Command Palette
Search for a command to run...
TRELLIS.2: O-Voxel 기술을 활용하여 복잡한 3D 형상 및 재료를 효율적으로 생성합니다. 환자 이탈 예측 데이터 세트: 이탈 위험이 있는 환자를 식별하는 데 도움이 됩니다.

현재 이미지에서 사용 가능한 3D 모델을 생성하는 것은 여전히 시간과 노동력이 많이 소요되는 작업이며, 기존 방식은 전문 모델러의 수동 작업에 크게 의존합니다. AI의 도움을 받더라도,복잡한 형태, 투명한 재질 또는 개방된 표면을 다룰 때, 모델은 종종 품질이 떨어지거나 비정상적인 구조를 생성하며, 게임이나 전자상거래에 직접 사용할 수 있는 사실적인 재질의 최종 제품을 제작하기 어렵습니다.
이러한 배경 속에서 마이크로소프트 팀은 2025년 12월, 단일 이미지에서 고품질 3D 에셋을 생성하고 텍스처링하는 작업을 위한 오픈 소스 프로젝트인 TRELLIS.2를 출시했습니다.이 프로젝트는 입력 이미지에서 3D 형상 및 재질에 이르기까지 엔드 투 엔드 프로세스를 제공하며, 빠른 경험 및 에셋 내보내기를 위한 대화형 웹 데모를 함께 제공합니다. TRELLIS.2는 기하학적 디테일과 텍스처 일관성 향상에 중점을 두고, 다양한 해상도와 계단식 추론 구성을 지원하며, 제어 가능한 추론 매개변수를 통해 속도와 품질의 균형을 유지하므로 3D 콘텐츠 제작, 신속한 프로토타이핑 및 창의적 탐색과 같은 시나리오에 적합합니다.
HyperAI 웹사이트에서 "TRELLIS.2 3D 생성 데모"를 만나보실 수 있습니다! 지금 바로 체험해 보세요!
온라인 사용:https://go.hyper.ai/drI7I
1월 19일부터 1월 23일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 5
* 엄선된 고품질 튜토리얼: 9개
* 이번 주 추천 논문: 5편
* 커뮤니티 기사 해석 : 4개 기사
* 인기 백과사전 항목: 5개
1월 마감인 주요 학술대회: 3개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. 환자 분할 데이터 세트
환자 세분화는 의료 분석 및 마케팅을 위한 환자 분류 데이터 세트입니다. 환자의 인구 통계, 건강 상태, 보험 유형 및 의료 서비스 이용 패턴을 분석하여 의미 있는 그룹으로 환자를 분류함으로써 개인 맞춤형 진료 및 마케팅의 효과를 향상시키는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/Wp8LS
2. CCTV 사고 낙상 감지 데이터 세트
CCTV Incident는 컴퓨터 비전 작업에서 낙상 감지, 자세 추정 및 사고 모니터링을 위해 특별히 설계된 공개 합성 데이터셋입니다. 이 데이터셋은 CCTV 오버헤드 뷰를 분석하도록 설계되어 모델이 사람의 자세를 이해하고 서 있는 사람과 넘어진 사람을 정확하게 구분할 수 있도록 합니다.
직접 사용:https://go.hyper.ai/q60Dm

3. 환자 이탈 예측 데이터셋
환자 이탈 예측 데이터 세트는 의료 분야를 위한 범주형 데이터 세트로, 2,000건의 환자 기록을 포함하며, 이탈 위험이 있는 환자를 식별하여 사전에 유지 조치를 취할 수 있도록 설계되었습니다.
직접 사용:https://go.hyper.ai/QAeYw
4. RealTimeFaceSwap-10k 화상 통화 스푸핑 데이터셋
RealTimeFaceSwap-10k 화상 통화 딥페이크 탐지 데이터셋은 화상 회의 시나리오에서 딥페이크 영상을 탐지하는 데 사용되는 데이터셋입니다. 이 데이터셋은 다양한 응용 시나리오와 데이터 유형을 포함하며, 영상 스푸핑 탐지를 위한 기본적인 데이터 지원을 제공하는 것을 목표로 합니다.
직접 사용:https://go.hyper.ai/SGZRO
5. TransPhy3D 투명 반사 합성 비디오 데이터 세트
TransPhy3D는 베이징 인공지능 연구원이 서던 캘리포니아 대학교, 칭화 대학교 및 기타 기관과 협력하여 개발한 합성 비디오 데이터셋으로, 투명하고 반사되는 장면에 초점을 맞추고 있습니다. 이 데이터셋은 Blender/Cycles를 사용하여 렌더링된 11,000개의 시퀀스로 구성되어 있으며, 고품질 RGB 프레임과 물리 기반 깊이 및 법선 레이블을 제공합니다.
직접 사용:https://go.hyper.ai/5ExjE
선택된 공개 튜토리얼
1.vLLM+Open WebUI Nemotron-3 Nano 배포
Nemotron-3-Nano-30B-A3B-BF16은 NVIDIA에서 처음부터 자체 개발한 대규모 언어 모델(LLM)로, 추론 및 비추론 작업 모두에 적용 가능한 통합 모델입니다. 이 모델은 AI 에이전트 시스템, 챗봇, RAG 시스템 및 기타 AI 애플리케이션을 개발하는 데 적합합니다.
온라인으로 실행:https://go.hyper.ai/VUuDA
2. MedGemma 1.5 멀티모달 AI 의료 모델
MedGemma 1.5는 의료 멀티모달 작업에 탁월한 성능을 발휘하는 모델입니다. 이미지 분류, 시각적 질의응답, 의학 지식 추론 분야에서 뛰어난 성능을 보여주어 다양한 임상 시나리오에 적합하며 의료 연구 및 진료를 효과적으로 지원합니다. 이 모델은 SigLIP 이미지 인코더와 고성능 언어 모듈을 기반으로 구축되었으며, 의료 영상, 텍스트, 검사 보고서 등 다양한 데이터셋으로 사전 학습되었습니다. 이를 통해 고차원 의료 영상, 전체 단면 병리 영상, 종단면 영상 분석, 해부학적 위치 파악, 의료 문서 이해, 전자 건강 기록 분석 등의 작업을 효율적으로 처리할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/dZRn9
3. 네모트론 음성 스트리밍 ASR: 자동 음성 인식 데모
Nemotron Speech Streaming ASR은 NVIDIA의 Nemotron Speech 팀에서 출시한 스트리밍 자동 음성 인식 모델입니다. 낮은 지연 시간과 실시간 음성 전사 시나리오에 맞춰 설계되었으며, 높은 처리량의 배치 추론 기능도 갖추고 있어 음성 비서, 실시간 자막 생성, 회의록 작성, 대화형 AI와 같은 애플리케이션에 적합합니다. 이 모델은 캐시 인식 FastConformer 인코더와 RNN-T 디코더 아키텍처를 사용하여 연속적인 오디오 스트림을 효율적으로 처리하고, 인식 정확도를 유지하면서 종단 간 지연 시간을 크게 줄입니다.
온라인으로 실행:https://go.hyper.ai/SDEBI
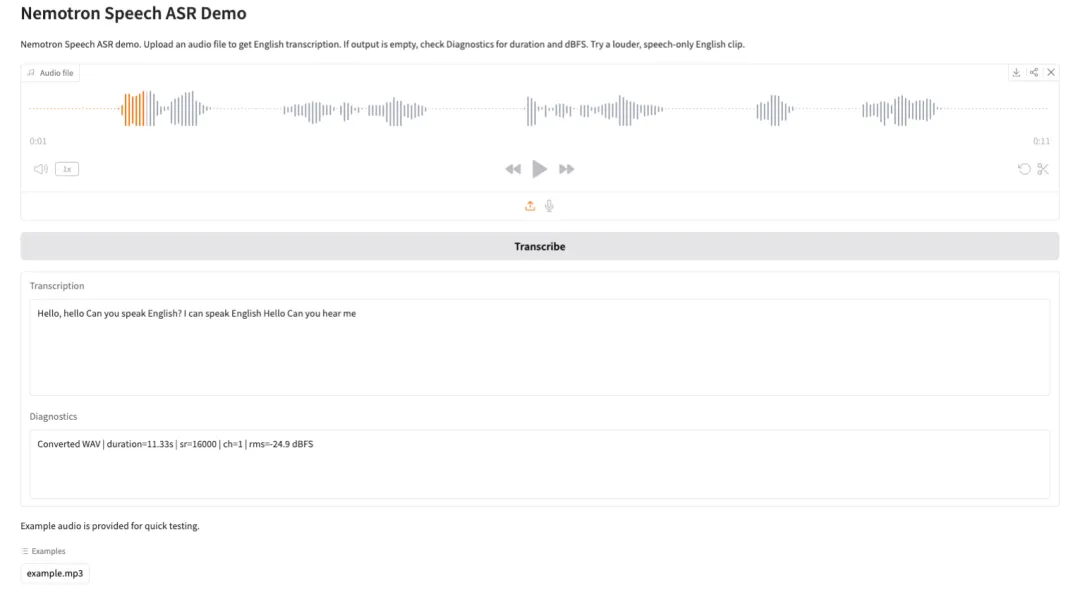
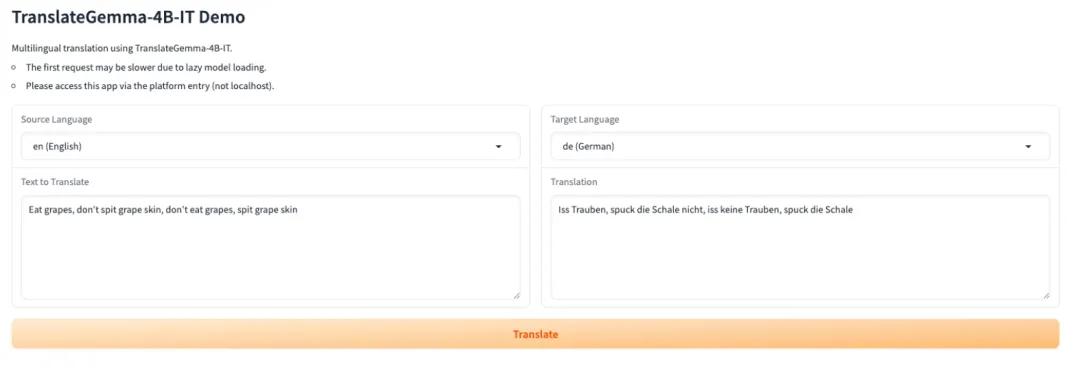
4. TranslateGemma-4B-IT: Google에서 제공하는 오픈 소스 번역 모델 시리즈입니다.
TranslateGemma는 Google 번역 팀에서 출시한 경량 오픈 소스 번역 모델 제품군입니다. Gemma 3 모델 제품군을 기반으로 구축되었으며, 다국어 텍스트 번역 및 실제 배포 시나리오에 특화되어 설계되었습니다. 이 제품군은 컴팩트한 파라미터 규모로 안정적이고 사용 가능한 번역 기능을 제공하므로 GPU 메모리가 제한적인 환경이나 빠른 배포가 필요한 환경에서도 로딩 및 추론이 용이합니다.
온라인으로 실행:https://go.hyper.ai/FRy35
5. GLM-Image: 정확한 의미론을 갖춘 고품질 이미지 생성 모델
GLM-Image는 Zhipu AI에서 개발한 오픈 소스 이미지 생성 모델로, 자기회귀 디코딩과 확산 디코딩을 통합합니다. 이 모델은 텍스트를 이미지로, 이미지를 이미지로 생성하는 두 가지 방식을 모두 지원하며, 통합된 시각-언어 표현을 기반으로 구축되었습니다. 이를 통해 동일한 모델이 텍스트 입력과 이미지 입력을 모두 이해하고, DiT(Diffusion Transformer) 방식의 확산 백본 네트워크를 통해 정교한 이미지 생성을 수행할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/2bcfV

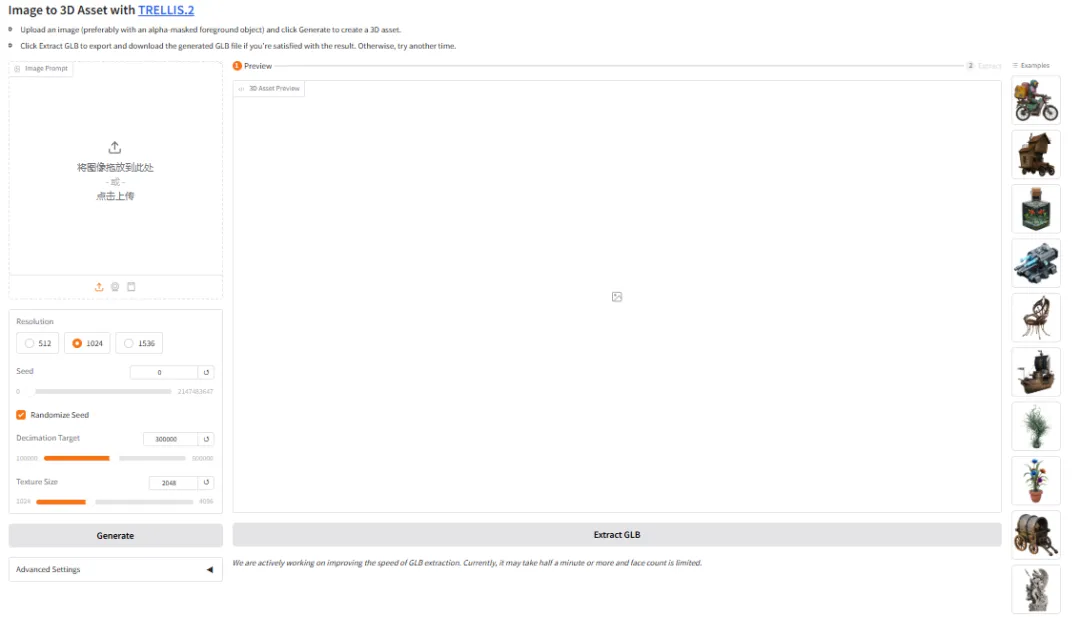
6. TRELLIS.2 3D 데모 생성
TRELLIS.2는 마이크로소프트에서 공개한 오픈 소스 프로젝트로, 40억 개의 파라미터를 가진 대규모 모델입니다. 단일 이미지에서 바로 텍스처가 적용된 3D 에셋을 생성하는 데 중점을 두고 있습니다. 이 모델은 고품질 형상 생성과 재질 생성을 통합하여, 단일 워크플로 내에서 고정밀 형상 재구성 및 3차원 PBR 재질 합성을 완료합니다.
온라인으로 실행:https://go.hyper.ai/drI7I
7.vLLM+Open WebUI 배포 기능Gemma-270m-it
FunctionGemma-270m-it은 Google DeepMind에서 출시한 경량 함수 호출 전용 모델로, 2억 7천만 개의 파라미터를 가지고 있습니다. Gemma 3 270M 아키텍처를 기반으로 구축되었으며, Gemini 시리즈와 동일한 연구 기법을 사용하여 학습되었습니다. 함수 호출 시나리오에 특화된 이 모델은 2024년 8월까지 수집된 6TB의 학습 데이터를 활용하며, 공개 도구 정의 및 도구 사용 상호작용 데이터를 포함합니다. FunctionGemma는 최대 32KB의 컨텍스트 길이를 지원하며, 엄격한 콘텐츠 보안 필터링과 책임 있는 AI 개발 프로세스를 거쳤습니다.
온라인으로 실행:https://go.hyper.ai/pdN7q

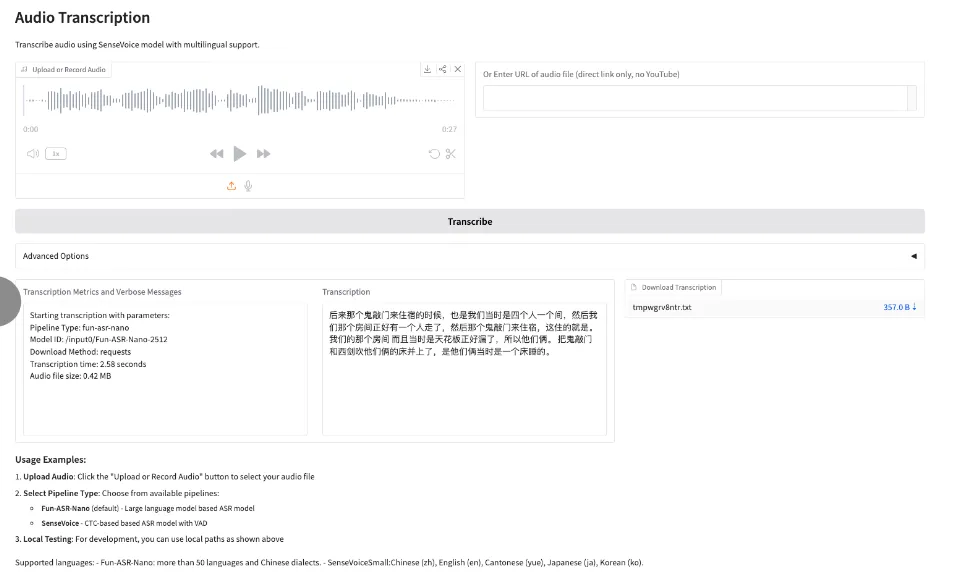
8. Fun-ASR-Nano: 대규모 엔드투엔드 음성 인식 모델
Fun-ASR-Nano는 알리바바 통이 랩에서 출시한 대규모 모델 기반 음성 인식 솔루션으로, Fun-ASR 시리즈의 일부입니다. 이 솔루션은 컴퓨팅 성능이 낮은 환경에서도 작동하도록 설계되었으며, 낮은 지연 시간의 음성-텍스트 변환을 목표로 하고 실제 평가 데이터셋에서의 성능에 중점을 두고 있습니다. 주요 기능으로는 다국어 자유 음성 인식(자유로운 코드 스위칭), 사용자 정의 가능한 핫워드, 환음 억제 등이 있습니다.
온라인으로 실행:https://go.hyper.ai/j7OdD
9. Fara-7B: 효율적인 웹 기반 지능형 에이전트 모델
Fara-7B는 Microsoft Research에서 출시한 최초의 컴퓨터용 에이전트 기반 SLM(소형 언어 모델)입니다. 단 70억 개의 매개변수(7B)만으로 실제 웹 페이지 조작 작업에서 탁월한 성능을 발휘하며, 여러 웹 에이전트 벤치마크에서 최첨단(SOTA) 성능을 달성하고 일부 작업에서는 대규모 모델에 근접하거나 이를 능가합니다.
온라인으로 실행:https://go.hyper.ai/2e5rp
이번 주 논문 추천
1. 시청, 추론 및 검색: 에이전트 기반 비디오 추론을 위한 오픈 웹 기반 비디오 딥 리서치 벤치마크
본 논문은 비디오에서 시각적 기준점을 추출하고, 대화형 검색을 수행하며, 다중 소스 증거 기반의 다중 홉 추론을 수행하는 모델을 요구하는 최초의 비디오 딥러닝 벤치마크인 VideoDR을 구축합니다. 다양한 대규모 모델에 대한 평가 결과, 에이전트 패러다임이 워크플로우 패러다임보다 항상 우수한 것은 아니며, 그 효율성은 긴 검색 과정에서 초기 시각적 기준점을 유지하는 모델의 능력에 달려 있음을 밝혀냈습니다. 본 연구는 목표물의 변화와 장기적인 일관성이 주요 병목 현상임을 규명합니다.
논문 링크:https://go.hyper.ai/uB9jE
2. 베이비비전: 언어를 초월한 시각적 추론
본 연구는 기존의 다층 모델(MLLM)이 언어적 사전 정보에 지나치게 의존하고 있으며, 어린아이들이 지닌 핵심적인 시각 능력을 결여하고 있음을 발견했습니다. 연구팀의 BabyVision 벤치마크 테스트 결과, 최고 성능을 보인 모델(예: Gemini, 49.7점)조차 성인 수준(94.1점)에 훨씬 못 미치는 점수를 기록했으며, 심지어 6세 아동 수준에도 미치지 못해 기본적인 시각 이해 능력에 심각한 결함이 있음을 보여주었습니다. 본 연구는 다층 모델을 인간 수준의 시각 인지 및 추론 능력으로 발전시키는 것을 목표로 합니다.
논문 링크:https://go.hyper.ai/cjtcE
3. STEP3-VL-10B 기술 보고서
본 논문에서는 고성능 오픈소스 멀티모달 기반 모델인 STEP3-VL-10B를 제안합니다. 통합된 사전 학습, 강화 학습, 그리고 혁신적인 병렬 협력 추론 메커니즘을 통해 단 100억 개의 파라미터로 탁월한 성능을 달성합니다. 여러 벤치마크 테스트에서 10~20배 더 큰 거대 모델 및 최상위급 클로즈드 소스 모델과 경쟁하거나 이를 능가하는 성능을 보여주며, 시각 언어 지능 분야에 강력하고 효율적인 벤치마크를 제공합니다.
논문 링크:https://go.hyper.ai/q6kmv
4. 지도를 활용한 사고: 지리 위치 파악을 위한 강화 병렬 지도 증강 에이전트
본 논문에서는 모델이 "지도를 활용하여 사고"할 수 있도록 하는 방안을 제안합니다. 에이전트-맵 루프와 2단계 최적화를 통해 강화 학습과 병렬 테스트 시간 확장을 적용하여 이미지 지리적 위치 정확도를 크게 향상시켰습니다. 새롭게 구축된 실제 이미지 벤치마크인 MAPBench에서, 본 방법은 기존의 오픈소스 및 클로즈드소스 모델들을 능가하며, 500미터 이내 정확도를 8.01 TP3T에서 22.11 TP3T로 획기적으로 향상시켰습니다.
논문 링크:https://go.hyper.ai/Fn9XT
5. 시각-언어 추론을 활용한 도시 사회 의미론적 분할
본 연구는 위성 영상에서 사회적 의미 개체를 분할하는 문제를 해결하기 위해 시각 언어 모델을 활용한 추론 방식의 SocioSeg 데이터셋과 SocioReasoner 프레임워크를 제안합니다. 이 방법은 교차 모달 인식과 다단계 추론을 통해 인간의 주석 작성 과정을 모방하며, 강화 학습을 이용하여 최적화됩니다. 실험 결과, 기존 최첨단 모델들을 능가하는 성능을 보이며, 강력한 제로샷 일반화 능력을 입증했습니다.
논문 링크:https://go.hyper.ai/PW7g4
커뮤니티 기사 해석
1. 독일 연구팀은 단백질 서열, 3D 구조 및 기능적 특성 데이터를 통합하여 메트릭 학습을 기반으로 인간 E3 유비퀴틴 리가아제의 "전체적인 모습"을 구축했습니다.
생물체에서 세포 단백질의 적절한 분해와 재생은 단백질 항상성 유지에 매우 중요합니다. 유비퀴틴-프로테아좀 시스템(UPS)은 신호 전달과 단백질 분해를 조절하는 핵심 메커니즘입니다. 이 시스템에서 E3 유비퀴틴 리가아제는 핵심 촉매 단위로 작용하며, 지금까지 연구된 E3 리가아제들은 높은 이질성을 보여왔습니다. 이러한 배경에서 독일 괴테대학교 연구팀은 "인간 E3 리가아제 콤플렉스(ligome)"를 분류했습니다. 이들의 분류 방법은 메트릭 학습 패러다임을 기반으로 하며, 약지도 학습 방식의 계층적 프레임워크를 활용하여 E3 패밀리와 그 하위 패밀리 간의 진정한 관계를 포착합니다.
전체 보고서 보기:https://go.hyper.ai/zyM1F
2. 예일대학교는 2,000명 이상의 AI 화학 전문가 팀을 구성하여 효율적인 전문화와 최적의 합성 경로 식별을 가능하게 하는 MOSAIC 프로젝트를 제안했습니다.
현대 합성화학은 지식의 급속한 축적과 그 응용 및 변형의 효율성 사이에서 두드러진 모순에 직면해 있습니다. 현재 이 분야의 발전은 주로 두 가지 요인에 의해 제한되고 있습니다. 첫째, 전문가의 경험만으로는 끊임없이 확장되는 반응 공간을 모두 포괄하기 어려워 학제 간 합성 과제에서 시행착오 비용이 많이 발생합니다. 둘째, 인공지능 기술이 빠르게 발전하고 있음에도 불구하고 화학 분야에서 범용 모델의 신뢰성은 여전히 부족합니다. 이러한 배경에서 예일대학교 연구팀은 최근 범용 대규모 언어 모델을 다수의 전문 화학 전문가로 구성된 협업 시스템으로 변환한 MOSAIC 모델을 제안했습니다.
전체 보고서 보기:https://go.hyper.ai/oatBT
3. 온라인 튜토리얼 | GLM-Image: 자기회귀 + 확산 디코더의 하이브리드 아키텍처를 기반으로 지시 사항을 정확하게 이해하고 올바른 텍스트를 작성하는 방법
이미지 생성 분야에서 확산 모델은 안정적인 학습과 뛰어난 일반화 능력 덕분에 점차 주류로 자리 잡고 있습니다. 그러나 "지식 집약적" 시나리오에 직면했을 때, 기존 모델은 명령 이해와 세부적인 특징 추출을 동시에 처리하는 데 어려움을 겪습니다. 이러한 문제를 해결하기 위해 Zhipu는 화웨이와 협력하여 차세대 이미지 생성 모델인 GLM-Image를 오픈소스로 공개했습니다. 이 모델은 Ascend Atlas 800T A2와 MindSpore AI 프레임워크를 기반으로 완전히 학습되었습니다. GLM-Image의 핵심 특징은 언어 모델의 심층적인 이해 능력과 확산 모델의 고품질 생성 능력을 결합한 혁신적인 "자기회귀 + 확산 디코더" 하이브리드 아키텍처(9B 자기회귀 모델 + 7B DiT 디코더)를 채택한 것입니다.
전체 보고서 보기:https://go.hyper.ai/LTojo
4. 칭화대학교와 시카고대학교의 최신 네이처(Nature) 연구 결과! AI 덕분에 과학자들의 승진이 평균 1.37년 빨라지고, 과학 연구 범위가 4.631 TP3T만큼 단축되었습니다.
최근 칭화대학교와 시카고대학교의 연구팀이 네이처(Nature)지에 "인공지능 도구는 과학자들의 영향력을 확대하지만 과학의 집중력을 약화시킨다"라는 제목의 최신 연구 결과를 발표했습니다. 이 연구는 인공지능이 과학에 미치는 근본적인 영향을 업계가 이해할 수 있도록 전례 없는 체계적인 증거를 제공합니다.
전체 보고서 보기:https://go.hyper.ai/0NhLI
인기 백과사전 기사
1. 초당 프레임 수(FPS)
2. 역 정렬 융합 RRF
3. 시각 언어 모델(VLM)
4. 하이퍼네트워크
5. 제한된 관심
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
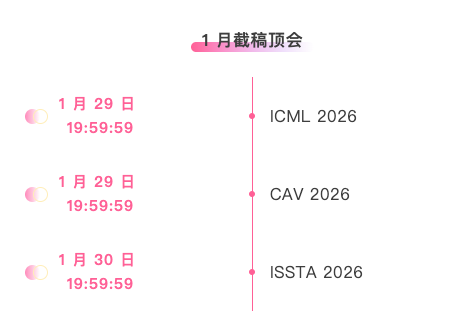
주요 AI 학술대회를 한눈에 확인할 수 있는 플랫폼:https://go.hyper.ai/event
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!








