Command Palette
Search for a command to run...
Meituan のオープンソース ビデオ生成モデルである LongCat-Video は、テキストベースのビデオ生成、画像ベースのビデオ生成、ビデオ継続機能を組み合わせ、トップレベルのオープンソース モデルやクローズドソース モデルに匹敵します。

ワールドモデルは、複雑な現実世界の環境を理解、シミュレーション、予測することを目的としており、現実世界のシナリオにおける人工知能の効果的な応用のための重要な基盤となります。このフレームワークにおいて、ビデオ生成モデルは、生成プロセスを通じて、幾何学的要素、意味的要素、物理的要素を含む様々な知識形式を段階的に圧縮・学習します。したがって、これは世界モデルを構築するための重要な道筋とみなされており、最終的には現実の物理世界のダイナミクスの効果的なシミュレーションと予測を実現することが期待されています。動画生成の分野では、長時間の動画を効率的に生成する機能を実現することが特に重要です。
これに基づいて、Meituan は、最新のビデオ生成モデルである LongCat-Video をオープンソース化しました。これは、テキストからビデオ、画像からビデオ、ビデオの継続など、統一されたアーキテクチャを通じてさまざまなビデオ生成タスクを処理することを目的としています。LongCat-Video は、一般的なビデオ生成タスクにおける優れたパフォーマンスに基づき、真の「世界モデル」の構築に向けた確かな一歩であると研究チームから評価されています。
LongCat-Video の主な機能は次のとおりです。
* 複数のタスクのための統一されたアーキテクチャ。 LongCat-Video は、テキストベースのビデオ、画像ベースのビデオ、およびビデオ継続タスクを単一のビデオ生成フレームワーク内に統合し、条件付きフレームの数によって区別します。
* 長時間のビデオ生成機能。 LongCat-Video は、ビデオ継続タスクに基づいて事前トレーニングされており、数分間のビデオを生成し、生成プロセス中に色の歪みやその他の形式の画質低下を効果的に回避できます。
* 効率的な推論。 LongCat-Video は、「粗から細へ」戦略を採用し、わずか数分で 720p、30fps のビデオを生成し、ビデオ生成の精度と効率を効果的に向上させます。
* マルチ報酬強化学習フレームワーク (RLHF) の強力なパフォーマンス。 LongCat-Video は、グループ相対ポリシー最適化 (GRPO) を採用しており、複数の報酬を使用することでモデルのパフォーマンスをさらに強化し、主要なオープンソースのビデオ生成モデルや最新の商用ソリューションに匹敵するパフォーマンスを実現します。
内部ベンチマークパフォーマンス評価に基づくと、LongCat-Video はテクスチャビデオタスクで優れたパフォーマンスを発揮します。ビジュアルとモーション品質の両方で非常に優れたパフォーマンスを発揮し、最上位モデルである Wan2.2 とほぼ同等のスコアを獲得しています。このモデルは、テキストの配置と全体的な品質においても堅牢な結果を達成し、複数の側面にわたって一貫した高品質のエクスペリエンスをユーザーに提供しました。
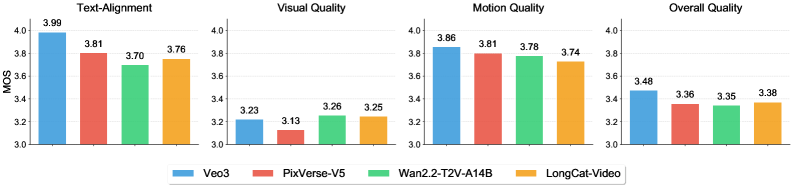
画像から動画への変換タスクにおいて、LongCat-Videoは画質において際立っており、Wan2.2などの他のモデルを凌駕し、高画質画像の生成において大きな優位性を示しています。しかしながら、画像の位置合わせや全体的な品質といった分野では、依然として改善の余地があります。

最近、Cloudflareで障害が発生し、X、ChatGPT、Canvaなど、幅広いインターネットアプリケーションで接続障害が発生しました。LongCat-Videoが障害時の対応をシミュレーションした様子を見てみましょう👇
現在、「LongCat-Video:MeituanのオープンソースAI動画生成モデル」は、HyperAIウェブサイトの「チュートリアル」セクションで公開されています。以下のリンクをクリックして、ワンクリックでデプロイできるチュートリアルをお試しください⬇️
チュートリアルのリンク:
デモの実行
1. hyper.aiホームページにアクセス後、「LongCat-Video:MeituanのオープンソースAIビデオ生成モデル」を選択するか、「チュートリアル」ページに移動して選択し、「このチュートリアルをオンラインで実行」をクリックします。


2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。

3.「NVIDIA RTX PRO 6000 Blackwell」と「PyTorch」のイメージを選択し、必要に応じて「Pay As You Go」または「Daily Plan/Weekly Plan/Monthly Plan」を選択し、「ジョブ実行を続行」をクリックします。


4. リソースの割り当てをお待ちください。最初のクローン作成には約3分かかります。ステータスが「実行中」に変わったら、「APIアドレス」の横にあるジャンプ矢印をクリックしてデモページに移動してください。

効果実証
デモインターフェースに入ると、テスト用に「Image-to-Video」「Text-to-Video」「Long Video」「Video Continuation」の4つのサンプルから選択できます。この記事では例として「Image-to-Video」を選択します。
サンプル画像をアップロードした後、「プロンプト」を入力します。「詳細オプション」では、ネガティブプロンプト、解像度、生成プロセスにおけるランダム性の開始点など、より理想的な生成効果を実現するためのパラメータをさらに設定できます。


最近、Cloudflareで障害が発生し、X、ChatGPT、Canvaなど、幅広いインターネットアプリケーションで接続障害が発生しました。LongCat-Videoによる、この障害に対するユーザーの反応のシミュレーションを見てみましょう👇
以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
チュートリアルのリンク:








