Command Palette
Search for a command to run...
パデュー大学のチームは、人間の反応的な把握プロセスをシミュレートして、ロボット学習用のデータの効率的な触覚表現を実現しました。

ロボットの自律学習の旅において、タッチは不可欠な部分であり、これによりマシンは物理世界の詳細を認識できるようになります。ただし、従来の触覚認識システムのトレーニングは大量のデータ収集に依存することが多く、コストがかかり非効率的です。データ駆動型アプローチの限界が明らかになるにつれ、効率的なデータ表現を通じて触覚学習のパフォーマンスを向上させる方法は、現在のロボット研究の焦点の 1 つとなっています。
近年、自己教師あり学習、スパース表現、クロスモーダル知覚に基づく革新的なテクノロジーが急速に登場し、触覚表現の簡素化と最適化のための新しいアイデアを提供しています。

この分野のブレークスルーにより、ロボットが限られたデータで複雑なタスクに迅速に適応できるようになるだけでなく、人間や環境と対話する能力も大幅に向上します。この革命的な変化の中で、データ効率の高い触覚表現テクノロジーがロボットの知覚と学習に新たな扉を開きます。
12月18日、Embodied Touch Communityが主催し、HyperAIが共催する「New Frontiers」の第4回オンライン共有イベントで、パデュー大学博士課程 3 年生の Xu Zhengtong 氏は、LeTac-MPC と UniT の 2 つの主要な科学研究結果と、「ロボット学習のためのデータの効率的な触覚表現」というテーマに関する研究の技術的ルートを共有しました。
HyperAI Super Neural は、Xu Zhengtong 博士のこの詳細な共有を、当初の意図に違反することなく編集し、要約しました。
微分可能な最適化はロボット学習における強力なツールです
最適化はロボット工学の分野において非常に重要かつ効率的なツールであり、軌道計画や人間とコンピューターの相互作用において多くの優れた結果を実証しています。最適化について説明する前に、まず、微分可能な最適化という概念を導入する必要があります。この概念を説明するために、最適化問題の一般定式化から始めます。
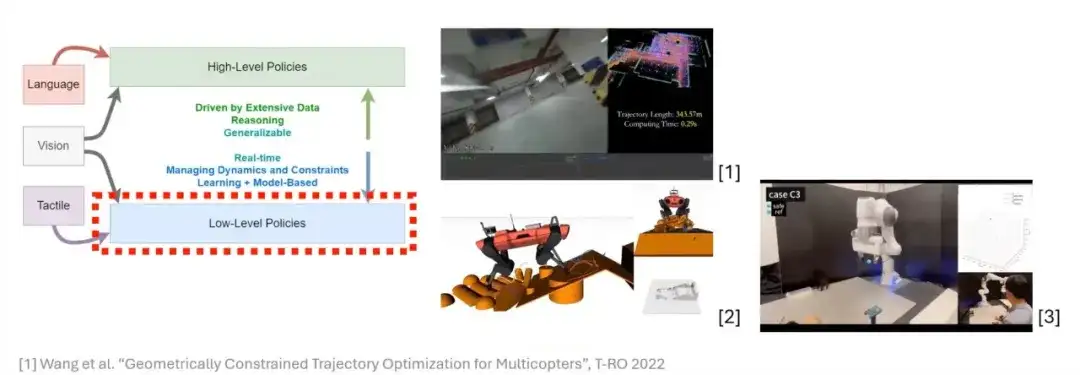
最適化の中心的な考え方は、特定のアプリケーション シナリオのターゲット関数 (コスト関数) を構築することです。これらの目的関数には通常、大量の事前知識が含まれており、一連の制約を受ける場合があります。したがって、最適化問題を構築するときは、多くの場合、目的関数にこれらの制約を追加する必要があります。
次、最適化の基本的な形式である二次計画法 (QP) に焦点を当てます。これは最適化の分野で最も単純な形式の 1 つであり、実際のアプリケーションでは依然として幅広いシナリオがあります。

これに基づいて、「微分可能」という概念を導入します。いわゆる微分可能性とは、ニューラル ネットワークにおいて、層の出力がその内部パラメーターに対して偏微分計算を実行できることを意味します。微分可能な二次計画法 (Differentiable QP) を導入する意義は次のとおりです。最適化層をニューラル ネットワークに追加する場合は、その層が微分可能であることを確認する必要があります。この方法でのみ、最適化層のパラメーターを自然に更新し、ネットワークのトレーニングと推論中に勾配情報を流すことができます。したがって、二次計画問題を微分可能にすることができれば、それをニューラル ネットワークに統合し、ネットワークの一部にすることができます。
さらに、ロボット学習における最適化問題は、目的関数や制約の設計など、特定のシナリオにおける事前知識に依存することがよくあります。微分可能な最適化問題を構築することで、この事前知識を最大限に活用し、モデル設計に効果的に統合できます。ただし、場合によっては、問題をモデル化できない (つまり、モデルベースの表現を構築できない) 場合があります。この点について、データ駆動型のメソッドを使用して、モデルにこれらの部分のルールを独自に学習させることができます。これはまさに微分可能最適化問題の中核となる考え方です。
要約すると、二次計画問題には微分可能な特性があるため、ニューラル ネットワークの一部として導入できます。この方法は、ネットワーク設計のための新しいツールを提供するだけでなく、ロボット学習におけるモデル設計により多くの柔軟性と可能性をもたらします。
LeTac-MPC:触覚信号に基づく反応性把握とモデル制御手法の研究
私たちは反応性把握という概念を思いつきました。人間が物を掴む過程を観察したところ、人間は通常、指を通して物の性質や状態を認識し、フィードバックに基づいて指の動きを調整していることが分かりました。例えば:
※卵を掴むとき、私たちは卵が硬いけれども壊れやすいと認識し、損傷しないように適切な力を加えます。指のフィードバック圧力が増加すると、握力が弱まります。
※パンを掴む際、パンが柔らかいため、指の動きを調整することで潰れや変形を防ぎます。
※牛乳瓶を掴むときに瓶を振ると、牛乳の揺れによって物体の慣性が変化します。指はこれらの変化を感知し、慣性によるボトルの滑りを防ぐために握る動作を動的に調整します。

リアクティブグラブロボットの実装を模倣する
人間の把握プロセスを利用して、モデルベースのアプローチを通じてこのプロセスをシミュレートする方法を探ります。GelSight のような視覚ベースの触覚センサーを使用すると、元の画像から主要な特徴を抽出し、簡単な処理によって深度画像または差分画像を生成し、しきい値処理を通じて接触面積を計算できます。接触面積は、加えられる力のサイズを反映することができ、力が大きいほど接触面積は大きくなり、力が小さいほど接触面積は小さくなります。
さらに、オプティカル フロー テクノロジーを使用してマーカーの動きを追跡することにより、別の重要な量である変位を取得できます。この量は横力に関係します。これらの信号を組み合わせることで、比例微分 (PD) コントローラーに基づいた制御方法を構築し、触覚反応性の把握を実現できます。
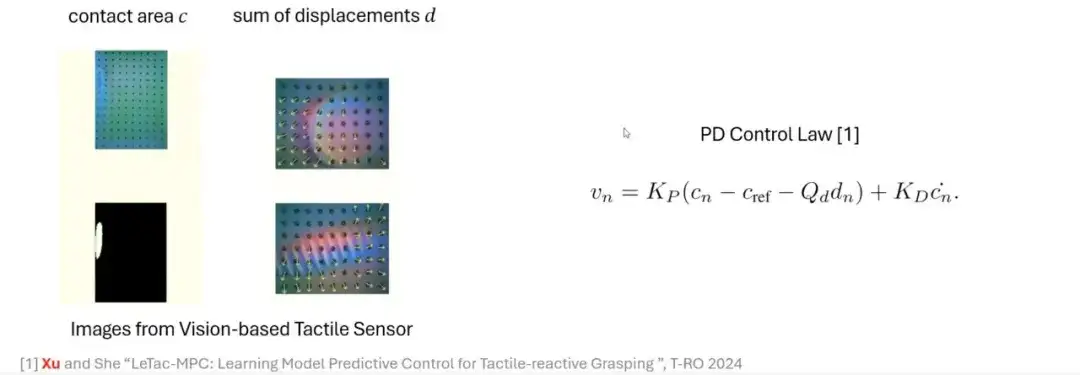
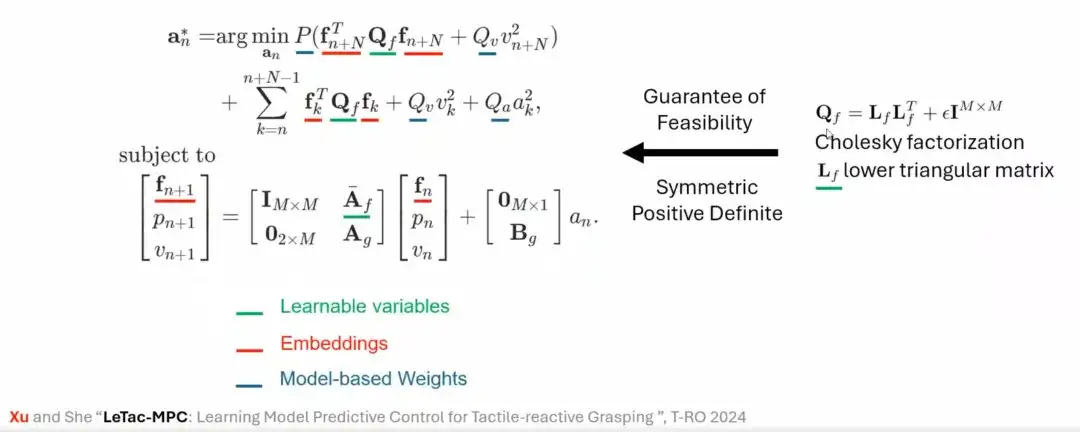
PDコントローラーからMPCコントローラーへ
PDコントローラに加えて、モデル予測コントローラ(MPC)に基づいた把握手法も設計します。 MPC の制御目標は PD コントローラの制御目標と似ていますが、その特性は線形仮定とグリッパー モデルに基づいています。たとえば、最初に線形仮定 (Linear Assumption) と 1 自由度グリッパー運動モデル (Single Degree of Gripper Motion Model) を導入し、次に 2 つを統合してモデル化し、最後に MPC に基づく制御則を構築します。
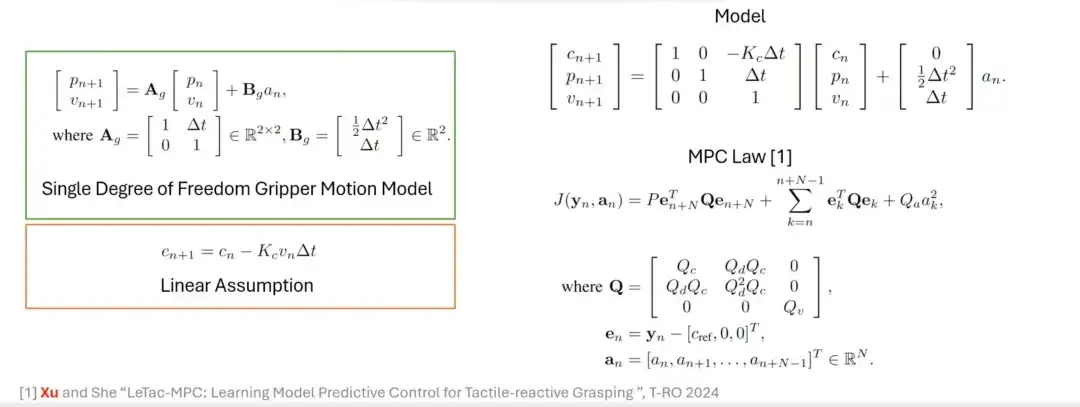
MPC コントローラーのアプリケーションと制限事項
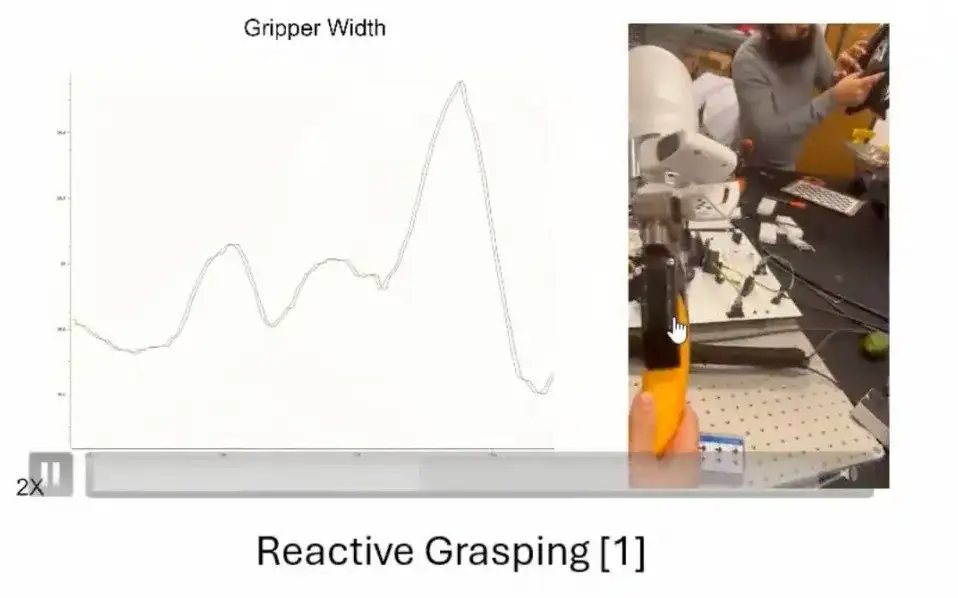
MPC コントローラー モデルは、複数のシナリオで適切にパフォーマンスを発揮します。ここでは 2 つのアプリケーションをリストします。最初のアプリケーションは、バナナをドラッグするとき、グリッパーはバナナの動的フィードバックに応じて強度を調整し、安定した把握を保証します。外力が取り除かれると(人間の手がバナナを放すなど)、コントローラは徐々に安定状態に収束します。
用紙のアドレス:
https://ieeexplore.ieee.org/document/10684081
2 番目のアプリケーションは、IROS に関する私たちのグループの別のメンバーによって提案された結果です。すなわち、複雑な動作タスクを実現するために多自由度グリッパが使用され、私たちが提案したMPCコントローラが使用されます。
用紙のアドレス:
https://arxiv.org/abs/2408.00610

ただし、モデルベースのコントローラーには一定の制限があり、現実の日常的なオブジェクトのほとんどに一般化するのは困難です。これは主に、モデリング プロセスでの仮定が単純化されていることが原因であり、一部の実際のオブジェクトでは機能しないことがよくあります。下図に示すように、柔らかい物体や複雑な形状の物体の場合は、単純な閾値設定では正確に接触領域を抽出することが困難ですが、アボカドやビスケットなどの比較的硬い物体は触感イメージが強いため、正確に接触領域を抽出することができます。接触部分を抽出します。
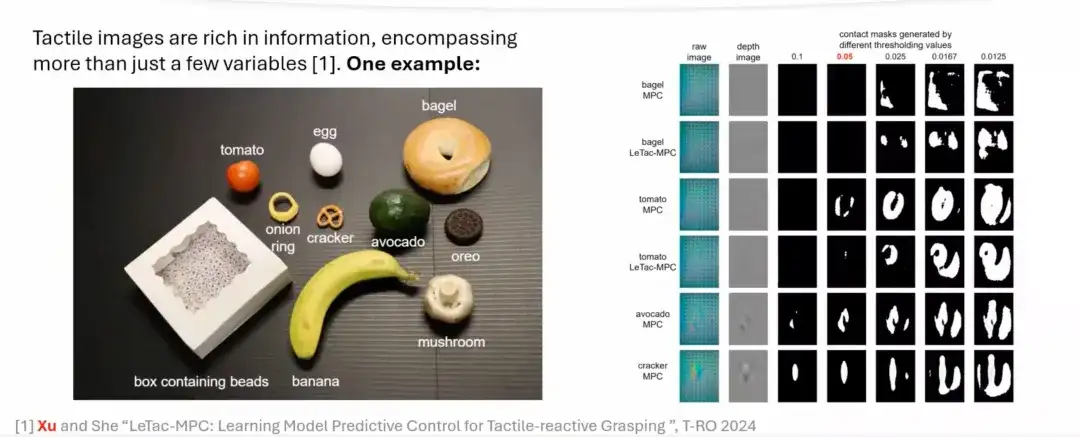
LeTac-MPC コントローラーの 3 つの主な利点
この問題を解決するために、私たちは数学的手法(コレスキー分解など)によって最適化問題の可解性を確保し、それによってコントローラーの学習プロセスを安定化させ、最終的にLeTac-MPCを提案しました。
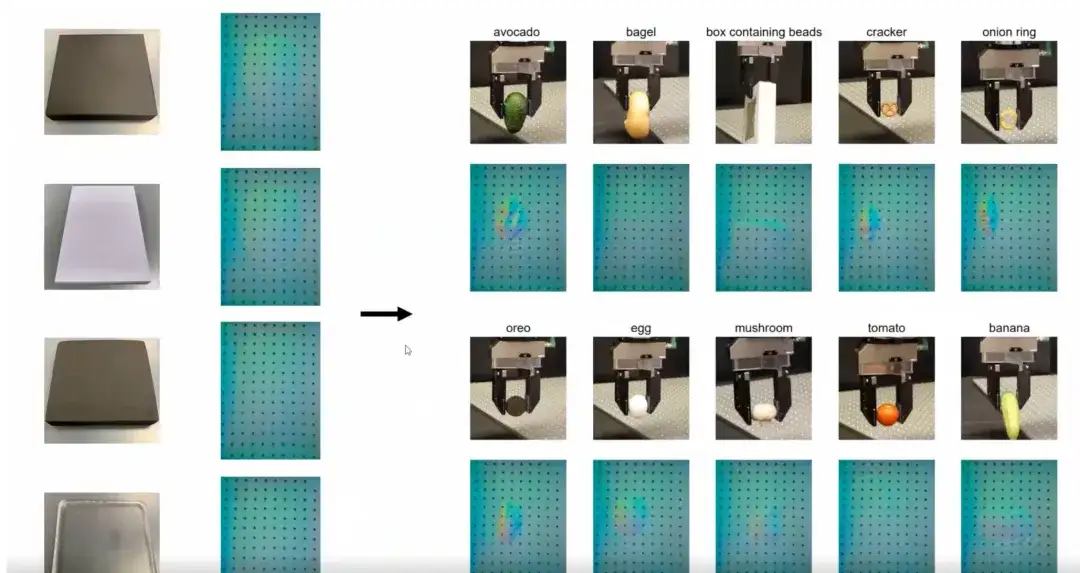
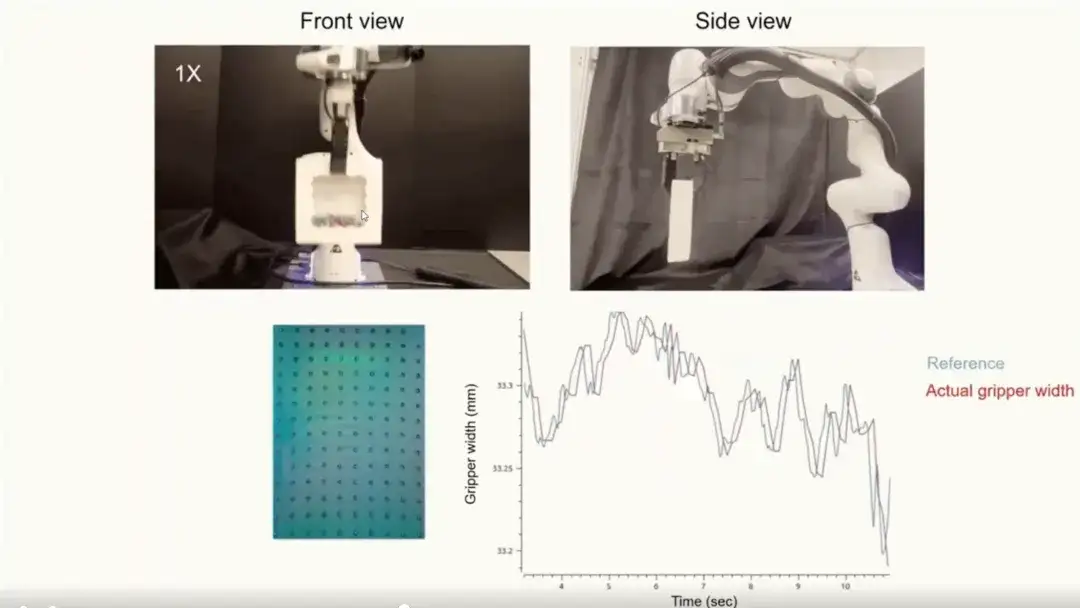
以下の図は、4 つの異なる硬度のオブジェクトのみを含むデータセットでトレーニングした最も直感的な結果を示しています。これらのオブジェクトは異なる剛性を持っています。トレーニング データが限られているにもかかわらず、私たちがトレーニングしたコントローラーは、さまざまなサイズ、形状、素材、テクスチャを持つ日常のオブジェクトに一般化されます。小さなサンプルのトレーニングに基づくこの一般化機能は、コントローラーの大きな利点です。
第二に、私たちが訓練したコントローラーは、掴んだ物体からの干渉に耐性があります。外部干渉により掴んだ物体が落下しないように、掴み方や強さをリアルタイムに調整できます。
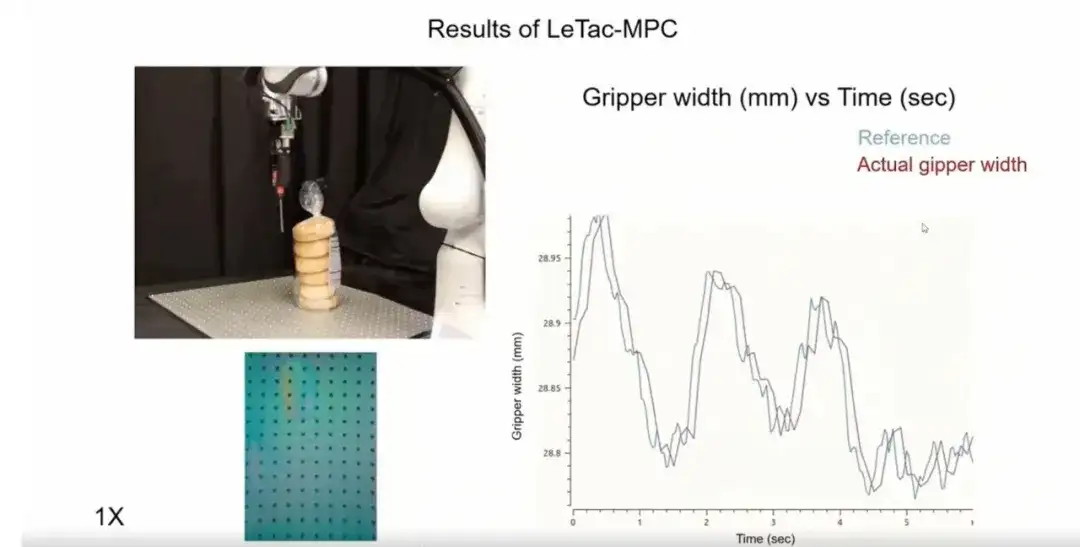
第三に、私たちがトレーニングしたコントローラーは非常に応答性が良いです。以下の図に示すように、激しい動きや慣性の変化 (瓦礫が入った箱など) が発生するシナリオでは、コントローラーはオブジェクトの動的な変化に迅速に対応できます。
UniT: ロボット学習のための統一された触覚表現
上記の研究により、コントローラの汎化能力を実現しました。それでは、単一の単純な物体を使用して統一された触覚表現を学習できるでしょうか?
以下の図に示すように、単一の単純なオブジェクトは、ボールやレンチ (六角レンチなど) などの幾何学的に単純なオブジェクトにすることができます。これらの物体の触覚画像は比較的単純であるため、私たちの方法も比較的単純です。

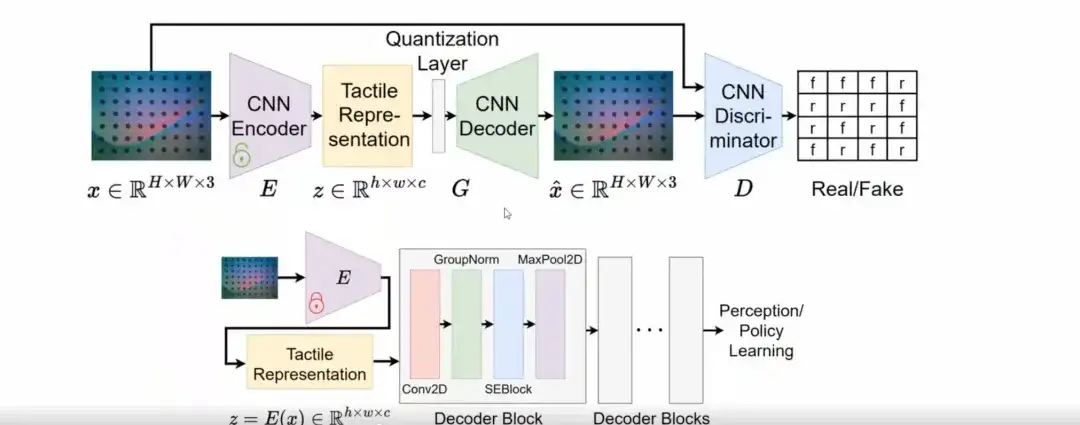
具体的には、新しいネットワーク構造を設計したわけではありませんが、VQGAN が一般化機能を備えた触覚表現を効果的に学習できることがわかりました。
トレーニングフェーズでは、VQGAN モデルを採用して触覚表現を学習します。推論段階では、VQGAN の潜在空間が単純な畳み込み層を通じてデコードされ、下流のタスク (知覚やポリシー学習など) に接続されます。
用紙のアドレス:
https://arxiv.org/abs/2408.06481
復元実験
表現の有効性を検証するために、アーレンキーとスモールボールの復元実験を行いました。
一つ目はアレンキー実験です。以下の図に示すように、トレーニング データはアレン キーからのみ取得されますが、潜在空間を通じて目に見えないオブジェクトの元の画像を再構成できます。これは、潜在空間には元の画像の有用な情報のほとんどが含まれていることを示しています。 MAE と比較すると、MAE は元の画像を正確に再構成することが困難であることがわかり、これは MAE が復号化プロセス中に情報損失を受ける可能性があることを示しています。

2つ目はスモールボール実験です。下の図に示すように、トレーニング データは Small Ball からのみ取得されており、再構成効果はアレン キーほど良くありませんが、このモデルは複雑なオブジェクトの元の信号をある程度まで再構成できます。

さらに、潜在空間は、触覚の幾何学的情報 (形状や接触構成など) を捕捉するだけでなく、マーカー ポイントの移動情報も暗黙的に含みます。たとえば、元の画像と再構成された画像のマーカー ポイント トラッキングを通じて、マーカー トラッキングにおける 2 つのパフォーマンスが非常に近いことがわかりました。

下流のタスクとベンチマーク
UniT 法の表現能力について、6D 姿勢推定、3D 姿勢推定、分類ベンチマークなどの複数のベンチマーク テストを実施しました。
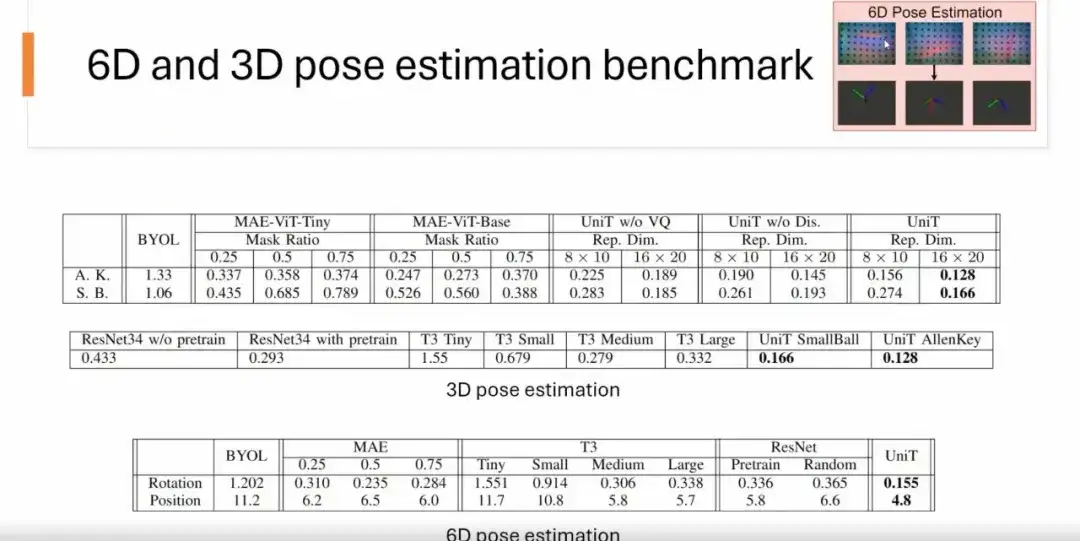
6D 姿勢推定の場合、生の触覚画像 (USB プラグの触覚画像など) を入力して、その位置と回転を予測します。結果は、MAE、BYOL、ResNet、および T3 メソッドと比較して、UniT モデルが他のメソッドよりも精度が優れていることを示しています。
3D 姿勢推定の場合、物体の回転姿勢を予測するだけです。以下の図に示すように、他の方法と比較して、UniT はパフォーマンスが優れています。
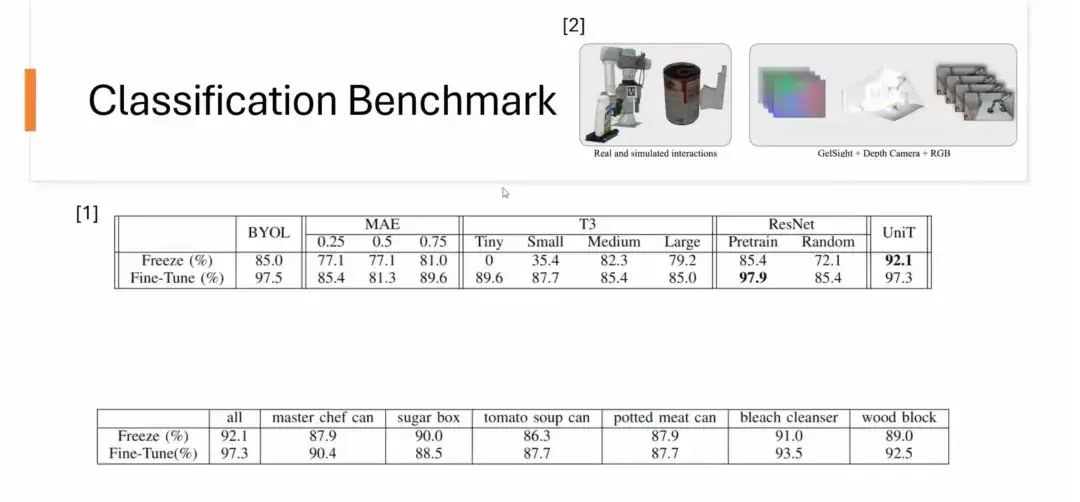
次に、分類ベンチマークも実行しました。データセットは CMU の YCBSight-Sim から取得されます。データセットは小さいですが、UniT は分類タスクで優れたパフォーマンスを示します。特に、単一の物体に対する触覚表現を学習した後は、他の目に見えない物体の分類タスクに自然に一般化できます。たとえば、マスター シェフのみでトレーニングされた表現は、6 つの異なるオブジェクトの分類にうまく適用でき、優れた結果が得られます。単一のオブジェクトでトレーニングされた表現の中には、多数のオブジェクトでトレーニングされた表現のパフォーマンスを超えるものもあります。
戦略学習実験
さらに触覚表現を政策学習実験に応用し、複雑なタスクでのパフォーマンスを検証します。実験ではトレーニングにアレン キー データを使用し、次の 3 つのタスクを評価しました。
* 六角レンチの挿入 (写真左): 非常に高い精度が要求される正確な挿入作業。
※切りくず把握(写真参照):壊れやすい物の繊細な掴み作業に対応します。
*チキンレッグハンギング(右の写真):長時間にわたるダイナミックな掴みとコントロールを伴う両腕のタスク。

3 つの異なる方法をベンチマークします。これら 3 つの方法は、Vision-Only (視覚信号のみに依存)、Visual-Tactile from Scratch (視覚と触覚の共同トレーニング)、および Visual-Tactile with UniT (UniT によって抽出された触覚表現を戦略学習に使用) です。次の図に示すように、UniT 表現を使用したポリシー学習方法は、すべてのタスクで最高のパフォーマンスを発揮します。

将来的には、HyperAI は身体化された触覚コミュニティが引き続きオンライン共有活動を開催できるよう支援し、国内外の専門家や学者を招待して最先端の結果や洞察を共有する予定ですので、ご期待ください。








