HyperAI
Command Palette
Search for a command to run...
ShowUI: GUI 自動化に焦点を当てた視覚言語アクション モデル

1. チュートリアルの概要

ShowUIは、シンガポール国立大学のShow LabとMicrosoftが2024年に共同開発した視覚・言語・動作モデルで、グラフィカルユーザーインターフェース(GUI)インテリジェントアシスタント向けに設計されており、人間の作業効率を向上させます。このモデルは、画面インターフェースの内容を理解し、クリック、入力、スクロールなどのインタラクティブな動作を実行します。Webアプリケーションとモバイルアプリケーションの両方のシナリオをサポートし、複雑なユーザーインターフェースタスクを自動的に完了できます。ShowUIは、スクリーンショットとユーザーコマンドを解析して、インターフェース上のインタラクティブな動作を予測できます。関連する研究論文も入手可能です。 ShowUI: GUI ビジュアル エージェント用の 1 つのビジョン、言語、アクション モデル CVPR 2025 に含まれています。
このチュートリアルでは、デフォルトのリソースとして単一の RTX 5090 グラフィック カードを使用しますが、プログラムの起動には、最小で単一の RTX 4090 グラフィック カードも使用できます。
2. プロジェクト例
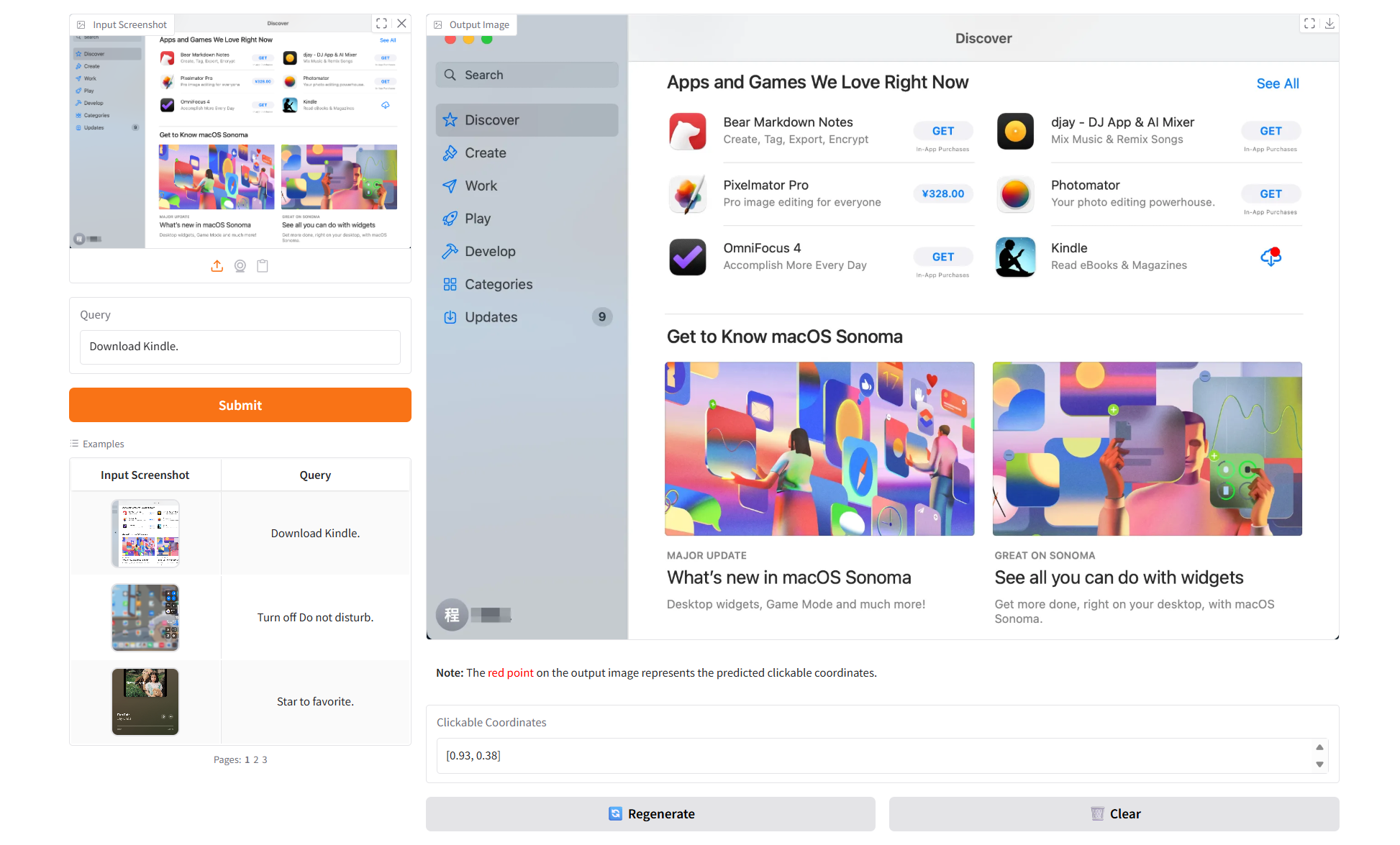
3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
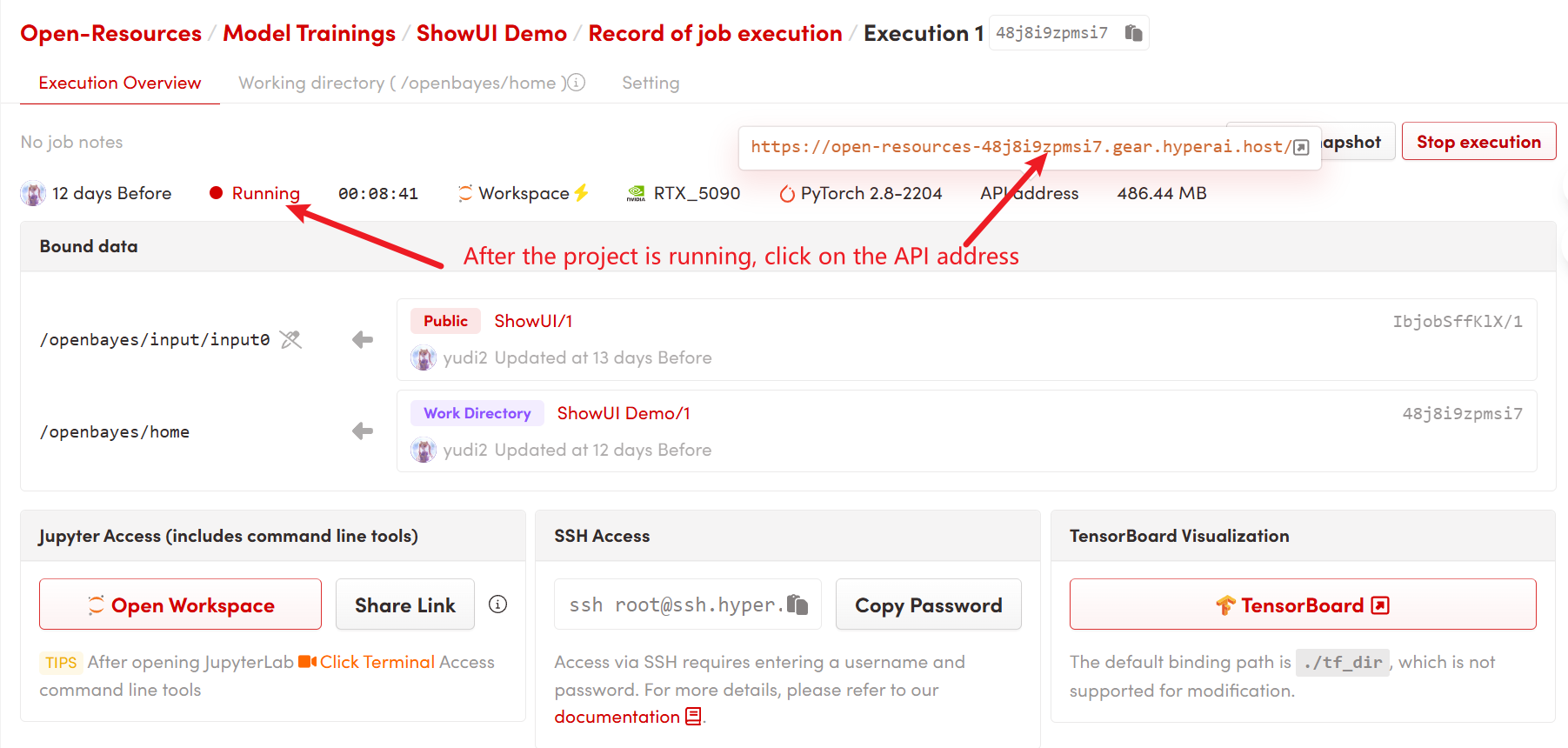
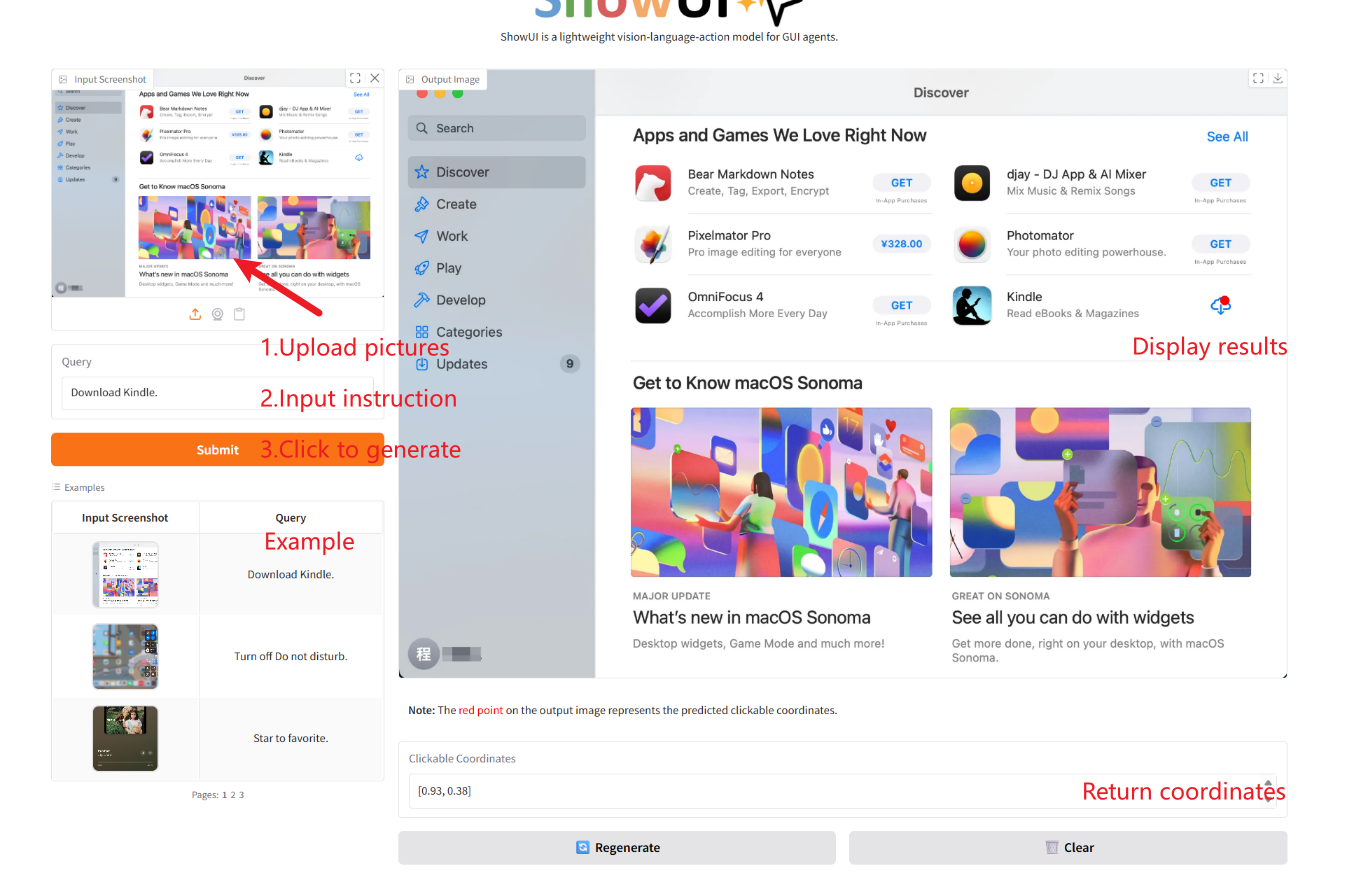
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
引用情報
@misc{lin2024showui,
title={ShowUI: One Vision-Language-Action Model for GUI Visual Agent},
author={Kevin Qinghong Lin and Linjie Li and Difei Gao and Zhengyuan Yang and Shiwei Wu and Zechen Bai and Weixian Lei and Lijuan Wang and Mike Zheng Shou},
year={2024},
eprint={2411.17465},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.17465},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。