Command Palette
Search for a command to run...
WildSpeech-Bench 음성 이해 생성 벤치마크 데이터 세트
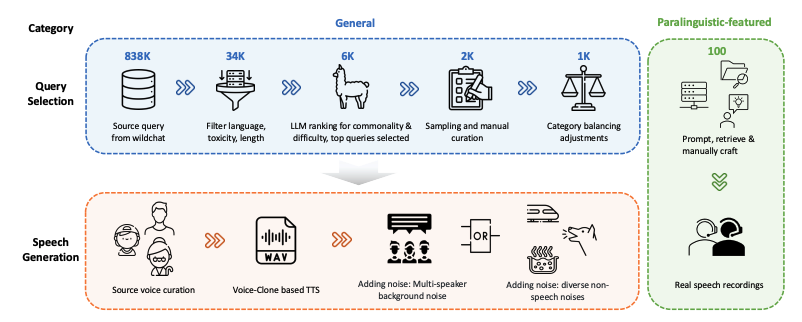
WildSpeech-Bench는 Tencent가 2025년에 발표한 SpeechLLM의 음성 대 음성 기능을 평가하는 최초의 벤치마크입니다. 관련 논문 결과는 다음과 같습니다.WildSpeech-Bench: 실제 환경에서의 종단 간 SpeechLLM 벤치마킹"는 실제 음성 상호 작용 시나리오에서 음성 입력에서 음성 출력까지 완전한 음성 입력을 이해하고 생성하는 모델 능력(음성 대 음성, S2S)을 측정하는 것을 목표로 합니다. 이 데이터셋은 정보 질의, 해결 요청, 의견 교환, 텍스트 생성, 준언어적 표현의 다섯 가지 주요 범주에 걸쳐 1,100개의 질의를 포함합니다. 각 범주는 공통적인 사용자 의도에 해당합니다. 이 중 1,000개는 일반적인 음성 상호작용 시나리오(정보 질의, 해결 요청, 의견 교환, 텍스트 생성 포함)에서 추출되었으며, 나머지 100개는 멈춤, 억양, 더듬거림, 그리고 음성에 가까운 단어 인식과 같은 준언어적 특징을 특징으로 합니다. 각 질의에는 다양한 화자 속성(성별, 연령, 음성 변형), 음향 조건, 소음 환경 설정을 포함하는 다양한 음성 출력 예시가 함께 제공되어 자연스러운 음성 상호작용의 다양성과 어려움을 더욱 현실적으로 시뮬레이션합니다.
소환
@misc{zhang2025wildspeechbenchbenchmarkingendtoendspeechllms, 제목={WildSpeech-Bench: 실제 환경에서 엔드투엔드 SpeechLLM 벤치마킹}, 저자={Linhao Zhang, Jian Zhang, Bokai Lei, Chuhan Wu, Aiwei Liu, Wei Jia, Xiao Zhou}, 연도={2025}, eprint={2506.21875}, archivePrefix={arXiv}, primaryClass={cs.CL}, }