Command Palette
Search for a command to run...
DeepMindは、あらゆるモダリティと細胞タイプにおける突然変異の影響を1秒で予測するAlphaGenomeをリリースしました。

Google DeepMindのAlphaシリーズに新しいメンバー、AlphaGenomeが加わりました。これにより、人間の DNA 配列における単一の変異や突然変異が、遺伝子を制御する一連の生物学的プロセスにどのように影響するかをより包括的かつ正確に予測できるようになります。
AlphaGenome モデルは、最大 100 万塩基対の DNA 配列を入力として受け取り、その調節活動に関連する数千の分子特性を予測します。同時に、遺伝子変異や突然変異の影響は、変異配列と非変異配列の予測結果を比較することで評価できます。このモデルは、DeepMindの既存のゲノムモデルEnformerをベースに構築されており、タンパク質コード領域の変異の分類に重点を置いたAlphaMissenseモデルを補完します。
論文の共同筆頭著者であるジュン・チェン氏は、自身のXアカウントで、「RNAスプライシングエラーは多くの疾患の共通の原因です。私たちは初めて、RNA-seqのカバレッジ、スプライシング部位、部位利用、そしてそれらが形成する特定のスプライシングジャンクションを同時に予測できる統合モデルを構築しました。これにより、スプライシング結果の全体像をより包括的に描写できます」と述べています。また、AlphaGenome の重要なブレークスルーの 1 つは、「配列から直接スプライシング ジャンクションを予測し、それを使用して変異の影響を予測する機能」です。
「これはこの分野における画期的な出来事だ」とメモリアル・スローン・ケタリングがんセンターのカレブ・ラロー医学博士は語った。初めて、長いコンテキスト、単一ベースの精度、最先端のパフォーマンスを組み合わせたモデルが実現しました。DeepMindは、AlphaGenome APIを通じて非商用の研究ユーザー向けにプレビュー版を公開しており、今後モデルを正式にリリースする予定だ。
* 研究論文リンク:
100万のDNA配列と種の情報に基づき、U-Netのような設計を採用
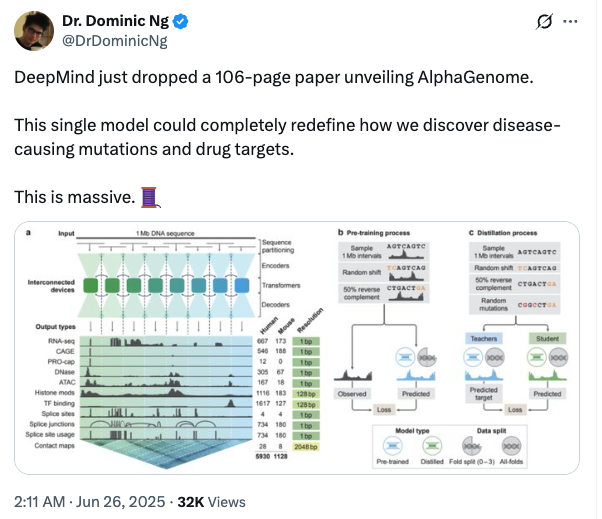
下の図 a に示すように、ディープラーニング モデル AlphaGenome は、1 Mb (百万塩基) の DNA 配列と種の情報 (ヒト/マウス) を入力として受け取ります。異なる細胞タイプの予測のための5,930のヒトゲノム座位または1,128のマウスゲノム座位以下の 11 種類の出力タイプをカバーします。
* 遺伝子発現(RNA-seq、CAGE、PRO-cap)
* 詳細なスプライシングパターン(スプライス部位、スプライス部位の使用頻度、スプライス接合部)
* クロマチン状態(DNase、ATAC-seq、ヒストン修飾、転写因子結合)
* クロマチン接触マップ
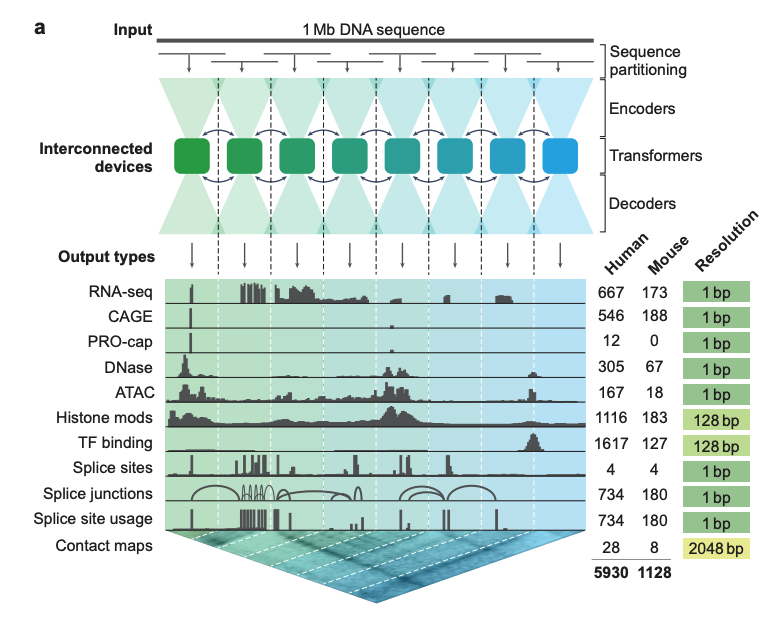
モデルアーキテクチャの観点から言えば、AlphaGenome は、U-Net のようなバックボーン アーキテクチャ設計を採用しています。下の図 a に示すように、入力シーケンスは次の 2 種類のシーケンス表現に効率的に処理できます。
1 次元埋め込み (1 bp および 128 bp の解像度): 線形ゲノム配列を表し、ゲノム軌跡の予測を生成するために使用されます。
* 2次元埋め込み(解像度 2048 bp):ゲノム断片間の空間的相互作用を表し、ペアワイズ接触マップを予測するために使用されます。
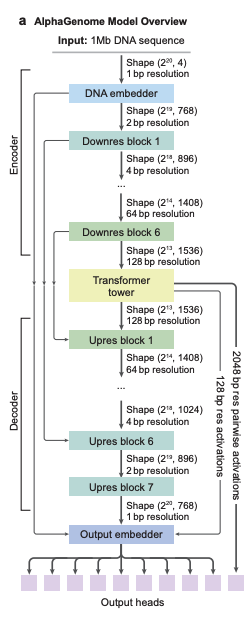
モデルの畳み込み層は、局所的な配列パターンをモデル化することできめ細かな予測をサポートするために使用され、Transformerモジュールは、エンハンサーとプロモーター間の相互作用など、より長距離の依存関係をモデル化するために使用されます。分散型シーケンス並列処理により、このモデルは1MBのシーケンス全体を用いて単一の塩基で学習でき、相互接続された8台のTPUv3デバイスで実行できます。
モデルのトレーニングに関しては、研究者たちは、事前トレーニングと蒸留という2段階のトレーニングを採用しました。事前トレーニング段階では、既存の実験データを使用して、下の図 b に示すように 2 種類のモデルをトレーニングします。
* 折りたたみ専用モデル:学習は4分割交差検証法を用いて実施されました。すなわち、参照ゲノムのセグメントの3/4を学習に使用し、残りの1/4を検証とテストに使用しました。これらのモデルは、未知の参照ゲノムセグメントにおけるゲノムトラジェクトリ予測におけるAlphaGenomeの汎化能力を評価するために使用されました。
* オールフォールドモデル:下の図 c に示すように、次の蒸留段階として、教師モデルは参照ゲノムの利用可能なすべてのセグメントでトレーニングされます。
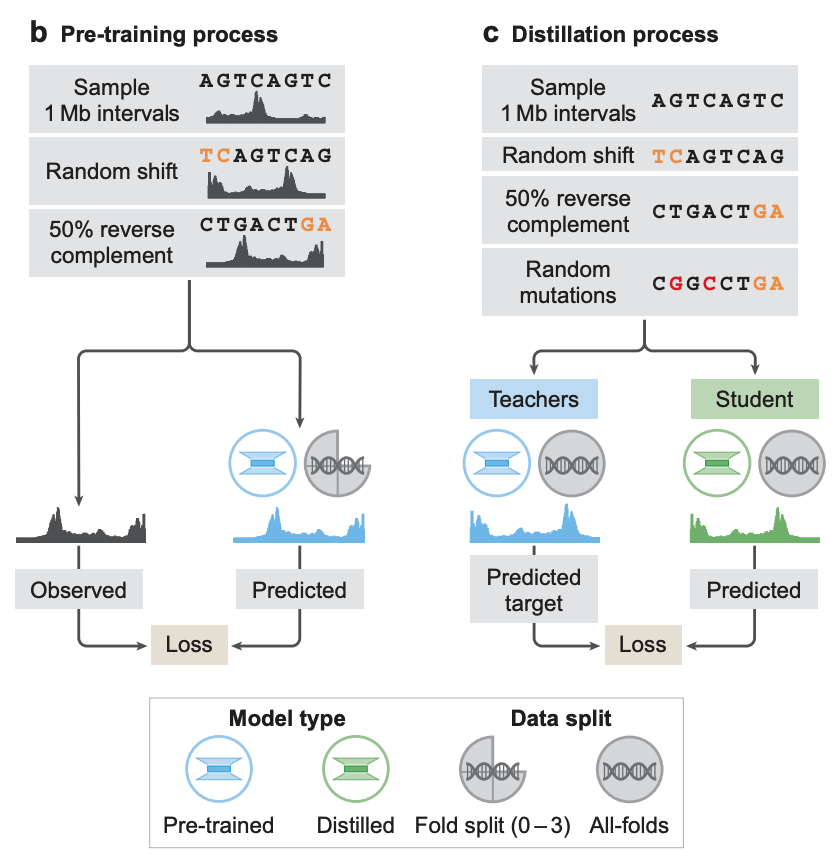
蒸留段階では、研究者は事前トレーニング済みのアーキテクチャを共有する学生モデルをトレーニングしました。目標は、ランダムに拡張された入力シーケンスを使用して、複数の完全に折り畳まれた教師モデルの組み合わせた出力を予測することです。これまでの研究では、この蒸留モデルは、1 つのモデル インスタンスでより強力な堅牢性とより高い変分効果予測 (VEP) 精度を同時に達成できることが示されています。
この設計のおかげで、学生モデルは、単一のデバイス呼び出しで、すべてのモダリティと細胞タイプの変動効果を予測するタスクを完了できます。NVIDIA H100 GPU では、各バリアントの予測には 1 秒もかかりません。これにより、従来のマルチモデル統合方法と比較して、大規模な変動の影響を予測する際に非常に効率的になります。
AlphaGenomeはさまざまなゲノム予測タスクでリードしています
DeepMind によると、AlphaGenome には既存の方法に比べて次のような独自の利点があります。
長い配列コンテキスト + 単一塩基解像度
AlphaGenomeは、最大100万塩基長のDNA配列を解析し、1塩基レベルで予測を行うことができます。これにより、制御遺伝子の遠隔領域をカバーしながら、生物学的な微細な詳細を捉えることができます。従来のモデルは、配列長と予測精度のバランスに重点を置くことが多く、モデル化できるモダリティの範囲と精度が制限されていました。AlphaGenomeの革新的な技術は、この制限を打ち破り、従来のEnformerモデルの半分の計算リソースでトレーニングを行い、わずか4時間でトレーニングセッションを完了します。
包括的なマルチモーダル予測機能
高解像度と長い入力シーケンスの組み合わせにより、AlphaGenome はこれまでにないほど多様な制御パターンを予測し、研究者により体系的な遺伝子制御情報を提供することができます。
効率的な変異スコアリング
AlphaGenomeは、変異の影響を1秒以内にスコア化できます。変異前後の配列の予測差異を比較し、様々なモダリティに最適な要約手法を用いることで、遺伝子変異が分子メカニズムに及ぼす潜在的な影響を迅速かつ正確に評価できます。
新しいスプライスサイトモデリング
AlphaGenomeは、RNAスプライシングジャンクションの位置と発現レベルを、配列情報に基づいて直接予測する革新的な技術です。多くの希少遺伝性疾患(脊髄性筋萎縮症や特定の嚢胞性線維症など)はスプライシングエラーと関連しており、この機能は関連する病因研究のための新たなツールとなります。
ベンチマークで優れたパフォーマンス
AlphaGenomeは、DNA構造の近接性、遺伝子発現への変異の影響、スプライシングパターンの変化など、様々なゲノム予測タスクにおいてリードしています。24のDNA配列予測評価のうち22で既存の最良モデルを上回り、26の変異影響タスクのうち24で既存の最良モデルに匹敵または上回りました。さらに重要なのは、全ての評価モダリティで統合予測を行うことができる唯一のモデルであり、高い汎用性を示していることです。
具体的には、AlphaGenomeのモデルのパフォーマンスを評価するために、研究者らはまず、変異体の影響の高品質な予測を実現するための前提条件である、未知のゲノムセグメントへの一般化能力を調べた。研究者らは、モデルによって予測される11のモダリティすべてを対象に、合計24回のゲノムトラジェクトリ予測評価を実施しました。交差検証アウトオブフォールド評価では、事前学習済みのフォールド特異的なAlphaGenomeモデルを用い、各タスクにおける現在の最も強力な外部モデルと予測値を比較しました。
結果は次のようになります。AlphaGenome は、24 の評価のうち 22 で対応する外部モデルを上回りました。下図dに示す通り。注目すべきは、細胞タイプ特異的な遺伝子発現変化(対数変化、LFC)予測タスクにおいて、AlphaGenomeは別のマルチモーダルシーケンスモデルBorzoiと比較して、+17.4%の相対パフォーマンス向上を示したことです(下図e参照)。
さらに、AlphaGenomeは、様々なタスクにおいて単一のモダリティに特化した特化型モデルを凌駕しました。例えば、
クロマチンコンタクトマップの予測では、AlphaGenome は、以下の図 d に示すように、接触マップのピアソン相関係数の +6.3% の増加と細胞タイプ固有の差異の +42.3% の増加によって示され、Orca モデルを上回りました。
転写開始部位のトラックの予測では、AlphaGenome は ProCapNet を上回り、全体的なカウントのピアソン相関係数の改善は +15% でした。
クロマチンアクセシビリティ予測では、AlphaGenome は ChromBPNet を上回り、ATAC-seq では +8%、DNase-seq では +19% 向上しました。
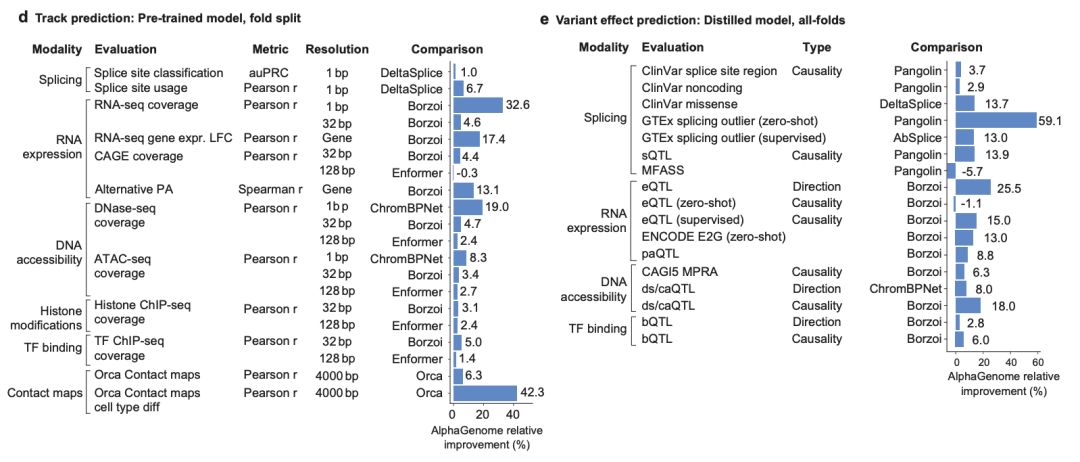
* 図 e: 部分的変異効果を予測するタスクにおける AlphaGenome の相対的なパフォーマンスの向上。
業界のマイルストーンとして高く評価される
AlphaGenomeによるこの大ヒットモデルの発売は、ニュースが発表されて以来、Twitter上で熱い議論を巻き起こし続けています。
ディープマインド研究担当副社長プッシュミート・コーリ氏は次のように述べている。「アルファゲノムは、DNA変異の影響を予測することで、ヒトの非コードゲノムの包括的な見解を提供します。これにより、病気の生物学に対する理解が深まり、新たな研究の道が開かれるでしょう。」コメント欄では、感嘆や賞賛の他に、使い方について気になる声も上がっています。
エディンバラ大学の遺伝学博士課程の学生はこう語った。「このモデルは、疾患の原因となる変異や薬剤のターゲットを発見する方法を完全に再定義する可能性があり、非常に意義深い。」
生物科学分野の評論家は、「アルファゲノムは単なる遺伝子ではなく、制御ゲノム全体です。DNAをコードに例えると、アルファゲノムはコードで構成されたソフトウェアです」と述べています。
実用面では、AlphaGenome は幅広い科学研究の可能性を秘めています。例えば、疾患メカニズム研究、遺伝子変異が制御プロセスに与える影響をより正確に予測し、潜在的な病原性変異を特定し、新たな標的を明らかにすることができます。特に、顕著な影響を及ぼす稀な変異の研究に適しています。存在する合成生物学の分野では、神経細胞内の標的遺伝子のみを活性化するなど、特定の制御機能のための DNA 設計を指示します。存在する基礎ゲノム研究では、主要な機能要素の局在化と役割の定義を加速し、特定の細胞タイプの機能を制御するために必要な「コア指示」を特定するのに役立ちます。
ユニバーシティ・カレッジ・ロンドンのマーク・マンスール教授は、「アルファゲノムは、非コードバリアントの役割を大規模に特定するための重要なパズルのピースを提供し、がんなどの複雑な疾患をより深く理解することを可能にします」とコメントしています。現在、アルファゲノムは非営利目的の研究に開放されており、これを基に学術コミュニティからさらなる成果が生まれることを期待しています。








