HyperAI
Command Palette
Search for a command to run...
SRPO: 画像生成は AI に別れを告げます!
1. チュートリアルの概要

SRPOは、テンセント・フンユエン・チーム、香港中文大学深圳校理学院、清華大学深圳国際大学院が2025年9月に共同で立ち上げたテキスト画像生成モデルです。報酬信号をテキスト条件付き信号として設計することで、報酬のオンライン調整を可能にし、オフライン報酬の微調整への依存を軽減します。SRPOはDirect-Align技術を導入し、事前定義されたノイズ事前分布を通して任意のタイムステップから元の画像を直接復元することで、後のタイムステップでの過剰最適化を回避します。FLUX.1.devモデルの実験では、SRPOは人間が知覚する生成画像のリアリティと美的品質を大幅に向上させ、トレーニング効率が非常に高く、最適化を完了するのにわずか10分しかかからないことが示されています。関連研究論文も入手可能です。 完全な普及軌道を人間の細分化された嗜好と直接整合させる 。
このチュートリアルでは、単一のA6000 GPUをコンピューティングリソースとして使用します。このモデルは現在、英語のプロンプトのみをサポートしています。
2. エフェクト表示

3. 操作手順
1. コンテナを起動します
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
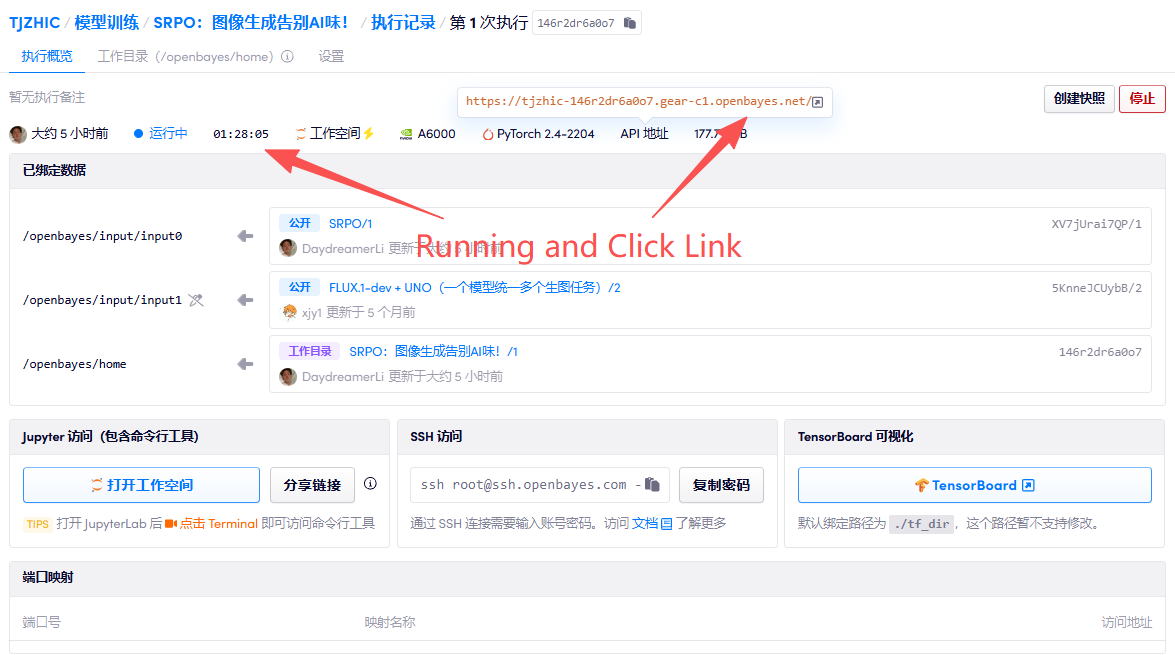
2. 使用手順
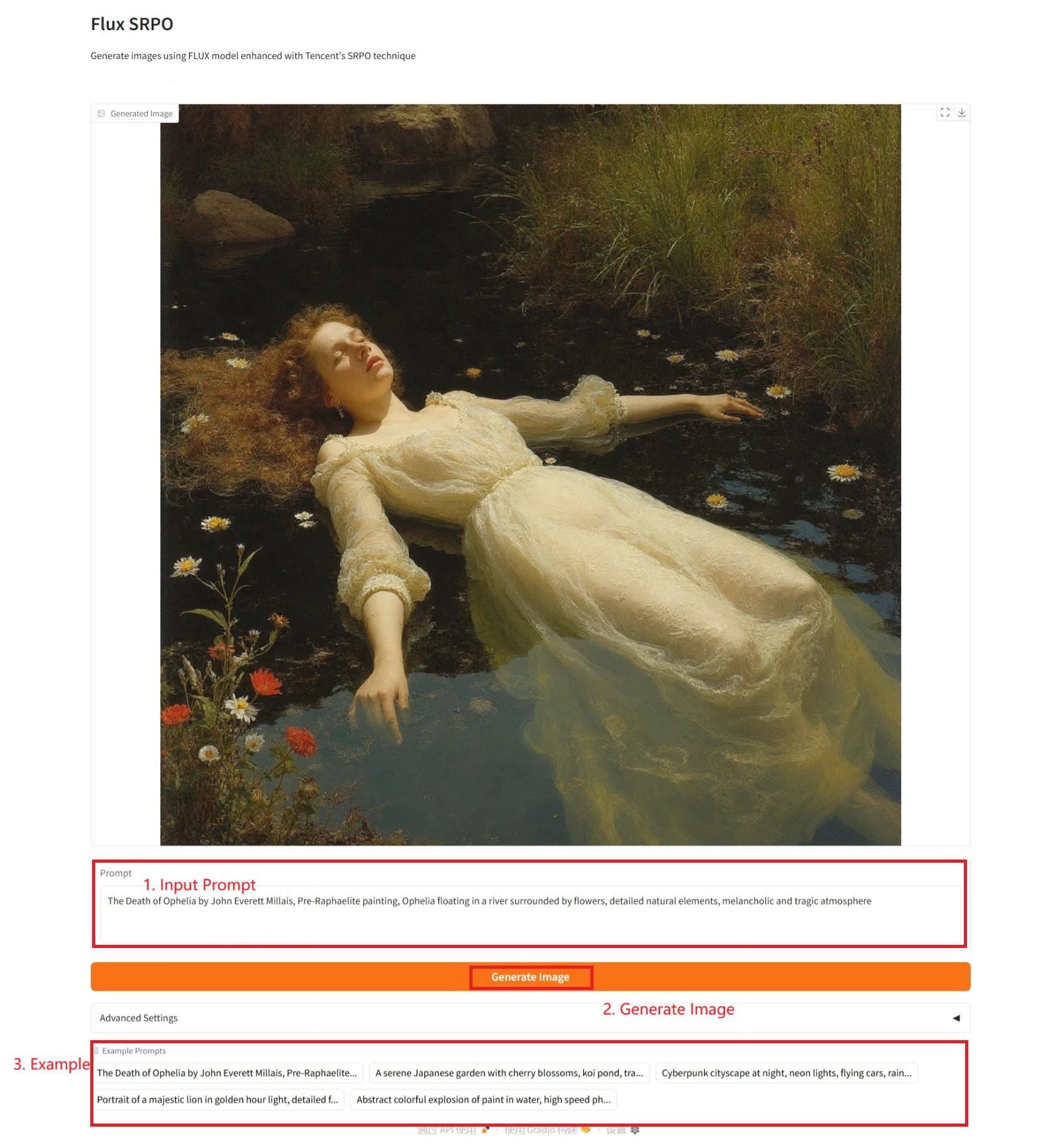
具体的なパラメータ:
- プロンプト: ここでテキストの説明を入力できます。
- 幅: 画像の幅。
- 高さ: 画像の高さ。
- ガイダンス スケール: 画像生成中にテキスト プロンプトが最終結果に与える影響を制御するために使用されるガイダンス スケール。
- 推論ステップ: 推論ステップの数は、生成プロセスの反復回数を制御し、生成の品質と計算時間に影響します。
- シード: 乱数生成プロセスの初期値を制御するために使用される乱数シード。
- 使用されたシード: 使用されたシード。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{shen2025directlyaligningdiffusiontrajectory,
title={Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference},
author={Xiangwei Shen and Zhimin Li and Zhantao Yang and Shiyi Zhang and Yingfang Zhang and Donghao Li and Chunyu Wang and Qinglin Lu and Yansong Tang},
year={2025},
eprint={2509.06942},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.06942},
}
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。