Command Palette
Search for a command to run...
Flow-GRPOフローマッチングテキストグラフモデルデモ
1. チュートリアルの概要

Flow-GRPOは、香港中文大学マルチメディア研究所、清華大学、快手克玲チームによって2025年5月13日に発表されたフローマッチングモデルです。このモデルは、オンライン強化学習フレームワークとフローマッチング理論を革新的に統合し、GenEval 2025ベンチマークにおいて画期的な成果を達成しました。SD 3.5 Mediumモデルの総合生成精度は、ベンチマークの63%から95%へと飛躍的に向上し、生成品質評価指標は初めてGPT-4oを上回りました。関連研究論文も公開されています。 Flow-GRPO: オンライン強化学習によるフローマッチングモデルのトレーニング 。
このチュートリアルでは、リソースとして単一の RTX 4090 カードを使用し、イメージ生成プロンプトは英語のみをサポートします。
2. プロジェクト例
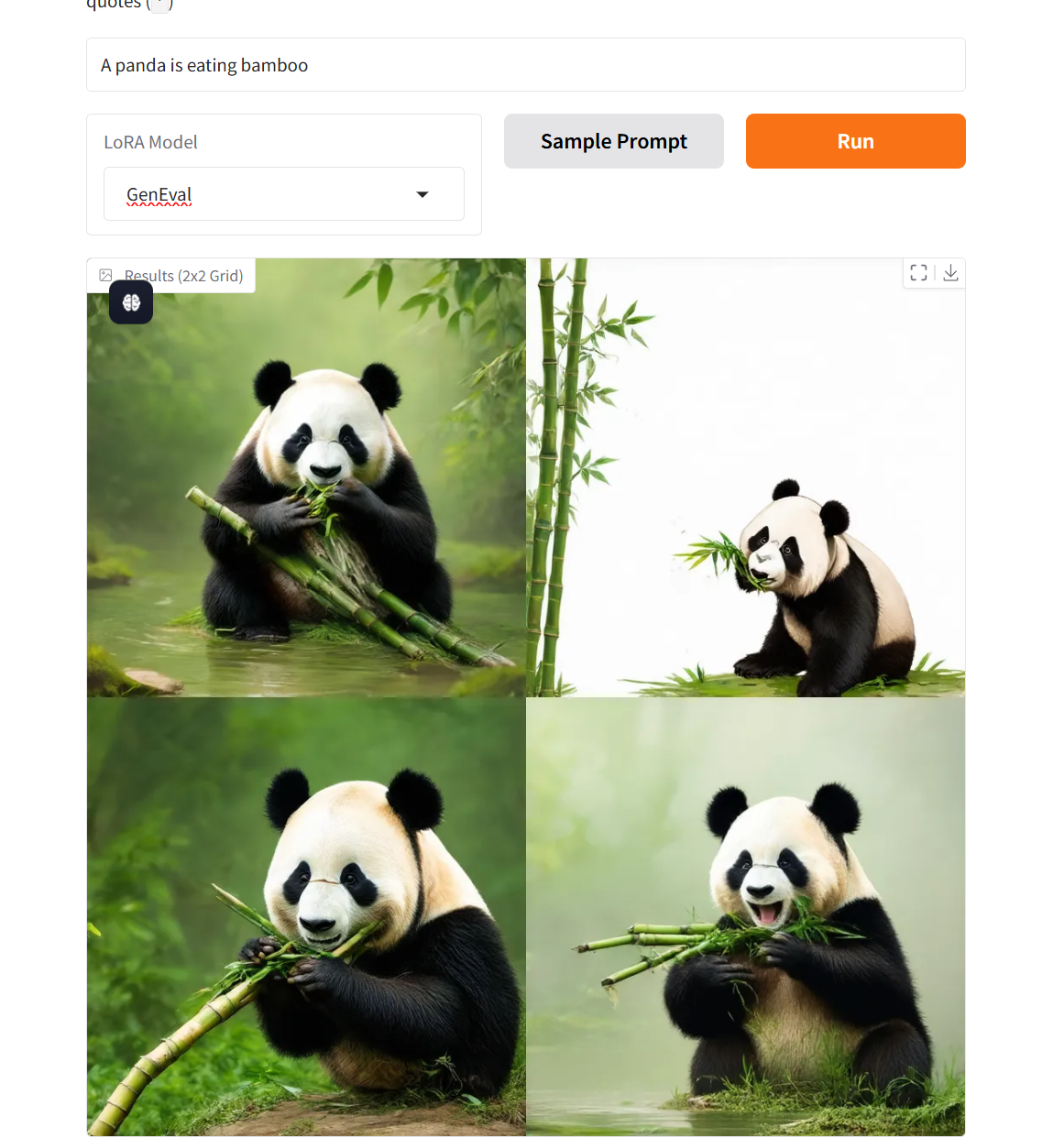
3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
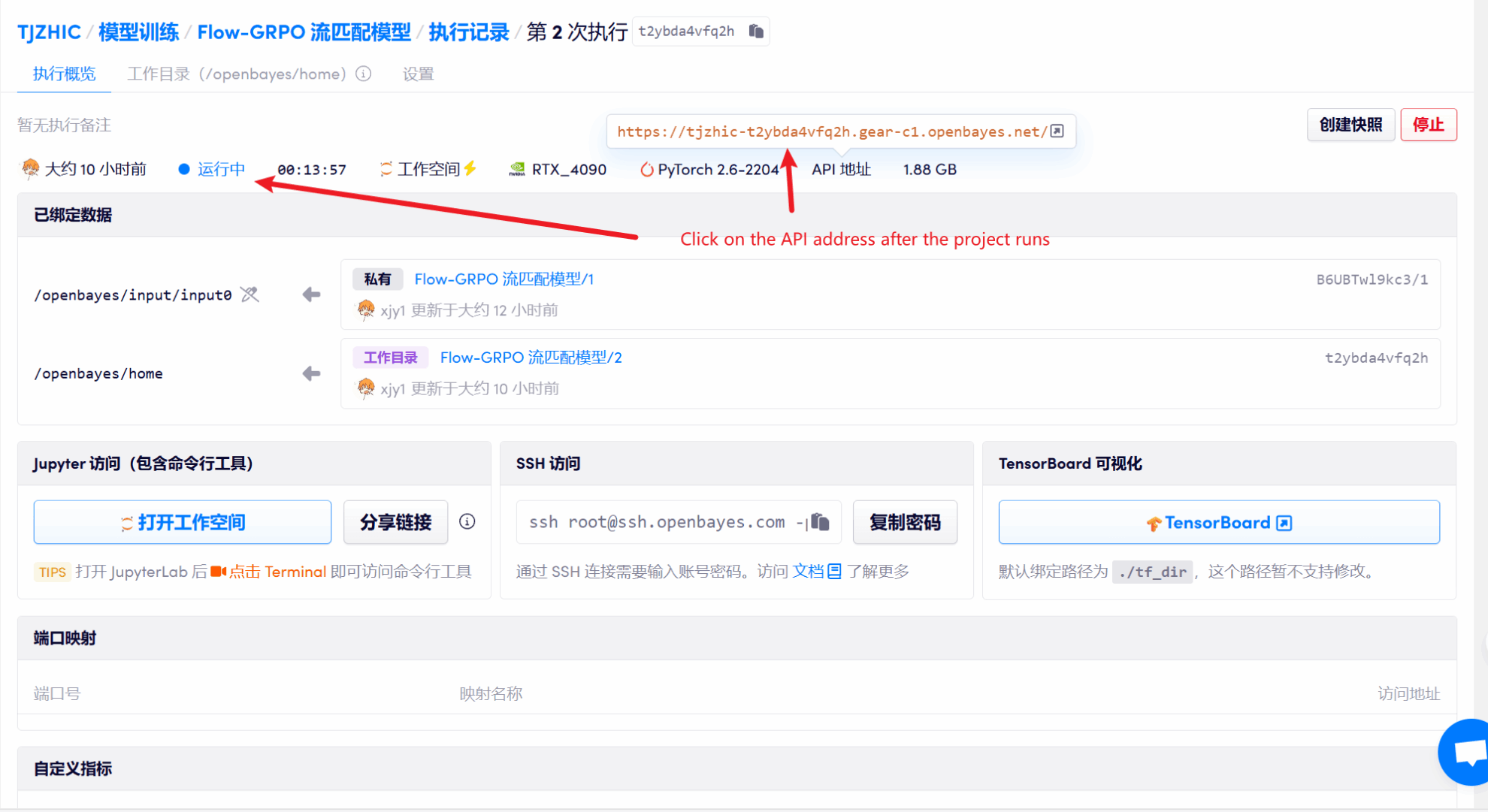
2. Web ページに入ると、モデルと会話を開始できます。
利用手順
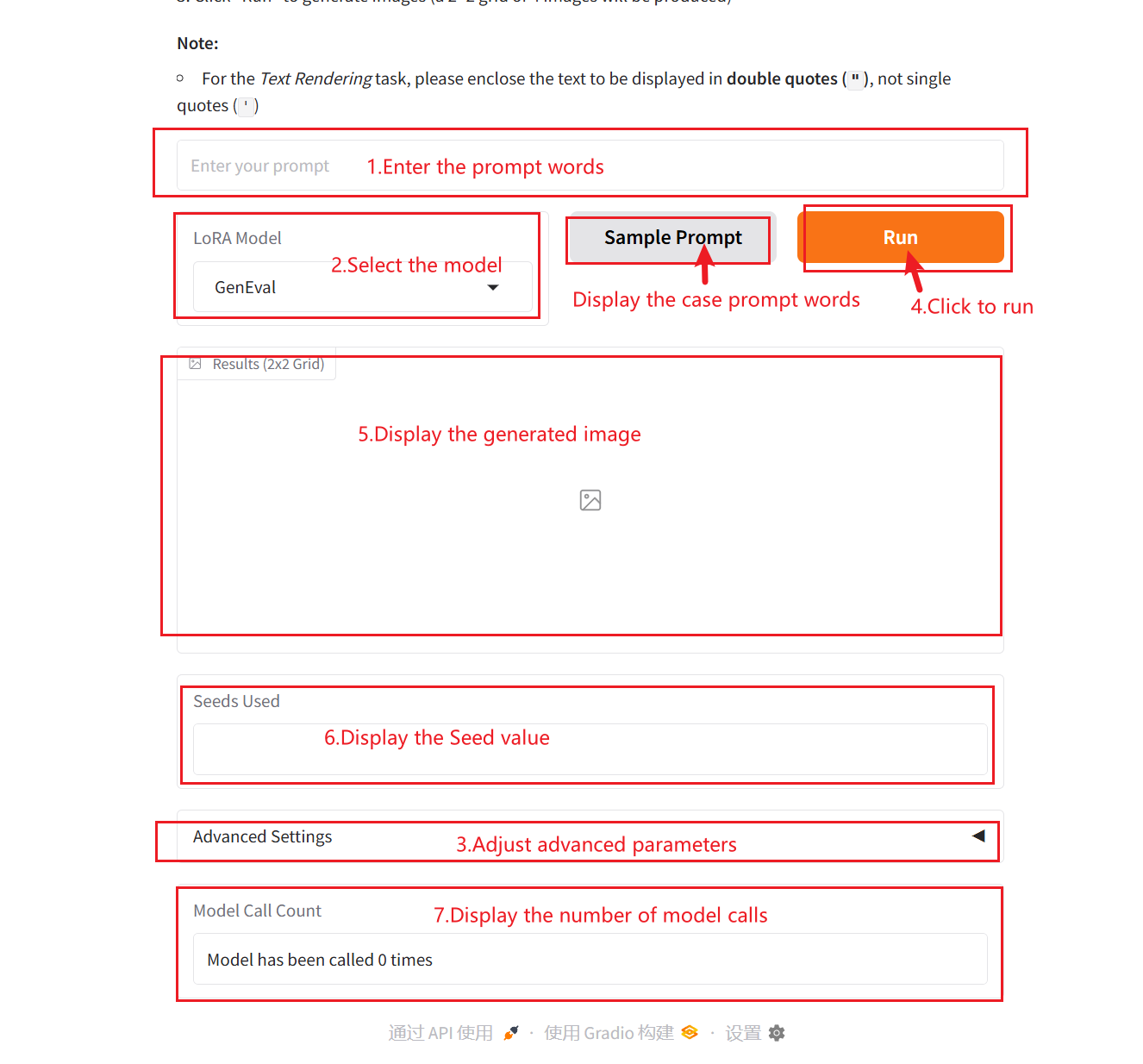
パラメータの説明:
- LoRA モデル:
- なし: 基本モデルはネイティブに呼び出され、最適化戦略は導入されません。
- ジェネラルエバル: 複雑なシナリオの生成と検証をサポートするために、6次元の評価システムが構築されています。
- テキストレンダリング: 正確なテキスト視覚化により、グラフィックとテキスト コンテンツを正確にマッピングできます。
- 人間の好みの調整: 美的嗜好の定量的な調整と統合されたPickScore評価フレームワーク
- 開始シード: 生成プロセスのランダム性を制御するために使用される乱数シード。同じシード値では同じ結果が生成されます (他のパラメータが同じである場合)。これは、結果を再現する上で非常に重要です。
- 幅: 生成される画像の幅を制御するために使用されます。
- 身長: 生成された画像の高さを制御するために使用されます。
- ガイダンススケール: これは、生成モデル内の条件付き入力 (テキストや画像など) が生成される結果に影響を与える度合いを制御するために使用されます。ガイダンス値を高くすると、生成される結果が入力条件に近くなりますが、値を低くするとランダム性が高まります。
- 推論ステップ数: モデルの反復回数または推論プロセスのステップ数を表し、モデルが結果を生成するために使用する最適化ステップの数を表します。通常、ステップ数が多いほど、より正確な結果が生成されますが、計算時間が長くなる可能性があります。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
Githubユーザーに感謝 xxxjjjyyy1 このチュートリアルの展開。このプロジェクトの引用情報は次のとおりです。
@misc{liu2025flowgrpo,
title={Flow-GRPO: Training Flow Matching Models via Online RL},
author={Jie Liu and Gongye Liu and Jiajun Liang and Yangguang Li and Jiaheng Liu and Xintao Wang and Pengfei Wan and Di Zhang and Wanli Ouyang},
year={2025},
eprint={2505.05470},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.05470},
}