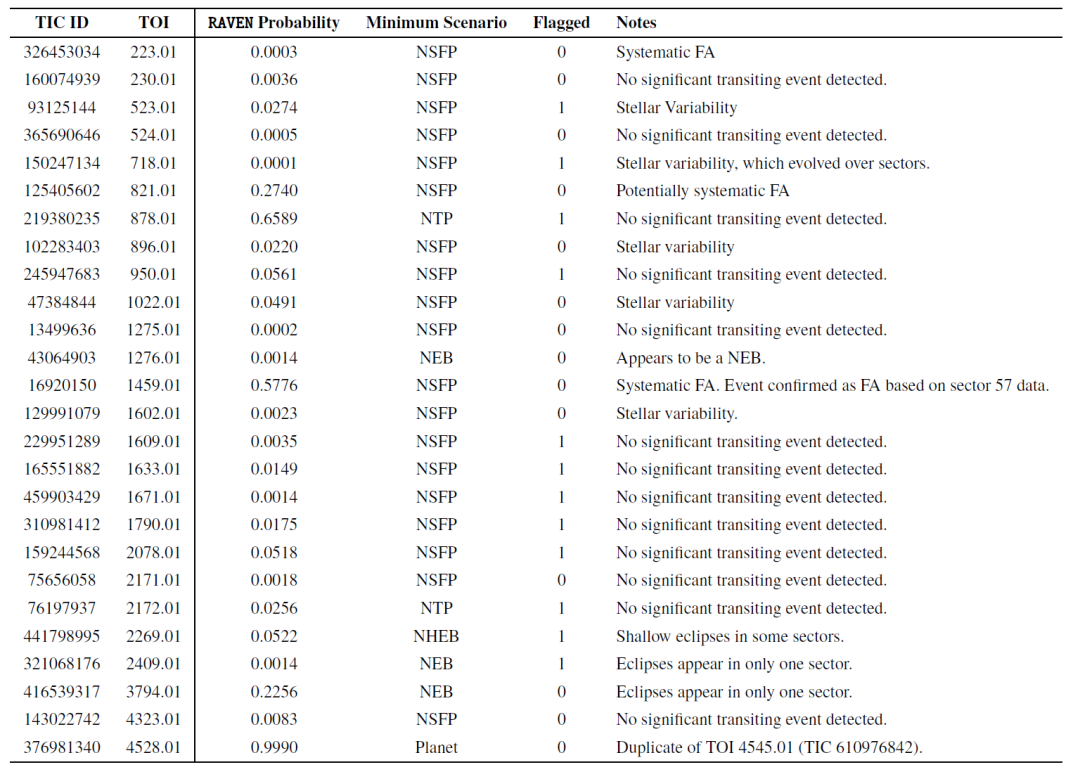
연구진은 또한 오경보(FA) TOI에 대한 RAVEN 프로세스의 성능을 평가했습니다. 아래 표는 샘플에서 26개의 FA TOI에 대한 가장 낮은 사후 확률과 해당 오탐 시나리오를 보여줍니다. 거의 모든 FA TOI의 확률이 행성 시나리오와 일치하지 않아 RAVEN이 이를 효과적으로 식별했음을 입증합니다.
최종적으로, 초기 TOI 샘플을 검토한 후 연구진은 알려진 행성 397개와 확인된 행성 308개를 포함하여 총 705개의 행성을 선정했습니다. 그 결과는 다음과 같습니다...대부분의 행성 TOI는 높은 사후 행성 확률을 가지며, 81%는 0.5 임계값을 초과합니다.
특히, 420개의 행성은 확률이 0.9를 초과하여 "행성일 가능성이 높음" 범위에 속합니다. 또한, 210개의 행성은 TOI가 통계적 유효성 검증 기준인 0.99를 초과하며, 이는 전체 행성 표본 중 약 30%에 해당합니다.이러한 결과는 RAVEN이 실제 행성 후보를 선별, 순위 지정 및 검증하는 데 있어 우수한 성능을 보인다는 것을 입증합니다.
인공지능은 점차 천문학 연구를 위한 중요한 기반 시설로 자리 잡고 있습니다.
기술 발전이라는 더 넓은 관점에서 볼 때, 인공지능은 천문학 연구에 필수적인 인프라로 점차 자리매김하고 있습니다. 그 중요성은 단순히 "데이터 처리 효율 향상"을 넘어 과학적 발견의 전반적인 패러다임을 재편하기 시작했습니다. 오랫동안 천문학은 물리적 모델과 인공적인 규칙에 기반한 분석 방법에 의존해 왔습니다. 그러나 관측 능력의 향상과 함께 데이터의 규모와 복잡성은 지속적으로 증가해 왔습니다. 광도 곡선에서 고해상도 이미지, 다차원 스펙트럼, 그리고 항성 목록 정보에 이르기까지, 전통적인 방법은 고차원적이고 비선형적이며 잡음이 심한 데이터를 처리하는 데 점차 한계에 다다르고 있습니다. 이러한 배경에서,머신러닝과 딥러닝을 핵심으로 하는 AI 기술은 "방대한 관측 데이터"와 "효과적인 과학적 이해"를 연결하는 중요한 가교 역할을 하고 있습니다.
관측 방법의 발전으로 천문 데이터는 더 이상 단일 양식에 국한되지 않습니다. 이미지, 스펙트럼, 시계열 광도 곡선, 항성 목록 매개변수 등 다양한 데이터 소스가 공존하며, 기존의 딥러닝 모델은 이러한 상황에서 새로운 한계를 드러내기 시작했습니다. 실제로 여러 양식을 통합한 천문 모델을 구축하려는 연구가 진행되었지만, 이러한 시도들은 여전히 상당한 한계를 가지고 있습니다.대부분의 연구는 초신성 폭발과 같은 단일 현상에 초점을 맞추고 "대조적 목표"를 핵심 기술로 사용합니다. 이로 인해 모델이 임의의 모달 조합에 유연하게 대처하고 표면적인 상관관계 이상의 핵심적인 과학적 정보를 모달 간에 포착하기 어렵습니다.
이러한 병목 현상을 극복하기 위해,캘리포니아 대학교 버클리, 케임브리지 대학교, 옥스퍼드 대학교를 비롯한 전 세계 10개 이상의 연구 기관 팀이 협력하여 천문학 분야 최초의 대규모 다중 모드 기본 모델 제품군인 AION-1(Astronomical Omni-modal Network)을 출시했습니다.이미지, 스펙트럼, 별 목록 데이터와 같은 이질적인 관측 정보를 통합된 초기 융합 백본 네트워크를 통해 통합하고 모델링함으로써, 이 시스템은 제로샷 시나리오에서 뛰어난 성능을 보일 뿐만 아니라, 선형 탐지 정확도 또한 특정 작업을 위해 특별히 훈련된 모델과 유사한 수준입니다.
논문 제목: AION-1: 천문 과학을 위한 옴니모달 기초 모델
서류 주소:https://openreview.net/forum?id=6gJ2ZykQ5W
한편, 구체적인 과학적 질문 차원에서도 AI는 전통적인 관측 방법의 한계를 뛰어넘고 있습니다. 예를 들어, 현대 천문학에서 강력한 중력 렌즈는 우주의 거대 구조와 블랙홀과 은하의 공진화를 연구하는 데 중요한 도구입니다. 강력한 중력 렌즈 역할을 하는 퀘이사는 초거대 블랙홀과 그 숙주 은하 사이의 스케일링 관계(특히 MBH-숙주 은하 관계)의 진화를 적색편이에 따라 연구할 수 있는 매우 드문 관측 기회를 제공합니다.
그러나 퀘이사는 극히 드물며, 이를 식별하는 것은 천문학자들에게 항상 큰 과제였습니다. 슬론 디지털 스카이 서베이(SDSS)에 등록된 약 30만 개의 퀘이사 중에서 겨우 12개의 후보만 발견되었고, 최종적으로 확인된 것은 단 3개뿐입니다.이러한 배경에서 스탠포드 대학교, SLAC 국립 가속기 연구소, 베이징 대학교, 이탈리아 국립 천체물리학 연구소의 브레라 천문대, 유니버시티 칼리지 런던, 캘리포니아 대학교 버클리 등 여러 연구 기관으로 구성된 연구팀은 DESI DR1의 스펙트럼 데이터에서 강력한 중력 렌즈 역할을 하는 퀘이사를 식별하기 위한 데이터 기반 워크플로우를 개발했습니다. 이 워크플로우를 사용하여 연구진은 7개의 고품질(A급) 퀘이사 렌즈 후보를 식별했습니다.
논문 제목: DESI DR1에서 발견된 강력한 렌즈 역할을 하는 퀘이사
서류 주소:https://arxiv.org/abs/2511.02009
향후 대규모 천체 관측과 같은 미래 관측 임무의 발전과 함께 천문학은 데이터 폭발 시대로 접어들 것이며, 이에 따라 인공지능(AI)의 역할도 더욱 심화될 것으로 예상됩니다. 분석 지원부터 발견을 주도하는 역할까지, 단일 작업 모델부터 일반적인 기초 모델에 이르기까지, AI는 우주에 대한 우리의 이해를 재정립하고 있습니다. AI는 단순히 "우리가 보는 방식"뿐만 아니라 "우리가 발견할 수 있는 것"까지도 변화시키고 있습니다.
참고문헌:
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W








