Command Palette
Search for a command to run...
オンラインチュートリアル | 最大4倍の高速生成速度:DiffusionGemmaは、複数ラウンドの並列ノイズ除去に基づく継続的な最適化により、テキストのブロック全体を同時に生成できます。

6月11日、Googleは離散拡散技術をベースとしたテキスト生成モデル「DiffusionGemma」を正式にオープンソース化しました。このモデルは、業界をリードするGemma 4シリーズのパラメータごとのインテリジェンス機能と最先端のGemini Diffusion研究を活用し、新しい拡散ヘッドを統合することで生成速度を最大化しています。従来のテキストをトークンごとに出力する大規模モデルとは異なり、テキストブロック全体を同時に生成し、複数回の並列ノイズ除去処理によって結果を継続的に最適化できます。これにより、発電速度が最大4倍向上する。
公式データによると、DiffusionGemmaは単一のNVIDIA H100 GPUで1秒あたり1100トークン以上、GeForce RTX 5090で1秒あたり700トークン以上の生成速度を達成でき、同レベルの自己回帰モデルをはるかに凌駕している。
建築的な観点から見ると、DiffusionGemmaは、26Bパラメータレベルのハイブリッドエキスパート(MoE)設計を採用しています。パラメータの総数は約252億個ですが、推論時にアクティブになるのはわずか38億個であるため、強力な推論能力を維持しながら計算オーバーヘッドを大幅に削減できます。このモデルはエンコーダー・デコーダー構造に基づいて構築されており、双方向アテンション機構を組み込んでいるため、256個のトークンを同時に並列処理できます。また、インラインテキスト編集、コード補完、数式構造生成など、グローバルコンテキストに大きく依存するタスクもサポートしています。
さらに、DiffusionGemmaは最大256Kトークンの長いコンテキスト、マルチモーダルなグラフおよびテキスト入力、<|think|>によってアクティブ化される推論モードをサポートしており、開発者に次世代の高効率AIアプリケーションを探求するための新しいテクノロジーオプションを提供します。
Googleは、生成される品質の点で標準のGemma 4が本番環境により適していると依然として強調しているものの、DiffusionGemmaによって実証された拡散ベースのテキスト生成機能は、大規模言語モデルの開発において、注目すべき新たな道を開く可能性がある。
開発者が最小限の労力でDiffusionGemmaを体験できるようにするため、HyperAIはモデルのオープンソース化後すぐに対応し、NVIDIA RTX Pro 6000グラフィックカード1枚だけでモデルの強力な機能を検証できる、簡単に導入できるノートブックをリリースしました。
オンラインで実行:https://go.hyper.ai/879dB
その他のオンラインチュートリアル:
デモの実行
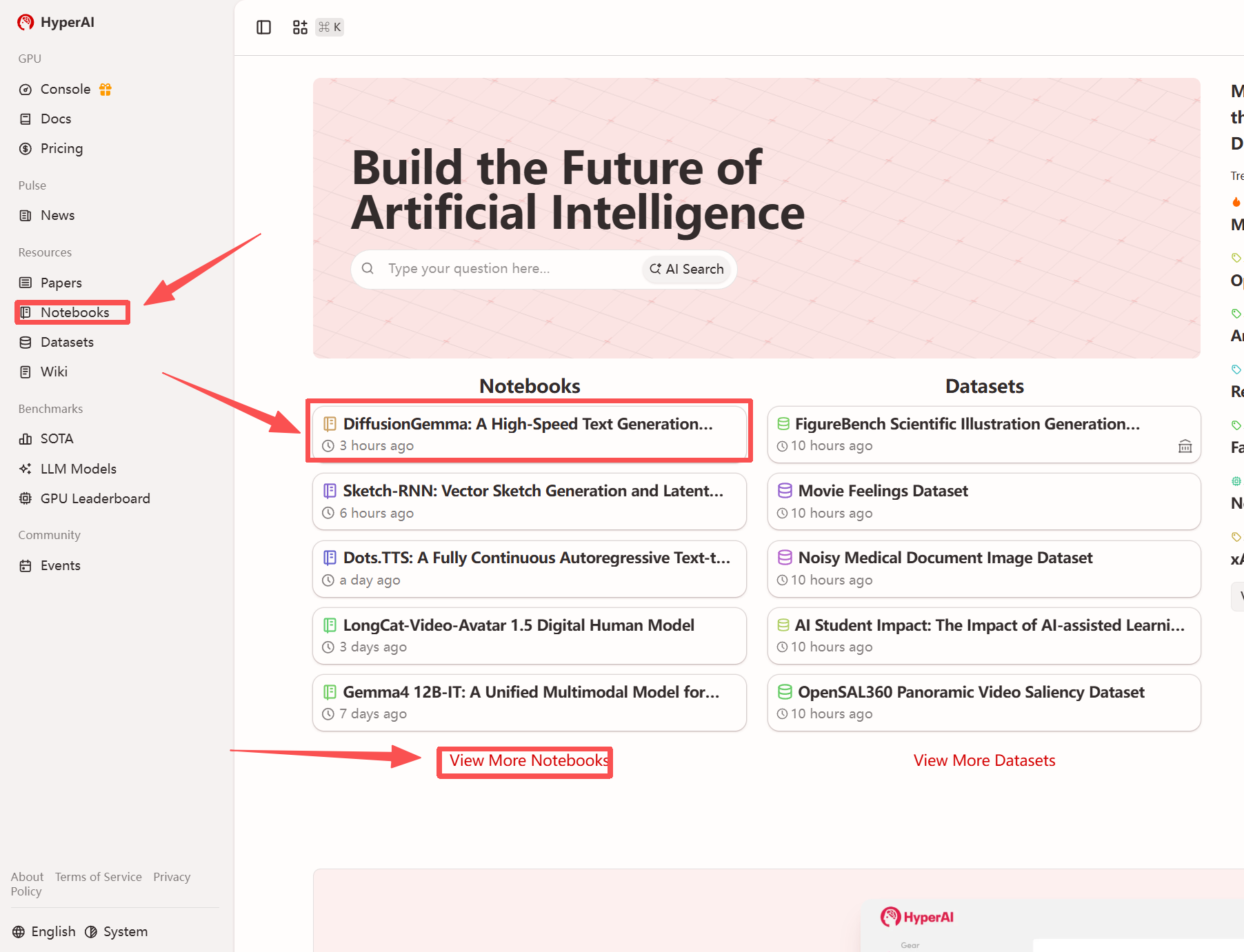
1. hyper.ai のホームページにアクセスしたら、「チュートリアル」ページを選択するか、「その他のチュートリアルを見る」をクリックし、「DiffusionGemma: 離散拡散に基づく高速テキスト生成モデル」を選択して、「このチュートリアルを実行する」をクリックします。
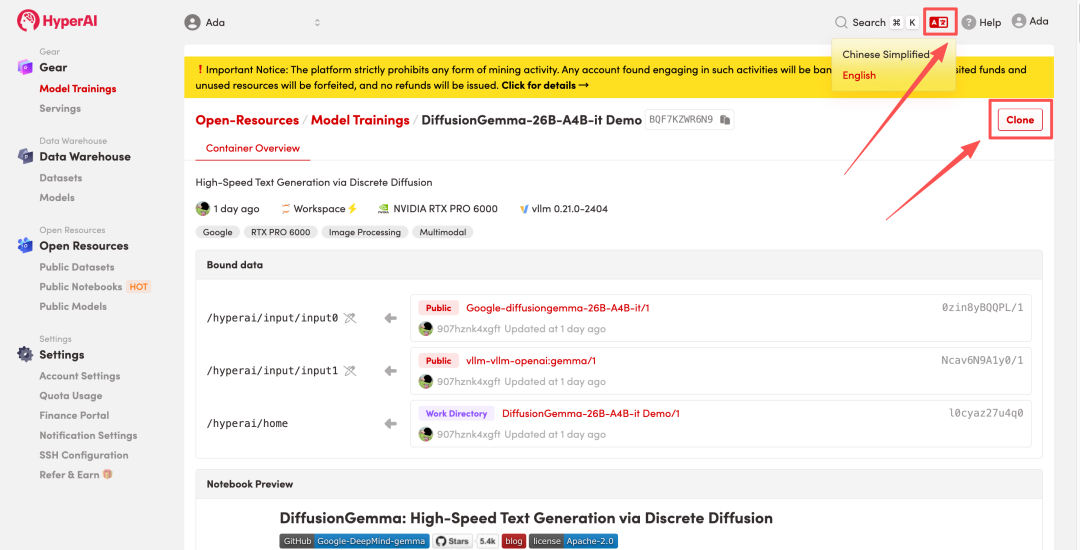
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
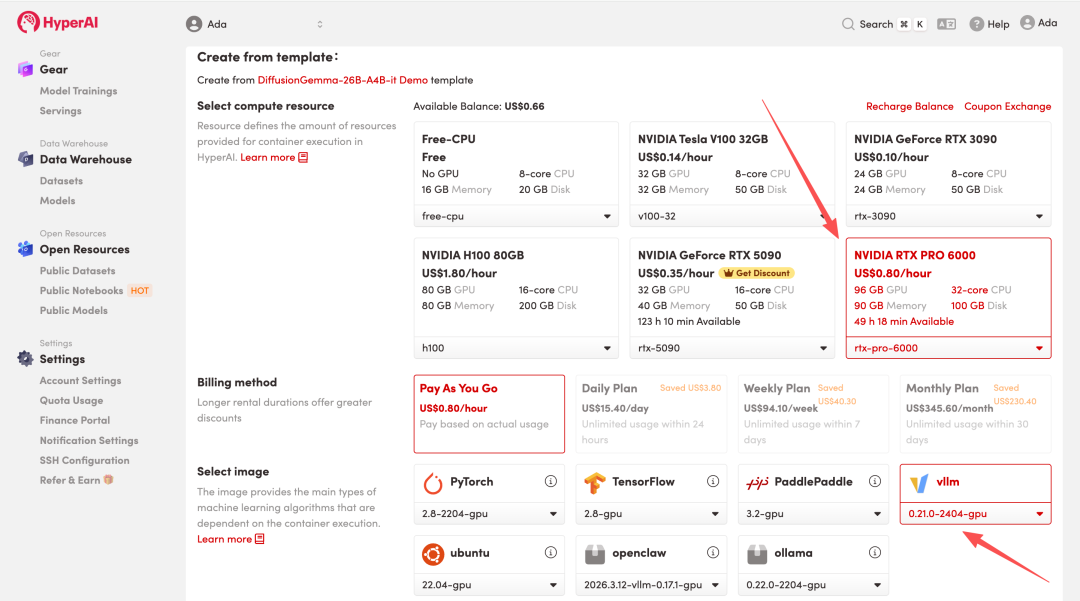
3. 「NVIDIA RTX Pro 6000」と「vLLM」のイメージを選択し、「ジョブの実行を続行」をクリックします。
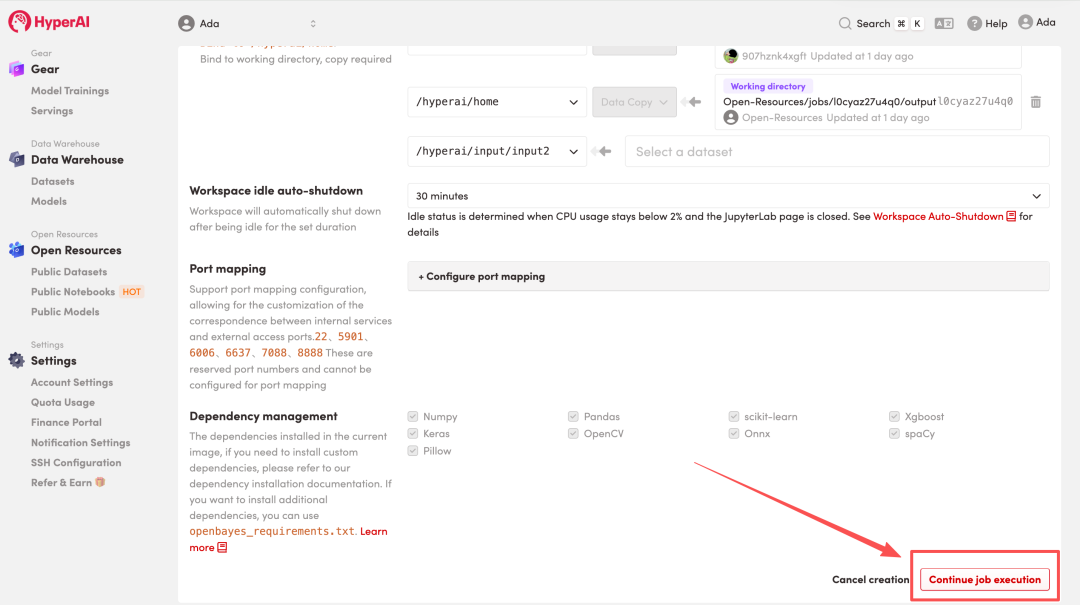
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
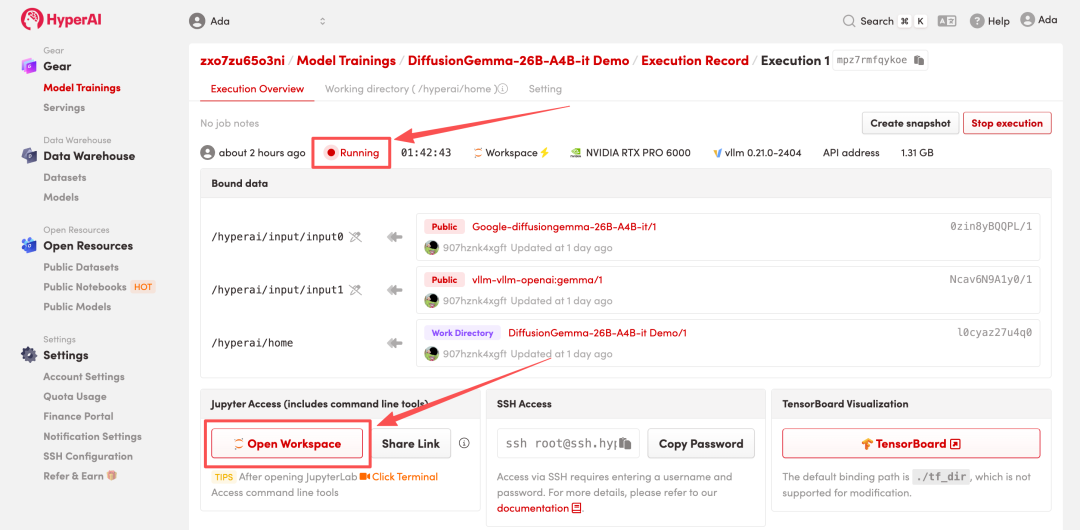
エフェクト表示
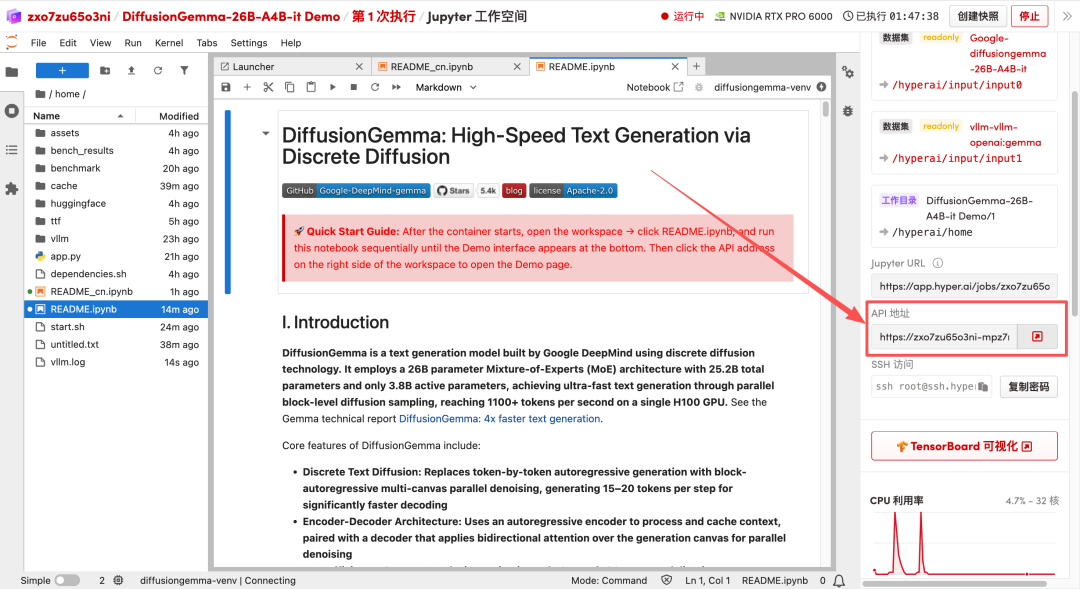
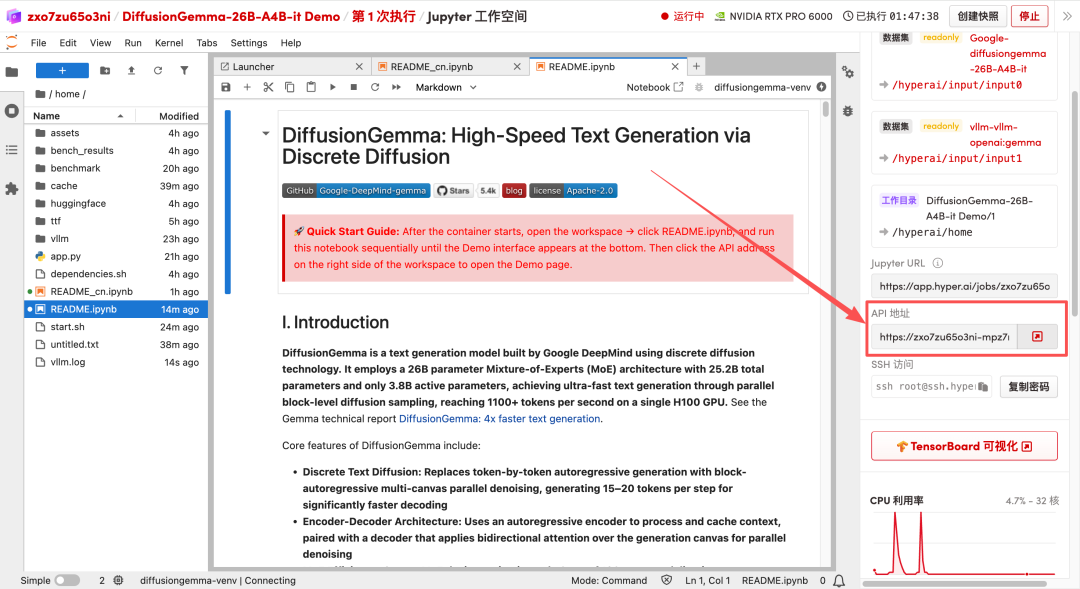
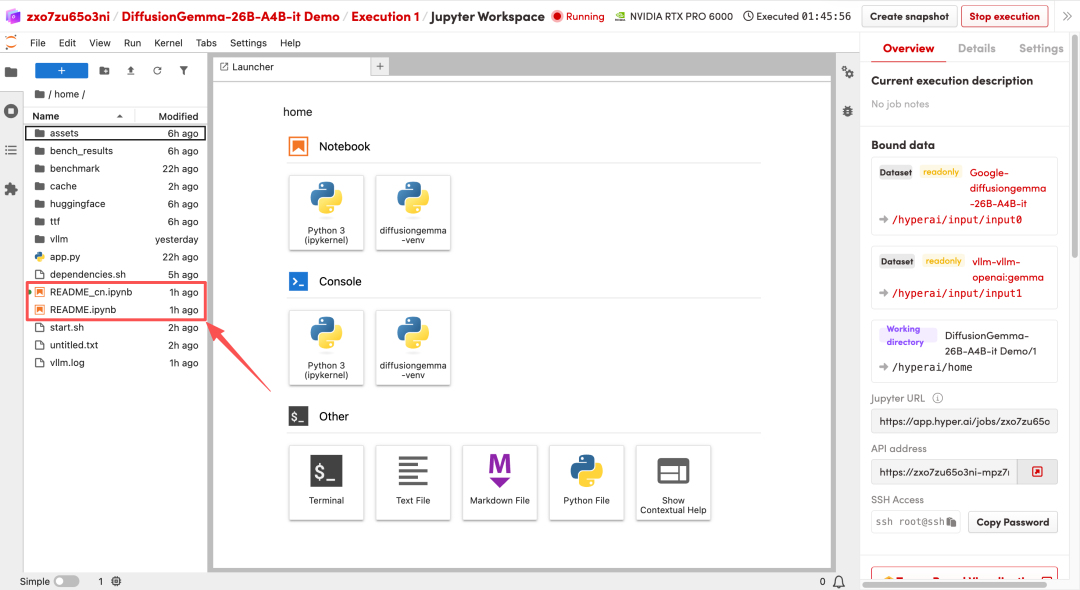
1. ページがリダイレクトされたら、左側のREADMEファイルをクリックし、上部の「実行」をクリックします。
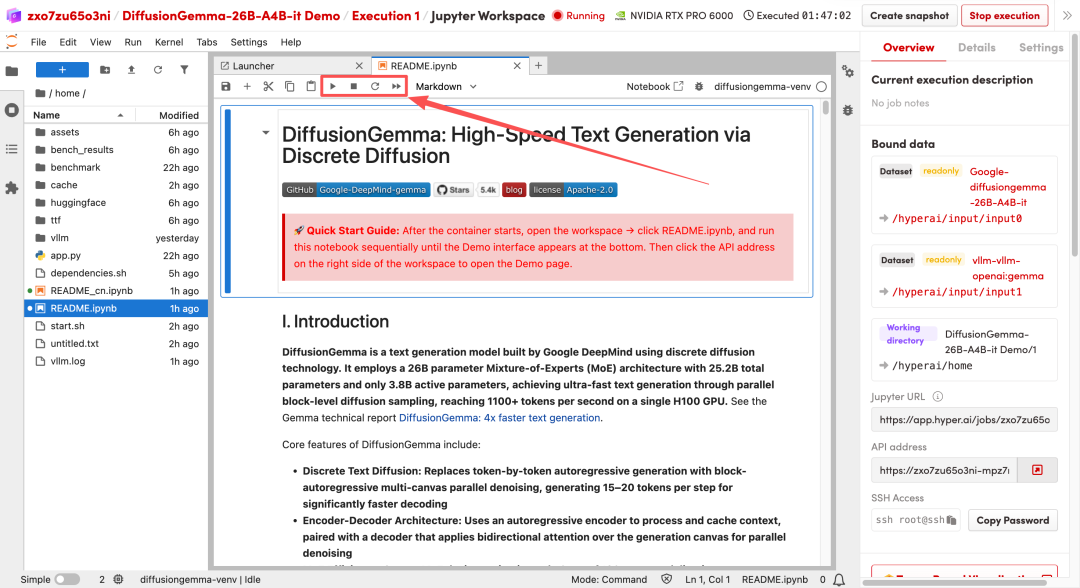
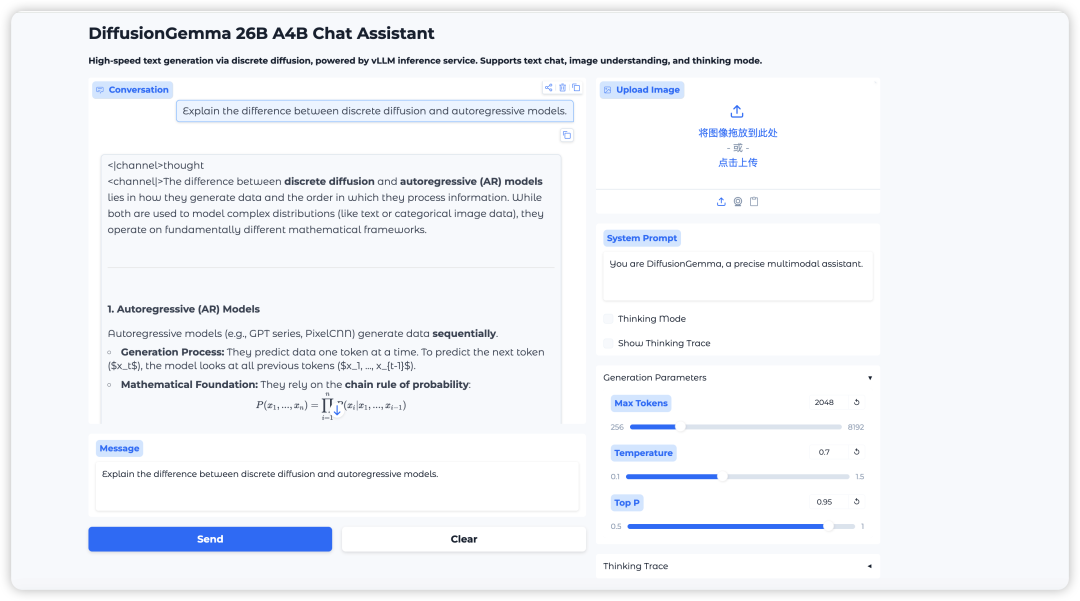
2. 処理が完了したら、右側のAPIアドレスをクリックしてデモインターフェースを開きます。