Command Palette
Search for a command to run...
NVIDIA를 비롯한 여러 기업은 백만 종에 달하는 수십억 개의 유전자를 기반으로 EDEN 시리즈 모델을 구축하여 최첨단(SOTA) 유전체 및 단백질 예측 기능을 구현했습니다.
프로그래밍 가능 생물학의 근본적인 목표는 생명 시스템의 합리적인 설계와 정밀한 제어를 달성하여 복잡한 질병에 혁신적인 치료법을 제공하는 것입니다. 그러나이 과정은 생물학적 시스템의 본질적인 복잡성으로 인해 오랫동안 제약을 받아왔습니다.다양한 규모의 조절 네트워크, 숨겨진 긴 서열 의존성, 그리고 환경 변화에 대한 유기체의 다양한 적응성은 전통적인 "시행착오" 방식의 연구 개발을 맞춤화, 낮은 처리량, 높은 비용이라는 딜레마에 빠뜨렸습니다.
궁극적으로 현재의 계산 모델이 의존하는 훈련 데이터는 규모와 다양성 측면에서 생명체가 수십억 년의 진화를 통해 만들어낸 방대한 설계 공간을 포괄하기에는 턱없이 부족합니다. 따라서 이러한 모델들은 보편적 설계 원리를 포착하는 데 어려움을 겪습니다.다양한 모드와 규모를 아우르는 혁신적인 치료법 설계에 직면했을 때, 그 효과를 일반화하는 능력이 심각하게 부족하다.
이러한 근본적인 한계를 극복하기 위해,베이스캠프 리서치, 엔비디아, 그리고 여러 유수 학술 기관들이 공동으로 EDEN 시리즈 메타게놈 기본 모델을 개발했습니다.종간 상호작용과 환경 정보와 연관된 방대한 양의 자연 진화 데이터를 학습함으로써, 생물학적 설계의 심층적인 "문법"과 보편적 원리를 체계적으로 최초로 추출해냈습니다. 이 모델은 280억 개의 매개변수를 가지고 있으며, 여러 벤치마크 테스트에서 최첨단 결과를 달성했습니다. 이 모델의 핵심적인 혁신은 종간 서열을 이해하고 생성하는 탁월한 능력에 있으며, 이를 통해 생명공학을 "스크리닝" 단계에서 "예측 가능한 프로그래밍" 단계로 발전시켰습니다.
EDEN의 통합 바이오디자인 엔진으로서의 역량을 검증하기 위해 연구팀은 다양한 치료 방식에 걸쳐 체계적인 테스트를 수행했습니다. 유전자 치료에서 EDEN은 표적 부위에 단 30개 염기쌍의 힌트만 사용하여 인간 게놈에 큰 조각을 정확하게 통합할 수 있는 활성 재조합효소를 새롭게 설계할 수 있습니다. 항균 펩타이드 설계와 관련해서는…동일한 모델로 생성된 펩타이드 라이브러리는 다제내성 병원균에 대해 최대 97% 활성을 나타냈다.또한 마이크로몰 수준의 효능을 지니고 있습니다. 생태계 수준에서 EDEN은 수만 개의 인공 유전체, 정확한 대사 경로 및 합리적인 종간 관계를 포함하는 합성 미생물군집을 성공적으로 구축했습니다.
"EDEN 기반 모델군을 활용한 AI 프로그래밍 가능 치료제 설계"라는 제목의 관련 연구 결과는 bioRxiv에 사전 공개 논문으로 게재되었습니다.
연구 하이라이트:
* 이 시스템은 진화 역사를 통해 보편적 설계 원리를 직접 학습하는 새로운 패러다임을 개척했으며, 전 세계 생물 다양성을 포괄하는 메타게놈 데이터베이스인 BaseData를 활용한 훈련을 통해 탁월한 종간 서열 이해 및 생성 능력을 달성했습니다.
* 본 연구는 단일 기본 모델이 다중 규모, 다중 모드 치료법 설계에 있어 강력한 활용성을 지니고 있음을 입증하며, 단일 모델이 분자에서 생태계에 이르기까지 복잡한 설계 과제를 균일하게 해결할 수 있음을 보여줍니다.
* EDEN은 DNA 단서만을 이용하여 여러 질병 관련 부위에 대한 기능성 재조합효소를 설계할 수 있으며, 훈련되지 않은 표적에서 63.21 TP3T의 기능성 적중률을 달성합니다.

서류 주소:
https://doi.org/10.64898/2026.01.12.699009
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "EDEN"이라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
더 많은 AI 프런티어 논문:
https://hyper.ai/papers
BaseData 데이터셋: 고품질 장문 시퀀스를 활용하여 생물학적 AI 데이터 벤치마크를 재정립합니다.
본 연구에 사용된 BaseData 데이터셋은 기존 생물학 데이터베이스의 한계를 근본적으로 극복합니다. 기존 데이터베이스는 일반적으로 제한된 참조 게놈과 단편적인 짧은 염기서열에 의존하는 반면, BaseData는 완전한 진화 신호를 체계적으로 포착하여 전 세계 생물 다양성을 포괄하는 진화 게놈 데이터 공급망을 구축하는 것을 목표로 합니다.
BaseData의 핵심 가치는 주로 규모와 전략적 구성에 반영되어 있습니다. 아래 다이어그램에서 볼 수 있듯이,이 데이터베이스에는 9조 7천억 개의 뉴클레오티드 마커가 포함되어 있으며, 100만 개 이상의 새로운 종과 1000억 개 이상의 새로운 유전자를 포괄합니다.더욱 중요한 것은, 이 데이터는 무작위로 수집된 것이 아니라 환경 메타게놈, 박테리오파지, 이동성 유전 요소와 같은 정보 밀도가 높은 시퀀스로 의도적으로 풍부하게 구성되었다는 점입니다. 이러한 데이터는 박테리오파지-숙주 상호작용 및 수평적 유전자 전달과 같은 핵심적인 진화 역학을 자연스럽게 기록하며, 모델이 종간에 보편적인 기능 규칙을 학습하는 데 필요한 핵심 자료를 제공합니다.
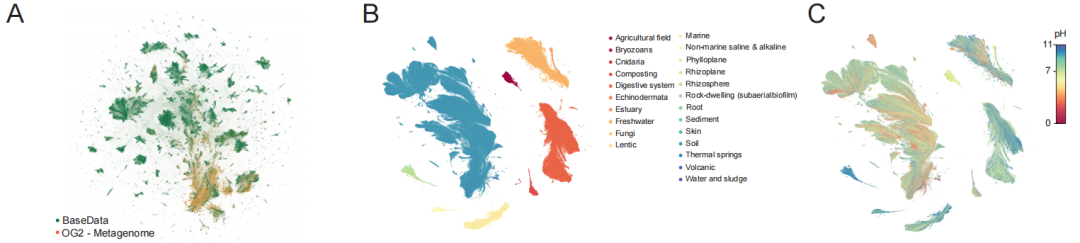
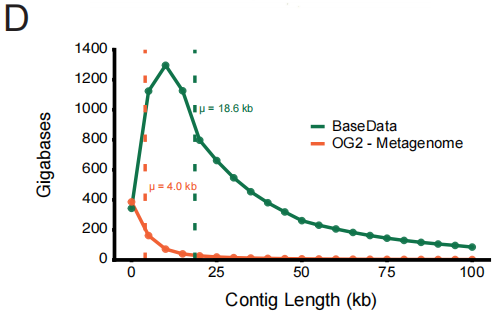
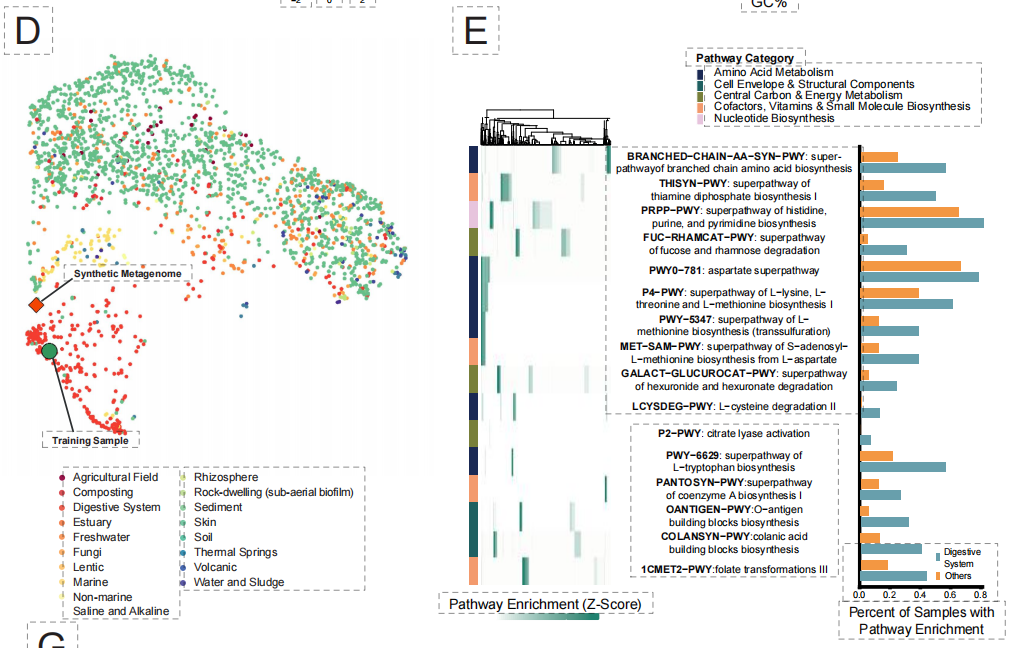
데이터 품질 측면에서 BaseData는 특히 시퀀스 컨텍스트의 완전성 측면에서 질적인 개선을 이루었습니다. 널리 사용되는 OpenGenome-2(OG2)와 비교했을 때, 연속적인 시퀀스 단편(겹치는 부분)의 중간 길이는 18.6kbp에 달하며(OG2는 4.0kbp), 각 어셈블리에는 훨씬 더 많은 유전자가 포함되어 있습니다. 이처럼 더 길고 연속적인 배경 정보는 모델이 유전자 간 조절 및 대사 경로를 이해하는 데 매우 중요합니다.
이러한 품질 우위를 정량화하기 위해 연구팀은 통제된 실험을 수행했습니다. 즉, BaseData와 OG2에서 가져온 동일한 크기의 데이터셋으로 일련의 모델을 학습시킨 것입니다. 결과는 "품질 인식 확장 법칙"을 명확하게 입증했습니다. 동일한 계산 오버헤드 조건에서 BaseData로 학습된 모델은 테스트 퍼플렉시티가 더 빠르게 감소했습니다. 핵심적인 발견은 대규모 모델(예: 70억 개의 매개변수)이 BaseData의 긴 시퀀스 정보를 최대한 활용하여 궁극적으로 OG2로 학습된 유사 모델보다 우수한 성능을 보인다는 것입니다.이는 장기적인 맥락이 모델 성능에 결정적인 영향을 미친다는 것을 직접적으로 보여줍니다.
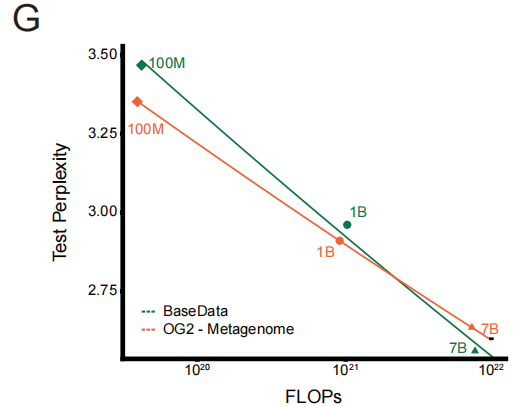
이 패턴을 기반으로연구팀은 전체 베이스데이터를 사용하여 280억 개의 매개변수로 EDEN-28B 모델을 학습시켰습니다.이 모델은 가장 낮은 테스트 퍼플렉시티를 달성했을 뿐만 아니라, 성능 향상 궤적 또한 소규모 모델에서 도출된 확장 예측과 완벽하게 일치했습니다. 후속 작업 모니터링에서, 사전 학습 과정에서 모델이 생성한 단백질의 구조적 신뢰도 지수는 학습 과정에 따라 지속적으로 단조 증가하는 양상을 보였으며, 이는 고품질 데이터가 실제 치료에 필요한 데이터 생성 능력을 직접적이고 안정적으로 향상시킨다는 것을 입증합니다.
또한 모든 데이터는 28개국 208개 라이선스를 포괄하는 표준화된 법적 계약을 통해 확보되었으며, 이를 통해 출처에서 사용까지 추적성과 이익 공유 체계를 구축하고 대규모 생물학적 AI 연구에 필요한 윤리 및 거버넌스 기준을 설정했습니다.
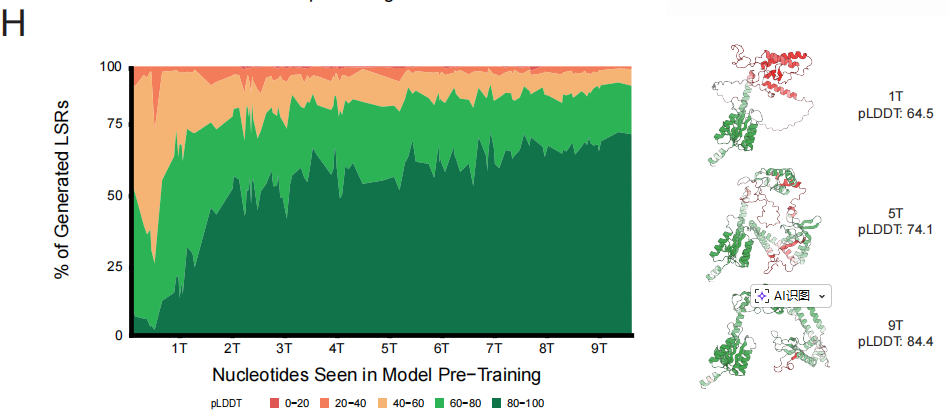
EDEN은 범용 생물학적 설계 엔진입니다.
EDEN 모델 제품군은 "확장성, 범용성 및 확장성"을 핵심 설계 원칙으로 삼아 설계되었으며, 모델 매개변수는 1억에서 280억에 이릅니다.그중에서도 핵심 작업 모델인 EDEN-28B는 메타게놈 데이터의 고유한 특성에 깊이 적응된 아키텍처와 훈련 전략을 가지고 있습니다.
모델 아키텍처 측면에서,EDEN은 대규모 언어 모델을 통해 검증된 디코더 전용 Transformer 아키텍처를 채택했으며, 특히 Llama 3.1의 설계 방식을 기반으로 합니다.이러한 선택은 Transformer의 장거리 의존성 모델링 능력이 탁월하기 때문에 가능합니다. EDEN-28B는 6,144개의 은닉층과 48개의 어텐션 헤드를 가진 48층 네트워크로 구성되며, RoPE 위치 인코딩을 사용하는 SwiGLU 활성화 함수를 사용합니다. 이 모델은 512개의 어휘 크기를 가진 단일 뉴클레오티드 해상도 토큰화 방식을 채택하여 가장 기본적인 "문자" 수준에서 DNA 서열을 이해하고 생성할 수 있습니다.
핵심적인 기술적 특징은 긴 시퀀스를 생성할 수 있다는 점입니다. 모델의 컨텍스트 윈도우는 8,192개의 레이블로 설정되어 있지만, 실제 적용에서는이 시스템은 13,000개 이상의 염기쌍으로 이루어진 일관된 게놈 서열을 안정적으로 생성하고 정확하게 조립할 수 있으며, 동시에 정확한 유전자 순서, 판독 프레임 및 조절 요소 구조를 유지합니다.이는 모델이 단순한 국소 패턴 매칭을 넘어 훨씬 더 심층적인 유전체 구조의 "문법"을 추론하고 적용할 수 있음을 보여줍니다. 이 문법은 물리적 윈도우 길이를 초월합니다. 전체 학습은 1,008개의 H100 GPU에서 완료되었으며, 대규모 분산 컴퓨팅을 통해 방대한 양의 진화 데이터로부터 효율적인 학습을 달성했습니다.
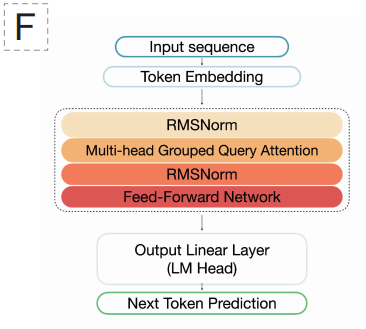
EDEN의 핵심 설계 철학은 "사전 학습-미세 조정" 패러다임을 따릅니다. 첫 번째 단계에서는 종의 진화 역사를 아우르는 대규모 BaseData를 사용하여 모델을 사전 학습함으로써 단백질 접힘 및 대사 경로 구성과 같은 생물학적 설계의 일반적인 원리를 내재화합니다.
이러한 견고한 기반을 바탕으로 특정 DNA 부위를 표적으로 하는 재조합효소를 설계하거나 새로운 항균 펩타이드를 생성하는 것과 같은 구체적인 치료제 설계 과제를 수행할 수 있습니다.소량의 고품질 작업 쌍 데이터만으로도 가벼운 미세 조정을 통해 모델은 해당 작업의 "특징"을 빠르게 습득할 수 있습니다.이 설계는 단일 EDEN 모델이 범용 "생물학적 서열 엔진" 역할을 하여 유전자 삽입 및 펩타이드 설계부터 미생물군집 공학에 이르기까지 다양한 치료 방식을 유연하게 적용하고 구동할 수 있도록 함으로써 "하나의 모델로 다양한 기능 구현"이라는 프로그래밍 가능한 생물학의 비전을 진정으로 실현합니다.
분자, 세포에서 생태계 수준에 이르기까지 치료 혁신을 주도합니다.
실제 치료 설계에서 EDEN 모델의 보편성과 효과성을 체계적으로 검증하기 위해 연구팀은 규모, 패턴 및 생물학적 복잡성이 매우 다른 네 가지 핵심 방향을 선정하여 실험적 검증을 진행했습니다.
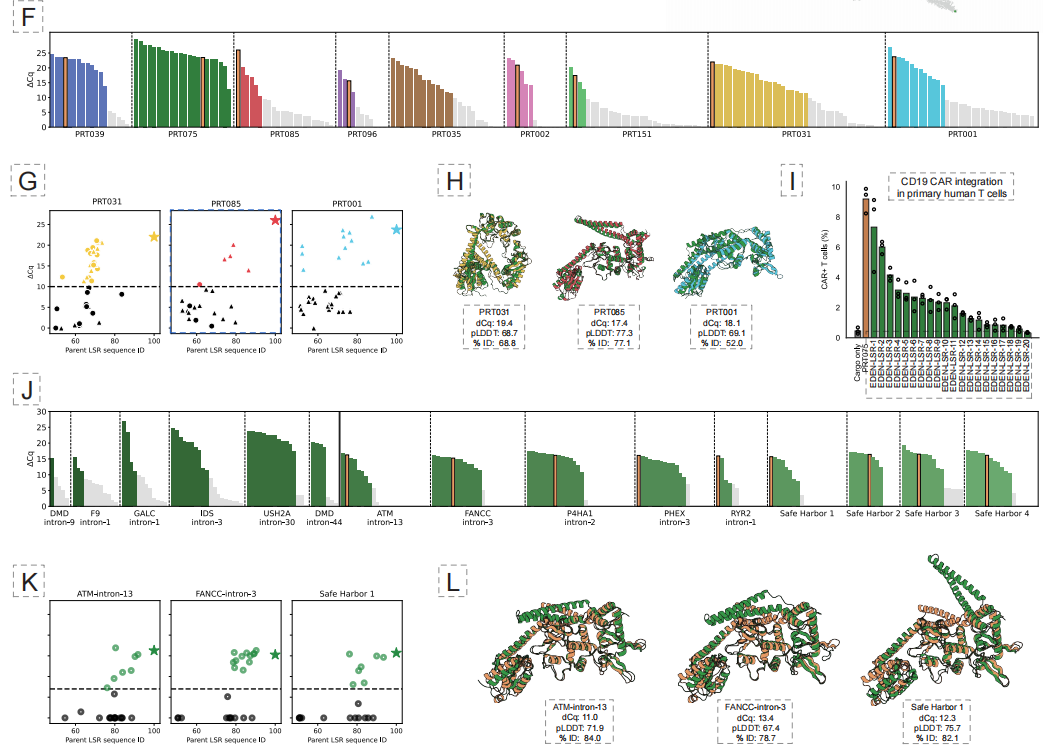
AI 프로그래밍 가능 유전자 삽입(aiPGI) 분야에서 연구팀은 "대형 DNA 조각의 정밀한 통합"이라는 오랜 난관을 극복하는 데 집중해 왔습니다.기존의 CRISPR 기술은 이중 가닥 절단을 유도하는 방식에 의존하며, 자연적으로 존재하는 대형 세린 재조합효소(LSR)는 인간 게놈 서열을 인식할 수 없습니다. 아래 그림에서 볼 수 있듯이, EDEN은 EDEN-LSR 모델을 구축하여 모델에 포함된 수백만 개의 LSR 결합 부위 쌍을 정밀하게 조정함으로써 "표적 DNA 서열 → 해당 재조합효소"의 매핑 관계를 이해할 수 있도록 했습니다.
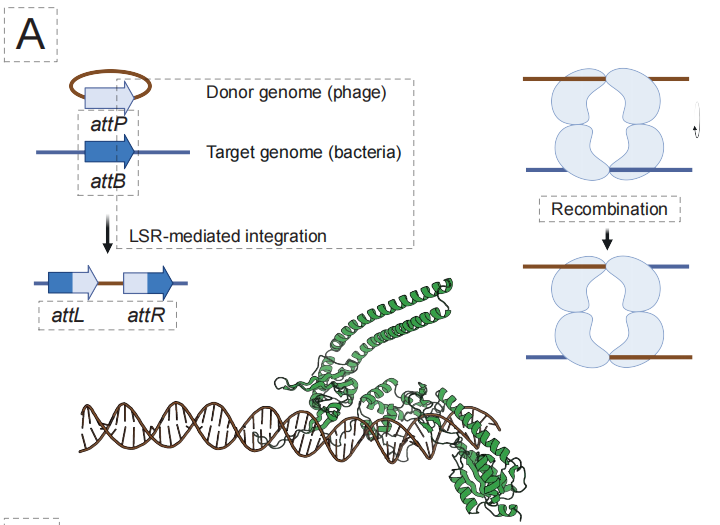
실험 결과에 따르면 이 접근법은 10개의 서로 다른 질병 관련 유전자 좌위와 4개의 잠재적 "안전지대" 좌위에 대해 활성 LSR을 성공적으로 생성했으며, 전체 기능적 적중률은 53.61 TP3T였습니다. 더욱 중요한 것은,50% 설계 효소는 인간 일차 T 세포에 치료 관련 CAR 유전자 삽입을 달성할 수 있으며, 일부 변형체는 세포주에서 최대 40%의 통합 효율을 달성했습니다.이는 임상 적용 가능성을 보여줍니다.
새로운 가교 재조합효소(BR) 분야에서,EDEN 모델의 기능은 더욱 프로그래밍 가능한 유전자 편집 시스템인 브리징 재조합효소로 확장되었습니다.아래 그림에서 볼 수 있듯이, 설계 최적화를 위해 연구팀은 수백만 개의 BR 함유 유전체 영역에 대한 미세 조정을 통해 EDEN-BR 특이적 모델을 구축했습니다.
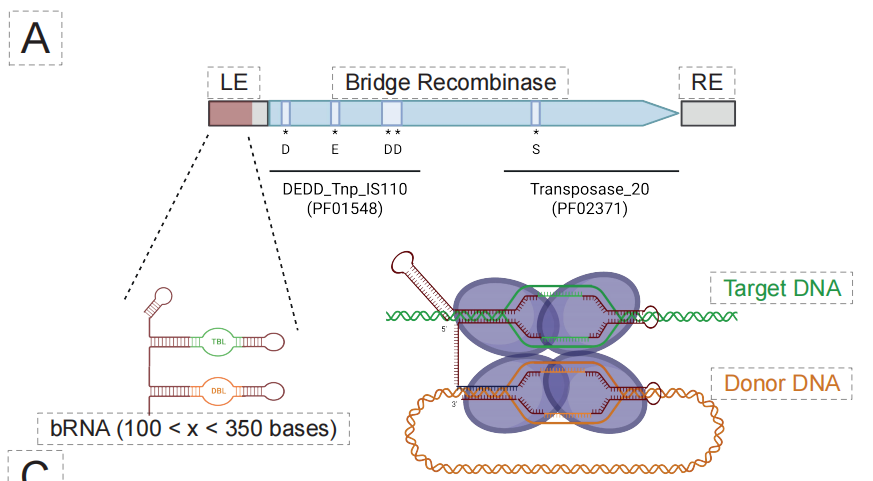
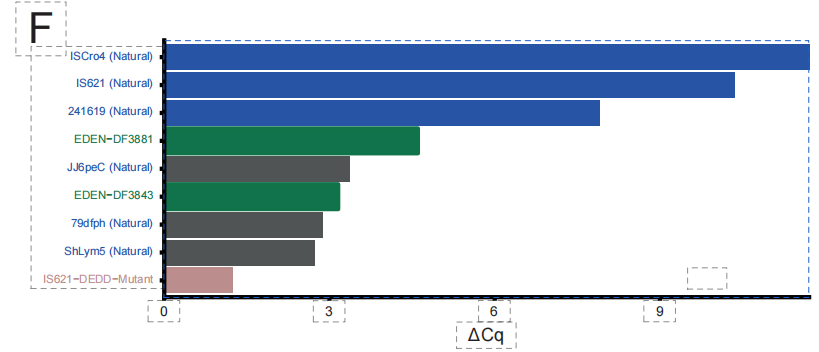
핵심 생화학 실험을 통해 이 설계 과정의 타당성이 검증되었습니다. 아래 그림에서 볼 수 있듯이, 예비 무세포 실험에서 EDEN-BR로 생성된 49개의 후보 서열 중 2개가 재조합효소 활성을 나타내는 것으로 확인되었습니다. DF3843과 DF3881로 명명된 이 두 인공적으로 설계된 단백질은 알려진 천연 BR 서열과 각각 최대 851 TP3T 및 65.81 TP3T의 유사성을 보입니다. 잘 연구된 참조 단백질인 ISCro4와의 서열 유사성은 351 TP3T보다 훨씬 낮지만, 3차원 구조는 매우 유사합니다.이는 EDEN이 단순히 서열을 모방하는 것이 아니라 단백질의 기능과 접힘을 결정하는 핵심 구조적 논리를 완전히 파악했음을 증명합니다.
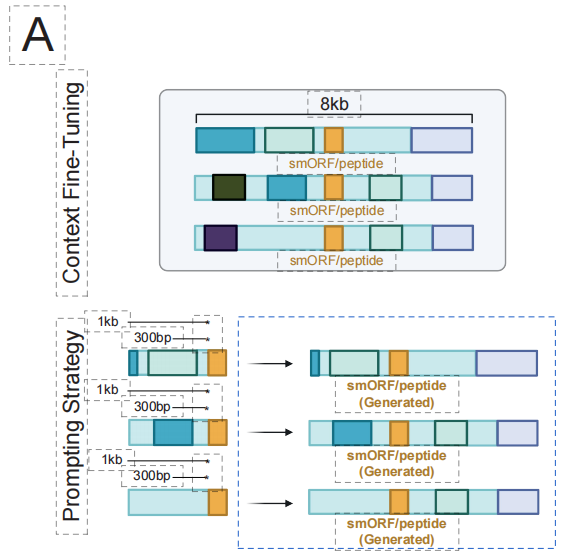
신규 항균 펩타이드(AMP) 분야에서 연구팀은 EDEN의 신규 항균 펩타이드 설계 능력을 검증했습니다. 아래 그림에서 볼 수 있듯이,유전체적 맥락 정보를 통합하는 정밀 조정 전략을 활용함으로써, 이 모델은 새로운 항균 펩타이드 서열을 생성할 수 있습니다.
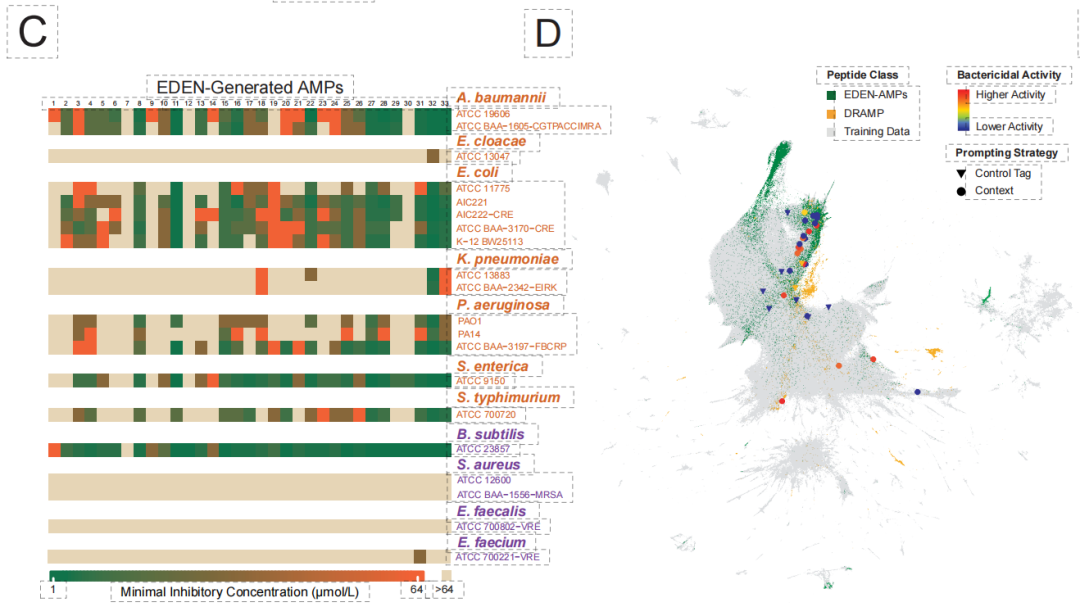
실험적 검증을 통해 획기적인 결과가 도출되었습니다. 아래 그림에서 보는 바와 같이,33개의 생성 펩타이드로 구성된 AMP 라이브러리에서 최대 971개의 TP3T 서열이 항균 활성을 나타냈다.그중에서 가장 우수한 성능을 보인 후보 물질들은 다제내성 그람 음성 세균(예: 아시네토박터 바우마니)에 대해 마이크로몰 농도 수준의 억제 효과를 나타내어 강력한 외막 투과 능력을 입증했습니다. 생성된 염기서열들은 일반적으로 기존 데이터베이스와 낮은 유사성을 보였는데, 이는 해당 모델이 기존의 상동성 한계를 극복하고 진정한 "데 노보 설계(de novo design)"를 달성할 수 있음을 보여줍니다.
마지막으로, 가장 복잡한 생태계 수준에서 이 연구는 "합성 미생물군집" 설계에 대한 과제를 제기했습니다. 기존 방법은 여러 종 간의 대사적 상호작용과 생태적 균형을 조율하는 데 어려움을 겪습니다. 아래 그림에서 볼 수 있듯이, EDEN은 소화계 미생물군집 데이터를 사용하여 미세 조정을 거친 후,기능 유전자 또는 생태적 지위에 대한 단서만을 기반으로 9만 종 이상의 생물종을 포함하고 수 기가베이스에 달하는 합성 메타게놈을 성공적으로 생성했습니다.
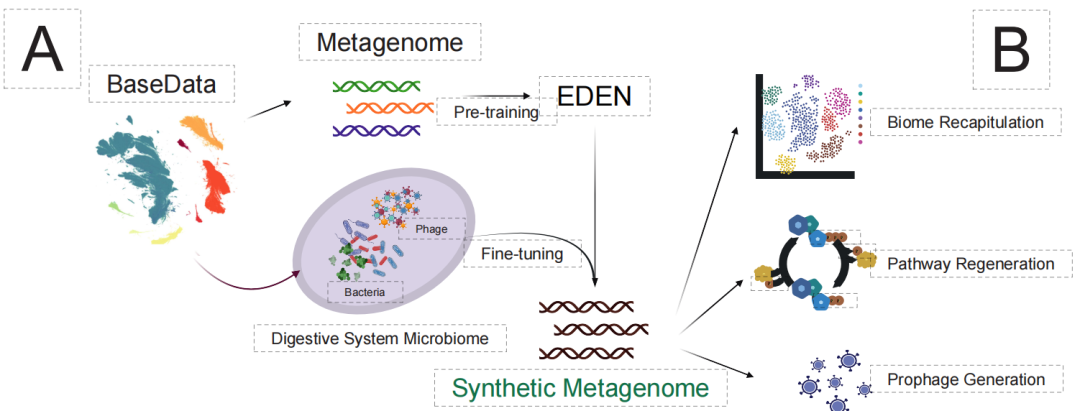
생성된 결과는 높은 수준의 생태적 현실성을 보여줍니다.99% 종은 소화계 관련 생물군으로 정확하게 분류되었으며, 종간 대사 경로가 완전히 보존되었다.더 나아가, 이 모델은 숙주 게놈에 통합된 프로파지 구조까지 정확하게 생성할 수 있어 숙주와 바이러스 간의 복잡한 상호작용 논리를 포착했음을 보여줍니다.
이 네 가지 규모별 실험은 통합된 진화 데이터로 사전 학습된 EDEN 모델이 범용 생물학적 설계 엔진으로서의 역할을 수행할 수 있음을 종합적으로 보여줍니다. 이 모델은 최소한의 작업별 데이터 지침만으로도 분자, 세포 및 생태계 수준에서 신속하고 안정적으로 치료 혁신을 이끌어낼 수 있으며, 프로그래밍 가능한 생물학을 위한 견고한 실질적 기반을 마련합니다.
인공지능과 합성생물학의 통합을 통한 혁신
최근 몇 년 동안 프로그래밍 가능한 생물학 분야에서 학계와 산업계의 통합 및 혁신이 크게 가속화되었으며, 일련의 주요 발전들이 바이오디자인의 경계를 재정의하고 있습니다.
전 세계 유수의 학술 기관들이 진화론적 지식을 전례 없는 규모와 정밀도로 계산 가능한 모델로 변환하고 있습니다. 예를 들어, 2024년 초 딥마인드, 아이소모픽 랩스, 그리고 여러 대학의 공동 연구팀은 단백질 구조와 상호작용을 예측하고 특정 기능을 가진 새로운 단백질을 생성할 수 있는 알파폴드 3(AlphaFold 3) 모델을 발표했습니다. 이 모델은 생체 분자의 복잡한 상호작용을 고정밀 시뮬레이션을 위한 통합 프레임워크에 포함시킨 최초의 모델입니다.네이처지는 이 발견을 "생명체의 분자 기계 내부 작동 방식을 규명하는 데 있어 획기적인 진전"이라고 극찬했다.
업계는 이러한 혁신적인 발견들을 플랫폼과 치료법으로 전환하는 속도를 가속화하고 있습니다. AI 기반 신약 개발 분야에서 NVIDIA와 Recursion Pharmaceuticals는 신약 발견 방식을 '건초 더미에서 바늘 찾기'에서 '체계적인 접근 방식'으로 전환하는 것을 목표로 하는 생화학 AI 모델 라이브러리인 BioNeMo를 출시했습니다. 합성 생물학 기업인 Ginkgo Bioworks는 자동화 플랫폼을 활용하여 탄소 포집 및 화학 물질 생산을 위한 미생물 군집을 체계적으로 설계함으로써 '합성 생태계' 구축을 주도하고 있습니다.
데이터와 알고리즘에 의해 주도되는 이러한 새로운 흐름은 생물학을 관찰 및 서술 과학에서 프로그래밍 가능하고, 디버깅 가능하며, 예측 가능한 공학 분야로 변화시키고 있습니다. 이는 생명체를 더욱 정밀하게 코딩하여 질병을 정복할 수 있다는 것을 의미할 뿐만 아니라, 자원, 환경, 건강 분야의 지구적 과제를 해결하기 위해 생물학적 시스템을 체계적으로 설계할 수 있는 가능성을 예고합니다.
참조 링크:
1.https://nvidianews.nvidia.com/news/nvidia-announces-broad-expansion-of-its-biomedicine-platform
2.https://www.ginkgobioworks.com/2024/01/04/ginkgo-bioworks-and-pfizer-expand-collaboration-to-advance-rna-based-therapeutics/








