Command Palette
Search for a command to run...
ワンクリックで GLM-4-9B-Chat を体験してください

最近、Zhipu AI ベースとなる大型モデル GLM-4 - GLM-4-9B の最新のオープンソース成果がリリースされました。これには初めてマルチモーダル機能が搭載されています。公式データによると、トレーニング量が多い Llama-3-8B モデルと比較して、GLM-4-9B は中国語の科目で 50% も向上し、マルチモダリティでは GPT-4V に匹敵することができます。
コンテキスト長に関しては、GLM-4-9B は 128K から 1M へのアップグレードを実現しました。これは、125 件の論文を一度に消化できるのと同等です。さらに、モデル語彙が60,000から150,000にアップグレードされ、中国語と英語以外の言語のコーディング効率が平均30%向上し、小さな言語のタスクをより速く処理できるようになりました。
「Llama3-8Bを超える」と謳うこのオープンソースモデルを皆様に初めて体験していただくために、オープンベイズ プラットフォームのパブリック モデル セクションでは、ワンクリック入力をサポートし、長いダウンロードとアップロードにかかる時間をスキップし、快適な展開を直接開始できる「GLM-4-9B-Chat」モデルを開始しました。
公開モデルのアドレス:
https://go.openbayes.com/F7pbS
それだけでなく、「GLM-4-9B-Chat デモのワンクリック展開」も OpenBayes プラットフォームの公開チュートリアル セクションに同期されており、すぐに GLM-4-9B-Chat の優れたパフォーマンスを体験し始めることができます。コマンドを入力してクローンをクリックする必要はありません。
公開チュートリアルのアドレス:
https://go.openbayes.com/ulmZe
操作手順
PART 1 デモ走行ステージ
1. ログイン http://OpenBayes.com, [公開チュートリアル] ページで、[GLM-4-9B-Chat Demo のワンクリック展開] を選択します。
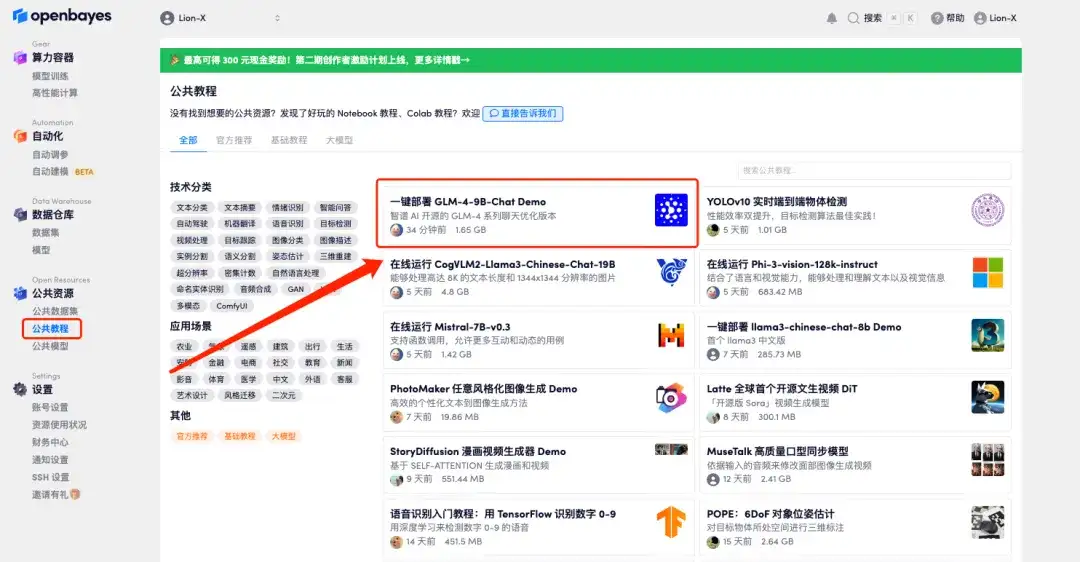
2. ページがジャンプしたら、右上隅の「クローン」をクリックしてチュートリアルを独自のコンテナにクローンします。
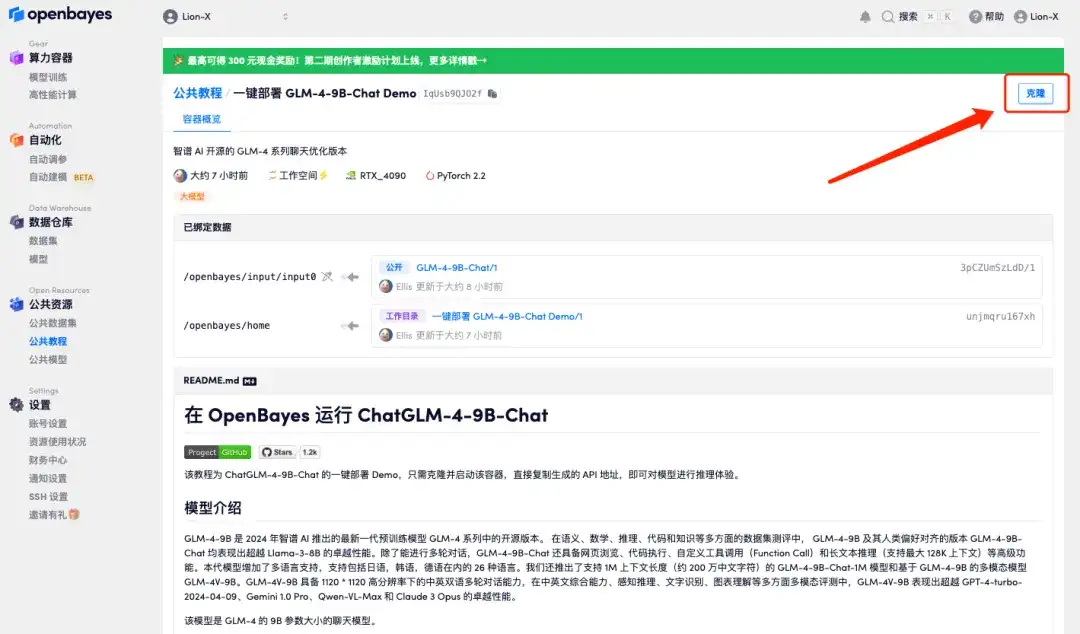
3. 右下隅の「次へ: コンピューティング能力の選択」をクリックします。

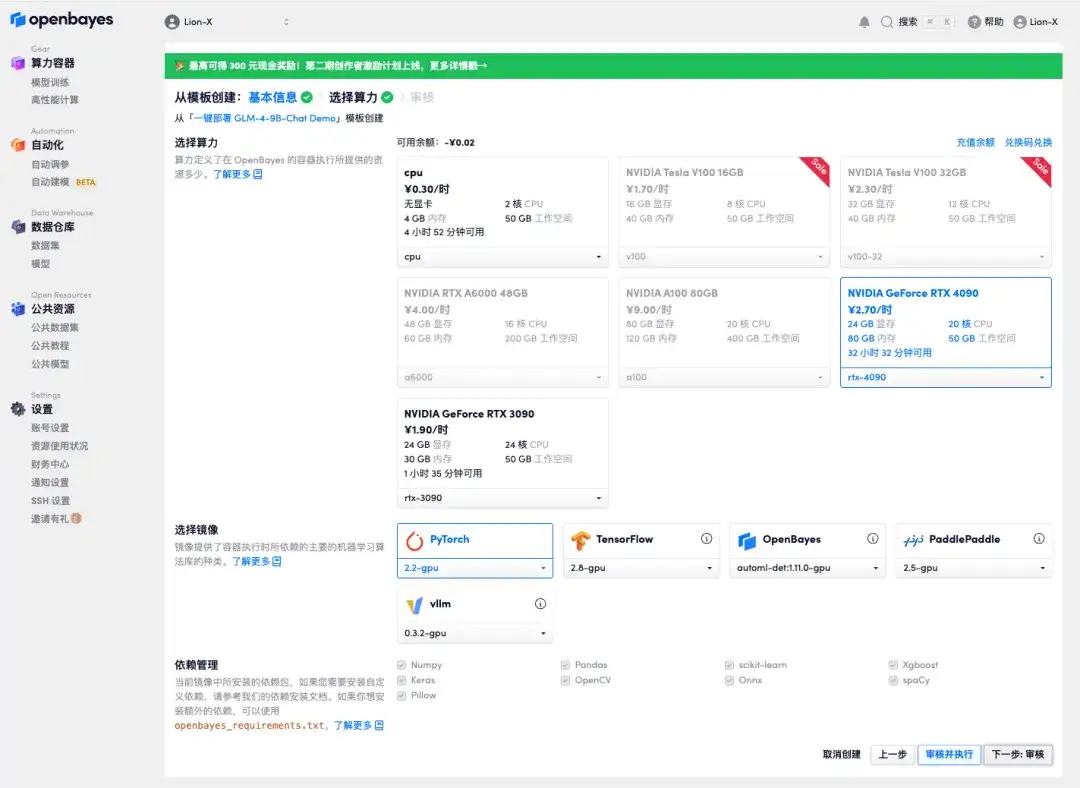
4. ジャンプ後、「NVIDIA GeForce RTX 4090」を選択し、「次へ: 確認」をクリックします。以下の招待リンクを使用して登録した新規ユーザーには 4 時間が与えられます RTX4090 + 5 時間の無料 CPU!
Xiaobei さんの専用招待リンク (ブラウザに直接コピーして開きます):https://go.openbayes.com/9S6Dr
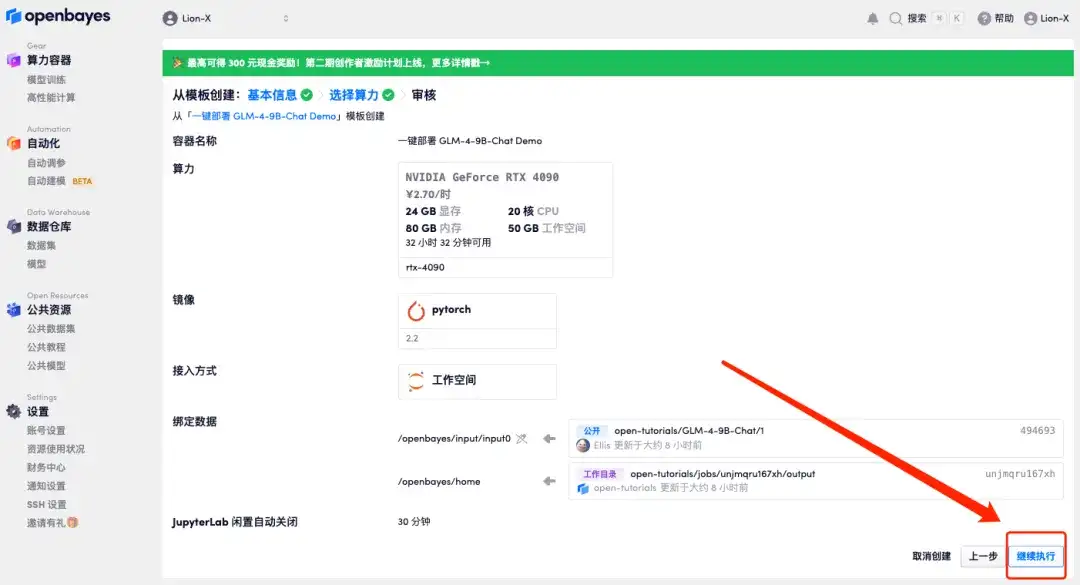
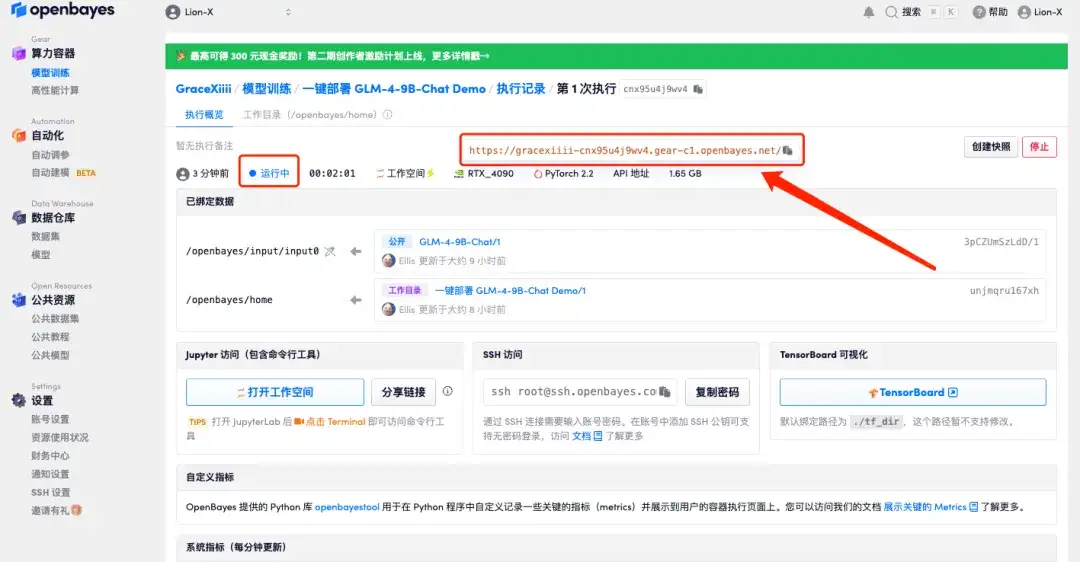
5. [続行] をクリックし、リソースが割り当てられるまで待ちます。最初のクローンには約 3 分かかります。ステータスが「実行中」に変わったら、「API アドレス」にマウスを移動し、アドレスをコピーして新しいタブで開くと、GLM-4-9B-Chat Demo ページにジャンプします。APIアドレスアクセス機能を利用するには実名認証が必要となりますのでご注意ください。
10 分以上「リソースを割り当てています」状態が続く場合は、コンテナを停止して再起動してみてください。再起動しても問題が解決しない場合は、公式 Web サイトのプラットフォーム カスタマー サービスにお問い合わせください。
PART 2 デモ走行ステージ
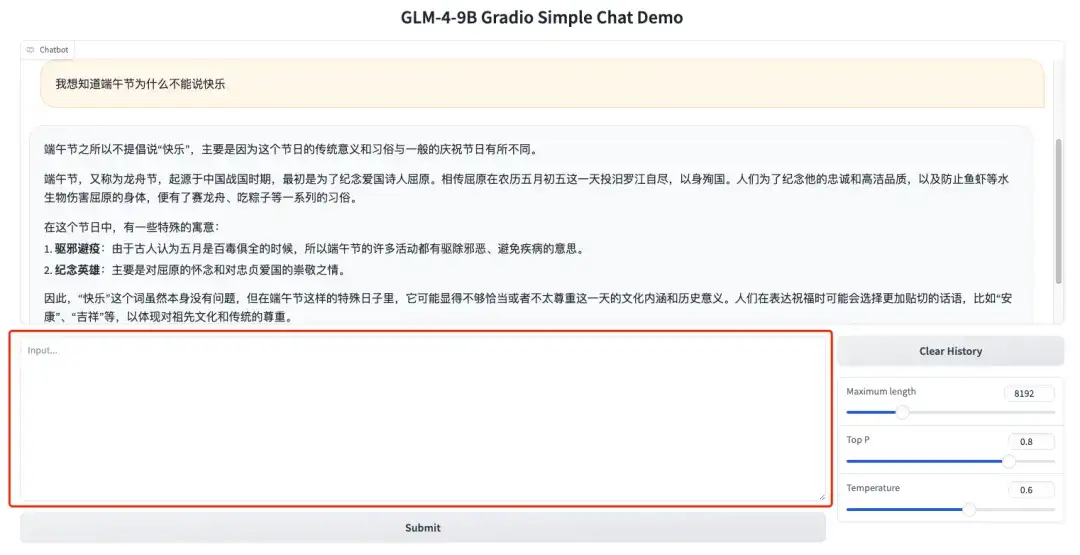
1. GLM-4-9B-Chat Demo ページを開き、ダイアログ ボックスにテキストを入力し、[送信] をクリックして会話を開始します。

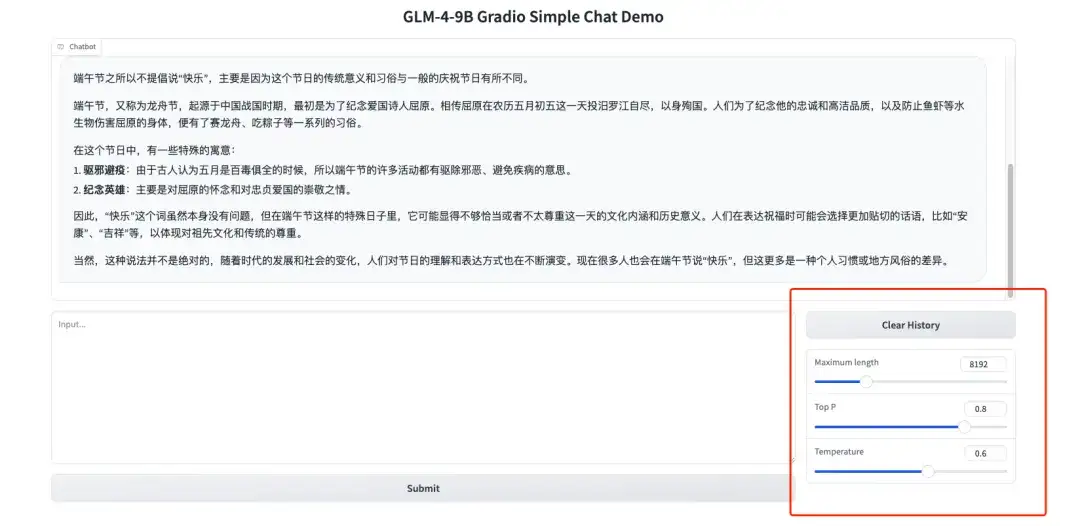
2. 右側のハイパーパラメータ パネルはそれぞれ以下を表します。
* 最大長: モデルが出力するテキストの最大数。
* 上位 P: モデル出力の確率分布から選択される候補単語の範囲を制御します。値が増加すると、テキスト生成プロセスで考慮される単語のセットが大きくなります。
* 温度: ランダム性を制御するハイパーパラメータ。値が大きいほど、生成されるテキストのランダム性が高くなります。
新規ユーザーの特典
登録特典:下の招待リンクをクリックして登録すると、4 時間の RTX 4090 + 5 時間の無料 CPU コンピューティング時間を取得できます。これは永久に有効です。
Xiaobei さんの専用招待リンク (ブラウザに直接コピーして開きます):








