Command Palette
Search for a command to run...
WildSpeech-Bench音声理解生成ベンチマークデータセット
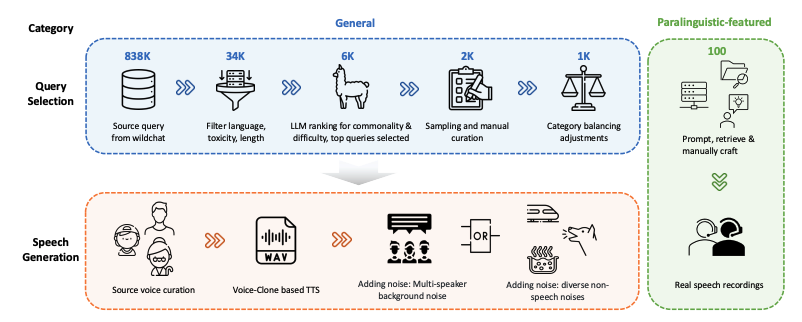
WildSpeech-Benchは、2025年にテンセントがリリースしたSpeechLLMの音声合成機能を評価する最初のベンチマークです。関連する論文の結果は次のとおりです。WildSpeech-Bench: エンドツーエンドの音声LLMのベンチマーク「」は、実際の音声インタラクションのシナリオで、音声入力から音声出力(Speech-to-Speech、S2S)までの完全な音声理解と生成を行うモデルの能力を測定することを目的としています。 このデータセットには、情報クエリ、ソリューション要求、意見交換、テキスト作成、パラ言語的表現という5つの主要カテゴリにわたる1,100件のクエリが含まれています。各カテゴリは、一般的なユーザーインテントに対応しています。これらのクエリのうち1,000件は、一般的な音声インタラクションシナリオ(情報クエリ、ソリューション要求、意見交換、テキスト作成を含む)からのものであり、残りの100件は、休止、イントネーション、吃音、近似音声単語認識などのパラ言語的特徴を特徴としています。各クエリには、多様な話者属性(性別、年齢、声質)、音響条件、ノイズ環境設定を網羅した多様な音声出力例が付属しており、自然な音声インタラクションの多様性と課題をよりリアルにシミュレートしています。
引用
@misc{zhang2025wildspeechbenchbenchmarkingendtoendspeechllms, title={WildSpeech-Bench: 実環境におけるエンドツーエンドのSpeechLLMのベンチマーク}, 著者={Linhao Zhang、Jian Zhang、Bokai Lei、Chuhan Wu、Aiwei Liu、Wei Jia、Xiao Zhou}、 年={2025}、 eprint={2506.21875}、 archivePrefix={arXiv}、 primaryClass={cs.CL}、 }