Command Palette
Search for a command to run...
AI 논문 주간 보고서 | 최첨단 OCR 기술 해석: DeepSeek, Tencent, Baidu, 문자 인식부터 구조화된 문서 분석까지 동일 무대에서 경쟁

지난 몇 년 동안 OCR(광학 문자 인식)은 단순한 "문자 인식 도구"에서 빠르게 발전해 왔습니다.비전-언어 모델 기반의 범용 문서 이해 시스템마이크로소프트와 구글 같은 글로벌 기업들이 지속적으로 투자하는 가운데, 바이두, 텐센트, 알리바바 클라우드와 같은 중국 유력 업체들도 집중적인 구축에 나서면서 시장은 규칙 기반 OCR에서 인공지능과 자연어 처리를 통합한 지능형 문서 처리(IDP)로 빠르게 발전하고 있으며, 금융, 정부 업무, 의료 등 실제 비즈니스 시나리오에서 그 활용도가 지속적으로 확대되고 있습니다.
지속적인 산업 수요에 힘입어 OCR 연구의 초점도 크게 바뀌었습니다.이 모델은 더 이상 "인식 정확도"만을 추구하는 것이 아니라, 복잡한 레이아웃, 다중 모달 기호, 긴 문맥 모델링, 엔드 투 엔드 의미 이해와 같은 더욱 어려운 문제들을 체계적으로 해결하기 시작했습니다.2차원 시각 정보를 효율적으로 인코딩하는 방법, 텍스트 정보를 더욱 효율적으로 분석하는 방법, 그리고 모델의 읽기 순서를 인간의 인지 논리에 더 가깝게 만드는 방법은 학계와 산업계 모두의 공통적인 관심사로 떠오르고 있습니다.
이처럼 활발한 상호작용이 이루어지는 상황에서 최신 OCR 관련 학술 논문을 지속적으로 추적하고 분석하는 것은 기술의 최첨단 방향을 파악하고, 업계의 실제 과제를 이해하며, 나아가 차세대 패러다임 혁신을 이끌어내는 데 특히 중요합니다.
이번 주에는 OCR 관련 인기 AI 논문 5편을 추천합니다.딥시크, 텐센트, 칭화대학교 등 여러 팀이 참여합니다. 함께 배워봐요! ⬇️
또한, 더 많은 사용자가 학계의 인공지능 분야 최신 동향을 이해할 수 있도록 HyperAI 웹사이트(hyper.ai)는 최첨단 AI 연구 논문으로 매일 업데이트되는 "최신 논문" 섹션을 개설했습니다.
최신 AI 논문:https://go.hyper.ai/hzChC
이번 주 논문 추천
- DeepSeek-OCR 2: 시각적 인과 흐름
DeepSeek-OCR을 기반으로 DeepSeek-AI 연구진은 DeepSeek-OCR 2를 제안했습니다. DeepSeek-OCR이 2차원 광학 매핑을 통해 긴 컨텍스트를 압축하는 가능성을 탐색하는 초기 단계였다면, DeepSeek-OCR 2는 이미지 의미론에 따라 시각적 토큰을 동적으로 재배열하는 새로운 인코더인 DeepEncoderV2의 가능성을 탐구하는 것을 목표로 합니다. DeepEncoder V2는 인코더에 인과 추론 기능을 부여하여 LLM 기반 콘텐츠 이해 전에 시각적 토큰을 지능적으로 재배열할 수 있도록 설계되었으며, 기존의 고정된 래스터 스캔 처리 방식을 대체합니다. 이를 통해 보다 인간과 유사하고 의미론적으로 일관된 이미지 이해를 달성하여 OCR 및 문서 분석 기능을 향상시킵니다.
논문 및 상세 해석:https://go.hyper.ai/ChW45
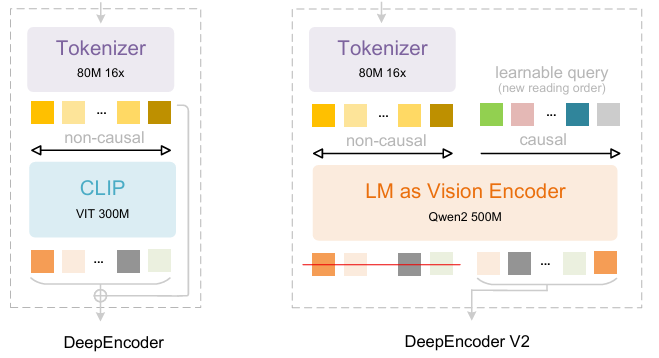
훈련 데이터 세트는 OCR 1.0, OCR 2.0 및 일반 컴퓨터 비전 데이터로 구성되며, 혼합 훈련 데이터 중 OCR 데이터가 80%를 차지합니다. 평가에는 9개 범주에 걸쳐 저널, 학술 논문 및 연구 보고서 등 1,355페이지 분량의 중국어 및 영어 문서를 포함하는 벤치마크인 OmniDocBench v1.5를 사용했습니다.
2. LightOnOCR: 최첨단 OCR을 위한 10억 데이터 용량의 다국어 지원 엔드투엔드 비전-언어 모델
LightOn 연구진은 문서 이미지에서 깔끔하고 정렬된 텍스트를 직접 추출하는 소형 10억 개 매개변수의 다국어 시각 언어 모델인 LightOnOCR-2-1B를 공개했습니다. 이 모델은 기존의 대규모 모델보다 뛰어난 성능을 보여줍니다. 또한 RLVR을 통해 이미지 현지화 기능을 향상시키고 체크포인트 병합을 통해 안정성을 개선했습니다. 모델과 벤치마크는 오픈 소스로 제공됩니다.
논문 및 상세 해석:https://go.hyper.ai/zXFQs
원클릭 배포 튜토리얼 링크:https://go.hyper.ai/vXC4o
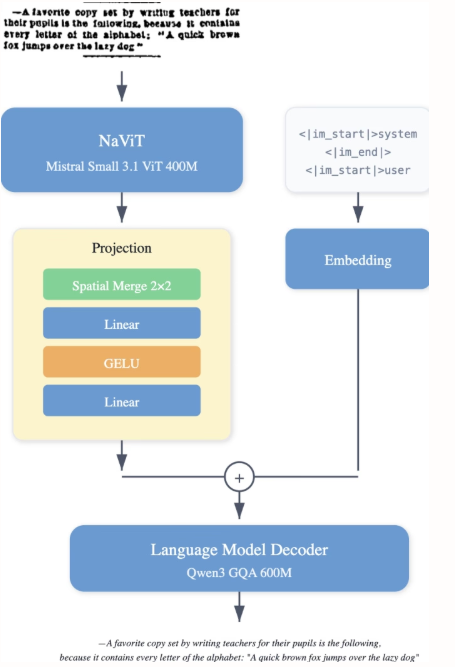
LightOnOCR-2-1B 데이터셋은 스캔 문서를 포함한 여러 출처에서 가져온 교사가 주석을 단 페이지들을 결합하여 견고성을 향상시키고 레이아웃 다양성을 위한 보충 데이터를 제공합니다. 이 데이터셋에는 GPT-4o로 주석 처리된 잘린 영역(단락, 제목, 초록), 착시 현상을 방지하기 위한 빈 페이지 예제, 그리고 nvpdftex 파이프라인을 통해 arXiv에서 얻은 TeX 기반 지도 학습 데이터가 포함되어 있습니다. 다양성을 높이기 위해 공개 OCR 데이터셋도 추가되었습니다.
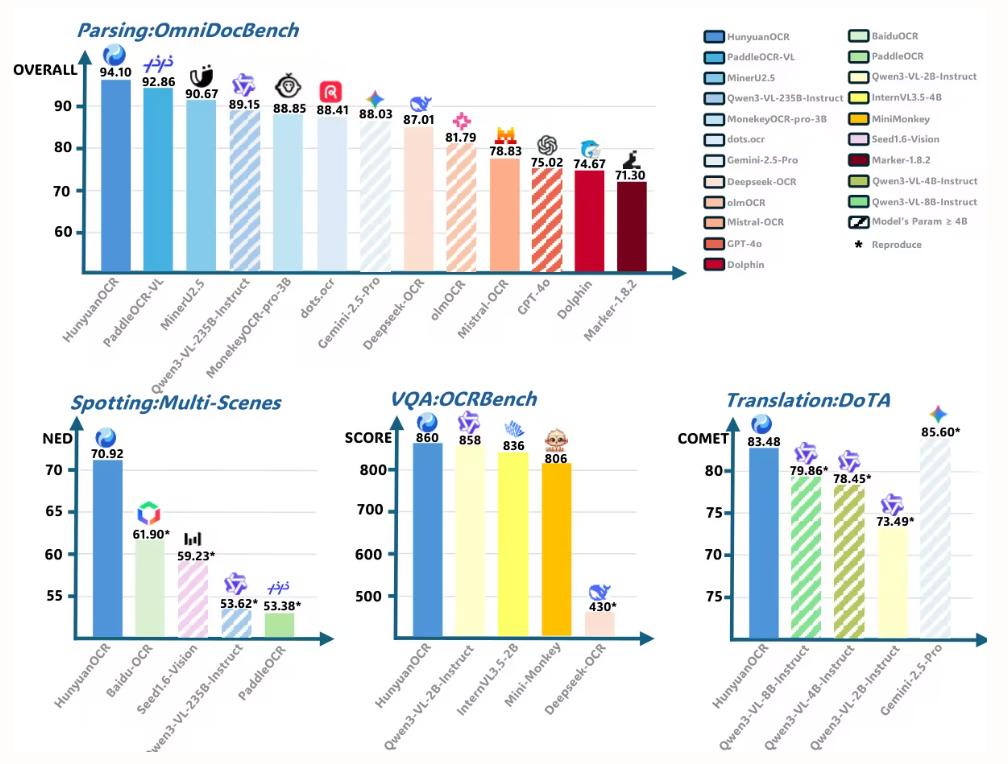
3. HunyuanOCR 기술 보고서
본 논문에서는 텐센트와 협력사들이 개발한 10억 개 파라미터를 가진 오픈소스 비전-언어 모델인 HunyuanOCR을 제안합니다. 데이터 기반 학습과 새로운 강화 학습 전략을 통해, HunyuanOCR은 경량 아키텍처(ViT-LLM MLP 어댑터)를 채택하여 텍스트 현지화, 문서 구문 분석, 정보 추출 및 번역을 포함한 엔드투엔드 OCR 기능을 통합합니다. HunyuanOCR은 대규모 모델 및 상용 API를 능가하는 성능을 보여주며, 산업 및 과학 연구 분야에 효율적으로 적용될 수 있습니다.
논문 및 상세 해석:https://go.hyper.ai/F9fni
원클릭 배포 튜토리얼 링크:https://go.hyper.ai/C4srs

본 논문에서는 HunyuanOCR을 사용하여 OmniDocBench에서 문서 구문 분석 성능을 평가합니다. 그 결과, 94.10점이라는 최고 점수를 달성하여 다른 모든 모델(더 큰 규모의 모델 포함)을 능가했습니다.
4 .PaddleOCR-VL: 0.9B 초소형 비전-언어 모델을 통해 다국어 문서 구문 분석 성능 향상
바이두 팀은 NaViT 방식의 동적 해상도 인코더와 ERNIE-4.5-0.3B 모델을 통합한 자원 효율적인 비전-언어 모델인 PaddleOCR-VL을 제안했습니다. 이 모델은 다국어 문서 구문 분석에서 최첨단 성능을 달성하며, 표와 수식 같은 복잡한 요소를 정확하게 인식합니다. 빠른 추론 능력을 유지하면서 기존 솔루션보다 우수한 성능을 보여주며 실제 시나리오에 적용하기에 적합합니다.
논문 및 상세 해석:https://go.hyper.ai/Rw3ur
원클릭 배포 튜토리얼 링크:https://go.hyper.ai/5D8oo
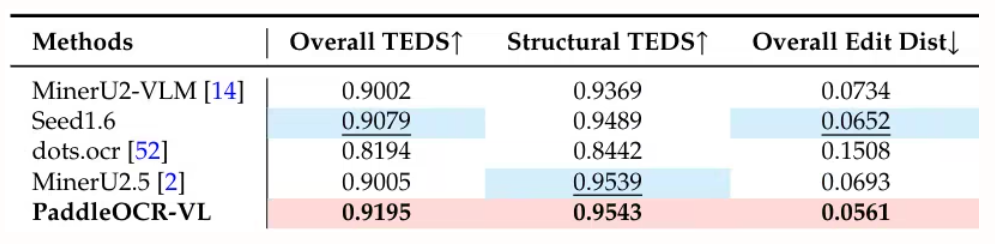
본 연구에서는 OmniDocBench v1.5, olmOCR-Bench 및 OmniDocBench v1.0을 사용하여 페이지 수준 문서 구문 분석을 수행했습니다. OmniDocBench v1.5에서 92.86점의 최고 종합 점수를 달성했으며, 이는 MinerU2.5-1.2B(90.67점)보다 우수한 점수입니다. 또한 텍스트(편집 거리 0.035), 수식(CDM 91.22), 표(TEDS 90.89 및 TEDS-S 94.76) 및 읽기 순서(0.043)에서도 선두를 차지했습니다.
5. 일반 OCR 이론: 통합된 엔드투엔드 모델을 통한 OCR-2.0 구현 방향
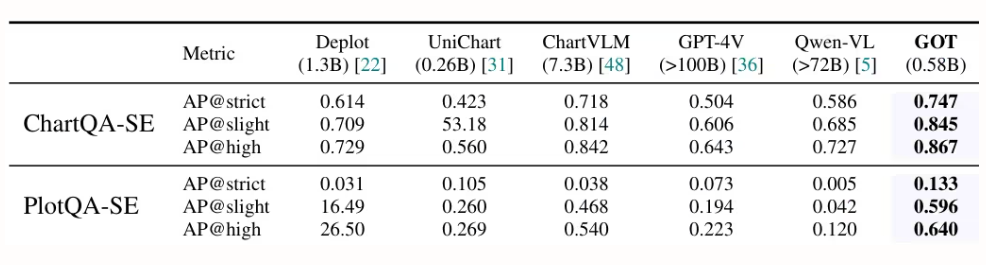
StepFun, Megvii Technology, 중국과학원대학교, 칭화대학교 연구진은 5억 8천만 개의 파라미터를 가진 통합형 엔드투엔드 OCR-2.0 모델인 GOT를 제안했습니다. 고압축 인코더와 장문 컨텍스트 디코더를 통해 텍스트뿐 아니라 수학 공식, 표, 차트, 기하 도형 등 다양한 인공 광학 신호까지 인식 기능을 확장했습니다. GOT는 슬라이스/전체 페이지 입력, 서식 있는 출력(Markdown/TikZ/SMILES), 대화형 영역 수준 인식, 동적 해상도, 다중 페이지 처리 등을 지원하여 지능형 문서 이해 기술 발전에 크게 기여합니다.
논문 및 상세 해석:https://go.hyper.ai/9E6Ra
원클릭 배포 튜토리얼 링크:https://go.hyper.ai/HInRr
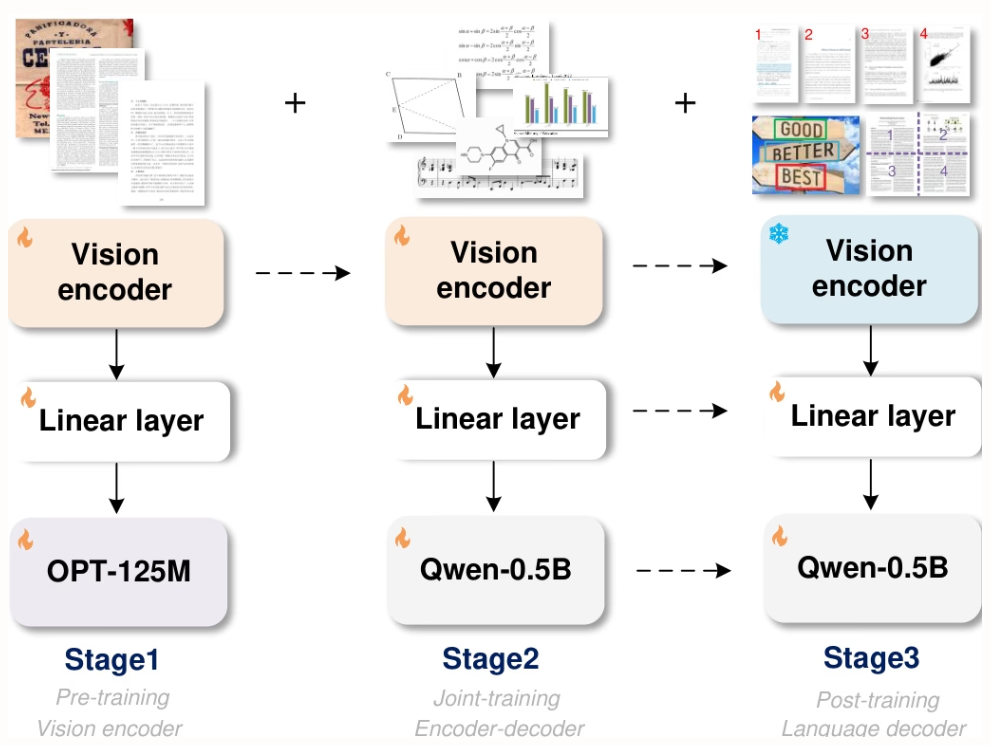
본 논문의 실험은 8×8 L40s GPU에서 수행되었으며, 사전 학습(3회 반복, 배치 크기 128, 학습률 1e-4), 공동 학습(1회 반복, 최대 토큰 길이 6000), 사후 학습(1회 반복, 최대 토큰 길이 8192, 학습률 2e-5)의 세 단계로 진행되었습니다. 첫 번째 단계에서는 성능 유지를 위해 80%의 데이터를 사용했습니다.
이번 주 논문 추천 내용은 여기까지입니다. 더 많은 최첨단 AI 연구 논문을 보시려면 hyper.ai 공식 웹사이트의 "최신 논문" 섹션을 방문하세요.
또한, 연구팀의 고품질 연구 결과와 논문 제출을 환영합니다. 관심 있는 분은 NeuroStar WeChat(WeChat ID: Hyperai01)을 추가해 주세요.
다음주에 뵙겠습니다!