HyperAI
Command Palette
Search for a command to run...
VoxCPM: 単語分割のないTTS技術
1. チュートリアルの概要
VoxCPMは、Mianbi Intelligenceと清華大学深圳国際大学院が2025年9月に共同開発した0.5億パラメータの音声生成モデルです。音声合成において、業界をリードするレベルの自然さ、音色の類似性、韻律表現力を実現します。VoxCPMは、エンドツーエンドの拡散自己回帰アーキテクチャを活用し、テキストから直接連続音声表現を生成し、従来の離散単語分割の限界を超えます。階層型言語モデリングと有限状態量子化制約により、意味と音響の暗黙的な分離を実現し、音声の表現力と生成安定性を大幅に向上させます。VoxCPMはゼロショット音声クローニングをサポートし、単一の参照オーディオクリップだけで話者の音色、アクセント、感情的なイントネーションなどの特徴を正確に再現し、非常にリアルな音声を生成します。
このチュートリアルで使用されるコンピューティング リソースは、単一の RTX 4090 カードです。
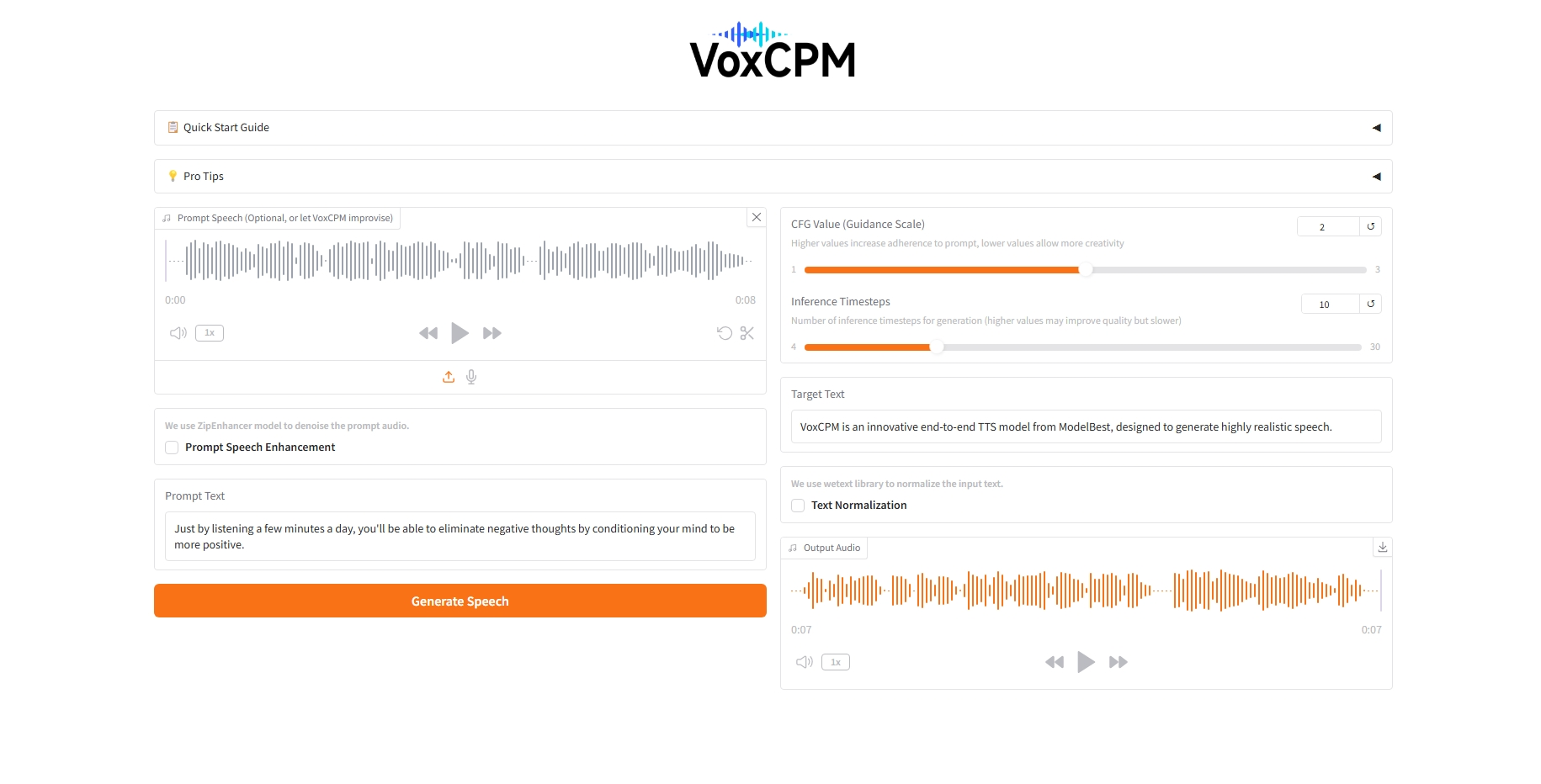
2. エフェクト表示
3. 操作手順
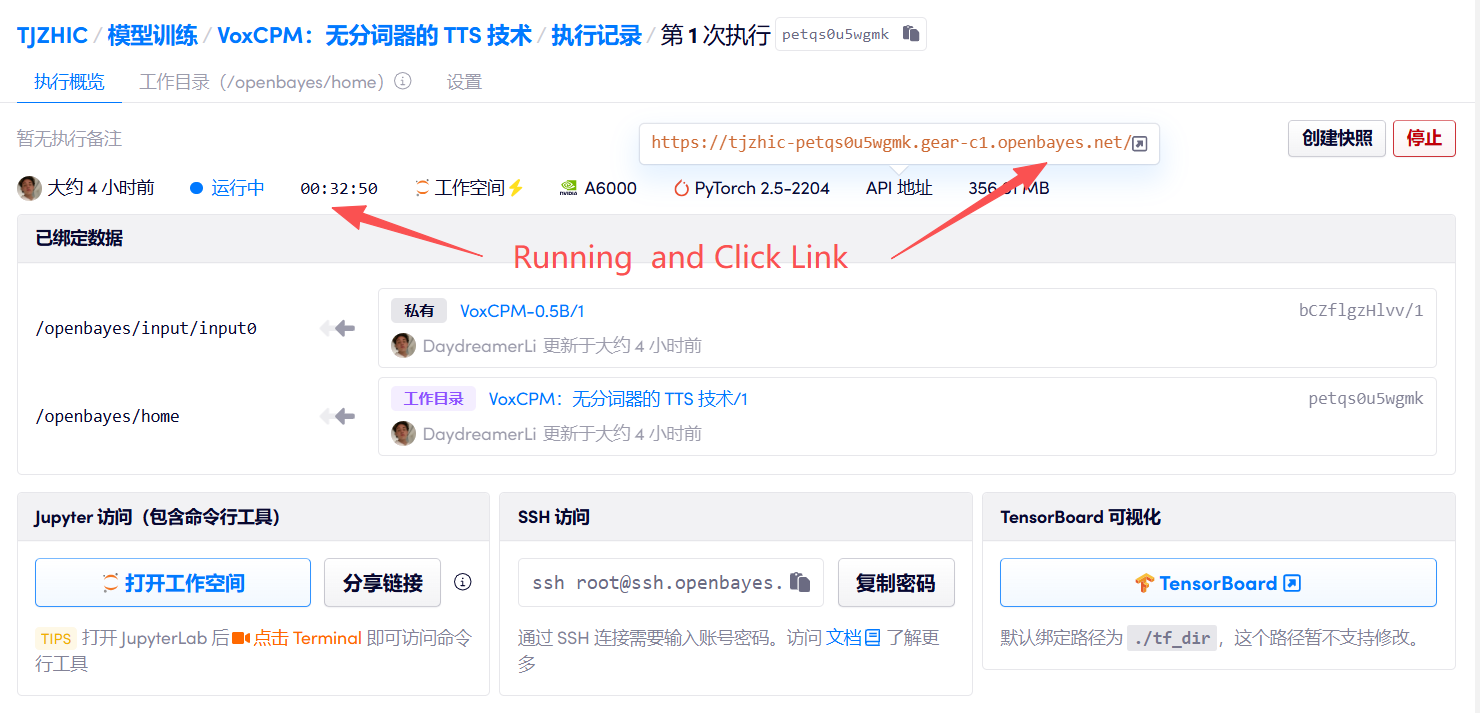
1. コンテナを起動します
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
2. 使用手順
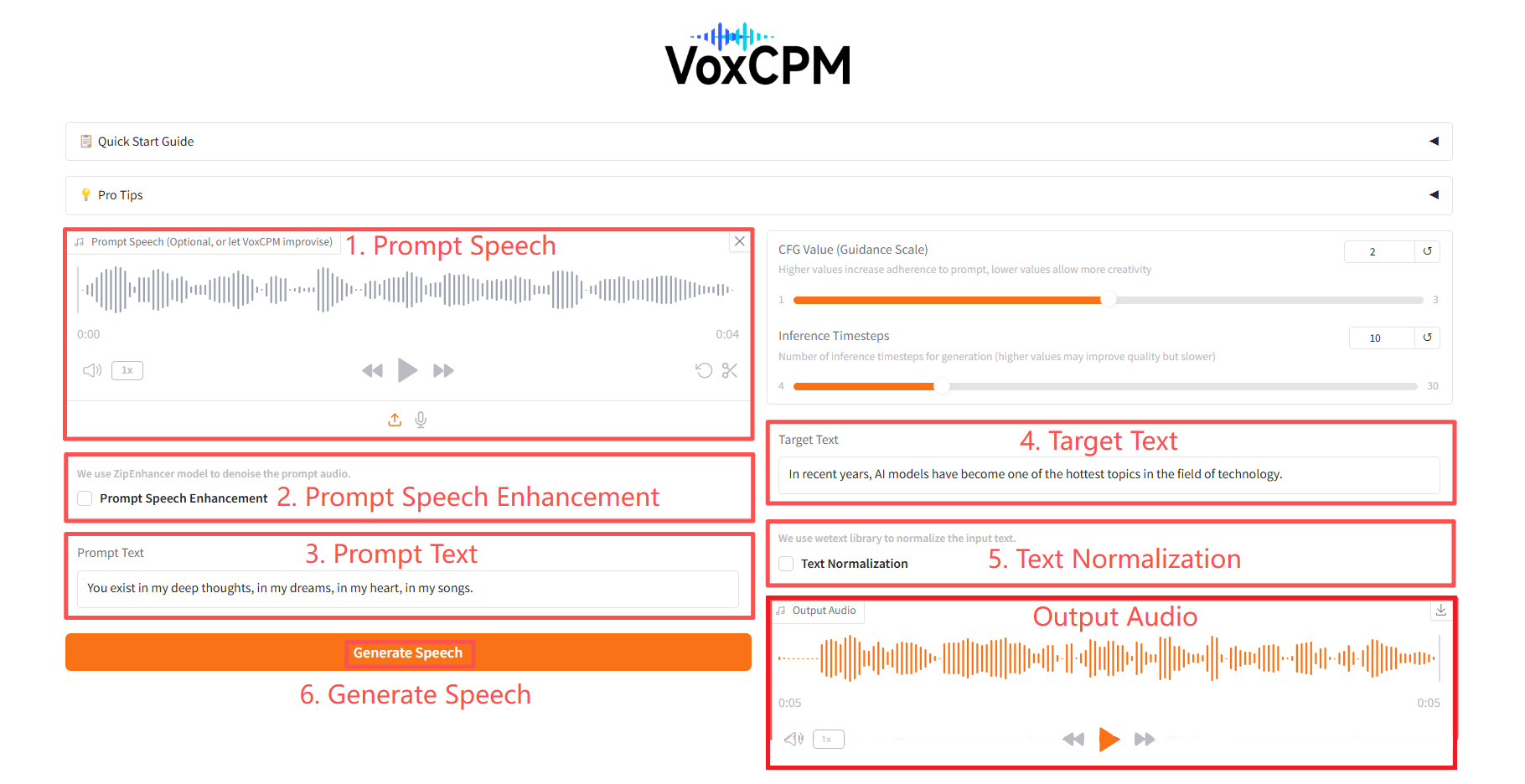
具体的なパラメータ:
- CFG 値: 値が高いほどプロンプトへの従順性が高く、値が低いほど創造性が高くなります。
- 推論タイムステップ: 生成する推論タイムステップの数 (値を大きくすると品質は向上しますが、速度は遅くなります)。
- プロンプト音声強化: ZipEnhancer モデルを使用してプロンプト音声のノイズを除去します。
- テキストの正規化: wetext ライブラリを使用して入力テキストを正規化します。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{voxcpm2025,
author = {{Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, Zhiyuan Liu}},
title = {{VoxCPM}},
year = {2025},
publish = {\url{https://github.com/OpenBMB/VoxCPM}},
note = {GitHub repository}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。