HyperAI
Command Palette
Search for a command to run...
OpenAudio-s1-mini: 高効率TTS生成ツール
1. チュートリアルの概要

このチュートリアルでは、単一の RTX 4090 カードのリソースを使用します。
2. プロジェクト例
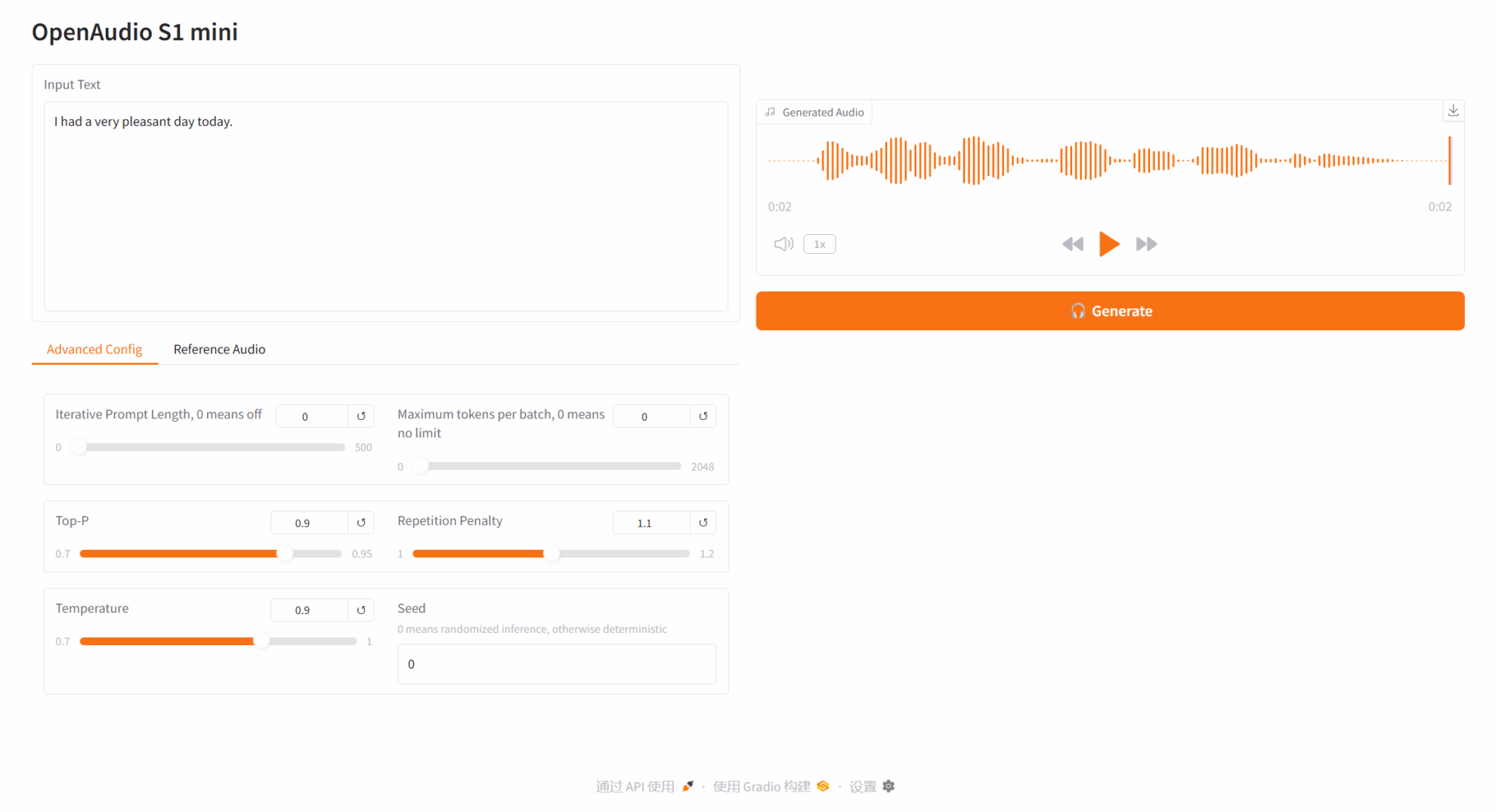
テキスト読み上げ

3. 操作手順
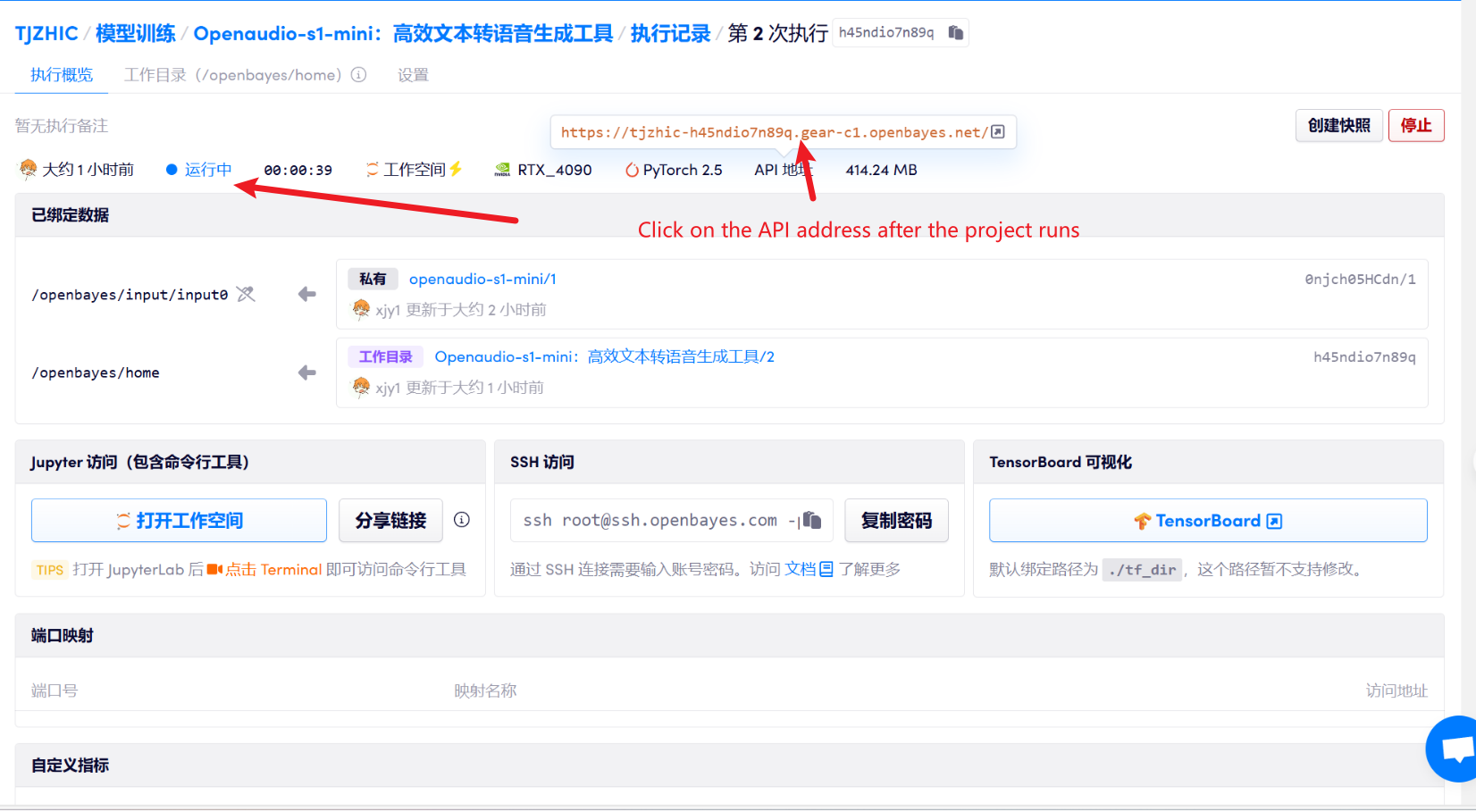
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. ウェブページに入ると、モデルを使用できます
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。 Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
利用手順
2.1 テキストから音声へ
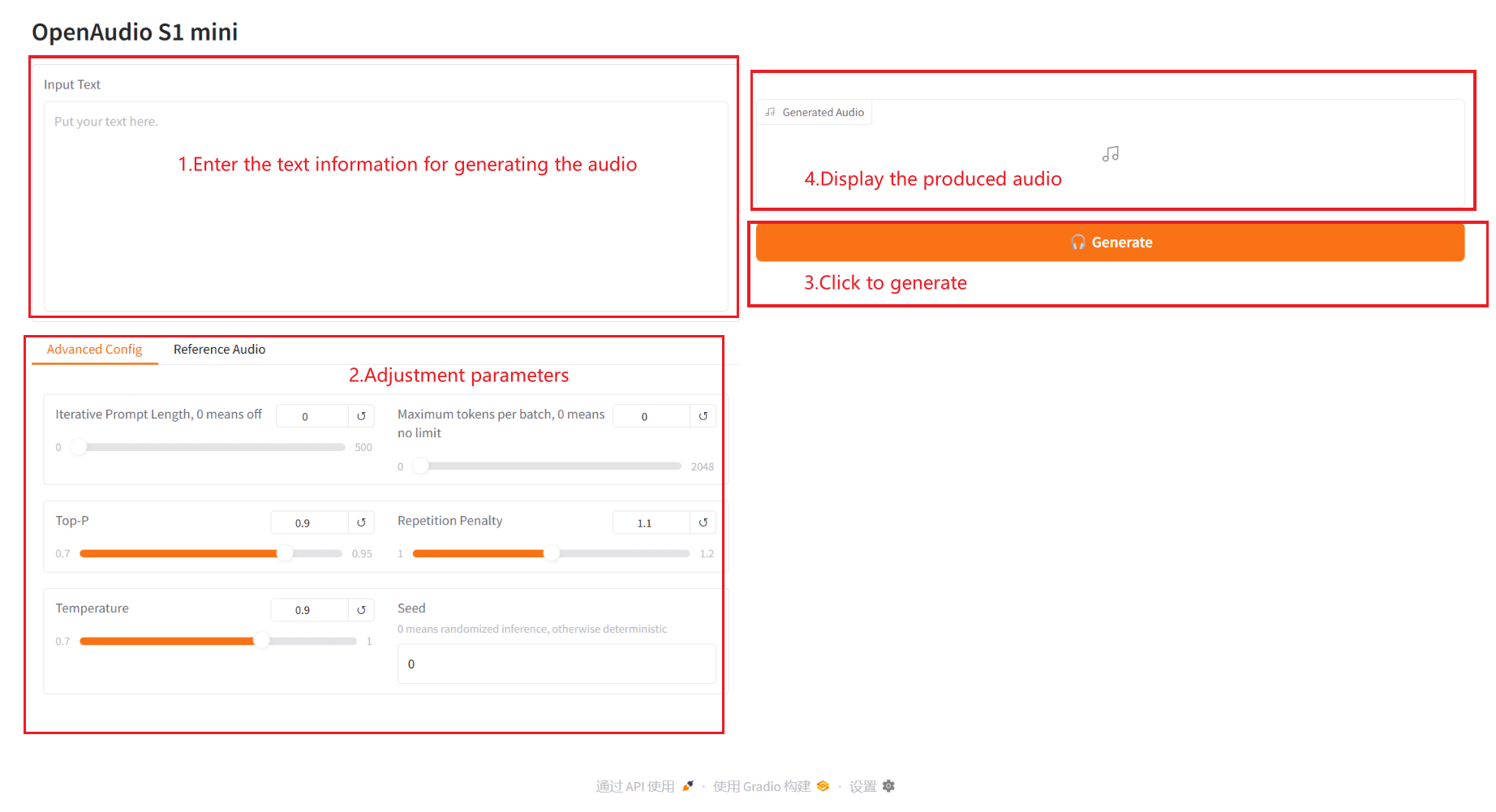
パラメータの説明:
- 詳細設定:
- 反復プロンプトの長さ: 反復プロンプトの長さ。0 はオフを意味します。0 以外の値は、音声を反復的に生成する際に毎回使用されるプロンプトテキストの長さを制御します。
- バッチあたりの最大トークン数: バッチあたりのトークンの最大数。0 は無制限を意味します。0 以外の値を指定すると、バッチあたりに処理されるトークンの最大数が制限されます。
- 上部 – P: 生成されるテキストの多様性と確実性を制御するカーネル サンプリング確率。
- 繰り返しペナルティ: 生成されたテキストにおける繰り返しコンテンツの頻度を制御するために使用される繰り返しペナルティ係数。値が大きいほど、繰り返しが回避されます。
- 温度: 生成されるテキストのランダム性を調整する温度係数。値が大きいほど、ランダム性が増します。
- シード: 再現可能な結果を確保するために固定の乱数を生成するために使用されるランダム シード。
- 参考音声:
- メモリ キャッシュを使用する: メモリ キャッシュを使用するかどうかを選択します。
- 参照オーディオ: サウンド コンテンツの参照として使用するオーディオ ファイル (wav ファイル) をアップロードします。
- 参照テキスト: アップロードしたオーディオのテキスト コンテンツを入力します。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。