HyperAI
Command Palette
Search for a command to run...
ProtT3 タンパク質テキストの質問と回答のデータ セット
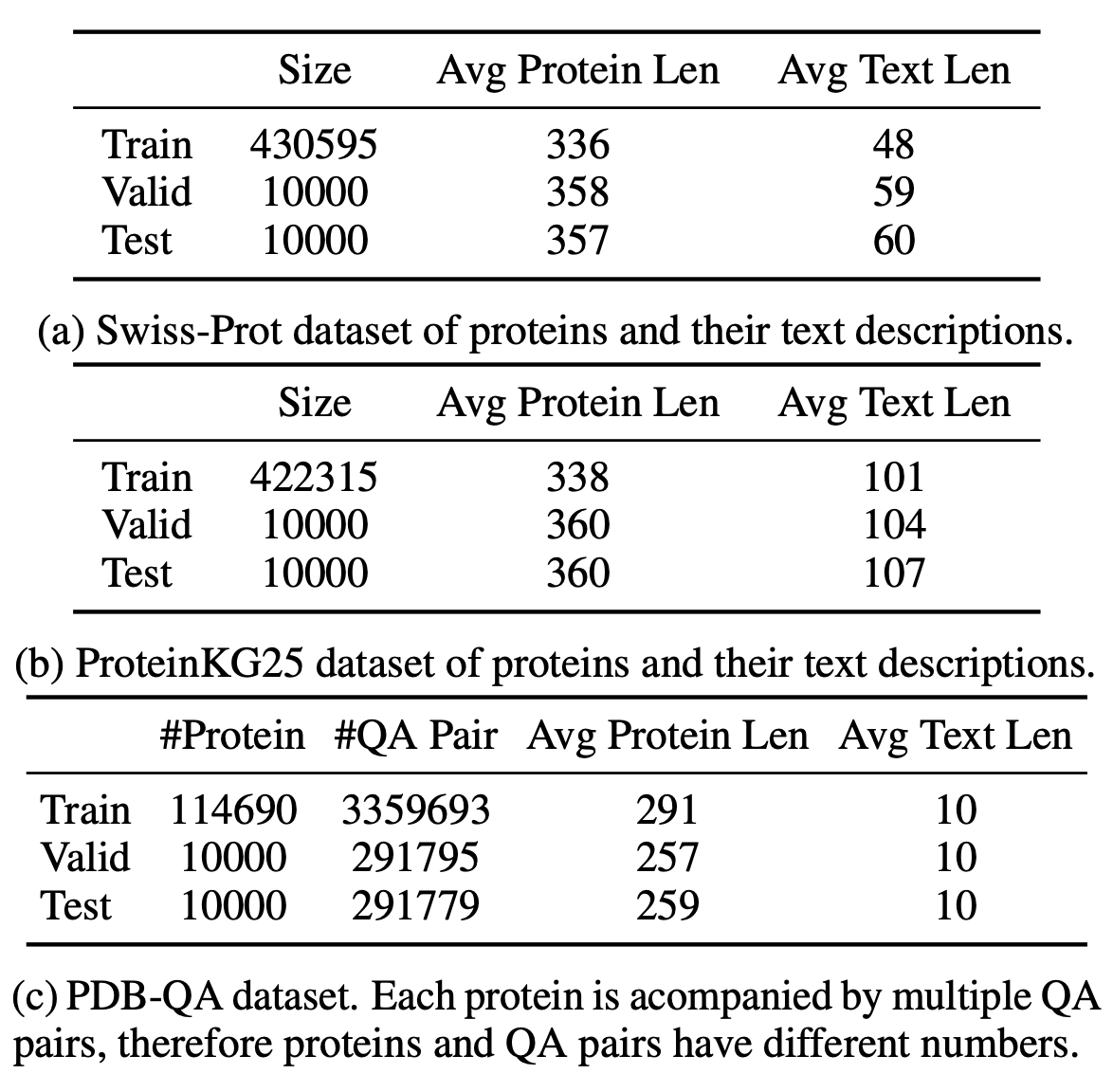
ProtT3 データセットは、2024 年にシンガポール国立大学、中国科学技術大学、北海道大学の研究チームによって共同で構築されました。関連する論文結果は「ProtT3: テキストベースのタンパク質理解のためのタンパク質からテキストへの生成』に出場し、ACL2024に選出されている。このデータセットは、論文調査のための事前トレーニングデータセットです。 ProtT3 データセットは、Swiss-Prot、ProteinKG25、PDB-QA の 3 つのデータセットで構成されています。

引用
「`bib @inproceedings{liu2024prott, タイトル={ProtT3: テキストベースのタンパク質理解のためのタンパク質からテキストへの生成}、 author={リウ、ジーユアンとチャン、アンとフェイ、ハオとチャン、エンジとワン、シャンとカワグチ、ケンジとチュア、タッセン} 書籍タイトル={{ACL}}、 発行元 = {計算言語学会}、 年={2024}、 url={https://openreview.net/forum?id=ZmIjOPil2b} }
ProtT3.torrent
シーディング 1ダウンロード中 0完了 246総ダウンロード数 386
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。