Command Palette
Search for a command to run...
DeepSeek-OCR: 従来の文字認識に代わる「視覚的圧縮」
1. チュートリアルの概要

DeepSeek社が2025年10月にリリースしたDeepSeek-OCRは、画像から長いコンテキストを圧縮する実現可能性に関する予備的な研究です。コアエンジンであるDeepEncoderは、高解像度の入力において高い圧縮率を達成しながら低い活性化レベルを維持し、画像トークンの数を制御可能かつ最適化された範囲内に維持することを目指しています。実験では、テキストトークンの数が画像トークンの数の10倍を超えない場合(つまり、圧縮率<10倍)、モデルは971 TP3Tのデコード(OCR)精度を達成することが示されています。圧縮率が20倍であっても、OCR精度は約601 TP3Tを維持します。これは、歴史文書の長いコンテキスト圧縮や大規模モデルにおけるメモリ減衰メカニズムなどの研究分野において大きな可能性を示しています。関連する研究論文も入手可能です。 DeepSeek-OCR: コンテキスト光学圧縮 。
このチュートリアルでは、デフォルトのリソースとして単一の RTX 5090 グラフィック カードを使用しますが、プログラムの起動には、最小で単一の RTX 4090 グラフィック カードも使用できます。
2. プロジェクト例
3. 操作手順
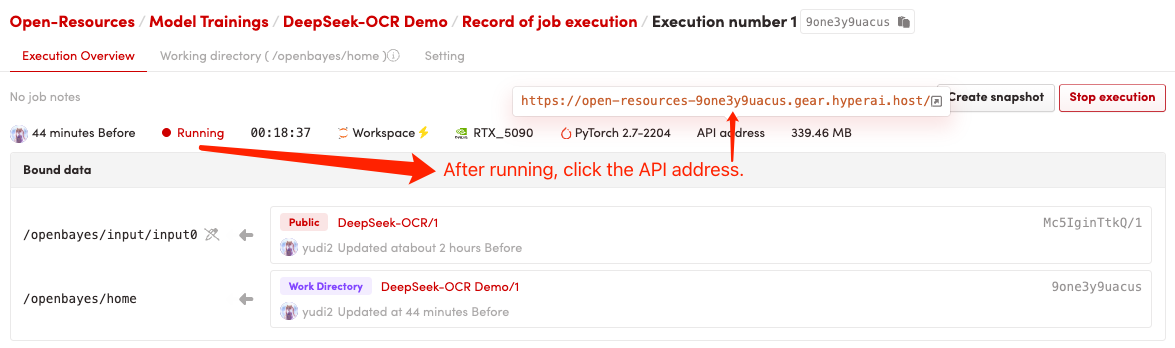
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. ウェブページにアクセスしたら、画像をアップロードしたりテキストを解析したりできます。
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
利用手順

3. 出力結果
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@article{wei2025deepseek,
title={DeepSeek-OCR: Contexts Optical Compression},
author={Wei, Haoran and Sun, Yaofeng and Li, Yukun},
journal={arXiv preprint arXiv:2510.18234},
year={2025}
}