HyperAI
Command Palette
Search for a command to run...
POINTS-Reader: エンドツーエンドの蒸留フリーアーキテクチャを備えた軽量のドキュメントビジョン言語モデル
1. チュートリアルの概要

POINTS-Readerは、テンセント、上海交通大学、清華大学が2025年8月に共同でリリースした軽量な視覚言語モデル(VLM)で、文書画像をテキストに変換することに特化して設計されています。POINTS-Readerは、膨大なパラメータ数や教師モデルの「蒸留」を追求するのではなく、2段階の自己進化型フレームワークを採用することで、表、数式、複数段組みレイアウトを含む複雑な中国語および英語文書を、最小限の構造を維持しながら高精度にエンドツーエンドで認識します。関連研究論文も公開されています。 POINTS-Reader: 文書変換のためのビジョン言語モデルの蒸留フリー適応 これはEMNLP 2025に採択されており、メインカンファレンスで発表される予定です。
このチュートリアルで使用されるコンピューティング リソースは、単一の RTX 4090 カードです。
2. エフェクト表示
ラテックス式による単一列

単一列テーブル
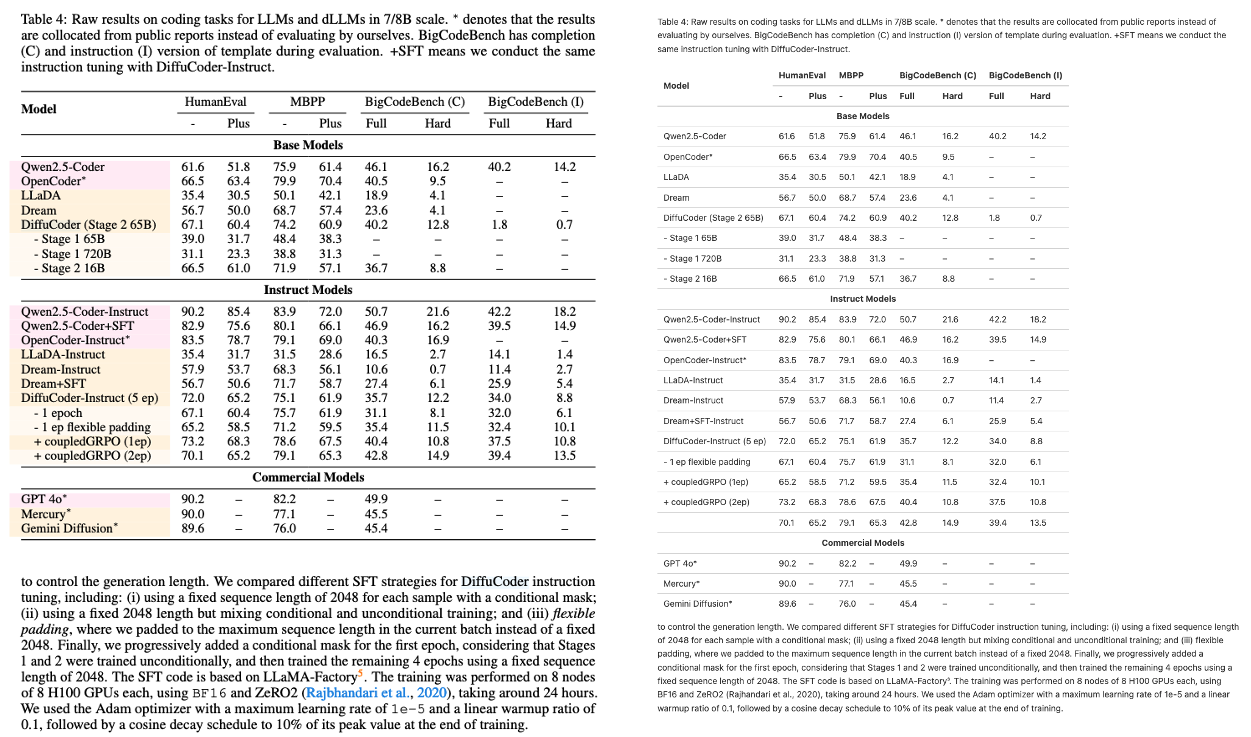
Latex式による複数列

表付き複数列
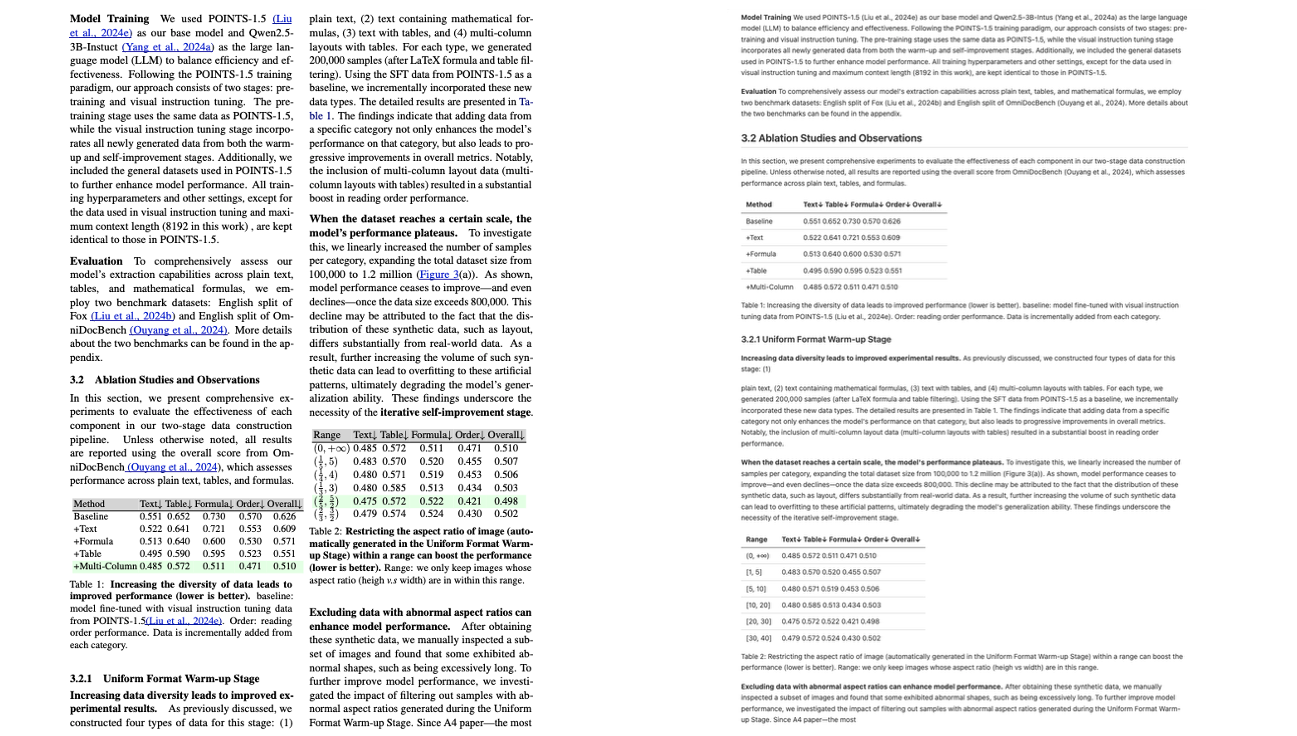
3. 操作手順
1. コンテナを起動します
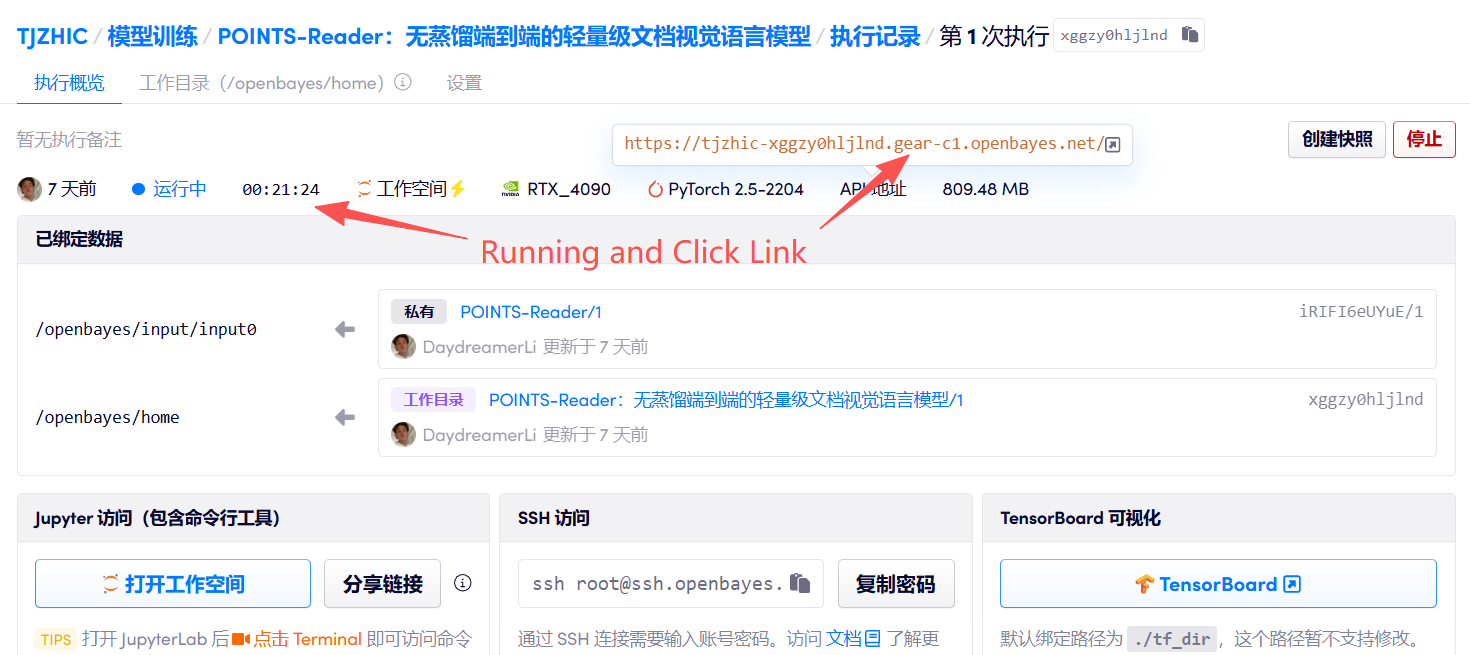
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
1. 抽出されたコンテンツ
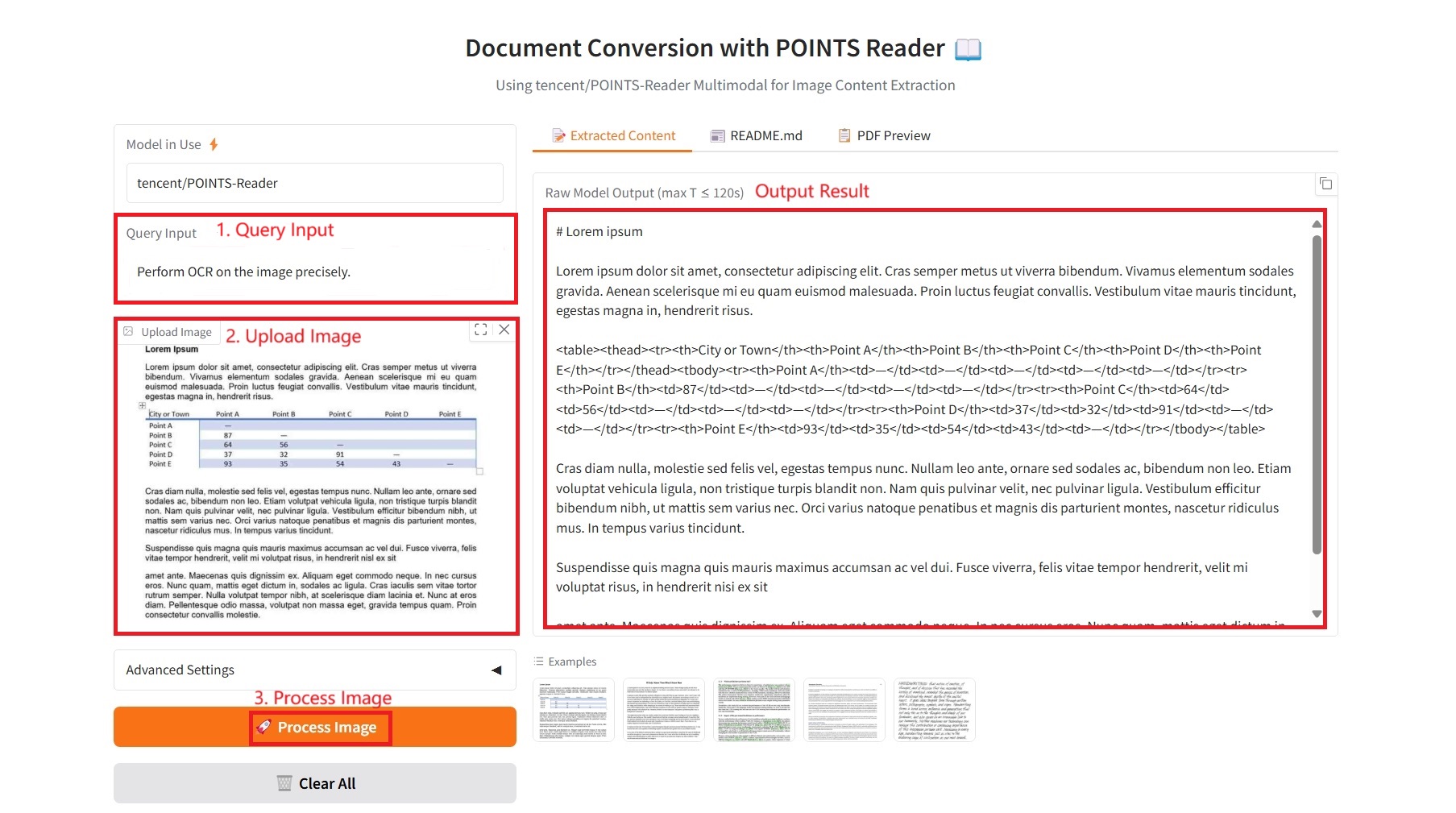
具体的なパラメータ:
- クエリ入力: テキスト要件を入力します。
- 画像拡大係数: 処理前に画像サイズを拡大します。小さなテキストのOCR精度が向上します。デフォルト: 1.0 (変更なし)。
- 最大新規トークン数: 生成されるテキストの最大長制限。出力コンテンツの単語数の上限を制御します。
- Top-p (核サンプリング): 出力の多様性を制御するために、サンプリングに累積確率 p を持つ最小の単語セットを選択する核サンプリング パラメーター。
- Top-k: 最も確率の高いk個の候補単語から抽出します。値が大きいほど出力はランダムになり、値が小さいほど出力は確実になります。
- 温度: 生成されるテキストのランダム性を制御します。値が高いほどランダムで多様な出力になり、値が低いほど決定論的で保守的な出力になります。
- 重複ペナルティ: 1.0 より大きい値を設定すると、重複コンテンツの生成が減少します。値が大きいほど、ペナルティは大きくなります。
- PDFエクスポート設定:
- フォント サイズ: PDF 内のテキストのフォント サイズ。エクスポートされたドキュメントの読みやすさを制御します。
- 行間隔: PDF 内の段落間の行間隔は、ドキュメントの美観と読みやすさに影響します。
- テキスト配置: 左揃え、中央揃え、右揃え、両端揃えなど、PDF 内のテキストの配置。
- PDF 内の画像サイズ: PDF に埋め込まれた画像のサイズ (小、中、大のオプションを含む)。
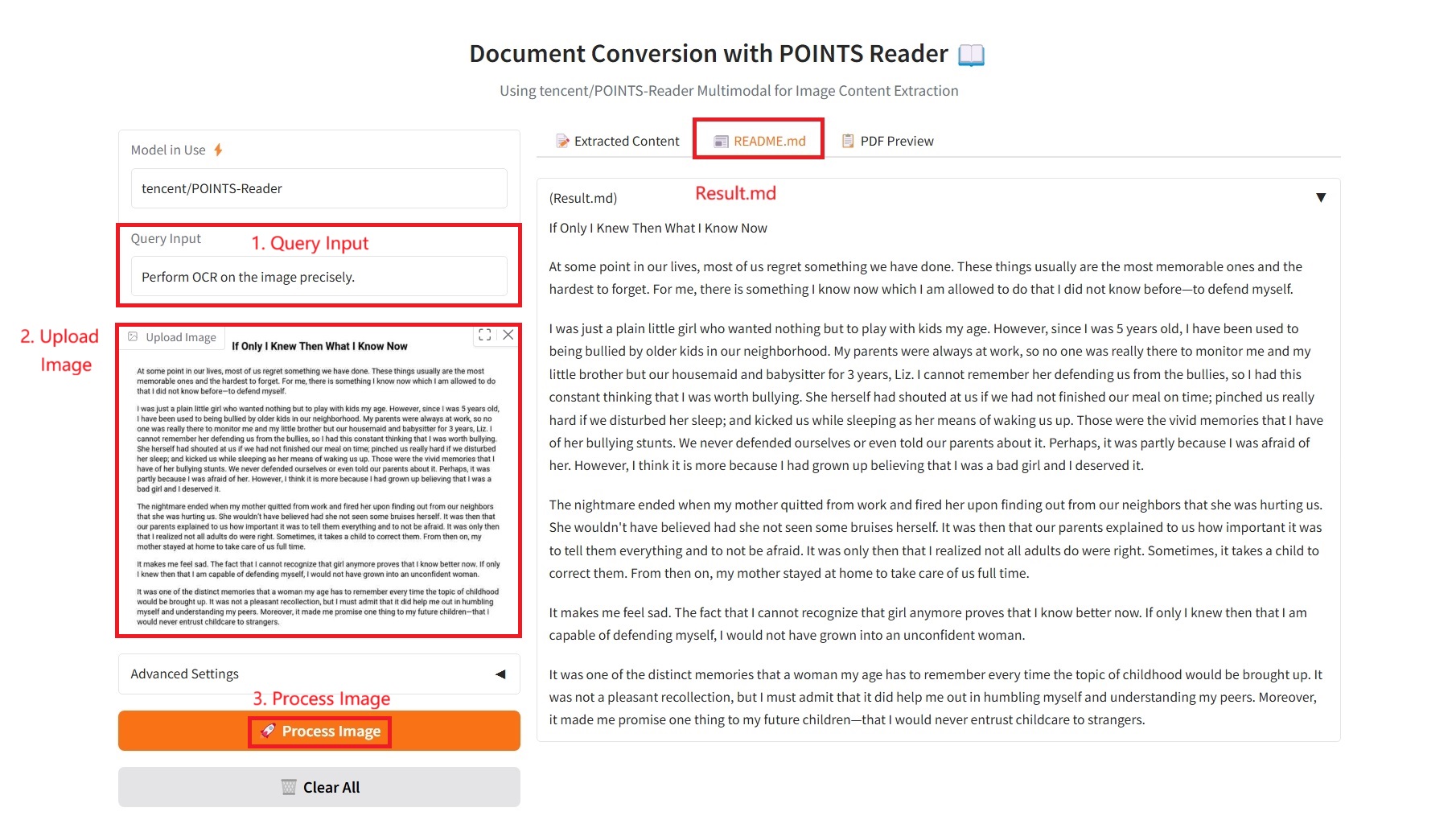
2. README.md
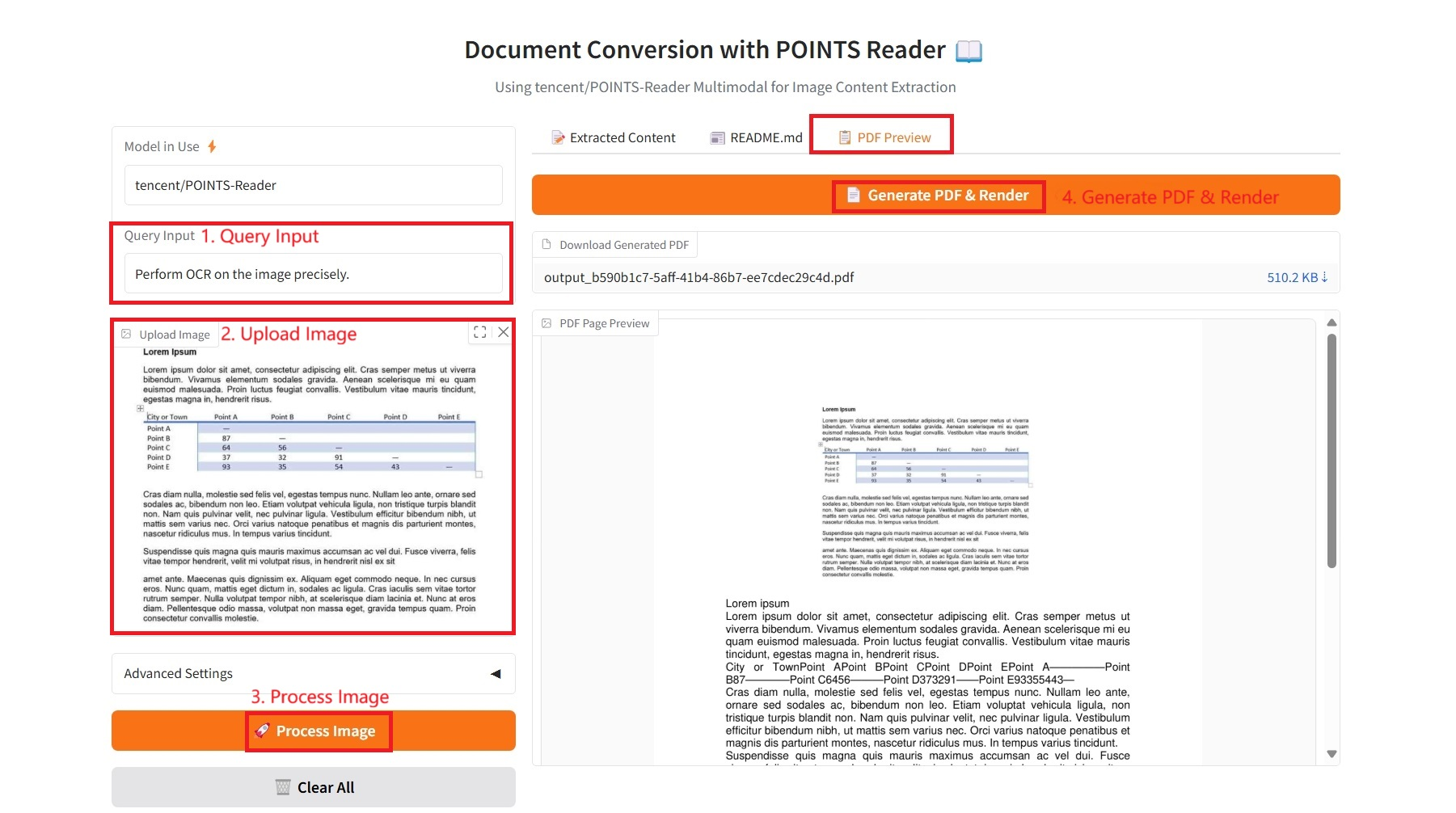
3. PDFプレビュー
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。