Command Palette
Search for a command to run...
PixelReasoner-RL : Modèle d'inférence Visuelle Au Niveau Du Pixel
Date
URL du document
Licence
MIT
1. Introduction au tutoriel
PixelReasoner-RL-v1 est un modèle de langage visuel révolutionnaire publié par TIGER AI Lab en mai 2025. L'article de recherche associé est le suivant : Pixel Reasoner : Inciter au raisonnement dans l’espace des pixels grâce à l’apprentissage par renforcement basé sur la curiosité .
Ce projet, basé sur l'architecture Qwen2.5-VL, s'affranchit des limitations des modèles de langage visuel traditionnels qui reposent uniquement sur le raisonnement textuel grâce à une méthode d'apprentissage par renforcement innovante, guidée par la curiosité. PixelReasoner peut raisonner directement dans l'espace pixel, prenant en charge des opérations visuelles telles que la mise à l'échelle et la sélection d'images, ce qui améliore considérablement sa capacité à comprendre les détails des images, les relations spatiales et le contenu vidéo.
Fonctionnalités principales :
- Inférence au niveau du pixel : le modèle peut être analysé et manipulé directement dans l’espace des pixels de l’image.
- Allier compréhension globale et locale : permettre à la fois une appréhension du contenu global de l'image et la possibilité de zoomer et de se concentrer sur des zones spécifiques.
- Formation axée sur la curiosité : introduction d’un mécanisme de récompense de la curiosité pour inciter le modèle à explorer activement les opérations au niveau des pixels.
- Capacité de raisonnement améliorée : Excellentes performances dans les tâches visuelles complexes, notamment la reconnaissance de petits objets et la compréhension des relations spatiales subtiles.
Ce tutoriel utilise Grado pour déployer PixelReasoner-RL-v1 à titre de démonstration, avec les ressources de puissance de calcul d'une seule carte RTX 5090.
2. Affichage des effets
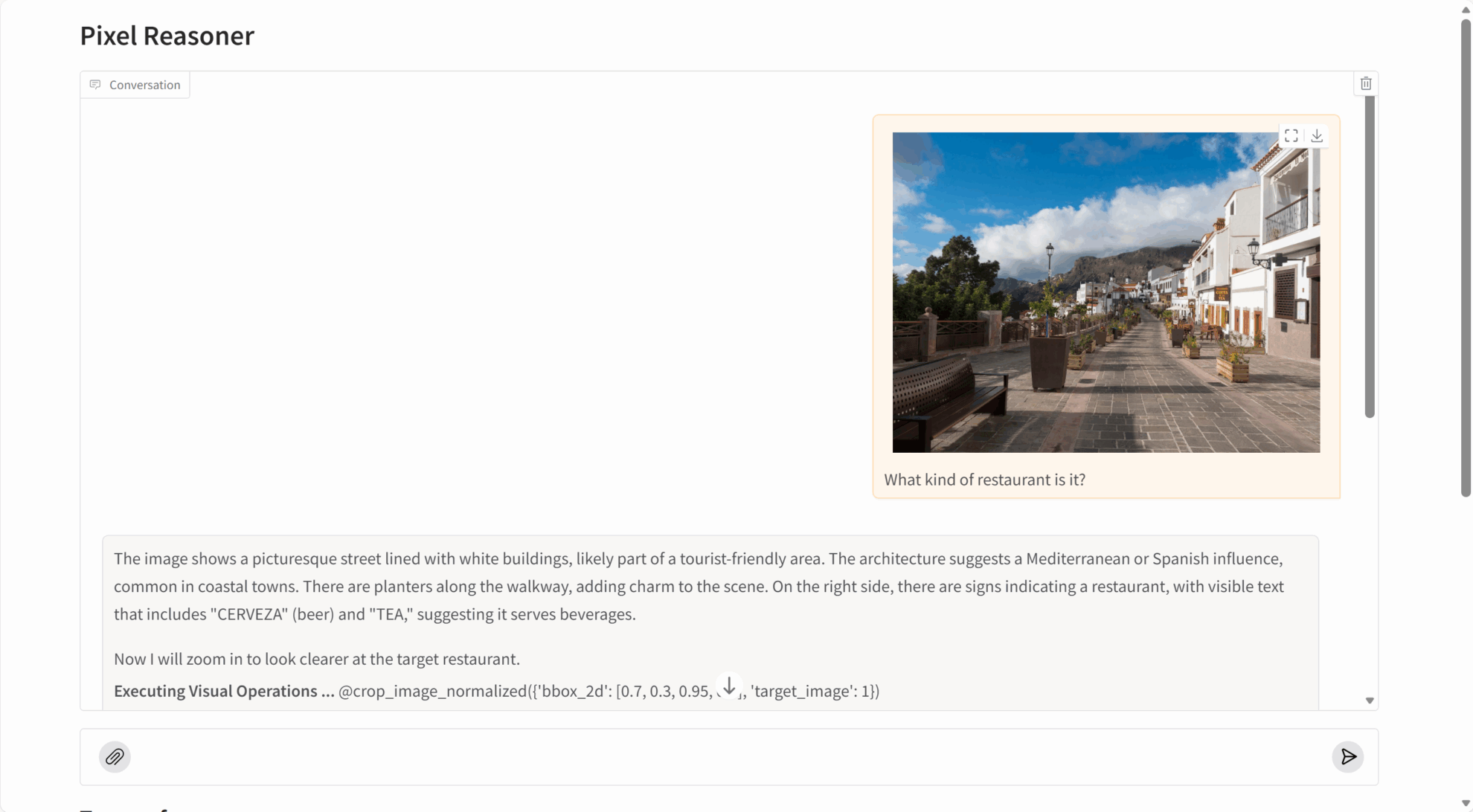
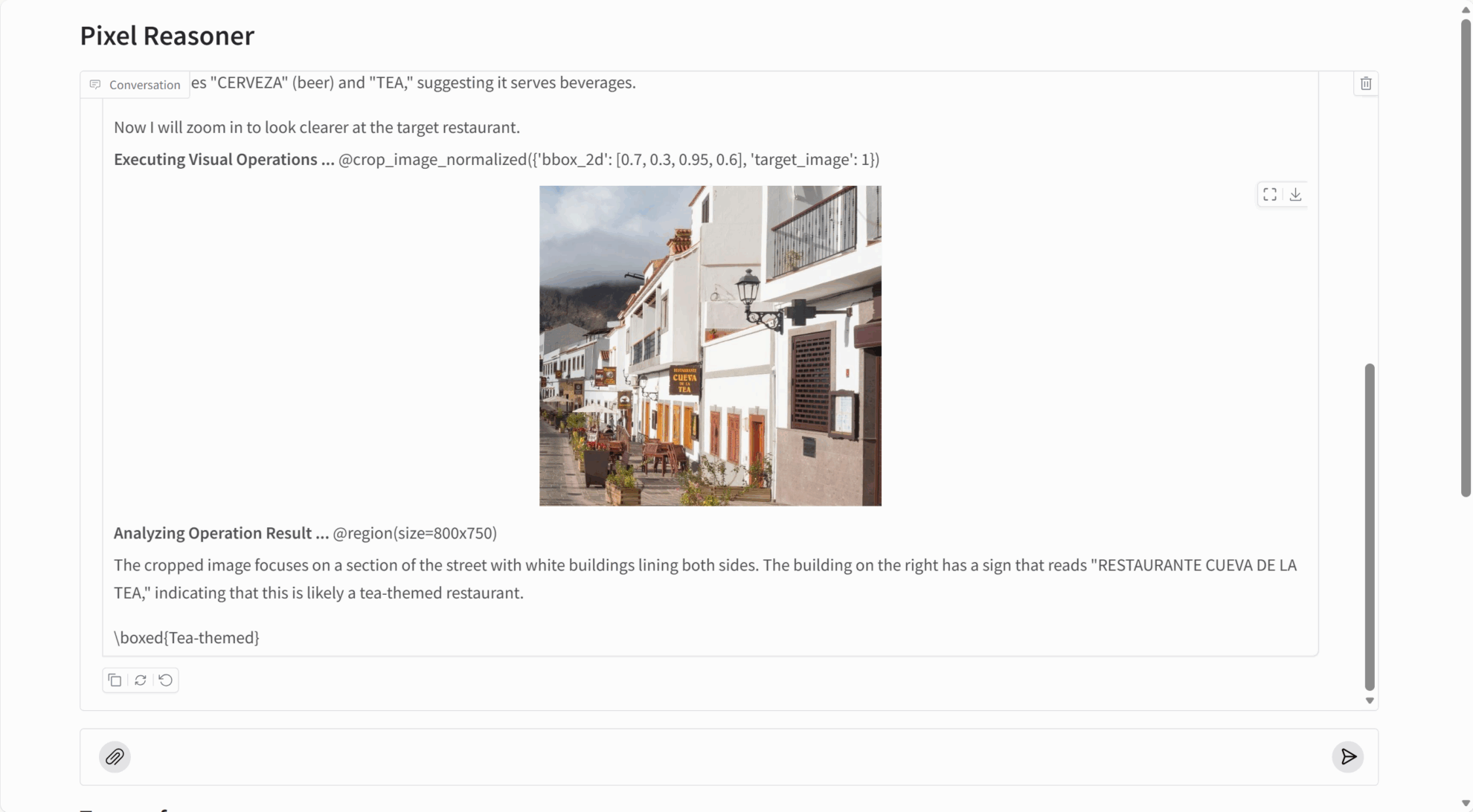
PixelReasoner-RL-v1 obtient des résultats exceptionnels sur de nombreuses tâches de raisonnement visuel :
- Compréhension de l'image : identification précise du contenu de l'image, des relations entre les objets et des détails de la scène.
- Capture de détails : Capable de détecter des objets minuscules, du texte intégré et d'autres informations fines dans les images.
- Analyse vidéo : Comprendre le contenu vidéo et les séquences d’actions en sélectionnant les images clés.
- Raisonnement spatial : compréhension précise de la position spatiale et des relations relatives des objets.
3. Étapes de l'opération
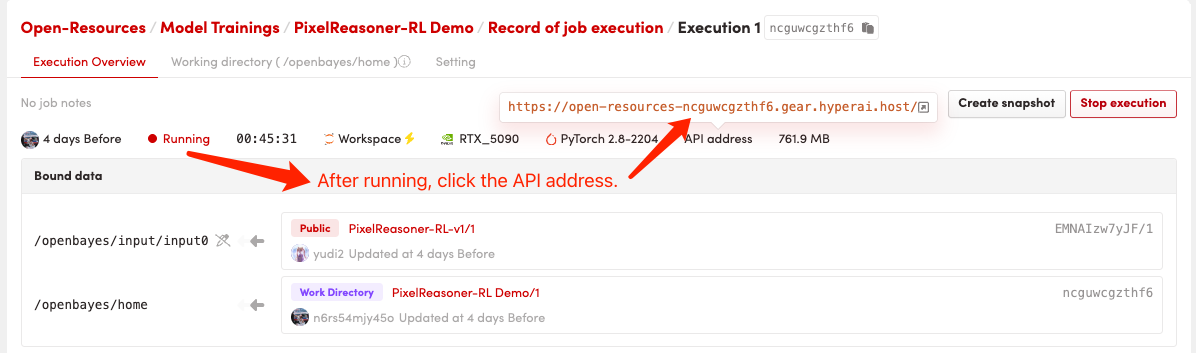
1. Démarrez le conteneur
Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Le démarrage initial prendra environ 2 à 3 minutes ; veuillez patienter. Une fois le déploiement terminé, cliquez sur « Adresse API » pour accéder directement à l’interface Grado.
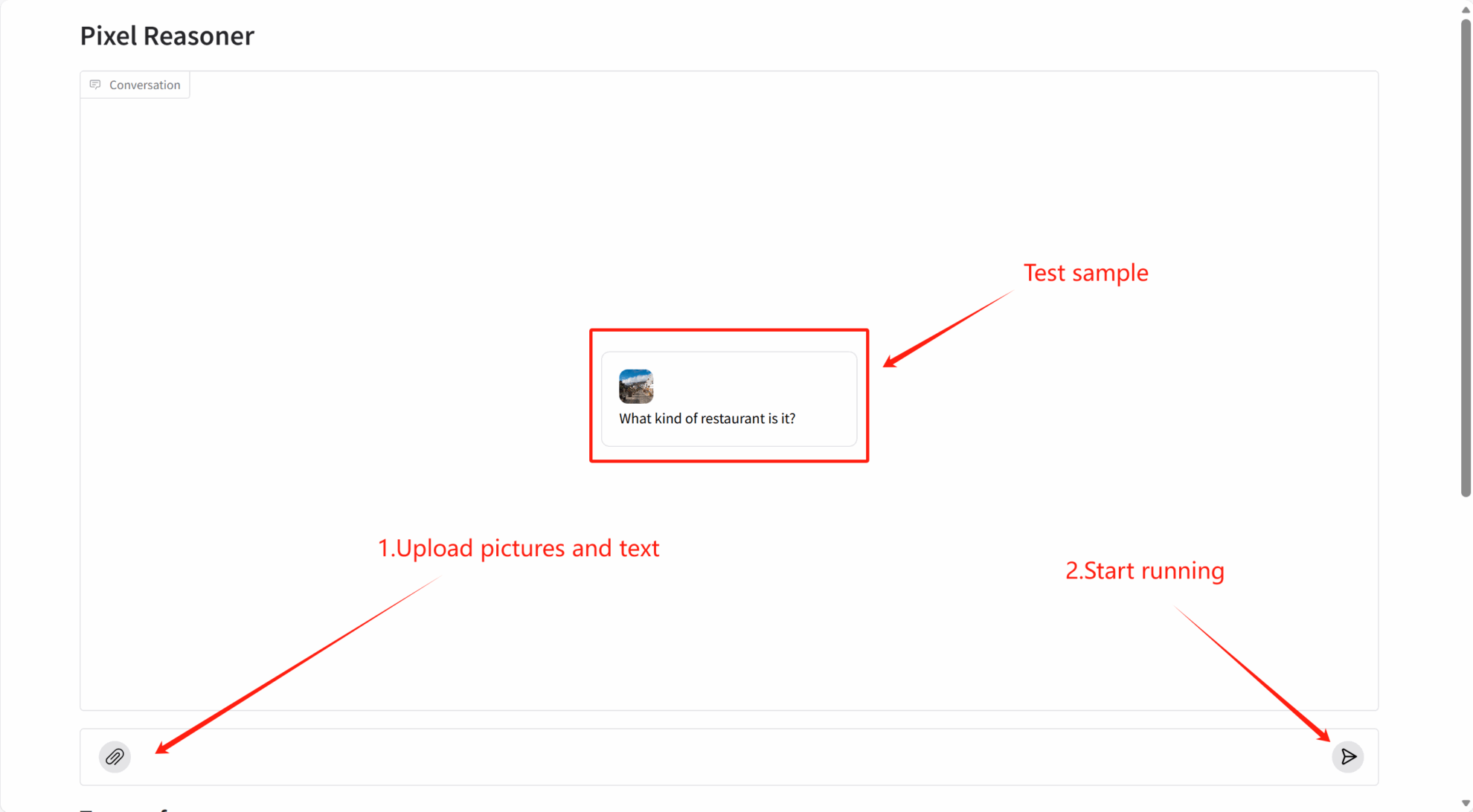
2. Pour commencer
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{pixelreasoner2025,
title={Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning},
author={Su, Alex and Wang, Haozhe and Ren, Weiming and Lin, Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2505.15966},
year={2025}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.