HyperAI
Command Palette
Search for a command to run...
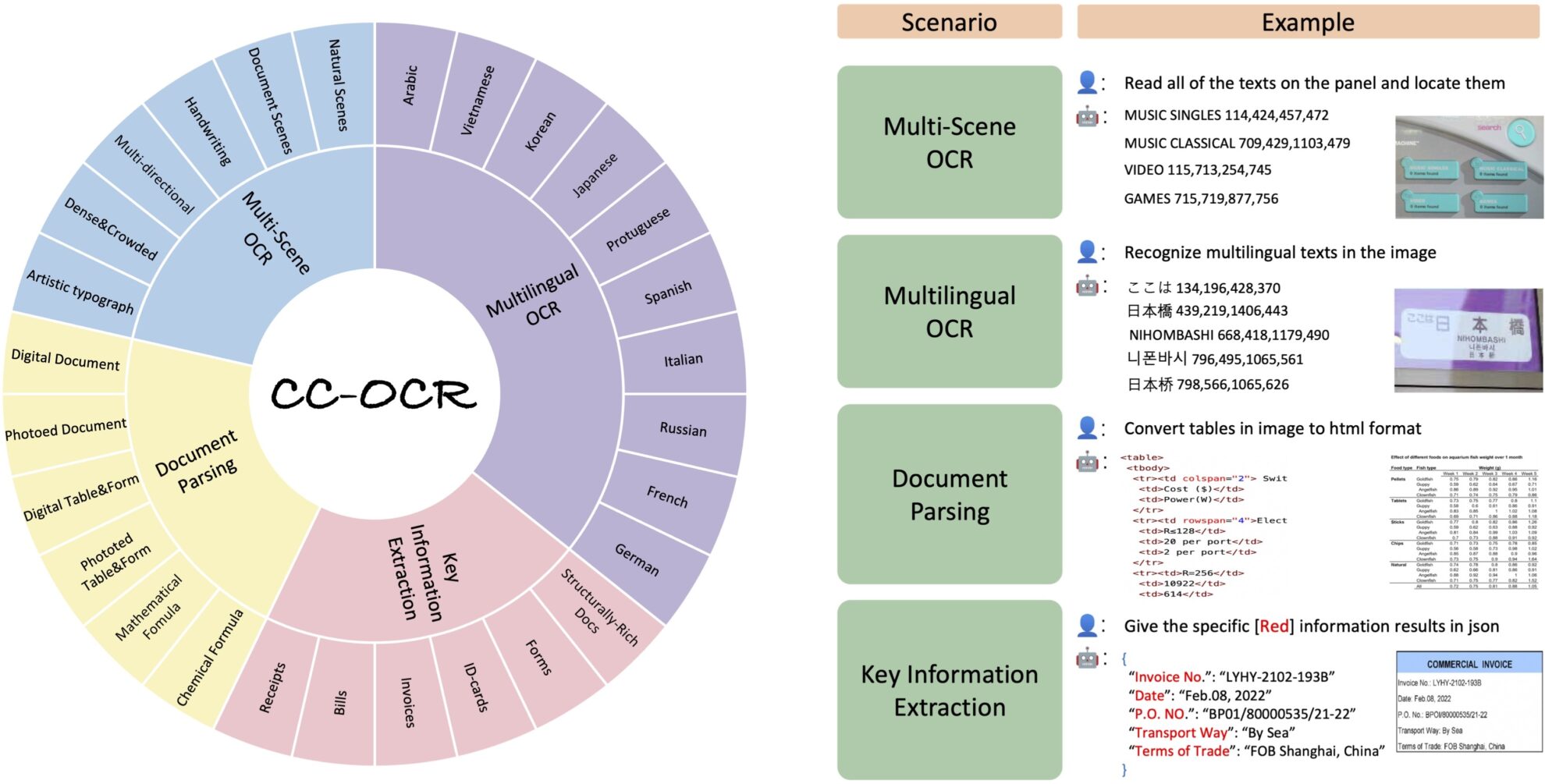
CC-OCR テキスト認識データセット
CC-OCR データセットは、テキスト認識 (OCR) タスクにおける大規模なマルチモーダル モデルのパフォーマンスを評価するための包括的かつ挑戦的なベンチマークを提供することを目的として、2024 年にアリババ グループ、華中科技大学、華南理工大学によって共同で開発されました。CC-OCR: 読み書き能力における大規模なマルチモーダルモデルを評価するための包括的かつ挑戦的な OCR ベンチマーク”。
このデータセットは、マルチシーンテキスト読み取り、多言語テキスト読み取り、ドキュメント解析、キー情報抽出という 4 つのコアタスクをカバーしており、39 のサブセットと 7,058 枚の完全に注釈が付けられた画像が含まれています。 CC-OCR の導入は、複雑な構造やきめ細かい視覚的課題における現在のマルチモーダル モデルの評価のギャップを埋め、実際のアプリケーションにおけるマルチモーダル モデルの進歩を促進する上で大きな意義を持ちます。
CC-OCR.torrent
シーディング 2ダウンロード中 0完了 232総ダウンロード数 420
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。