Command Palette
Search for a command to run...
스탠포드, 베이징 대학, UCL, UC 버클리는 CNN을 사용하여 810,000개의 퀘이사에서 희귀한 렌즈형 샘플 7개를 정확하게 식별하기 위해 협력했습니다.

1915년 아인슈타인이 제안한 획기적인 일반 상대성 이론은 질량이 중력을 생성할 뿐만 아니라 주변의 시공간을 휘게 하여 빛과 물질의 운동이 휘어진 시공간 경로를 따라간다는 것을 보여주었습니다. 따라서 거대한 천체는 마치 자연 렌즈처럼 작용하여 근처를 지나는 빛을 굴절시킵니다.
현대 천문학에서 강력한 중력 렌즈는 우주의 거대 구조와 블랙홀과 은하의 공진화를 연구하는 데 중요한 도구입니다. 강력한 중력 렌즈 역할을 하는 퀘이사는 초대질량 블랙홀과 적색편이를 보이는 모은하 사이의 스케일링 관계(특히 MBH-Mhost 관계)의 진화를 연구할 수 있는 매우 드문 관측 기회를 제공합니다. 이 강력한 탐사선을 사용하면 아인슈타인 반지름 θE로부터 모은하의 질량을 정확하게 추정할 수 있습니다.그러나 퀘이사는 극히 드물며, 이를 식별하는 것은 천문학자들에게 항상 큰 과제였습니다. 슬론 디지털 스카이 서베이(SDSS)에 등록된 약 30만 개의 퀘이사 중에서 겨우 12개의 후보만 발견되었고, 최종적으로 확인된 것은 단 3개뿐입니다.
이러한 배경에서 스탠포드 대학, SLAC 국립 가속기 연구소, 베이징 대학, 이탈리아 국립 천체물리학 연구소의 브레라 천문대, 런던 대학교, 캘리포니아 대학교 버클리 등 다수의 연구 기관으로 구성된 팀은 혁신적인 머신 러닝 방법과 암흑 에너지 분광기의 데이터를 활용하여 원래 작았던 이 샘플을 크게 확장했습니다.
연구팀은 DESI DR1의 스펙트럼 데이터에서 강력한 중력 렌즈 물체로 작용하는 퀘이사를 식별하기 위한 데이터 기반 워크플로를 개발했습니다.적색편이 적용 범위는 0.03 ≤ z ≤ 1.8입니다. 이 방법은 실제 DESI QSO 및 ELG 스펙트럼을 기반으로 구성된 현실적인 시뮬레이션 렌즈에서 학습된 합성곱 신경망(CNN)을 활용합니다. 이 과정을 적용하여 연구진은 전경 퀘이사의 적색편이보다 강한 [OII] 이중선 방출을 보이는 7개의 고품질(등급 A) 퀘이사 렌즈 후보를 식별했습니다. 이 후보 중 4개는 추가적인 Hβ, [OIII]λ4959Å, [OIII]λ5007Å 방출선을 보입니다.
참고: DESI DR1은 DESI(Dark Energy Spectral Survey)가 공개한 최초의 분광 조사 데이터입니다.
"DESI DR1에서 강력한 렌즈 역할을 하는 퀘이사 발견"이라는 제목의 관련 연구 결과가 arXiv에 인쇄본으로 게재되었습니다.
연구 하이라이트:
* 이전 연구에서 확인된 퀘이사 렌즈 샘플을 확대했습니다(후보 12개만 선정, 그중 3개 확정).
* 이를 통해 QSO 강한 렌즈 현상에 대한 최초의 통계적 샘플을 구축할 수 있는 길이 열렸으며, 이러한 희귀한 시스템을 대규모로 식별하기 위한 데이터 기반 방법의 잠재력을 보여주었습니다.
그 결과로 얻은 샘플은 블랙홀과 은하의 공진화를 연구하는 강력한 새로운 길을 제공할 것이며, 우주 시간에 걸친 직접적인 질량 측정을 통해 규모 관계를 확립할 것입니다.
서류 주소:
https://arxiv.org/abs/2511.02009
공식 WeChat 계정을 팔로우하고 백그라운드에서 "quasar"를 답글하면 전체 PDF를 받을 수 있습니다.
더 많은 AI 프런티어 논문:
https://hyper.ai/papers
데이터 세트: DESI DR1에서 선택된 812,118개의 퀘이사
첫 번째 DESI 자료에서는 광범위한 적색편이를 포괄하는 약 180만 개의 퀘이사 스펙트럼을 제공합니다.이 연구에서는 DESI DR1 본 조사의 HEALPixel 적색편이 카탈로그를 기반으로 812,118개의 퀘이사를 선정하고, 청색 카메라 노이즈 증가로 인한 스펙트럼의 달빛 영향을 피하기 위해 "어둠 시간" 절차를 채택했습니다("밝은 시간" 절차).
연구진은 Redrock에서 제공한 정보를 활용했는데, 출력에는 퀘이사의 TARGETID, 적색편이(z), 그리고 적색편이 오차(Guy et al., 2023)가 포함됩니다. 이 정보를 바탕으로 OBJTYPE = TGT, ZCAT PRIMARY = 1인 천체만 선택하여 지배적이지 않거나 적색편이에 맞지 않는 천체와 스펙트럼을 제외했습니다. 마지막으로, ZWARN = 0, SPECTYPE = QSO인 천체들은 퀘이사로 분류될 수 있지만 다른 스펙트럼 분류를 가진 천체들을 제외하기 위해 추가 필터링을 수행했습니다. 이 필터링 방법은 적색편이의 정확성을 보장하고, 적색편이 계산에 이상점이 없는 퀘이사 스펙트럼에서만 훈련 샘플을 추출하도록 했습니다.
퀘이사를 선택한 후연구자들은 FastSpec 카탈로그를 사용하여 방출선 은하(ELG) 샘플을 구성했습니다.이 단계는 시뮬레이션 렌즈를 구성하는 데 매우 중요합니다. 이 카탈로그는 DESI 천체에 대한 스펙트럼 정보(방출선 플럭스, 적색편이, 분류 등)를 제공하는 경량 처리 파이프라인인 FastSpecFit1을 기반으로 합니다. FastSpecFit은 특정 매개변수와 스펙트럼 모델을 적용하는 템플릿을 사용하여 잡음 없는 스펙트럼을 생성합니다. 연구진은 먼저 퀘이사와 동일한 방법과 적색편이 범위를 사용하되 SPECTYPE = GALAXY로 설정하여 ELG를 선정했습니다. 이 선별 과정을 통해 16,500개의 방출선 은하가 도출되었지만, 선택된 방출선이 데이터 잡음 수준을 초과하도록 하기 위해 주 관측소인 OII 3726에서 플럭스가 2 × 10^-17 erg cm^-2 s^-1보다 큰 ELG만 사용했습니다.
훈련 세트에 포함된 모든 천체물리학적 및 계측적 노이즈를 포괄하기 위해 실제 관측 데이터를 훈련 과정에 사용했습니다. 그러나 동일한 데이터 배치를 훈련과 실제 렌즈 탐색에 동시에 사용할 수는 없었습니다. 따라서 데이터 세트를 두 단계로 나누어 사용했습니다. 1단계에서는 812,118개의 천체 중 47%를 사용했고, 나머지는 2단계에서 사용했습니다.
1단계:
* 훈련 샘플:분류 네트워크와 적색편이 예측 네트워크는 1단계 훈련 샘플에서 384,873개 퀘이사로부터 70%를 사용하여 훈련되었습니다.
* 검증 샘플:1단계: 훈련 샘플의 나머지 30%는 훈련 중 모델 성능을 검증하는 데 사용됩니다.
* 블라인드 샘플:블라인드 샘플은 훈련, 검증 및 테스트에 사용되지 않은 427,245개의 퀘이사로 구성됩니다. 훈련이 완료된 후 이 데이터셋에서 실제 렌즈를 검색합니다.
* 테스트 샘플:테스트 과정에서는 1단계 블라인드 샘플에서 추출한 퀘이사 3,170개를 사용하였고, 그중 10%에 대해 시뮬레이션된 렌즈 시스템을 구축했습니다. 이 테스트 샘플은 하이퍼파라미터 최적화 후 네트워크 성능을 평가하는 데 사용되었습니다.
2단계:
2단계에서는 훈련 샘플과 블라인드 샘플을 바꾸고 동일한 과정을 반복합니다.
* 훈련 샘플:CNN은 1단계 블라인드 샘플에서 427,245개 퀘이사로부터 70% 샘플을 사용하여 훈련되었습니다.
* 검증 샘플:검증에 사용된 427,245개 샘플 중 30% 샘플이 채택되었습니다.
* 블라인드 샘플:블라인드 샘플은 훈련, 검증 및 테스트에 사용되지 않은 384,873개의 퀘이사로 구성되어 있습니다.
* 테스트 샘플:2단계 테스트에는 2단계 블라인드 샘플에서 추출한 퀘이사 3,547개가 사용되었으며, 이 샘플들은 훈련 및 검증 하위 집합과는 별개였습니다. 그중 10% 퀘이사는 시뮬레이션 렌즈 시스템을 구축하는 데 사용되었습니다.
시뮬레이션된 렌즈 시스템과 퀘이사의 비렌즈 스펙트럼에 대한 CNN 훈련.
강력한 중력 렌즈 천체로 작용하는 퀘이사를 성공적으로 식별할 수 있는 모델을 구성합니다.핵심은 레이블이 지정된 데이터 세트를 사용하여 모델을 학습시켜 렌즈 역할을 하는 퀘이사 스펙트럼의 특징과 렌즈가 아닌 퀘이사 스펙트럼의 특징을 구별할 수 있도록 하는 것입니다.다음 다이어그램은 전체 교육 과정을 보여줍니다.
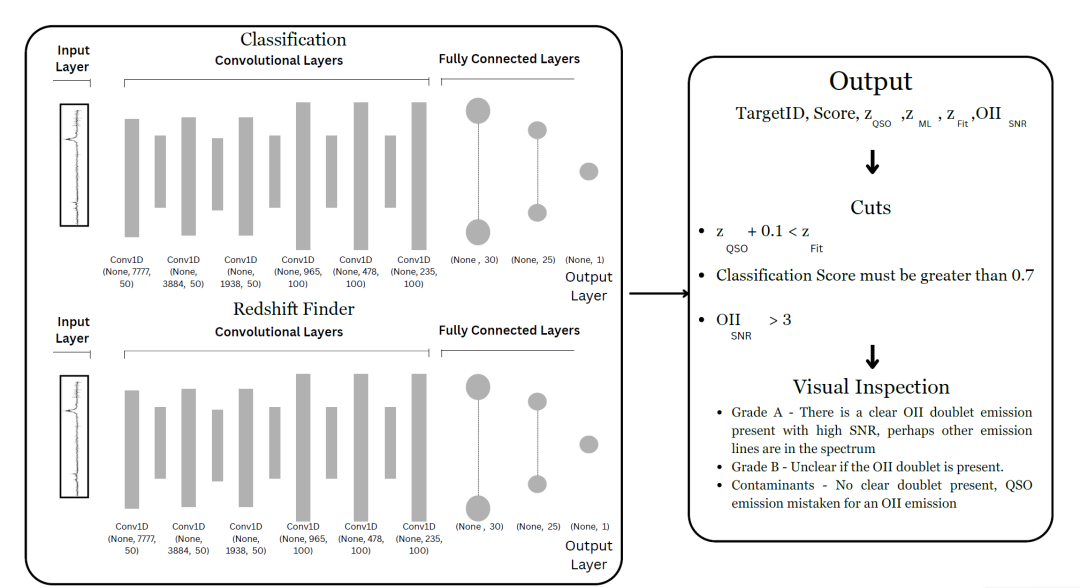
연구진은 DESI에서 관측한 퀘이사(QSO)와 방출선 은하(ELG)의 스펙트럼을 이용하여 시뮬레이션된 렌즈 시스템(양의 샘플)과 비렌즈 퀘이사 스펙트럼(음의 샘플)을 기반으로 합성곱 신경망(CNN)을 학습시켰습니다. 학습 세트에서 양 샘플과 음 샘플의 비율은 10% 대 90%였습니다.
① 훈련 세트 구성 및 시뮬레이션 렌즈 시스템
시뮬레이션된 스펙트럼은 QSO 및 ELG에 대한 교육 세트를 생성하는 데 사용될 수 있지만,하지만 이 연구의 목적은 DESI 스펙트럼의 고유한 특성을 보존하는 것입니다.이러한 특성은 관측 장비, 관측 조건 또는 천체 자체에 의해 발생합니다. 다양한 이유(분광선 폭증, 광도 차이 등)로 인해 QSO와 ELG의 [OII] 분광선은 높은 다양성을 보입니다. 따라서 연구진은 DR1에서 얻은 관측 데이터를 직접 사용하여 신경망을 학습시키고, 이를 통해 QSO와 ELG의 전반적인 관측 특성을 구축했습니다.
그러나 강한 렌즈 역할을 하는 QSO는 극히 드뭅니다. SDSS 데이터셋에서는 297,301개의 퀘이사 중 12개만 후보이며, 본 연구에서 고려한 적색편이 범위 내에서 DESI DR1 데이터셋에는 단 하나만 존재합니다. 따라서 본 연구에서 양성 샘플, 즉 QSO 렌즈는...실제 QSO의 스펙트럼과 높은 적색편이 ELG의 스펙트럼을 중첩하여 충분한 수의 양수 및 음수 샘플을 포함하는 훈련 세트를 구성하는 것이 필요합니다.
② CNN 분류기의 학습 및 아키텍처
분류기 네트워크는 6개의 합성곱 층(처음 세 층에 50개의 필터, 마지막 세 층에 100개의 필터)과 2개의 완전 연결 층(각각 30개와 25개의 노드)으로 구성됩니다. 합성곱 층은 퀘이사 및 ELG 스펙트럼의 방출선과 같은 스펙트럼의 국소적 특징을 추출하고, 최종적으로 0에서 1까지의 점수를 출력하는 데 사용됩니다. 학습 과정에서 임계값은 0.5로 설정되며, 예측 점수가 0.5 이상인 샘플은 렌즈 후보로 식별됩니다. 마지막으로, 블라인드 샘플에 적용할 때 임계값은 F1 점수를 최대화하기 위해 0.7로 최적화됩니다.
CNN 아키텍처는 6개의 합성곱 계층으로 구성됩니다. 처음 세 계층에는 각각 50개의 필터가 있고, 마지막 세 계층에는 각각 100개의 필터가 있습니다. 위 그림의 왼쪽에 표시된 것처럼 첫 번째 완전 연결 계층에는 30개의 노드가 있고 두 번째 계층에는 25개의 노드가 있습니다. 신경망은 0에서 1 사이의 점수를 출력합니다. 학습 과정에서 연구진은 임계값을 0.5로 설정했습니다. 예측 점수가 0.5 이상인 샘플은 신경망에서 렌즈로 식별되었습니다.
학습 과정에서는 Adam 옵티마이저를 지수 학습률 감소(exponential learning rate decay) 방식으로 사용하여 500단계마다 학습률을 0.95배씩 감소시켰습니다. 학습은 TensorFlow를 사용했으며, 학습 세트 분할, 혼동 행렬 계산, 그리고 메트릭 계산에는 scikit-learn을 사용했습니다.
이후 연구진은 각각 1단계와 2단계의 훈련 샘플을 사용하여 두 개의 CNN을 훈련했습니다.1단계에서 훈련된 CNN은 1단계 블라인드 샘플에 사용되고, 2단계에서 훈련된 CNN은 2단계 블라인드 샘플에 사용됩니다.학습 후, 모델은 테스트 샘플에 대한 분류 성능을 평가하고, 참양성(TP), 거짓양성(FP), 거짓음성(FN)을 합한 F1 점수를 기반으로 임계값을 조정합니다. 두 단계 모두에서 가장 높은 F1 점수는 임계값 0.7에 해당합니다.
마지막으로, 각 네트워크는 블라인드 샘플(모델에서 관찰되지 않은 퀘이사)에 적용되어 렌즈 후보의 첫 번째 목록을 생성합니다.
③ 적색편이 예측
퀘이사 스펙트럼에서 전경 QSO의 적색편이는 측정하기 쉽지만, 배경 ELG의 적색편이는 직접 구하기 어렵습니다. 연구팀은 두 가지 방법을 사용하여 성능을 비교했습니다.
* 레드록:스펙트럼은 PCA 템플릿을 사용하여 맞춰졌고, χ²를 최소화하기 위해 그리드 검색이 수행되었습니다.
* Redshift CNN 회귀 모델:분류기와 유사한 CNN 구조를 채택하지만, 출력은 연속적인 적색편이 값이며, 평균 제곱 오차(MSE)로 학습됩니다.
연구팀은 CNN에서 예측한 적색편이를 바탕으로 Δz=0.1 범위 내에서 [OII] 바이라인에 대한 로컬 이중 가우시안 피팅을 수행하여 적색편이 예측을 더욱 세부화하고 동시에 신호 대 잡음비(SNR)를 계산하여 고품질 후보를 선별했습니다.
결과 쇼케이스: 강력한 렌즈 후보 7개 발견
① CNN 분류기 성능: 훈련 세트와 검증 세트 모두에서 뛰어난 성능을 보였습니다.
1단계와 2단계의 학습 및 검증 세트에 적용된 CNN 분류기의 성능 지표는 아래 표에 나와 있습니다.
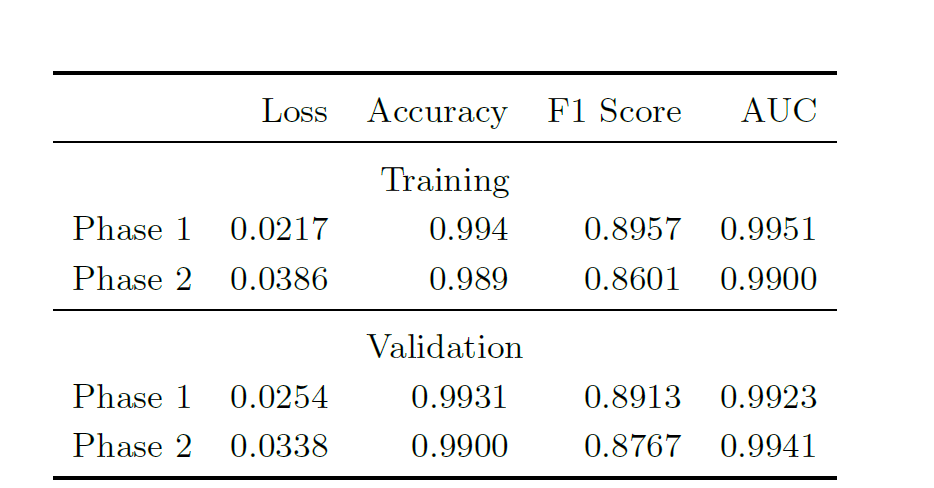
결과에 따르면 CNN 분류기는 훈련 세트와 검증 세트 모두에서 좋은 성능을 보였으며, F1 점수와 AUC 지표는 모델이 정밀도와 재현율을 효과적으로 균형 있게 조절할 수 있음을 나타냅니다.
② 적색편이 측정 성능: 모든 SNR 범위에서 CNN 적색편이 측정 장치는 Redrock 장치보다 상당히 우수한 성능을 보입니다.
테스트 샘플에서,연구원들은 [OII] 방출 특징의 다양한 SNR 범위에서 CNN과 Redrock의 성능을 관찰하기 위해 고적색편이 ELG의 신호 대 잡음비(SNR)에 따라 각 객체를 분류했습니다.연구진은 백분위수를 기준으로 샘플을 낮은 SNR(3 ≤ SNR < 7.52), 중간 SNR(7.52 ≤ SNR < 16.63), 높은 SNR(SNR ≥ 16.63)의 세 그룹으로 나누었습니다.
결과는 다음과 같습니다.
* 높은 SNR:CNN은 Δz = 0.1 내에서 100%의 소스 적색편이를 회복했는데, 이는 가우시안 피팅 후에는 99.48%, Redrock 후에는 51.04%였습니다.
* 중국의 SNR:CNN의 TP3T는 99.481이고, 가우시안 피팅의 TP3T는 1001이며, Redrock의 TP3T는 37.701입니다.
* 낮은 SNR:CNN의 TP3T는 100.001이고, 가우시안 피팅의 경우 96.881이며, Redrock의 경우 29.171입니다.
요약하자면,모든 SNR 범위에서 CNN 적색편이 측정과 가우시안 피팅을 결합한 결과는 배경 ELG 적색편이를 복구하는 데 있어 Redrock보다 상당히 우수한 성과를 보였습니다.상당한 스카이라인과 적외선 채널의 잔여 노이즈(마스킹 포함)에도 불구하고 CNN은 여전히 표준 Redrock 방식보다 우수한 성능을 보입니다. 가우시안 피팅은 중간 SNR 범위에서는 거의 정확한 결과를 보이지만, 매우 낮은 SNR 범위에서는 성능이 저하되어 순수 CNN 방식이 더 우수합니다.
③ 블라인드 샘플 적용 : Class A 고우선순위 렌즈 후보 7개 선정
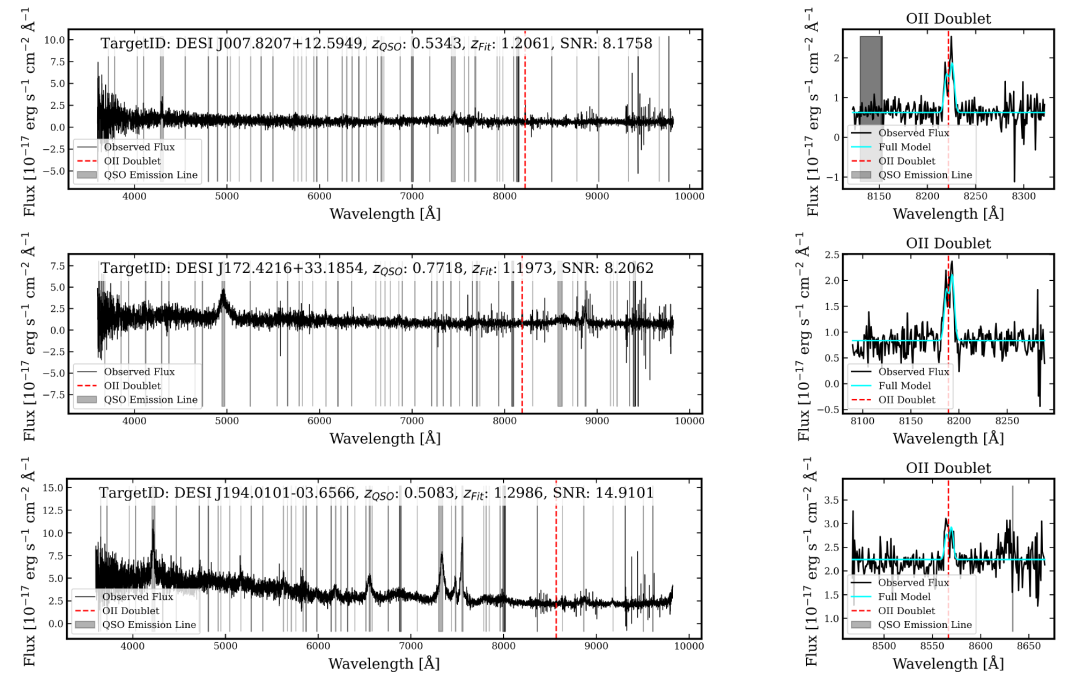
훈련된 CNN을 812,118개의 퀘이사 스펙트럼에 적용한 결과, 총 494개의 후보가 선정되었습니다. SNR 및 적색편이 정보와 결합된 수동 시각 검사를 통해, 아래 표와 같이 우선순위가 높은(A등급) 렌즈 후보 7개가 최종적으로 확정되었습니다.
아래 그림에서 볼 수 있듯이, 7개의 Class A 후보 모두 QSO보다 높은 적색편이에서 강한 [OII] 더블릿을 보이는 것으로 나타났습니다. 이 후보 중 4개는 동일한 적색편이에서 [OIII] λ 4959˚A 및 Hβ 선도 보입니다.
딥러닝은 천문학 연구의 패러다임을 바꾸고 있습니다.
지난 10년 동안 AI, 특히 딥러닝은 천문학 연구 패러다임을 빠르게 변화시켜 왔습니다. 데이터 수집 및 특징 추출부터 과학적 발견 과정에 이르기까지, 천문학에서 AI의 역할은 "보조 도구"에서 최첨단 혁신을 위한 핵심 동력으로 진화했습니다. 이러한 변화의 근본적인 이유는 다음과 같습니다.천문학은 전례 없는 데이터 폭발의 시대로 접어들고 있습니다.
DESI, LSST, Euclid와 같은 대규모 천문 탐사는 매년 페타바이트 규모의 데이터를 생성하며, 이는 기존의 수동 분석 및 고전 알고리즘의 처리 능력을 훨씬 능가합니다. 딥러닝 모델은 방대한 관측 데이터에서 복잡한 패턴을 자동으로 추출하는 데 탁월하여 스펙트럼, 이미지 및 시계열 데이터 처리에 이상적입니다.
대표적인 대표자 중 한 사람으로서2025년 11월, 캘리포니아 대학교 버클리, 케임브리지 대학교, 옥스퍼드 대학교를 포함한 전 세계 10개 이상의 연구 기관으로 구성된 팀이 공동으로...AION-1: 천문학을 위한 최초의 대규모 다중 모드 기초 모델 패밀리(천문 옴니모달 네트워크)AION-1은 통합된 초기 융합 백본 네트워크를 통해 이미지, 스펙트럼, 별 목록 데이터와 같은 이질적인 관측 정보를 통합하고 모델링함으로써, 제로샷 시나리오에서도 탁월한 성능을 발휘할 뿐만 아니라, 선형 탐지 정확도도 특정 작업을 위해 특별히 훈련된 모델과 유사합니다. AION-1은 데이터 이질성, 노이즈, 기기 다양성과 같은 핵심 과제를 체계적으로 해결함으로써 천문학 및 기타 과학 분야에 실현 가능한 다중 모드 모델링 패러다임을 제공합니다.
논문 제목:AION-1: 천문과학을 위한 옴니모달 기초 모델
서류 주소:https://openreview.net/forum?id=6gJ2ZykQ5W
천체 분류 분야에서 딥러닝은 핵심 기술로 자리 잡았습니다. 은하 형태 분류, 초신성 식별, 또는 강력한 중력 렌즈 탐색 등 어떤 분야든,CNN과 Transformer 아키텍처는 모두 고차원의 비정형 데이터에서 물리적 프로세스와 관련된 주요 기능을 찾아 수동 방법을 훨씬 뛰어넘는 속도와 일관성을 달성합니다.
예를 들어,중국과학원 운남천문대의 펭 하이청 박사가 이끄는 팀은 정저우대학의 리 루이 박사와 이탈리아 나폴리 페데리코 2세 대학의 니콜라 R. 나폴리타노 교수와 협력하여다중 모드 신경망 모델이 제안되어 천체 형태학적 특징과 SED 정보를 혁신적으로 통합하여 별, 퀘이사, 은하와 같은 천체를 고정밀 자동 식별할 수 있게 되었습니다. 이 방법은 유럽 남방 천문대 KiDS 프로젝트의 다섯 번째 데이터 발표에서 1,350제곱도의 천구 영역에 적용되어 23등급보다 밝은 2,700만 개 이상의 r-밴드 천체 분류를 완료했습니다.
논문 제목:신경망 기반 KiDS DR5 소스의 형태 광도 분류: 포괄적인 별-퀘이사-은하 카탈로그
서류 주소:https://iopscience.iop.org/article/10.3847/1538-4365/adde5a
전반적으로 AI는 단순히 전통적인 천문학적 방법을 대체하는 것이 아니라 과학 연구 패러다임을 지속적으로 업그레이드하고 있습니다. 즉, 천문학자들이 지루한 데이터 처리에서 벗어나 근본적인 물리적 질문에 집중할 수 있도록 하고, 희귀한 천체가 엄청난 양의 데이터에 압도당하는 것을 방지하며, 우주의 구조와 진화에 대한 더 빠르고 더 깊은 이해를 가능하게 합니다.
참고문헌:
1.https://arxiv.org/abs/2511.02009
2.https://phys.org/news/2025-11-machine-quasars-lenses.html
3.https://www.cpsjournals.cn/data/article/wl/preview/pdf/10.7693/wl20250701.pdf
4.https://mp.weixin.qq.com/s/6zlnE5-fIw21TQeg1QPPnQ
5.https://www.cas.cn/syky/202507/t20250711_5076040.shtml








