Command Palette
Search for a command to run...
카네기 연구소의 학제간 연구팀은 406개의 샘플을 기반으로 한 랜덤 포레스트 모델을 사용하여 33억 년 전까지 거슬러 올라가는 생명체의 흔적을 성공적으로 포착했습니다.

지구 표면 깊숙이 묻힌 고대 암석층의 유기 분자를 해독하는 것은 지구의 역사를 이해하고 생명 진화를 연구하는 데 매우 중요합니다. 생명 활동의 잠재적 증거인 이 유기 분자들은 지구 생명 탄생의 미스터리, 특히 광합성의 기원과 대기 산화와의 연관성을 밝히는 데 도움이 될 뿐만 아니라 생명 진화의 시간적 공백을 메우고 초기 지구 생태계 형성을 이해하는 데 중요한 단서를 제공합니다. 그러나 눈에 보이는 화석을 형성하는 대형 유기체와는 달리, 이러한 "증인"들은 지질학적 침식으로 인해 흔적도 없이 오래전에 사라졌습니다.따라서 심하게 분해된 유기물 잔해에서 생명의 흔적을 찾아내는 것은 고생물학과 지구과학 분야에서 중요한 과제가 되었습니다.
오랫동안 과학자들은 초기 생명체를 탐구하기 위해 주로 고생물학적 화석 형태와 동위원소 분석에 의존해 왔습니다. 그러나 이러한 방법들은 시료 보존 상태에 따라 한계가 있는 경우가 많습니다. 예를 들어, 지질이나 포르피린과 같은 복잡한 분자의 명확한 흔적은 약 16억 년 전까지만 추적할 수 있는데, 이는 다른 증거들이 제시하는 생명 기원 시기보다 훨씬 짧습니다. 더욱이, 시생대 암석에 나타나는 유기 분자의 기원은 불분명하고, 생물 기원과 비생물 기원의 경계를 명확히 구분하기 어렵기 때문에 많은 중요한 발견들이 추측 단계에 머물러 있습니다.
이 교착 상태를 해결하기 위해카네기 과학 연구소의 지구 및 행성 연구소가 주도하고 전 세계 여러 대학 및 연구 기관으로 구성된 다학제 팀과의 협력을 통해 "기술 융합" 솔루션이 제안되었습니다.연구팀은 먼저 열분해-가스 크로마토그래피-질량 분석법(py-GC-MS)을 사용하여 분석한 다음, 지도 학습 기법을 이용하여 분석된 데이터를 분류하고 구별함으로써 혼란스러운 분자 조각 속에 숨겨진 고대 생명의 흔적을 포착했습니다.
실험 결과, 이러한 기술들을 통합한 모델은 예상보다 뛰어난 성능을 보였습니다. 이 모델은 1001 TP3T의 해상도로 현대 유기물과 운석/화석 유기물을 정확하게 구분할 수 있으며, 971 TP3T의 정확도로 화석 식물 조직과 운석 유기물을 구분할 수 있습니다. 더욱 중요한 것은, 연구팀이 이 모델을 미지의 시료에 적용했을 때, 약 33억 3천만 년 전의 고원생대와 약 25억 2천만 년 전의 신원생대 암석에서 생물 기원 분자 집합체의 흔적을 성공적으로 식별해냈다는 점입니다. 이는 더 오래되고 보존 상태가 좋지 않은 생명체의 흔적을 탐색하는 데 새로운 방법론적 기반을 제공합니다.
"열분해-GC-MS 및 지도 학습을 통해 확인된 시생대 암석의 생명체에 대한 유기 지구화학적 증거"라는 제목의 관련 연구는 미국 국립과학원회보(PNAS)에 게재되었습니다.
연구 하이라이트:
* 제안된 기술 융합 접근 방식은 기존의 한계를 뛰어넘어, 열분해 가스 크로마토그래피-질량 분석법과 머신 러닝을 결합함으로써 분해 후 분자를 구별하는 핵심 과제를 극복합니다.
* 연구 샘플은 현대 생명체부터 수십억 년 전의 암석, 지구 생물부터 외계 운석에 이르기까지 광범위한 범위를 포괄하여 모델 훈련을 위한 종합적인 비교 자료를 제공합니다.
* 실험 결과는 이 방법이 과학적으로 타당하고 미래지향적임을 보여줍니다. 이 방법은 시생대 암석에서 생명 흔적의 존재를 입증할 뿐만 아니라, 알려지지 않은 다른 생명 흔적을 탐사하는 새로운 방법도 제시합니다.

서류 주소:
https://www.pnas.org/doi/10.1073/pnas.2514534122
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "열분해 가스 크로마토그래피"라고 답글을 달면 전체 PDF 파일을 받으실 수 있습니다.
데이터셋: 406개의 샘플로 구성되어 있으며, 광범위한 범위를 포괄하여 모델의 성능을 종합적으로 비교할 수 있도록 합니다.
연구팀은 약 38억 년 전(시생대)부터 1천만 년 전(신생대)까지의 고대 및 현대, 생물학적 및 비생물학적 출처를 아우르는 다양한 유기 분자를 포함하는 총 406개의 천연 및 합성 샘플을 분석했습니다. 샘플 유형에는 퇴적암(141개), 화석(65개), 현대 생물(123개), 운석(42개, 그중 39개는 탄소질 콘드라이트), 실험실에서 합성한 유기 분자(35개 그룹)가 포함되어 머신러닝 분석을 위한 풍부하고 다양한 데이터 기반을 제공했습니다.
이 406개 샘플 중 272개는 계통 발생 관계 및 생리적 특성을 기반으로 9개 범주로 명확하게 구분되었으며, 아래 그림과 같이 지도 학습 훈련(75%) 및 테스트(25%)에 사용되었습니다.
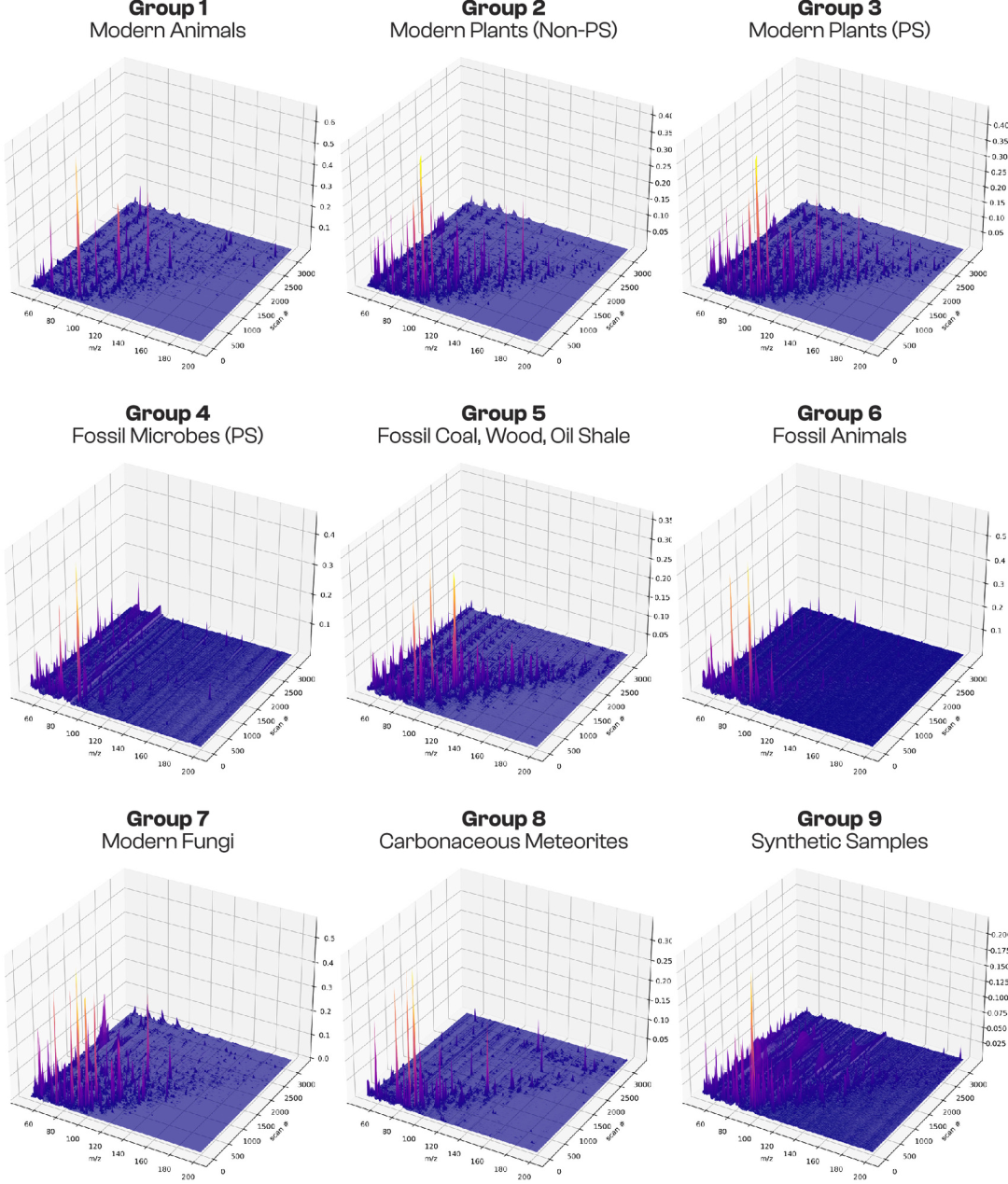
* 현대 동물:현대 비광합성 종속영양 생물의 유기 분자적 특성은 최근에 죽은 다양한 무척추동물과 척추동물로부터 얻어졌다. 표본 크기는 21이었다.
* 현대 식물(비광합성 조직):본 연구는 식물의 뿌리, 씨앗, 꽃, 열매, 수액 등 광합성을 하지 않는 조직과 분비물을 포함하여 식물의 다양한 기능 조직 간의 분자적 차이를 조사하였다. 표본 크기는 40개였다.
* 현대 식물(광합성 조직):본 연구는 주로 잎과 기타 광합성 조직에 초점을 맞추어 광합성 생체 분자의 특성에 대한 현대적 참고 자료를 제공하였다. 표본 크기는 36개였다.
* 광합성 남세균/조류 화석을 포함하는 퇴적암:염산(HCl)과 불산(HF)을 이용한 산 용해로 풍부해진 유기 잔류물은 셰일이나 부싯돌에 존재하며, 암석에는 남세균이나 조류 화석의 확실한 형태학적 증거가 있어 고대 광합성 미생물의 분자 기록으로 활용될 수 있다. 표본 크기는 24개였다.
* 화석화된 나무, 석탄, 그리고 오일 셰일:이 샘플들은 주로 현생누대(5억 4천1백만 년 전 이전)의 것이지만, 고대 고등 식물과 탄화수소의 분자 보존 특성을 보여주는 슝가이트와 안트락솔라이트와 같은 원생누대의 복합 탄화수소 함유 퇴적물도 포함합니다. 총 샘플 수는 49개입니다.
* 동물 화석:모든 샘플은 현생누대 시대의 것으로, 탄화된 어류 화석과 삼엽충 화석, 그리고 신생대 복족류 껍데기에서 추출한 껍데기 결합 단백질 등 고대 동물의 유기 분자 잔해를 포함합니다. 총 9개의 샘플이 있습니다.
* 현대 균류:이 연구에는 다양한 목재 부패균과 효모가 포함되어 있으며, 진핵생물 중 식물과 동물 이외의 그룹에 대한 분자 데이터의 공백을 메웁니다. 표본 크기는 16개입니다.
* 운석:수집된 시료는 주로 탄소질 운석(총 39개)으로, 화학적 용해 및 유기 분자 집합체의 농축 과정을 거쳐 비생물학적 유기물의 명확한 기준이 되었습니다. 총 42개의 시료가 수집되었습니다.
* 실험실에서 합성한 샘플:본 연구에서는 마이야르 반응 및 포르모스 반응과 같은 실험실 합성 과정을 통해 얻은 유기 분자 집합체를 사용하여 비생물학적으로 생성된 유기 물질의 분자적 특성을 모방하였다. 표본 크기는 35개였다.
게다가,연구팀은 특정 머신러닝 모델을 위해 두 개의 추가 보조 클래스 샘플을 설정했습니다.광합성 생물과 비광합성 생물을 구분하기 위해 총 세 가지 샘플을 사용했습니다. 광합성 원핵생물에 대한 자료를 보완하기 위해 현대 남세균 샘플 두 개를 사용했고, 비광합성 고세균에 대한 자료를 보완하기 위해 현대 호염성 세균(할로박터) 샘플 한 개를 사용했습니다.
마지막으로, 나머지 131개 샘플은 주로 유기물이 풍부한 시생대 또는 원생대 퇴적암에서 유래한 산 용해성 농축 잔류물이었다. 이 샘플에 포함된 유기 분자의 기원과 생리적 특성은 알려지지 않았거나 논란의 여지가 있지만, 이는 본 실험에서 기계 학습 분석의 적용 가능성을 검증하는 새로운 분류 테스트 영역을 제공한다.
연구 방법 및 모델: py-GC-MS와 머신러닝의 심층 통합
이 실험은 크게 네 단계로 요약할 수 있습니다.
* 첫 번째 단계는 다양한 현대 및 고대, 생물학적 및 비생물학적 출처에서 탄소를 함유한 406개의 서로 다른 샘플을 수집하는 것이었습니다.
두 번째 단계는 운석과 고대 퇴적암에서 탄소질 고분자 물질을 추출하는 것입니다.
* 세 번째 단계는 열분해 가스 크로마토그래피와 전자 충격 이온화 질량 분석기를 결합하여 각 샘플을 분석하는 것입니다.
* 4단계: 실험 샘플 분석 부분집합(머신러닝 방법)의 데이터를 사용하여 지도 학습 방식의 랜덤 포레스트 모델을 학습시킵니다.
이 방법의 가장 중요한 측면은 py-GC-MS 분석 기술과 머신러닝 방법을 "기술적으로 통합"하는 것입니다.
첫째, 분석 기법이 있습니다.본 실험에서 연구팀은 Agilent 8860 시리즈 가스 크로마토그래프와 Agilent 5999 사중극자 질량 분석기가 결합된 CDS 6150 열 프로브를 사용했습니다. 크로마토그래피 분리는 Agilent 30 M 5% 페닐 PDMS 컬럼을 이용하여 수행했습니다. 열분해 생성물은 헬륨을 이용하여 즉시 가스 크로마토그래피 컬럼으로 이송하여 분석했습니다. 구체적인 절차는 다음과 같습니다.
* 열분해:연구진은 미리 가열된(공기 중에서 550°C에서 3시간 동안 연소시킨) 석영관에 시료(10-100μg)를 넣은 다음, 이를 열 탐침 코일에 넣어 급속 열분해를 실시했습니다. 이때 시료를 500°C/s의 속도로 610°C까지 가열하고 10초 동안 유지했습니다.
* 크로마토그래피:초기 온도는 50℃로 1분간 유지한 후, 5℃/min의 속도로 300℃까지 상승시켜 15분간 유지하였다. 운반 기체로는 초고순도 헬륨(UHP 5.5 등급)을 사용하였다.
질량 분석법:이 장비는 250℃에서 70eV의 이온화 에너지로 전자 이온화(EI) 모드에서 작동하며, 스캔 범위는 m/z 45-700, 스캔 속도는 0.80초/10진수, 스캔 간 지연 시간은 0.20초입니다.
저분자 휘발성 물질(예: CO₂ 및 H₂O)의 간섭을 피하기 위해 실험 시작 후 처음 2분 동안은 MS 데이터를 수집하지 않았습니다. 또한, 크로마토그램에서 흔히 나타나는 오염물질(예: 팔미트산 및 스테아르산)의 용출 영역에서 발생하는 신호를 제외해야 했습니다. 각 샘플은 2차원 행렬(3,240개의 용출 시간 간격 x 150개의 m/z 값)로 변환되었고, 489,240개 원소의 신호 강도가 질량과 유지 시간의 함수로 기록되었습니다. 표준화 및 평활화 과정을 거쳐 최종적으로 8,149개의 유효 특징점이 남았습니다.
둘째로, 모델 선택이 사용되었습니다. 본 실험에서는 랜덤 포레스트 방법을 사용했습니다.이 방법은 높은 정확도, 낮은 계산 비용, 그리고 해석 용이성을 갖춘 앙상블 분류 방법입니다. 여러 개의 비상관 결정 트리를 구성하여 과적합 위험을 줄입니다. 이 모델은 레오 브레이먼의 저서 "랜덤 포레스트(Random Forests)"에서 언급된 랜덤 포레스트 모델을 채택합니다.
연구진은 학습된 기계 학습 모델에 대해 두 가지 검증 전략을 사용했습니다. 첫째, 751개의 TP3T 훈련 데이터셋과 251개의 TP3T 테스트 데이터셋을 층화 무작위 샘플링하여 두 그룹에서 각 클래스 샘플의 비율이 동일하도록 했습니다. 둘째, 10겹 교차 검증을 10회 반복하여 모델의 일반화 능력을 평가하고, 무작위 오류를 줄이기 위해 평균 정확도를 계산했습니다.
이 실험에서는 현대 생물 기원 물질(식물과 동물)과 비생물 기원 물질(운석 + 합성 시료), 고대 생물 기원 물질(생물 기원이 알려진 퇴적암)과 비생물 기원 물질, 고대 생물 기원 물질(화석화된 나무와 석탄 제외)과 비생물 기원 물질, 그리고 광합성 시료와 비광합성 시료를 구분하기 위해 네 가지 모델을 테스트했습니다.
실험 결과: 다중 모델, 다차원적 접근 방식을 통해 기술 통합의 실현 가능성을 검증하였다.
초기 테스트에서 연구원들은 비교적 균형 잡힌 표본 크기를 가정하고, 9개의 알려진 속성을 가진 36가지 표본 쌍 조합을 분류하기 위해 랜덤 포레스트 모델을 사용했습니다.36개의 테스트 중 25개는 훈련 세트와 테스트 세트 모두에서 90% 이상의 정확도를 보였으며, 그중 19개는 95% 이상의 정확도를 보였습니다.모든 결과는 아래 표에 나와 있습니다.
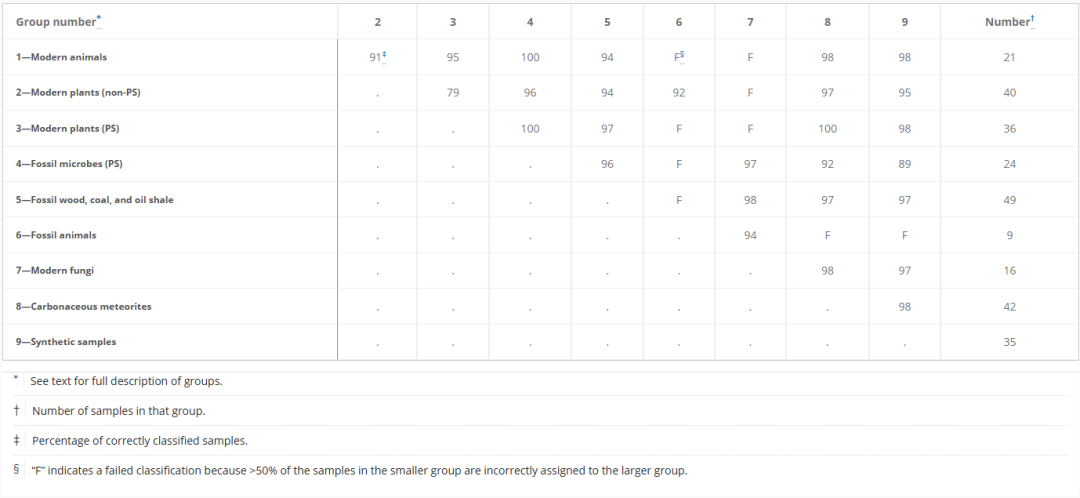
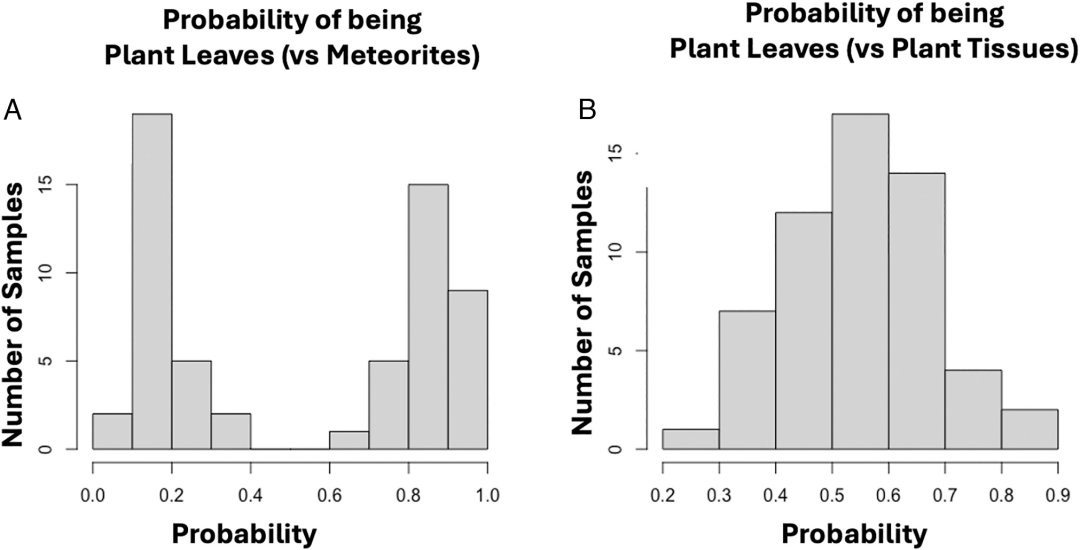
이 논문은 해당 방법을 더욱 명확히 설명하기 위해 다양한 사례 연구를 통해 효율성과 비효율성의 차이를 보여줍니다. 예를 들어, 3번과 8번 그룹, 즉 현대 식물(광합성 조직)과 운석의 경우를 살펴보겠습니다.이 방법은 100%의 정확도로 식물과 운석을 구별했습니다.모든 샘플의 분류 확률이 0.6보다 크거나 0.4보다 작았으며, 이는 분자적 특성에 유의미한 차이가 있음을 나타냅니다. 아래 그림 A를 참조하십시오.
또한, 생물 기원 샘플과 비생물 기원 샘플을 구분하는 것은 고생물학 및 우주생물학 연구의 핵심 목표입니다. 이를 위해 연구팀은 서로 다른 샘플 조합에 대해 생물 기원과 비생물 기원을 구분하는 능력을 검증하기 위해 세 가지 서로 다른 랜덤 포레스트 모델을 구축하고 비교했습니다.
구체적으로, 모델 # 1에서 연구팀은 1, 2, 3군과 8, 9군에서 각각 97개와 77개의 샘플을 사용하여 현대 식물과 동물, 그리고 비생물적 원천(운석 및 합성 샘플)을 구별하는 능력을 테스트했습니다.전체 정확도는 981 TP3T에 달했습니다.AUC 값은 훈련 세트에서 0.977, 테스트 세트에서 1.000이며, 10겹 교차 검증의 정확도는 98.3%입니다.
모델 # 2는 주로 고대 생물 시료와 유기물이 풍부한 비생물 시료를 구별하는 능력을 검증하는 데 사용되었습니다. 대조군은 4군과 5군, 그리고 8군과 9군에서 각각 87개와 77개의 시료를 추출하여 사용했습니다.87개의 생물 기원 고대 유기물 샘플 중 83개가 정확하게 분류되어 95.1 TP3T의 정확도를 달성했습니다.또한, 이 샘플 중 70개(80%)는 생물학적 기원 분류 확률에 대한 신뢰도가 0.6보다 높았습니다. 비생물학적 샘플 69개가 정확하게 분류되어 90%의 정확도를 달성했습니다. AUC 값은 훈련 세트에서 0.924, 테스트 세트에서 0.926이었으며, 10겹 교차 검증 정확도는 92.7%였습니다.
생물 기원이 불분명한 고대 퇴적암 109개에 모델 # 2를 적용했을 때, 68개 샘플(61%)에서 생물 기원 분류 확률이 0.50보다 크고, 32개 샘플에서 생물 기원 분류 확률이 0.60보다 큰 것으로 나타났습니다.
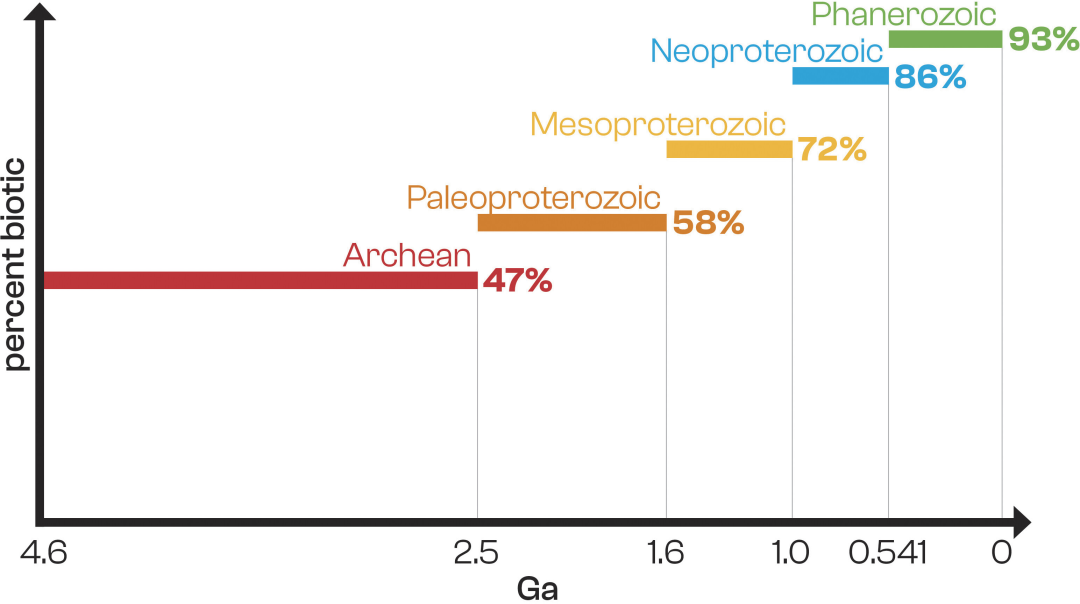
또한, 분석 결과 지질학적 연대에 따른 생물 기원 시료의 비율이 감소하는 추세가 나타났습니다. 82개의 현생누대 시료 중 76개(93%)는 생물 기원이었고, 43개(73%)는 원생누대, 그리고 21개(47%)만이 시생누대(45개 시료)에서 유래했습니다. 이는 연대가 증가함에 따라 생물 기원 시료의 비율이 현저하게 감소함을 보여주며, 이는 시료 내 생물 분자 분해 또는 비생물적 유기물 유입을 반영하는 것일 수 있습니다. (아래 그림 참조)
모델 # 3은 주로 고대 생물 기원과 비생물 기원을 구분하는 능력을 검증하는 데 사용됩니다. 생물 기원 샘플은 네 번째 샘플 그룹을 포함한 89개의 셰일 및 부싯돌 샘플로 구성되며, 비생물 기원 샘플은 여덟 번째 및 아홉 번째 그룹의 77개 샘플입니다.모든 생물학적 샘플은 정확하게 분류되었습니다. 80% 샘플은 생물학적 원인 분류에 대한 높은 신뢰도 확률(>0.60)을 보였으며, 비생물학적 원인 샘플의 정확도는 77%였습니다. AUC 값은 훈련 세트에서 0.873, 테스트 세트에서 0.863이었고, 10겹 교차 검증의 정확도는 91.6%였습니다.
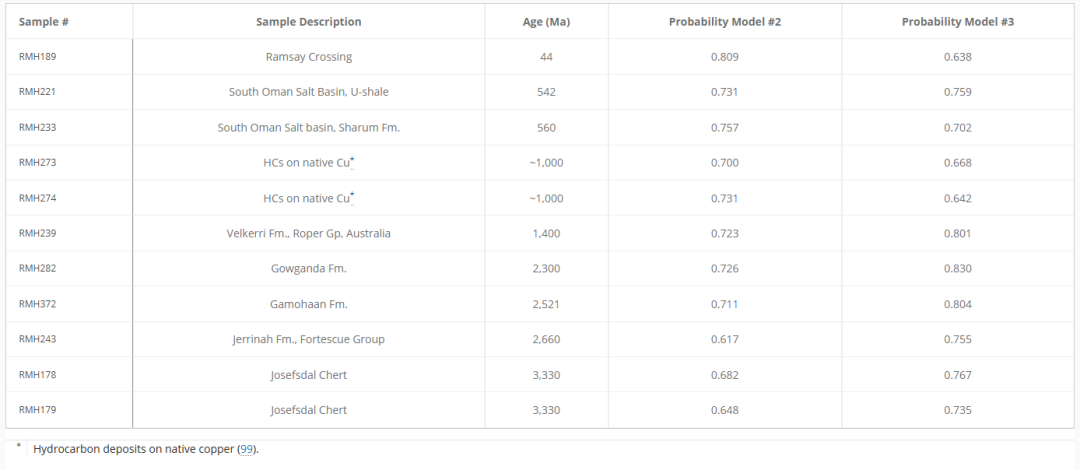
또한, 모델 # 2와 모델 # 3을 결합함으로써,연구진은 11개의 고대 샘플이 생물학적 기원임을 확인했으며, 그중 가장 오래된 것은 남아프리카공화국의 바버턴 그린스톤 벨트에서 발견된 요제프스달 부싯돌로, 33억 3천만 년 전의 것으로 추정됩니다.다음 표에서 볼 수 있듯이:
기술 통합은 생명의 기원을 탐구하는 중요한 수단이 되었다.
최근 몇 년 동안 전 세계 연구팀들은 초기 생명 흔적 규명 및 외계 유기물 추적과 같은 핵심 과제를 해결하기 위해 수많은 혁신적인 연구를 수행해 왔습니다. 이러한 연구들은 또한 복잡한 분자 혼합물 분석에 초점을 맞추고 있으며, 알고리즘 모델을 활용하여 기존 분석 방법으로는 포착하기 어려운 생물학적 특성을 규명함으로써 기술 통합 경로의 실현 가능성을 위한 견고한 토대를 마련하고 지구 생명 기원을 추적하고 있습니다.
예를 들어, 카네기 과학 연구소 지구행성연구소는 다른 여러 기관과 협력하여 위에서 언급한 방법들을 활용했습니다. 이러한 방법들은 행성 샘플에 포함된 유기물의 생물학적 기원을 밝히는 것은 물론, 지구 초기 생명체의 흔적을 찾아내는 데에도 사용될 수 있습니다.이 방법은 지구 및 외계 탄소질 물질에 대한 열분해 가스 크로마토그래피-질량 분석 측정과 머신러닝 분류 방법을 결합한 것입니다.이 방법은 비생물학적 기원의 샘플과 생물학적 샘플(심하게 손상된 생물학적 샘플 포함)을 구별하는 데 90%의 정확도를 달성했으며, 다윈의 생분자 선택 기능의 필요성을 정확하게 반영합니다.
논문 제목: 기계 학습 기반의 견고하고 특정 유형에 국한되지 않는 분자 생체 표지자
서류 주소:https://www.pnas.org/doi/10.1073/pnas.2307149120
py-GC-MS와 머신러닝의 통합은 초기 생명 탐구에 있어 전통적인 방법의 한계를 뛰어넘을 뿐만 아니라, 고생물학과 인공지능의 교차점에서 새로운 패러다임을 제시합니다. 그러나 앞서 언급한 실험 및 다른 연구들에서 볼 수 있듯이, 이러한 기술 통합 접근 방식은 여전히 최적화의 여지가 있으며, 향후 심층 연구를 위한 방향을 제시합니다. 지속적인 기술 발전과 함께 미래에는 인류가 생명의 기원에 대해 더욱 직관적이고 심도 있게 이해하고, 나아가 외계 생명체의 흔적을 탐색할 수 있게 될 것으로 기대됩니다.








