Command Palette
Search for a command to run...
칭화대학교와 시카고대학교의 최신 연구 결과가 네이처(Nature)에 발표되었습니다! 인공지능(AI)은 과학자들의 경력 발전 기간을 평균 1.37년 단축하고, 과학 연구 범위를 4.631 TP3T만큼 줄여줍니다.

인공지능(AI)의 급속한 발전은 과학 연구의 근본적인 논리를 완전히 바꿔놓고 있습니다. 알파폴드의 정확한 단백질 구조 예측과 노벨상 수상부터, 챗GPT가 자율 실험실에서 대량 실험을 가능하게 하는 사례, 그리고 대규모 언어 모델이 과학 논문 작성 및 결과 추출을 지원하는 사례에 이르기까지, AI는 다양한 방식으로 과학 연구 생산성을 향상시키고 연구의 가시성을 높일 수 있는 엄청난 잠재력을 보여주고 있습니다.
하지만 인공지능 도구는 개별 과학자들의 발전을 촉진하는 동시에, 과학 전반의 발전에 미치는 영향에 대한 심도 있는 고찰을 불러일으키고 있으며, 핵심 쟁점은 개인적 이익과 집단적 이익 사이의 잠재적 갈등에 초점을 맞추고 있습니다.인공지능은 단순히 과학자 개개인의 학문적 발전을 돕는 역할만 하는가, 아니면 과학 분야의 다양화된 탐구와 장기적인 발전을 동시에 이끌어낼 수 있는가?기존 연구들은 인공지능(AI)이 개별 과학자들에게 상당한 이점을 가져다줄 수 있음을 시사하지만, AI 교육 격차로 인한 불평등을 심화시킬 수도 있으며, 인용 패턴의 변화는 연구 환경을 조용히 바꾸고 있다. 그러나 AI가 과학에 미치는 영향에 대한 대규모 실증적 측정은 여전히 부족하며, 연구 생태계에 미치는 구체적이고 역동적인 영향은 아직 명확히 규명되지 않았다.
최근에,칭화대학교와 시카고대학교 연구팀이 '인공지능 도구는 과학자들의 영향력을 확대하지만 과학의 집중력을 약화시킨다'라는 제목의 최신 연구 결과를 네이처(Nature)지에 발표했습니다.1980년부터 2025년까지 발표된 4,130만 편의 자연과학 논문과 537만 명의 과학자 데이터를 분석한 결과, 과학 분야에서 인공지능(AI)의 역할에 대한 놀라운 역설이 드러났습니다. AI는 개별 연구에는 "초고속 가속기" 역할을 하지만, 집단 과학 연구에는 "보이지 않는 축소 장치"로 작용한다는 것입니다. 이 연구는 방대한 데이터셋뿐 아니라 정교한 분석 프레임워크를 활용했다는 점에서 의미가 있습니다.이는 인공지능이 과학에 미치는 근본적인 영향에 대한 업계의 이해를 뒷받침하는 전례 없는 체계적인 증거를 제공합니다.
서류 주소:
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "AI Tools"라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
더 많은 AI 프런티어 논문:
https://hyper.ai/papers
연구 접근 방식: 개인에서 집단에 이르는 완전한 인과 관계 사슬 구축.
본 연구의 최상위 설계는 매우 명확합니다. 단순히 현상을 기술하는 데 그치지 않고, 현상 규명부터 메커니즘 탐구에 이르기까지 완전한 분석 과정을 구축합니다.
출발점: 정확한 식별 (무엇)
이 연구의 첫 번째이자 가장 중요한 단계는 방대한 문헌 중에서 "인공지능을 도구로 사용하는 방법"을 연구하는 문헌과 "인공지능 자체를 연구하는 문헌"을 정확하게 구분하는 것이었습니다. 연구팀은 컴퓨터 과학 및 수학 분야의 연구들을 의도적으로 제외했습니다.이 과정은 생물학, 의학, 화학을 포함한 6개 자연과학 분야에 중점을 둡니다.이 연구는 인공지능이 과학 생산 방식에 미치는 "파급 효과"에 초점을 맞춰야 합니다.
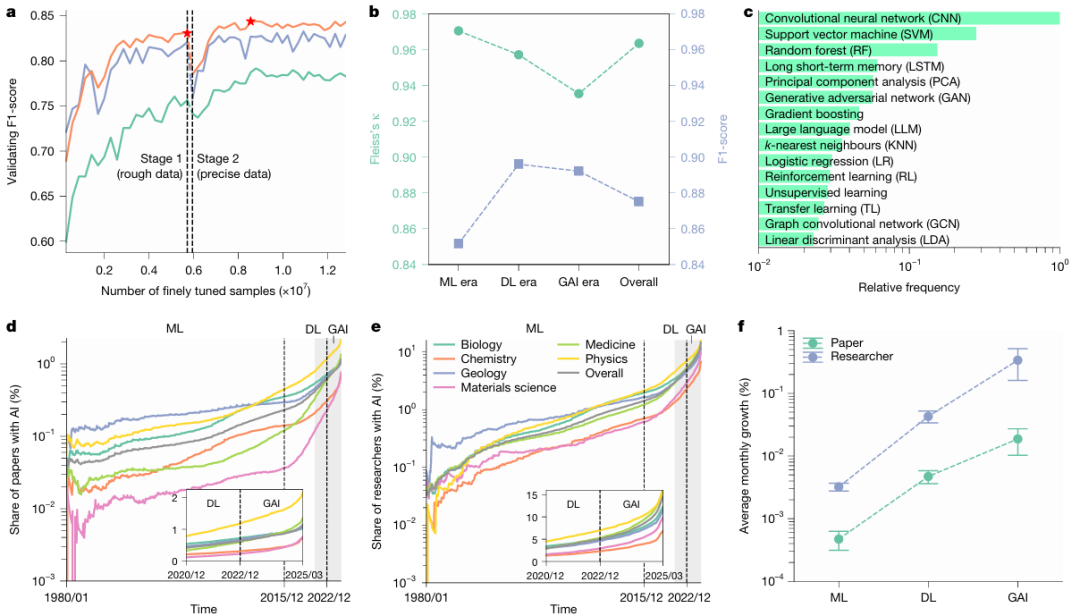
A: BERT 사전 학습 모델의 2단계 미세 조정 과정에서 AI의 논문 인식 성능이 지속적으로 향상되었습니다. 1단계에서는 비교적 불완전한 학습 데이터를 사용했고, 2단계에서는 이 데이터를 기반으로 더욱 정확한 판별 능력을 발전시켰습니다. 연구진은 논문 제목(녹색)과 초록(보라색)을 기반으로 각각 두 개의 모델을 독립적으로 학습시킨 후, 이들을 통합하여 앙상블 모델(주황색)을 구성했습니다. 두 단계에서 가장 우수한 성능을 보인 모델을 동적으로 선택하여(빨간색 별표) 모든 관련 논문을 식별했습니다.
b: 인식 결과의 정확도는 인간 전문가에 의해 평가되었습니다. AI 개발의 세 단계를 포괄하는 샘플에 대해 전문가들 간에 높은 수준의 일치도(κ ≥ 0.93)가 나타났습니다. 이 모델은 전문가가 주석을 단 데이터를 사용한 검증에서 최소 0.85의 F1 점수를 기록하며 높은 정확도를 보였습니다.
c: 선택된 AI 개발 기간 동안 각 분야별 상위 15개 AI 방법의 상대적 채택 빈도.
d, e: 1980년부터 2025년까지 머신러닝(ML), 딥러닝(DL), 생성형 인공지능(GAI)의 세 시기로 나누어, 선정된 과학 분야에서 인공지능을 활용한 논문 수(d, n = 41,298,433)와 인공지능을 활용하는 연구자 수(e, n = 5,377,346)의 증가 추이를 나타낸 그래프입니다. 세로축은 로그 스케일입니다.
f: 머신러닝, 딥러닝, 인공지능(GAI) 기간 동안 선택된 모든 분야에 걸쳐 인공지능 논문 수와 연구자 수의 월평균 증가율(n = 543개 월별 관측치). 오차 막대는 평균을 중심으로 하는 99% 신뢰구간(CI)을 나타냅니다.
개인 수준: 개인의 영향 정량화
정확한 식별을 바탕으로, 이 연구는 먼저 "개별 과학자들에게 어떤 이점이 있는가?"라는 질문에 답을 제시했습니다.연구팀은 연구자들의 연간 논문 발표, 인용 횟수, 그리고 경력 변화(초급 연구원에서 프로젝트 리더로)를 추적하여 놀라운 데이터를 얻어냈습니다.논문 발표 수는 3.02배, 인용 횟수는 4.84배, 경력 발전 기간은 1.37년 더 길었습니다.
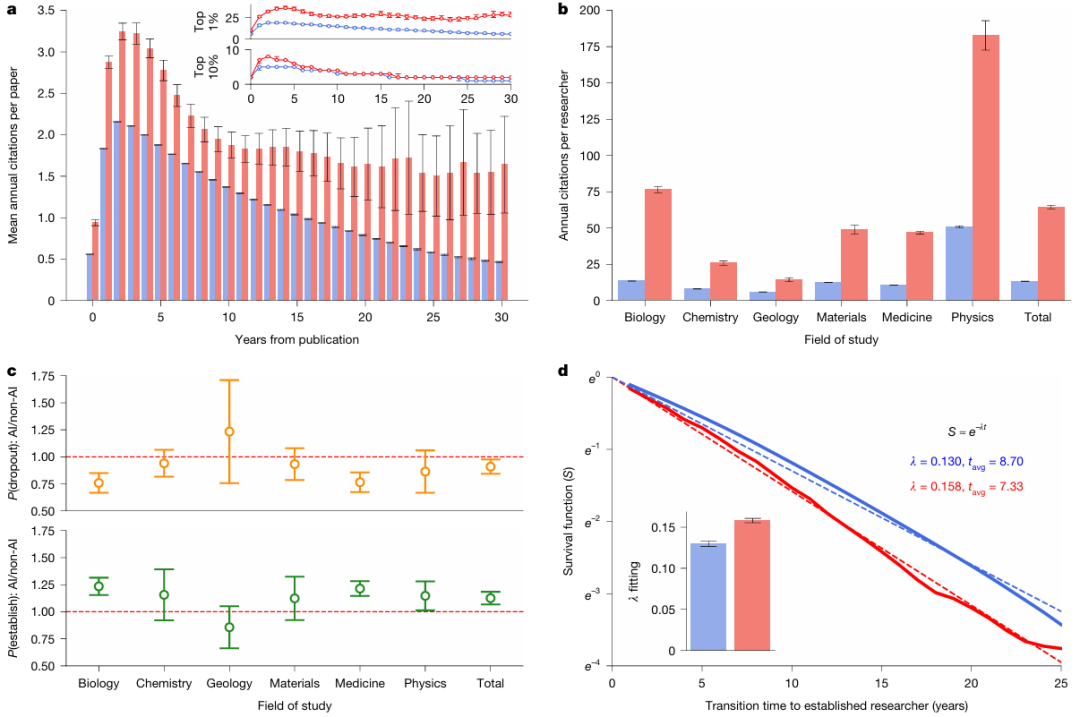
a: 인공지능 논문(빨간색)과 비인공지능 논문(파란색)의 출판 후 연평균 인용 횟수(삽입 그림은 각각 상위 11개 TP3T 분위수와 상위 101개 TP3T 분위수를 보여줌, n = 27,405,011). 일반적으로 인공지능 논문이 더 많은 인용을 받는 것을 알 수 있다.
b: AI를 사용한 연구자와 사용하지 않은 연구자 간의 연평균 인용 횟수 비교(P < 0.001, n = 5,377,346). AI를 사용한 연구자가 사용하지 않은 연구자보다 연평균 4.84배 더 많은 인용을 받았다.
c: 젊은 과학자들 사이에서 AI를 도입한 연구자와 도입하지 않은 연구자 간의 역할 전환 확률을 비교했습니다(모든 관찰 기간은 n=46년). AI를 도입한 젊은 과학자들은 AI를 도입하지 않은 동료들에 비해 경험 많은 연구자가 될 가능성이 더 높았고, 학계를 떠날 가능성은 더 낮았습니다.
d: 주니어 연구자에서 시니어 연구자로의 전환에 대한 생존 함수(P < 0.001, n = 2,282,029). 이 생존 함수는 지수 분포에 잘 부합하며, 이는 AI를 사용하는 주니어 과학자들이 이 전환을 더 빨리 완료함을 나타냅니다. 모든 패널에서 오차 막대는 99% 신뢰 구간(CI)을 나타냅니다. a의 삽입 그림은 1% 및 10% 분위수를 중심으로 하고 있으며, 나머지 패널은 평균을 중심으로 합니다. 모든 통계 검정은 양측 t-검정을 사용하여 수행되었습니다.
집단적 차원: 구조적 변화의 드러남
이후 연구 관점은 미시적 개인에서 거시적 생태계로 전환되었고, "모두가 AI의 혜택을 누릴 때 과학 전체에는 어떤 변화가 일어나는가?"라는 더욱 심오한 질문이 제기되었습니다. 이를 위해 연구팀은 두 가지 혁신적인 집단 지표를 도입했습니다. 첫 번째는 연구 주제의 포괄 범위를 측정하는 지식 범위(Knowledge Extent)이고, 두 번째는 후속 연구 간의 상호작용 밀도를 측정하는 후속 참여(Follow-on Engagement)입니다. 연구진은 동일한 원 연구를 인용한 후속 연구 결과를 전체적으로 분석하여 상호 인용 밀도를 계산했습니다. 그 결과, AI 연구에서 후속 상호작용이 약 221 TP3T 감소한 것으로 나타났습니다.
원인 규명: 근본적인 메커니즘 탐구 (이유)
마지막으로, 연구는 현상에만 그치지 않았습니다.대신, 이 책은 이러한 "팽창-수축" 역설의 근본적인 메커니즘을 파헤칩니다.연구팀은 인기, 초기 영향력, 자금 지원 우선순위와 같은 요소를 배제함으로써 가장 근본적인 이유, 즉 데이터 가용성을 지적했습니다. 인공지능은 자연스럽게 데이터가 풍부하고 모델링이 용이한 성숙한 분야에 집중되기 때문에 집단적인 관심이 한곳에 쏠리고 탐구할 수 있는 공간이 줄어드는 결과를 낳습니다.
"무엇"에서 "왜"로 이어지는 이 완벽한 논리적 연결고리는 연구 결론을 매우 설득력 있게 만듭니다.
연구 주요 내용: 핵심 문제를 직접적으로 해결하는 세 가지 주요 혁신
키워드 매칭을 넘어선 AI 기반 문서 인식 방법:
기존 연구에서는 인공지능 논문을 선별하기 위해 "신경망"과 같은 키워드에 의존하는 경우가 많지만, 이는 편향에 매우 취약합니다. 본 연구에서는 논문 제목과 초록을 각각 사용하여 2단계로 미세 조정하는 BERT 모델을 활용하고, 이 결과를 통합하여 최종 판단을 내립니다.이 방법은 전문가들의 블라인드 평가 후 F1 점수 0.875라는 높은 점수를 획득했습니다.이로써 전체 연구를 위한 견고하고 신뢰할 수 있는 데이터 기반이 마련되었습니다.
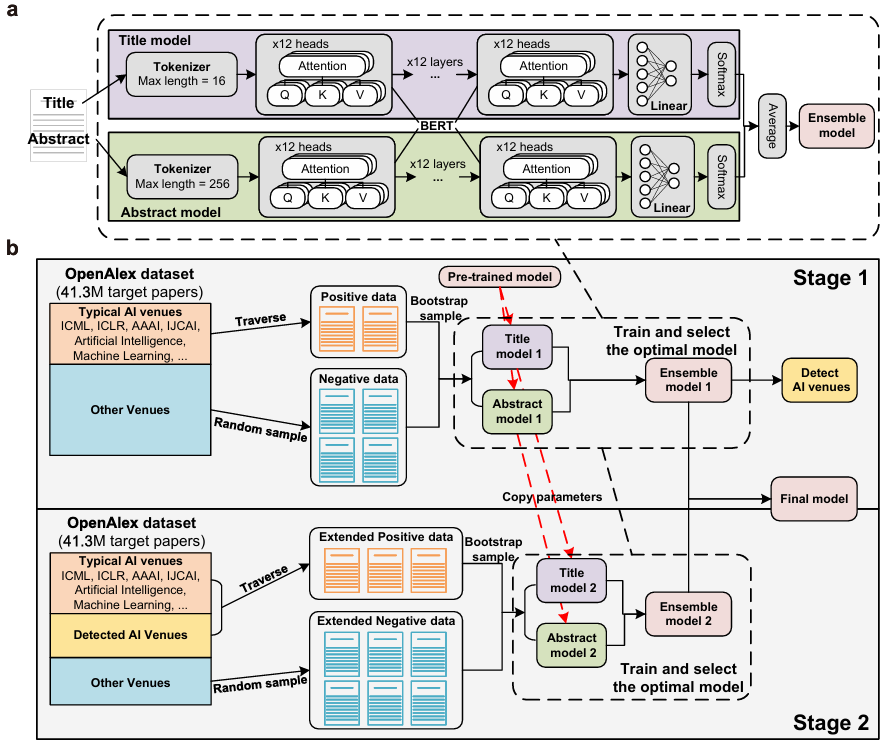
a: 배포된 언어 모델의 개략도. 이 모델은 토크나이저, 핵심 BERT 모델 및 선형 레이어로 구성됩니다.
b: 2단계 모델 미세 조정 과정의 개략도. 연구자들은 각 단계에서 긍정적 및 부정적 표본 데이터를 구성하기 위한 구체적인 방법을 설계했다.
지식의 폭을 측정하는 획기적인 정량적 지표:
특정 분야의 "탐구 범위"를 어떻게 측정할까요? 연구팀은 과학 문헌 분석을 위해 특별히 설계된 임베딩 모델인 SPECTER 2.0을 사용했습니다.각 논문은 768차원의 의미 벡터 공간에 매핑됩니다.논문 모음의 "지식 폭"은 해당 공간에서 논문들이 차지하는 최대 직경으로 정의됩니다. "지식 다양성"이라는 추상적인 개념을 정확하게 계산 가능한 기하학적 거리로 변환하는 이 접근 방식은 계량과학 분야에서 중요한 혁신입니다.
'외로운 밀집'이라는 학문적 상호작용 패턴을 밝히다:
연구 결과에 따르면, 동일한 AI 논문을 인용한 후속 연구들은 22% 기준으로 서로를 인용할 가능성이 낮아지는 것으로 나타났습니다. 이는 과학 연구 환경이 '네트워크형'이라기보다는 '별 모양'으로 고립되어 있음을 시사합니다. 즉, 수많은 연구가 마치 행성처럼 몇몇 '별'과 같은 AI 성과를 중심으로 집중되지만, 다른 연구들과의 수평적 연결은 부족한 것입니다. 이러한 '고립된 군중'의 상태는 과학적 창의성이 억압되고 있다는 위험한 신호입니다.
벡터 공간을 이용하여 과학의 폭을 어떻게 "측정"할 수 있을까요?
이 논문 전체가 웅장한 건물이라면, 그 핵심 기술은 의심할 여지 없이 SPECTER 2.0 임베딩 모델과 지식 확장이라고 할 수 있습니다.
전체 과학 지식 체계를 광활한 우주라고 상상해 보세요. SPECTER 2.0의 역할은 이 우주에 대한 정확한 좌표계를 구축하는 것입니다. 수천만 편의 논문과 그 인용 관계를 연구하여 각 논문을 768차원의 좌표점(즉, 벡터)으로 변환합니다. 이 고차원 공간에서 주제가 유사한 논문들은 좌표점이 서로 가깝고, 주제가 매우 다른 논문들은 좌표점이 멀리 떨어져 있습니다.
이 좌표계를 이용하면 연구 분야의 "영역"을 어떻게 측정할 수 있을까요? 연구팀의 접근 방식은 매우 독창적입니다.
견본 추출: 특정 분야(예: AI 기반 생물학 연구)에서 논문들이 무작위로 선정됩니다.
위치: SPECTER 2.0을 사용하여 이 모든 논문을 768차원의 지식 우주에 투영하여 좌표점 집합을 생성했습니다.
중심을 찾으세요: 이 모든 점들의 기하학적 중심(중심점)을 계산하세요.
지름을 측정하세요: 중심에서 가장 먼 지점으로부터의 거리를 이 논문 묶음의 "지식의 폭"으로 정의합니다.
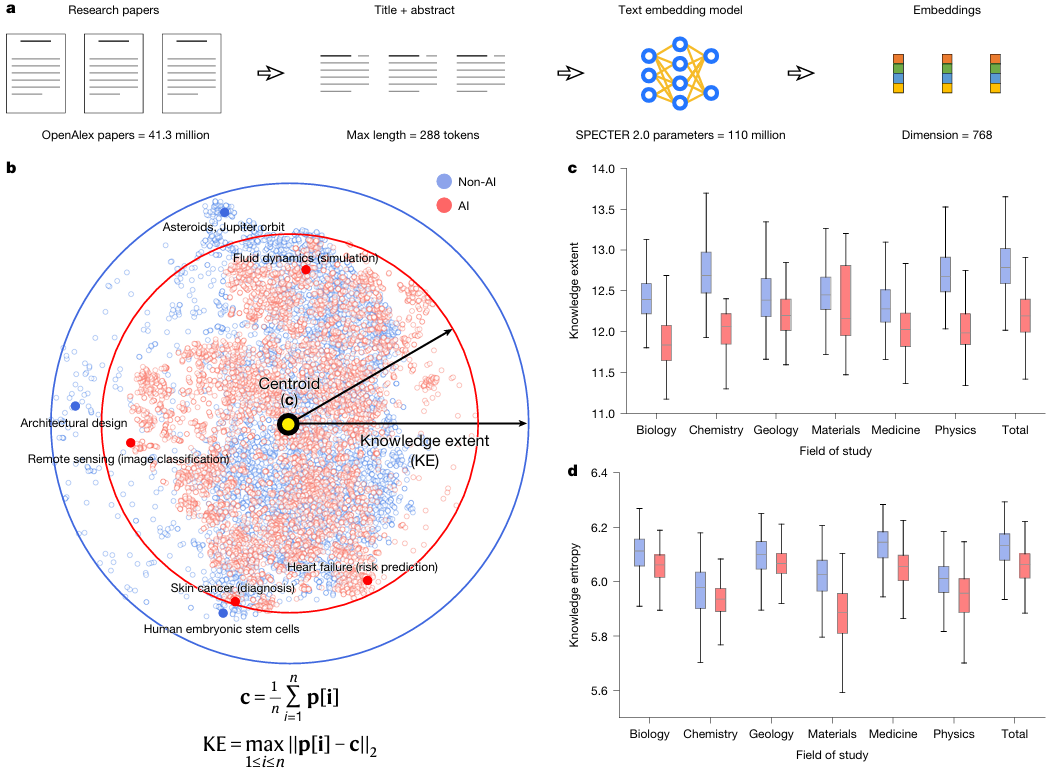
a: 연구원들은 사전 훈련된 텍스트 임베딩 모델을 사용하여 연구 논문을 768차원 벡터 공간에 임베딩하고 해당 공간 내에서 논문에 담긴 지식의 폭을 측정했습니다.
b: 시각화를 용이하게 하기 위해 연구진은 t-분포 랜덤 이웃 임베딩(t-SNE) 알고리즘을 사용하여 무작위로 선택된 10,000편의 논문(그중 절반은 인공지능 논문)의 고차원 임베딩을 2차원 공간으로 압축했습니다. 실선 화살표와 원형 경계에서 볼 수 있듯이, 인공지능 논문(차원 축소 없이 원래 공간에서 지식 범위를 계산한 논문)은 자연과학 전반에 걸쳐 더 작은 지식 범위를 나타냅니다. 또한, 인공지능 논문은 지식 공간에서 더 높은 수준의 클러스터링을 보여주며, 이는 특정 문제에 더 집중하고 있음을 시사합니다.
c: 학문 분야별 AI 논문과 비AI 논문의 지식 범위 비교(P < 0.001, 학문 분야별 표본 수 n = 1,000개). 결과는 AI 연구가 더 좁은 지식 영역에 집중되어 있음을 보여줍니다.
d: 학문 분야별 AI 논문과 비AI 논문의 지식 엔트로피 비교(P < 0.001, 학문 분야별 n = 1,000개 샘플). AI 연구의 지식 엔트로피가 더 낮은 것으로 나타났다. 패널 c와 d에서 상자 그림은 중앙값을 중심으로 하며, 상자의 상한과 하한은 각각 제1사분위수(Q1)와 제3사분위수(Q3)를 나타내고, 수염은 사분위 범위의 1.5배를 나타낸다. 모든 통계 검정은 중앙값 검정을 사용하여 수행되었다.
이 방법을 사용하여 연구팀은 AI 연구와 비AI 연구의 "영역" 규모를 공정하게 비교할 수 있었습니다. 결과는 AI 연구의 "지식 범위" 중앙값이 비AI 연구보다 4.631 TP3T 더 작다는 것을 분명히 보여줍니다. 이는 AI에 힘입어 과학자들이 한목소리로 더 작고 집중된 지식 영역으로 몰려들고 있음을 의미합니다.
또한, 해당 연구는 인용 분포를 분석하여 AI 연구가 더 강한 "매튜 효과"를 나타낸다는 것을 발견했습니다.상위 22.21 TP3T AI 논문은 총 801 TP3T의 인용 횟수를 기록했으며, 이들의 인용 불평등도(지니 계수 0.754)는 비AI 연구 논문(0.690)보다 유의미하게 높았습니다.
결론
요약하자면,이 기술적 해결책은 "과학이 더 좁아졌는가?"라는 질문에 답할 뿐만 아니라, 연구자들에게 "얼마나 좁아졌는가?", "어떤 차원에서 좁아졌는가?", 그리고 "좁아진 후 어떤 구조가 형성되었는가?"라는 질문에 더욱 정확하게 답해줍니다.이는 더 이상 막연한 우려가 아니라, 데이터를 통해 정확하게 묘사할 수 있는 현실입니다.
이 연구의 가치는 인공지능을 부정하는 데 있는 것이 아니라, 연구자들이 인공지능을 수용할 때 발생할 수 있는 숨겨진 비용을 가장 엄밀한 방식으로 밝히는 데 있다. 이 연구는 진정한 과학적 지능은 단순히 효율성을 높이는 "도구"가 아니라 인간 인지 능력의 한계를 확장하는 "파트너"가 되어야 한다는 점을 연구자들에게 상기시켜 준다.