Command Palette
Search for a command to run...
LightOnOCR-2-1B: RLVR 학습 기반의 고정밀 엔드투엔드 OCR; Google Streetview National Street View Images: 세계적 수준의 지리 매핑 기술을 기반으로 하는 오픈 소스 파노라마 이미지 라이브러리.

현재 OCR 기술은 복잡한 순차적 파이프라인에 의존합니다. 먼저 텍스트 영역을 감지하고, 그 다음 인식 작업을 수행한 후, 마지막으로 후처리 작업을 진행합니다.이 모델은 복잡한 레이아웃과 다양한 형식을 가진 문서를 처리할 때 다루기 어렵고 불안정합니다. 어느 단계에서든 오류가 발생하면 전체적인 결과가 저하될 수 있으며, 엔드 투 엔드 최적화가 어려워 유지 관리 및 수정 비용이 많이 듭니다.
이러한 맥락에서,LightOn은 LightOnOCR-2-1B 모델을 오픈 소스로 공개했습니다.단 10억 개의 파라미터만으로 구현된 이 엔드투엔드 비전-언어 모델은 권위 있는 벤치마크인 OlmOCR-Bench에서 새로운 최고 성능(SOTA)을 달성했습니다. 기존 최고 모델(90억 개의 파라미터 사용)을 능가하는 성능을 보여주면서도 모델 크기는 9배, 추론 속도는 수 배 향상시켰습니다. LightOnOCR-2-1B는 통합 모델을 사용하여 픽셀로부터 구조화되고 정렬된 텍스트와 이미지 경계 상자를 직접 생성합니다. 사전 학습된 구성 요소, 고품질 정제 데이터, 그리고 RLVR과 같은 전략을 통합함으로써 복잡한 문서 처리 과정을 간소화하고 효율성을 크게 향상시켰습니다.
HyperAI 웹사이트에서 "LightOnOCR-2-1B 경량 고성능 엔드투엔드 OCR 모델"을 사용해 보세요!
온라인 사용:https://go.hyper.ai/8zlVw
2월 2일부터 2월 6일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 6개
* 엄선된 고품질 튜토리얼: 9개
* 이번 주 추천 논문: 5편
* 커뮤니티 기사 해석 : 4개 기사
* 인기 백과사전 항목: 5개
2월 마감인 주요 학술대회: 4개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. RubricHub 다중 도메인 생성 작업 데이터 세트
RubricHub는 Li Auto와 저장대학교가 공동으로 공개한 대규모 다중 도메인 생성 작업 데이터셋입니다. 이 데이터셋은 개방형 생성 작업에 대한 채점 기준 기반의 고품질 지도 학습 자료를 제공합니다. 데이터셋은 원리 기반 합성, 다중 모델 통합, 난이도 진화 등의 전략을 통합한 자동화된 세분화된 채점 기준 생성 프레임워크를 사용하여 구축되었으며, 이를 통해 포괄적이고 판별력이 뛰어난 평가 기준을 생성합니다.
직접 사용:https://go.hyper.ai/g3Htm
2. 네모트론-페르소나스-브라질 브라질 합성 캐릭터 데이터셋
Nemotron-Personas-Brazil은 NVIDIA가 WideLabs와 협력하여 공개한 브라질 인구를 위한 합성 캐릭터 데이터셋입니다. 이 데이터셋은 브라질 인구의 다양성과 풍부함을 보여줌으로써 지역적 다양성, 민족적 배경, 교육 수준, 직업 분포 등 다차원적인 잠재적 인구 분포를 보다 포괄적으로 반영하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/7xKKH
3. CL-bench 컨텍스트 학습 평가 벤치마크
CL-bench는 대규모 언어 모델의 문맥 학습 능력을 평가하기 위한 벤치마크 데이터셋으로, 텐센트 훈위안 팀과 푸단 대학교가 공동으로 개발 및 출시했습니다. 이 데이터셋은 모델이 사전 학습된 지식에 의존하지 않고 주어진 문맥으로부터 새로운 규칙, 개념 또는 도메인 지식을 학습하고 이를 후속 작업에 적용할 수 있는지 여부를 테스트하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/w2MG3
4. RoVid-X 로봇 비디오 생성 데이터세트
RoVid-X는 베이징 대학이 ByteDance Seed와 협력하여 공개한 로봇 비디오 생성 데이터셋으로, 로봇 비디오 생성 시 비디오 생성 모델이 직면하는 물리적 문제를 해결하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/4P9hI
5. 구글 스트리트뷰 전국 스트리트뷰 이미지 데이터셋
구글 스트리트뷰는 여러 국가의 거리 풍경 이미지를 모아놓은 데이터셋입니다. 이미지 파일 이름에는 생성 날짜와 지도 이름이 포함되어 있으며, 각 국가별 이미지는 해당 국가의 폴더에 저장되어 있습니다.
직접 사용:https://go.hyper.ai/tZRlI

6. DeepPlanning 장기 계획 수립 역량 평가 데이터 세트
DeepPlanning은 Qwen 팀에서 공개한 데이터셋으로, 지능형 에이전트의 계획 수립 능력을 평가하고 복잡하고 장기적인 계획 작업에서 추론 및 의사 결정 능력을 측정하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/yywsb
선택된 공개 튜토리얼
1. vLLM-Omni를 사용하여 Qwen-Image-Edit 배포
Qwen-Image-Edit는 알리바바의 통이첸원(Tongyi Qianwen) 팀에서 출시한 다기능 이미지 편집 플랫폼입니다. 이 플랫폼은 의미 편집과 시각 편집 기능을 모두 갖추고 있어 요소 추가, 삭제, 수정과 같은 저수준 시각 편집은 물론, 지적 재산권 생성, 객체 회전, 스타일 변경과 같은 고수준 시각 의미 편집도 가능합니다. 중국어와 영어 텍스트 모두 정밀하게 편집할 수 있으며, 원본 글꼴, 크기, 스타일을 유지하면서 이미지 내 텍스트 내용을 직접 수정할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/DowYs
2. vLLM-Omni를 사용하여 Qwen-Image-2512를 배포합니다.
Qwen-Image-2512는 Qwen-Image 시리즈의 기본이 되는 텍스트-이미지 변환 모델입니다. 이전 버전과 비교하여 Qwen-Image-2512는 생성된 이미지의 전반적인 사실감과 사용성을 향상시키는 데 중점을 두고 여러 핵심 측면에서 체계적인 최적화를 거쳤습니다. 인물 이미지 생성의 자연스러움이 크게 향상되어 얼굴 구조, 피부 질감, 조명 관계가 실제 사진 효과에 더욱 가까워졌습니다. 자연 장면에서는 지형 질감, 식물 세부 묘사, 동물의 털과 같은 고주파 정보까지 더욱 세밀하게 생성할 수 있습니다. 동시에 텍스트 생성 및 타이포그래피 기능도 개선되어 가독성이 뛰어난 텍스트와 복잡한 레이아웃을 더욱 안정적으로 표현할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/Xk93p
3. Step3-VL-10B: 멀티모달 시각적 이해 및 그래픽 대화
STEP3-VL-10B는 Stepping Star 팀에서 개발한 오픈 소스 시각 언어 모델로, 특히 멀티모달 이해 및 복잡한 추론 작업을 위해 설계되었습니다. 이 모델은 100억(10B)이라는 제한된 파라미터 규모 내에서 효율성, 추론 능력, 시각적 이해 품질 간의 균형을 재정의하는 것을 목표로 합니다. STEP3-VL-10B는 시각 인식, 복잡한 추론, 인간 지시 정렬 분야에서 뛰어난 성능을 보여주며, 여러 벤치마크 테스트에서 유사한 규모의 모델들을 일관되게 능가하고, 일부 작업에서는 파라미터 규모가 10~20배 더 큰 모델들과도 동등한 수준의 성능을 보입니다.
온라인으로 실행:https://go.hyper.ai/ZvOV0
4.GLM-4.7-Flash의 vLLM+Open WebUI 배포
GLM-4.7-Flash는 Zhipu AI에서 출시한 경량 MoE 추론 모델로, 고성능과 높은 처리량의 균형을 이루도록 설계되었습니다. 사고 연쇄, 도구 호출 및 에이전트 기능을 기본적으로 지원하며, 하이브리드 전문가 아키텍처와 희소 활성화 메커니즘을 채택하여 대규모 모델의 성능을 유지하면서 단일 추론의 계산 오버헤드를 크게 줄였습니다.
온라인으로 실행:https://go.hyper.ai/bIopo

5. LightOnOCR-2-1B 경량 고성능 엔드투엔드 OCR 모델
LightOnOCR-2-1B는 LightOn AI에서 출시한 최신 세대 엔드투엔드 시각 언어 인식(OCR) 모델입니다. LightOnOCR 시리즈의 플래그십 버전인 이 모델은 문서 이해와 텍스트 생성을 하나의 컴팩트한 아키텍처로 통합했으며, 10억 개의 파라미터를 지원하고 일반 소비자용 GPU(약 6GB의 VRAM 필요)에서도 실행 가능합니다. 시각 언어 Transformer 아키텍처와 RLVR 학습 기술을 적용하여 매우 높은 인식 정확도와 추론 속도를 자랑합니다. 특히 복잡한 문서, 손글씨, LaTeX 수식 처리가 필요한 애플리케이션에 최적화되어 있습니다.
온라인으로 실행:https://go.hyper.ai/8zlVw
6. LFM2.5-1.2B의 vLLM+Open WebUI 배포 - 사고방식
LFM2.5-1.2B-Thinking은 Liquid AI에서 출시한 최신 엣지 최적화 하이브리드 아키텍처 모델입니다. LFM2.5 시리즈의 논리 추론에 특화된 버전으로, 긴 시퀀스 처리와 효율적인 추론 기능을 컴팩트한 아키텍처에 통합했습니다. 12억 개의 파라미터를 가진 이 모델은 일반 소비자용 GPU는 물론 엣지 디바이스에서도 원활하게 실행될 수 있습니다. 혁신적인 하이브리드 아키텍처를 채택하여 뛰어난 메모리 효율성과 처리량을 달성했으며, 인텔리전스 손실 없이 디바이스 내에서 실시간 추론이 필요한 시나리오에 최적화되어 있습니다.
온라인으로 실행:https://go.hyper.ai/PACIr
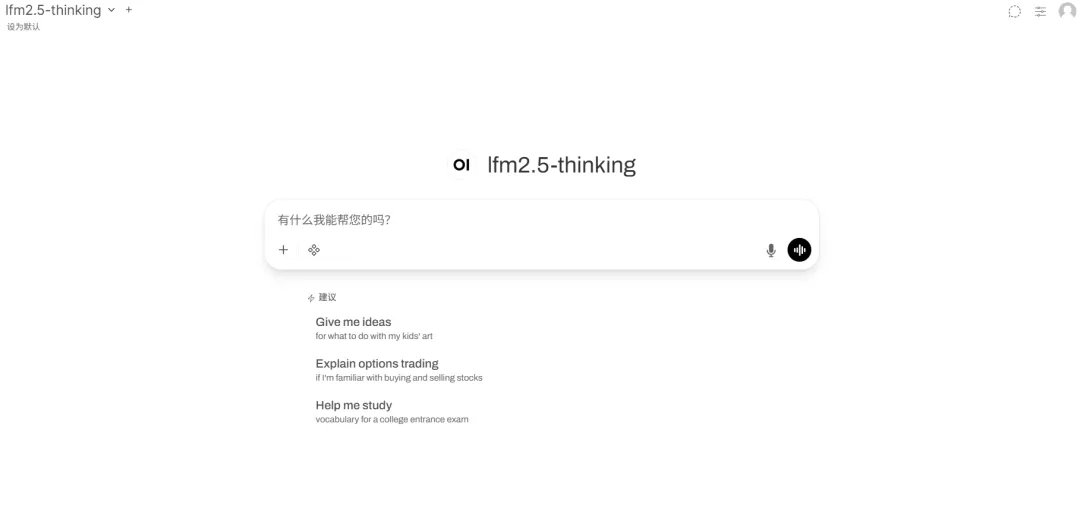
7. TurboDiffusion: 이미지 및 텍스트 기반 비디오 생성 시스템
TurboDiffusion은 칭화대학교 연구팀이 개발한 고효율 비디오 확산 생성 시스템입니다. 2.1 아키텍처를 기반으로 하는 이 프로젝트는 고차 증류 기법을 활용하여 대규모 비디오 모델에서 발생하는 느린 추론 속도와 높은 연산 자원 소모 문제를 해결하고, 최소한의 단계로 고품질 비디오를 생성합니다.
온라인으로 실행:https://go.hyper.ai/YjCht
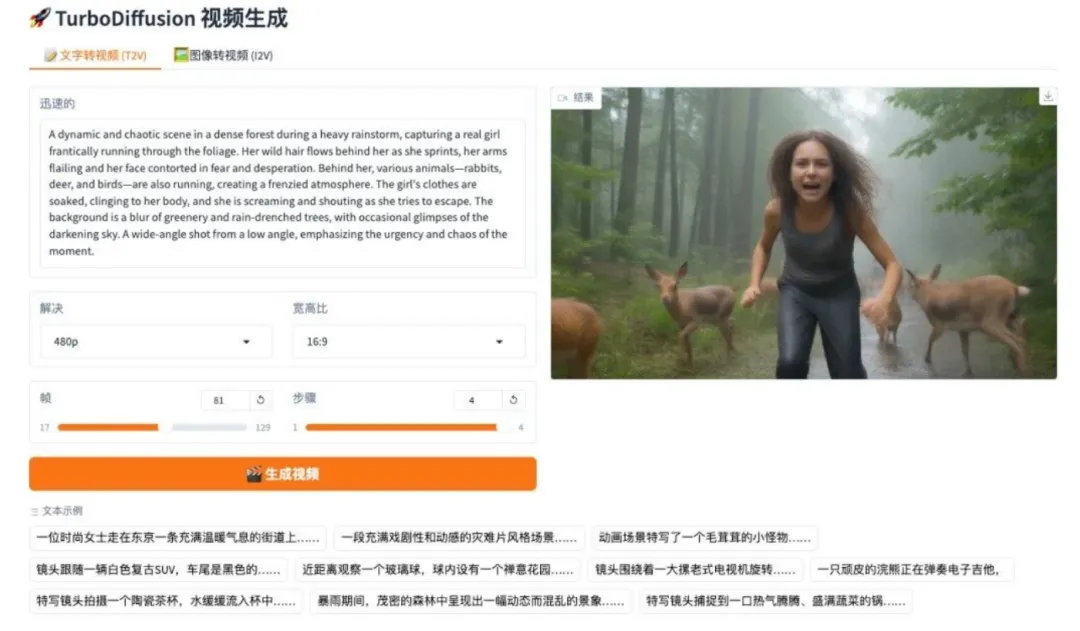
8. DeepSeek-OCR 2 시각적 인과 흐름
DeepSeek-OCR 2는 DeepSeek 팀에서 출시한 2세대 OCR 모델입니다. DeepEncoder V2 아키텍처를 도입하여 고정 스캔 방식에서 의미론적 추론 방식으로 패러다임을 전환했습니다. 이 모델은 인과 스트림 쿼리와 이중 스트림 어텐션 메커니즘을 활용하여 시각적 토큰을 동적으로 재배열함으로써 복잡한 문서의 자연스러운 읽기 논리를 더욱 정확하게 재구성합니다. OmniDocBench v1.5 평가에서 91.09%의 종합 점수를 달성하여 이전 모델 대비 크게 향상되었으며, OCR 결과의 중복률을 대폭 줄여 향후 완전 모달 인코더 구축을 위한 새로운 방향을 제시합니다.
온라인으로 실행:https://go.hyper.ai/ITInm
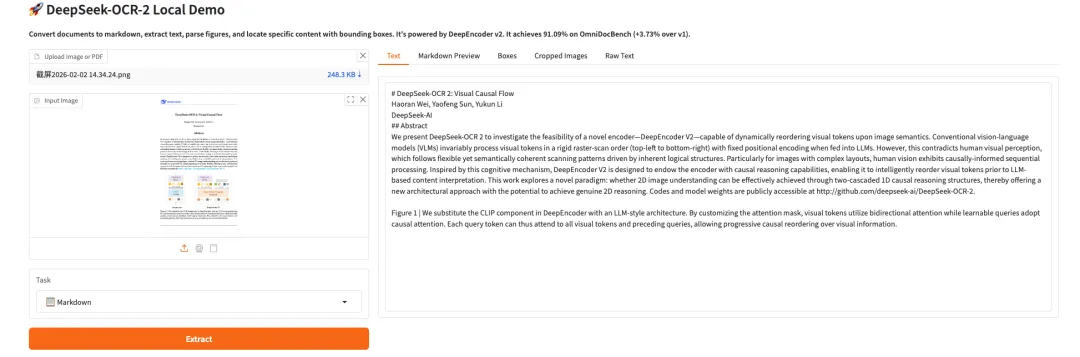
9. 페르소나플렉스-7B-v1: 실시간 대화 및 캐릭터 맞춤형 음성 인터페이스
PersonaPlex-7B-v1은 NVIDIA에서 출시한 70억 개 파라미터를 가진 멀티모달 개인 맞춤형 대화 모델입니다. 실시간 음성/텍스트 상호작용, 장기적인 페르소나 일관성 시뮬레이션, 멀티모달 인식 작업을 위해 설계되었으며, 밀리초 수준의 응답 속도로 몰입형 역할극 및 멀티모달 상호작용 시연 시스템을 제공하는 것을 목표로 합니다.
온라인으로 실행:https://go.hyper.ai/ndoj0
이번 주 논문 추천
1. 추론을 위한 협업 다중 에이전트 테스트 시간 강화 학습
본 논문에서는 구조화된 텍스트 경험을 추론 과정에 접목하여 다중 에이전트 추론 성능을 향상시키는 테스트 시간 강화 학습 프레임워크인 MATTRL을 제안합니다. MATTRL은 다중 전문가 팀 협업과 라운드별 점수 배분을 통해 합의를 도출하며, 재학습 없이 의료, 수학, 교육 분야의 벤치마크 데이터셋에서 강력한 성능 향상을 보여줍니다.
논문 링크:https://go.hyper.ai/ENmkT
2. A^3-Bench: 앵커 및 어트랙터 활성화를 통한 메모리 기반 과학적 추론 벤치마킹
본 논문에서는 메모리 기반의 이중 스케일 과학적 추론 벤치마크인 A³-Bench를 제안합니다. A³-Bench는 SAPM 주석 프레임워크와 AAUI 지표를 사용하여 앵커와 어트랙터의 활성화를 평가하고, 메모리 활용이 표준적인 일관성이나 답변 정확도를 넘어 추론의 일관성을 어떻게 향상시킬 수 있는지를 밝힙니다.
논문 링크:https://go.hyper.ai/Ao5t9
3. PaCoRe: 병렬 조정 추론을 통한 테스트 시간 컴퓨팅 확장 학습
본 논문에서는 병렬 추론 궤적 간의 메시지 전달을 통해 테스트 시간 계산(TTC)의 대규모 확장을 달성하는 병렬 협업 추론 프레임워크인 PaCoRe를 제안합니다. PaCoRe는 HMMT 2025 데이터셋에서 GPT-5(93.2%)를 능가하는 94.5%의 정확도를 보여줍니다. 또한, 고정된 컨텍스트 제약 조건 내에서 수백만 개의 토큰에 대한 추론 프로세스를 효율적으로 통합하며, 모델과 데이터를 오픈소스로 공개하여 확장 가능한 추론 시스템 개발을 촉진합니다.
논문 링크:https://go.hyper.ai/fQrnt
4. 비디오 생성을 위한 모션 속성 부여
본 논문에서는 모션 가중 손실 마스크를 통해 시간적 역동성과 정적 외관을 분리하는 모션 중심의 그래디언트 기반 데이터 속성 판별 프레임워크인 Motive를 제안합니다. 이를 통해 미세 조정에 영향을 미치는 세그먼트를 확장 가능하게 인식하여 텍스트-비디오 생성에서 모션의 부드러움과 물리적 타당성을 향상시킬 수 있습니다. Motive는 VPench 데이터셋에서 74.11 TP3T의 인간 선호도 승률을 달성했습니다.
논문 링크:https://go.hyper.ai/2pU21
5. VIBE: 시각적 지침 기반 편집기
본 논문에서는 20억 개의 파라미터를 가진 Qwen3-VL 모델을 가이드로, 16억 개의 파라미터를 가진 Sana1.5 확산 모델을 이미지 생성에 사용하는 간결한 명령어 기반 이미지 편집 워크플로우인 VIBE를 제안합니다. VIBE는 원본 이미지의 일관성을 엄격하게 유지하면서도 매우 낮은 계산 비용으로 고품질 편집을 구현합니다. 24GB의 GPU 메모리에서 효율적으로 실행되며, H100에서 2K 이미지를 약 4초 만에 생성하여 더 큰 규모의 기준 모델과 동등하거나 그 이상의 성능을 달성합니다.
논문 링크:https://go.hyper.ai/8YMEO
커뮤니티 기사 해석
1. 유럽 우주국은 허블 우주 망원경에서 3일 만에 1억 개의 데이터 포인트를 분석한 후, 1,000개 이상의 이상 천체를 발견하는 AnomalyMatch 프로젝트를 제안했습니다.
현재, 다중 대역, 넓은 시야각, 높은 심도를 특징으로 하는 대규모 천체 관측 조사는 천문학을 전례 없는 데이터 집약적 시대로 이끌고 있습니다. 이러한 관측 조사의 핵심적인 과학적 잠재력 중 하나는 특별한 천체물리학적 가치를 지닌 희귀 천체를 체계적으로 발견하고 식별하는 데 있습니다. 그러나 이러한 천체의 발견은 오랫동안 연구자들의 우연한 시각적 식별이나 시민 과학 프로젝트를 통한 수동 검토에 크게 의존해 왔습니다. 이러한 방법은 매우 주관적이고 비효율적일 뿐만 아니라, 앞으로 등장할 방대한 규모의 데이터에는 적합하지 않습니다. 이러한 한계를 극복하기 위해 유럽 우주국(ESA) 산하 유럽 우주 천문 센터(ESAC)의 연구팀은 AnomalyMatch라는 새로운 방법을 제안하고 적용했습니다.
전체 보고서 보기:https://go.hyper.ai/Jm3aq
2. 데이터셋 요약 | 파악, 질문 답변, 논리적 추론, 궤적 추론 및 기타 분야를 포괄하는 16개의 체화된 지능 데이터셋.
지난 10년간 인공지능의 주요 경쟁 분야가 "세상을 이해하는 것"과 "콘텐츠를 생성하는 것"이었다면, 다음 단계의 핵심 과제는 더욱 어려운 문제로 옮겨가고 있습니다. 바로 인공지능이 어떻게 물리적 세계에 진정으로 진입하여 그 안에서 행동하고, 학습하고, 진화할 수 있을까 하는 것입니다. 관련 연구 및 논의에서 "체화된 지능(embodied intelligence)"이라는 용어가 자주 등장합니다. 이름에서 알 수 있듯이, 체화된 지능은 전통적인 로봇이 아니라, 인지, 의사 결정, 행동의 폐쇄 루프 내에서 에이전트와 환경 간의 상호작용을 통해 형성되는 지능을 강조합니다. 이 글에서는 체화된 지능과 관련된 현재까지 이용 가능한 고품질 데이터셋들을 체계적으로 정리하고 추천하여, 향후 학습 및 연구를 위한 참고자료를 제공하고자 합니다.
전체 보고서 보기:https://go.hyper.ai/lsCyF
3. 온라인 튜토리얼 | DeepSeek-OCR 2 수식/표 구문 분석 개선으로 시각적 토큰 비용을 낮추면서 약 4%의 성능 향상 달성
시각 언어 모델(VLM) 개발에 있어 문서 OCR은 복잡한 레이아웃 분석 및 의미 논리 정렬과 같은 핵심적인 과제에 항상 직면해 왔습니다. 모델이 인간처럼 시각적 논리를 "이해"할 수 있도록 하는 것이 문서 이해 능력 향상의 핵심적인 돌파구였습니다. 최근 DeepSeek-AI의 DeepSeek-OCR 2가 새로운 해답을 제시합니다. 이 모델의 핵심은 새로운 DeepEncoder V2 아키텍처의 채택입니다. 기존의 CLIP 시각 인코더를 버리고 LLM 방식의 시각 인코딩 패러다임을 도입했습니다. 양방향 어텐션과 인과적 어텐션을 융합하여 의미 기반의 시각 토큰 재배열을 구현하고, 2D 이미지 이해를 위한 새로운 "2단계 1D 인과 추론" 경로를 구축했습니다.
전체 보고서 보기:https://go.hyper.ai/nMH13
4. 천체 물리학, 지구 과학, 유변학 및 음향학을 포함한 19가지 시나리오를 다루는 Polymathic AI는 정확한 연속 매체 시뮬레이션을 구현하기 위해 13억 개의 모델을 구축합니다.
과학 컴퓨팅 및 엔지니어링 시뮬레이션 분야에서 복잡한 물리 시스템의 진화를 효율적이고 정확하게 예측하는 것은 학계와 산업계 모두에게 항상 핵심적인 과제였습니다. 한편, 자연어 처리 및 컴퓨터 비전 분야에서 딥러닝 기술의 발전은 연구자들이 물리 시뮬레이션에서 "기초 모델"의 잠재적 응용 가능성을 탐구하도록 자극했습니다. 그러나 물리 시스템은 종종 여러 시간 및 공간 스케일에 걸쳐 진화하는 반면, 대부분의 학습 모델은 일반적으로 단기적인 동역학에만 맞춰 훈련됩니다. 이러한 모델을 장기 예측에 사용하면 복잡한 시스템에서 오류가 누적되어 모델 불안정성을 초래합니다. 이러한 문제점을 해결하기 위해 Polymathic AI Collaboration의 연구팀은 13억 개의 매개변수를 가진 Transformer 기반 아키텍처의 기초 모델인 Walrus를 제안했으며, 이 모델은 유체와 같은 연속체 동역학을 위해 설계되었습니다.
전체 보고서 보기:https://go.hyper.ai/MJrny
인기 백과사전 기사
1. 역방향 정렬과 RRF의 결합
2. 콜모고로프-아놀드 표현 정리
3. 대규모 다중 작업 언어 이해(MMLU)
4. 블랙박스 최적화 도구
5. 클래스 조건부 확률
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.

최고 AI 학술 컨퍼런스에 대한 원스톱 추적:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!