HyperAI
Command Palette
Search for a command to run...
Qwen3-Omni-30B-A3B-キャプション:音声解説大型モデル
1. チュートリアルの概要

Qwen3-Omni-30B-A3B-Captionerは、アリババ通益千文チームによって2025年9月にリリースされた大規模な音声記述モデルです。このモデルは、複雑な音声、環境音、音楽、映画やテレビの効果音について、プロンプトなしでも正確かつ包括的な記述を自動生成します。話者の感情、音楽要素(スタイルや楽器など)、機密情報を識別することができます。音声コンテンツ分析、セキュリティ監査、意図認識、音声編集などの分野に適しています。関連論文は「Qwen3-Omini 技術レポート”。
このチュートリアルでは、リソースとして単一の RTX A6000 カードを使用します。
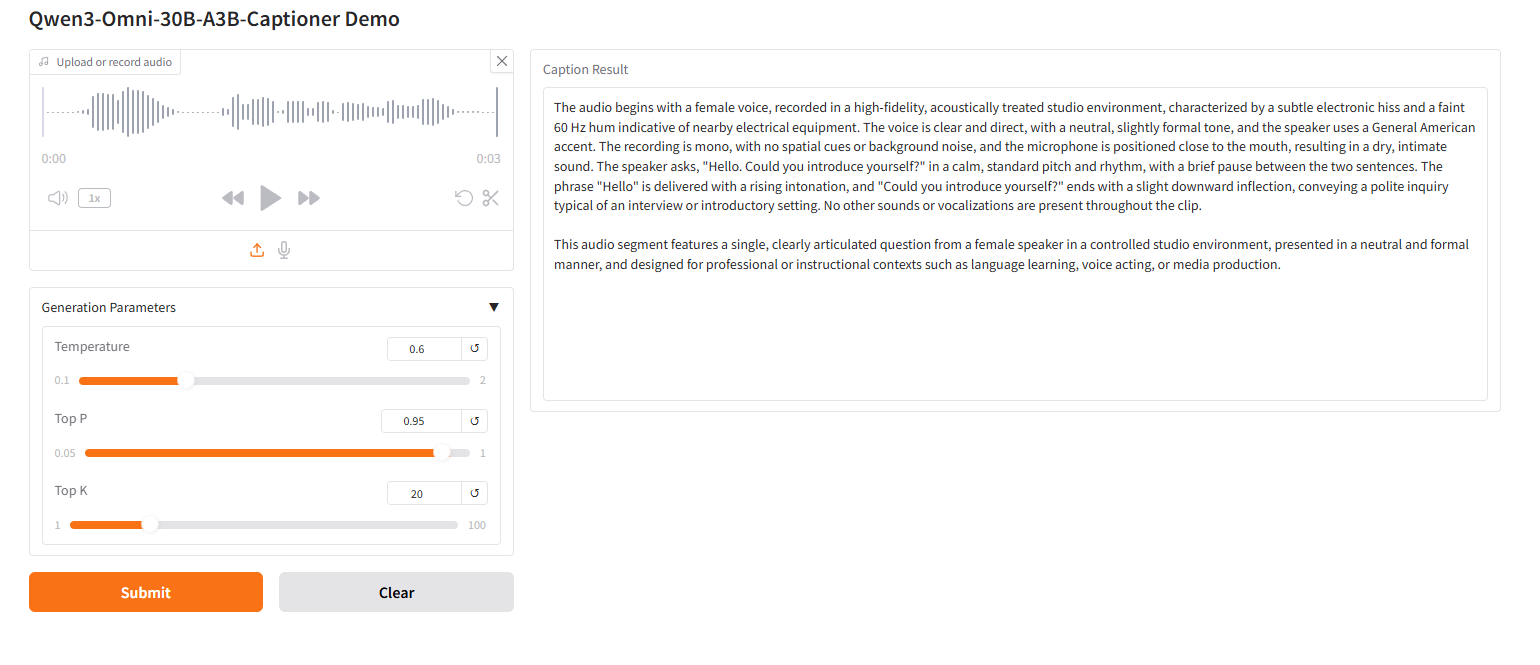
2. プロジェクト例
3. 操作手順
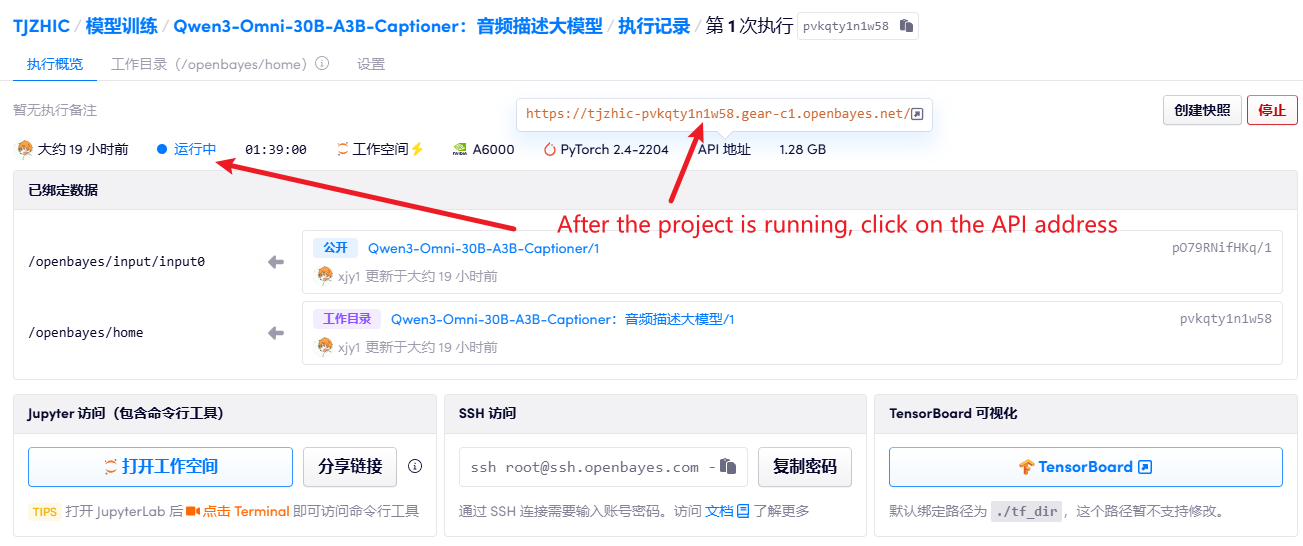
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。 注: 音声の長さは30秒に制限されています。結果の生成には約3~5分かかります。
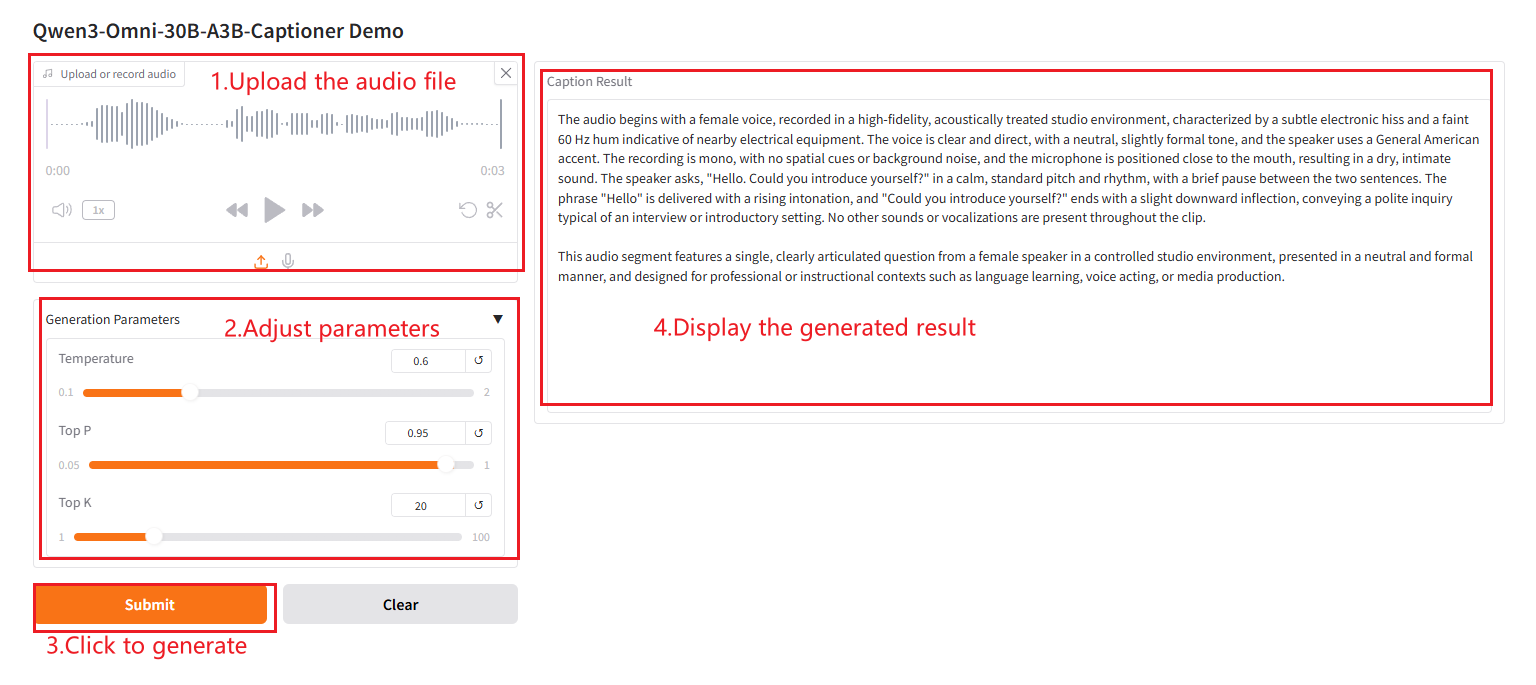
パラメータの説明
- 温度: 値が小さいほど、字幕はより「保守的」かつ確実になります。値が大きいほど、字幕はよりランダムかつ革新的になります。
- トップp: 確率がpに達する「高得点単語」のみを選択します。pが小さいほど候補数が少なくなり、テキストはより保守的になります。
- トップk: 確率が最も高いk個の単語のみを残します。kが小さいほど候補が少なくなり、テキストはより保守的になります。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。