Command Palette
Search for a command to run...
MMaDA : Modèle De Langage Diffus Multimodal À Grande Échelle
1. Introduction au tutoriel

MMaDA-8B-Base est un modèle de langage multimodal à grande échelle, basé sur la diffusion, développé conjointement par l'Université de Princeton, l'équipe ByteDance Seed, l'Université de Pékin et l'Université Tsinghua, et publié le 23 mai 2025. Ce modèle est le premier modèle unifié à explorer systématiquement l'architecture de diffusion comme paradigme fondamental de l'apprentissage multimodal. Son objectif est d'atteindre des capacités d'intelligence générale applicables à différentes modalités grâce à une fusion profonde du raisonnement textuel, de la compréhension multimodale et de la génération d'images. Des articles de recherche associés sont disponibles. MMaDA : Modèles de langage multimodaux à grande diffusion .
Les ressources informatiques de ce tutoriel utilisent une seule carte A6000, et le modèle déployé est MMaDA-8B-Base. Trois exemples de génération de texte, de compréhension multimodale et de conversion de texte en image sont fournis à des fins de test.
2. Étapes de l'opération
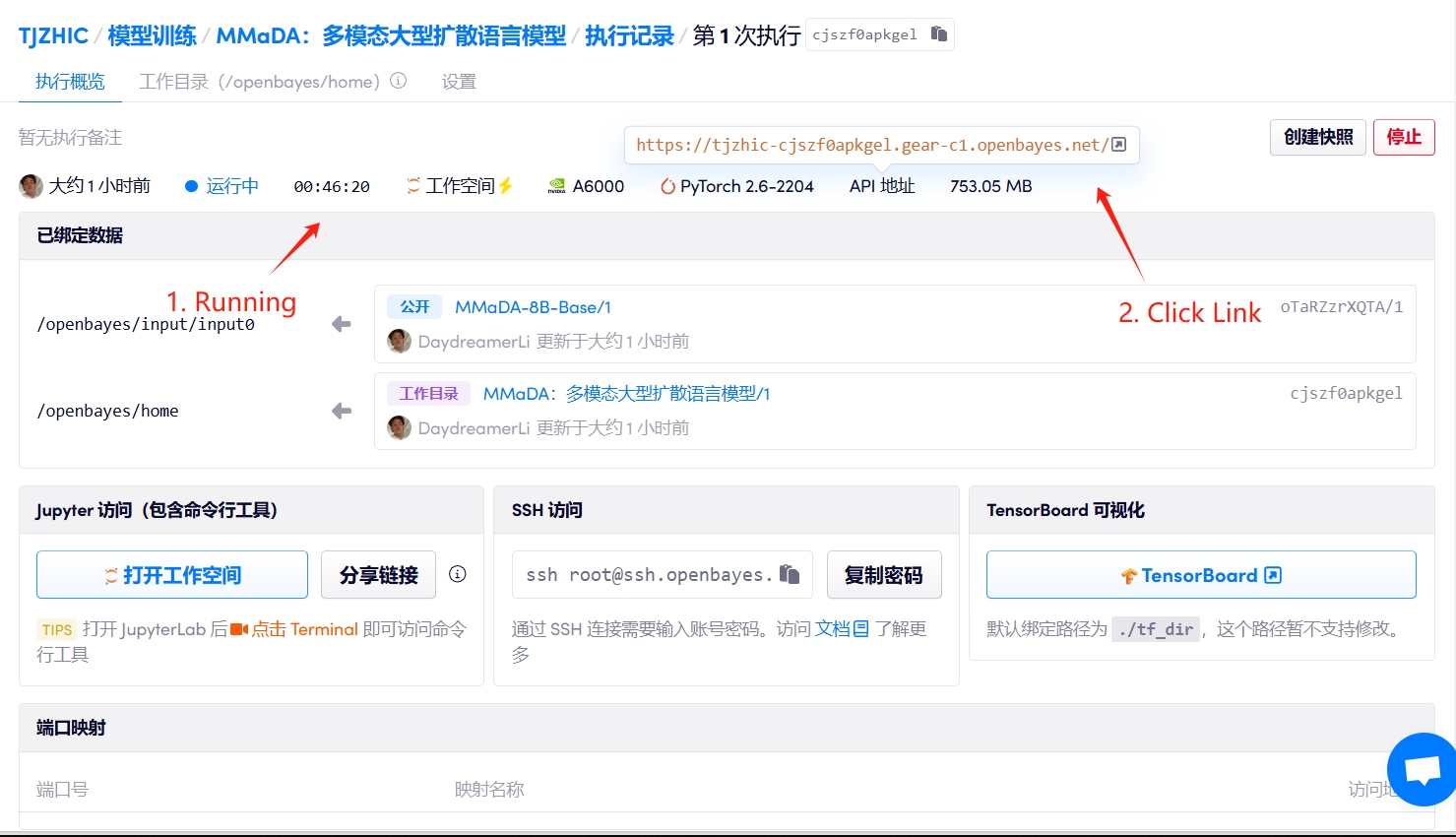
1. Démarrez le conteneur
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
2. Étapes d'utilisation
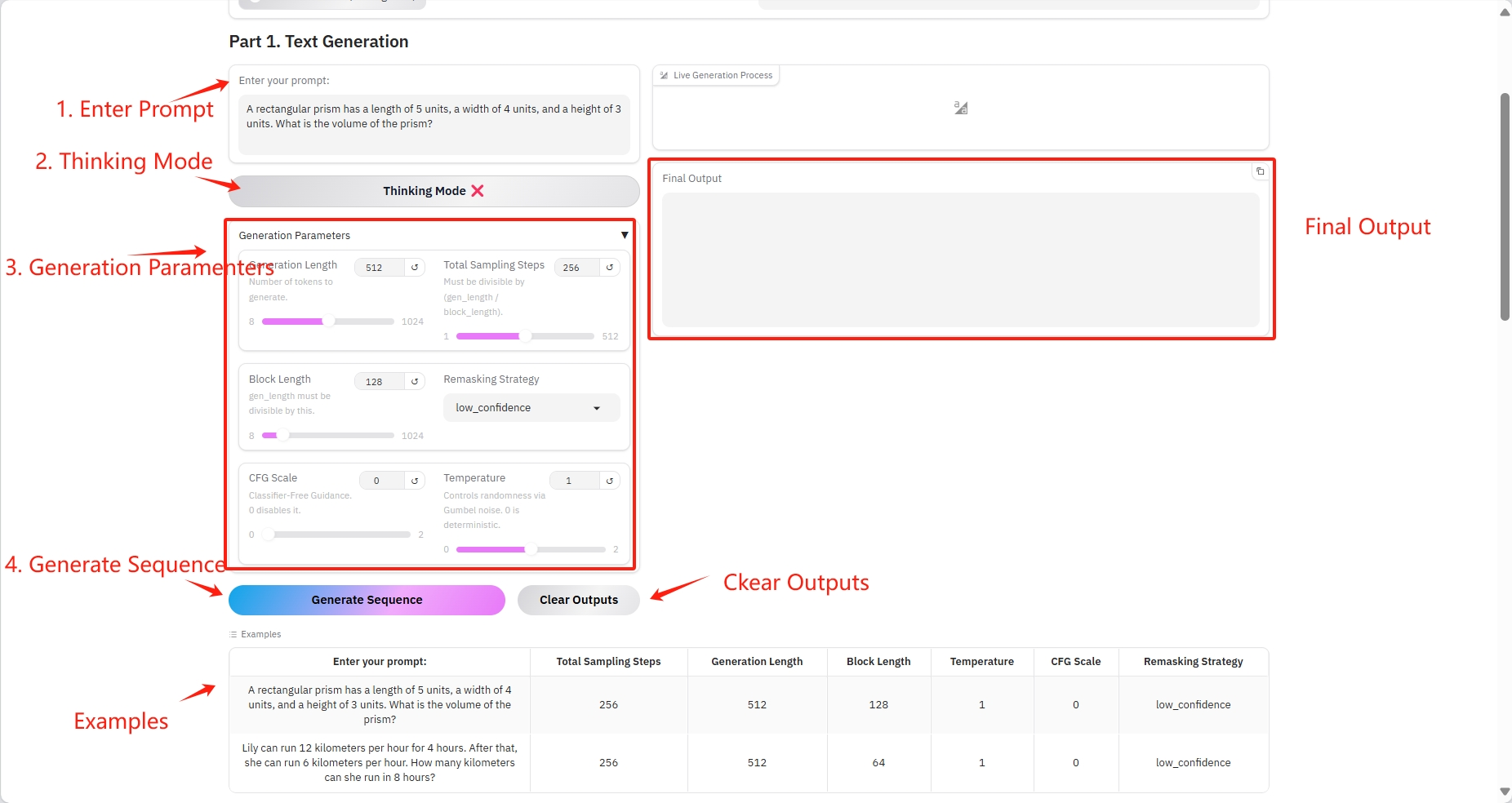
1. Génération de texte
Paramètres spécifiques :
- Invite : Vous pouvez saisir du texte ici.
- Durée de génération : le nombre de jetons générés.
- Nombre total d'étapes d'échantillonnage : doit être divisible par (gen_length / block_length).
- Longueur du bloc : gen_length doit être divisible par ce nombre.
- Stratégie de remasquage : Stratégie de remasquage.
- Échelle CFG : aucun guide de classification. 0 le désactive.
- Température : Contrôle le caractère aléatoire via le bruit de Gumbel. 0 est déterministe.
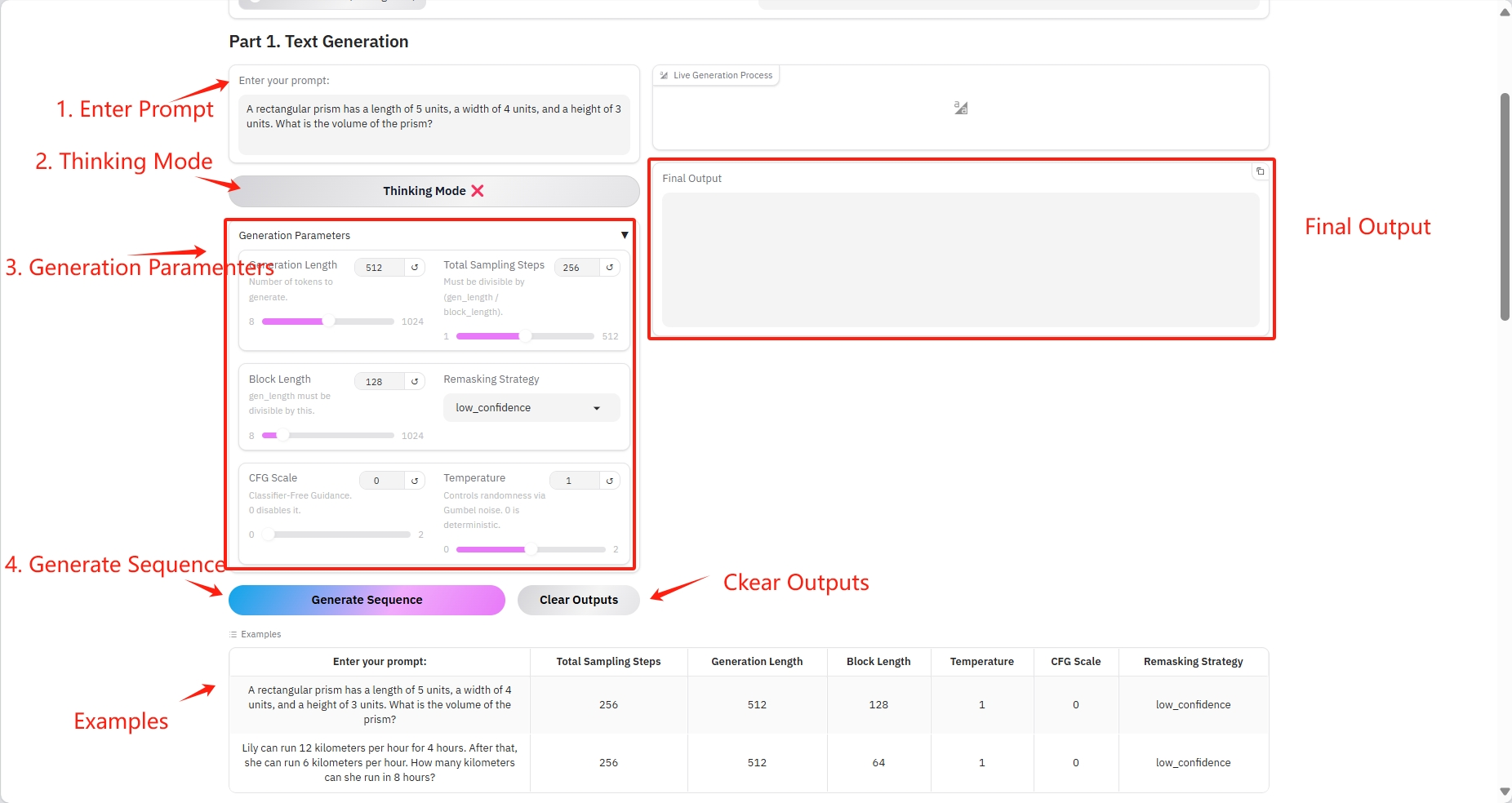
Résultat de sortie
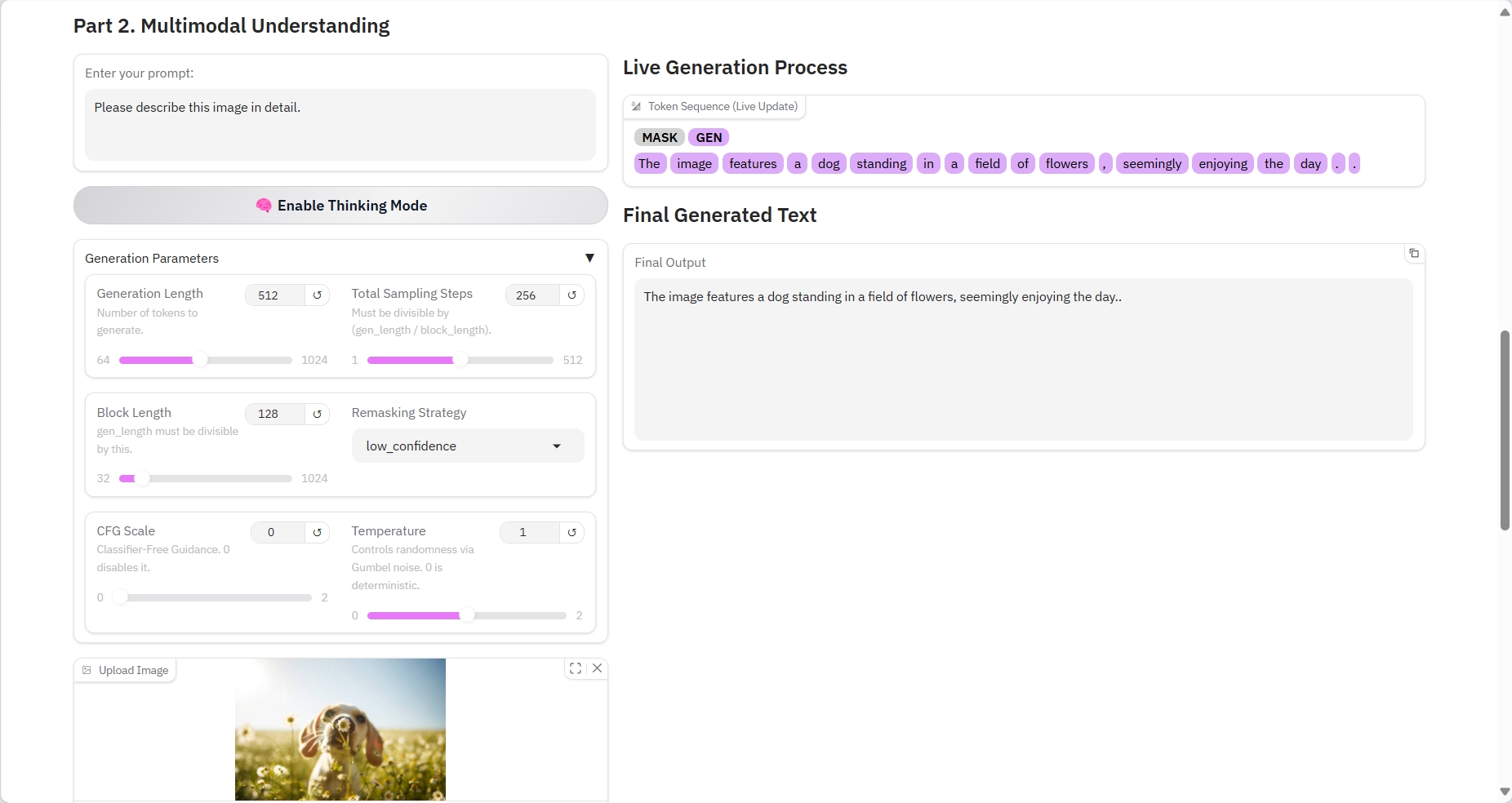
2. Compréhension multimodale
Paramètres spécifiques :
- Invite : Vous pouvez saisir du texte ici.
- Durée de génération : le nombre de jetons générés.
- Nombre total d'étapes d'échantillonnage : doit être divisible par (gen_length / block_length).
- Longueur du bloc : gen_length doit être divisible par ce nombre.
- Stratégie de remasquage : Stratégie de remasquage.
- Échelle CFG : aucun guide de classification. 0 le désactive.
- Température : Contrôle le caractère aléatoire via le bruit de Gumbel. 0 est déterministe.
- Image : photo.
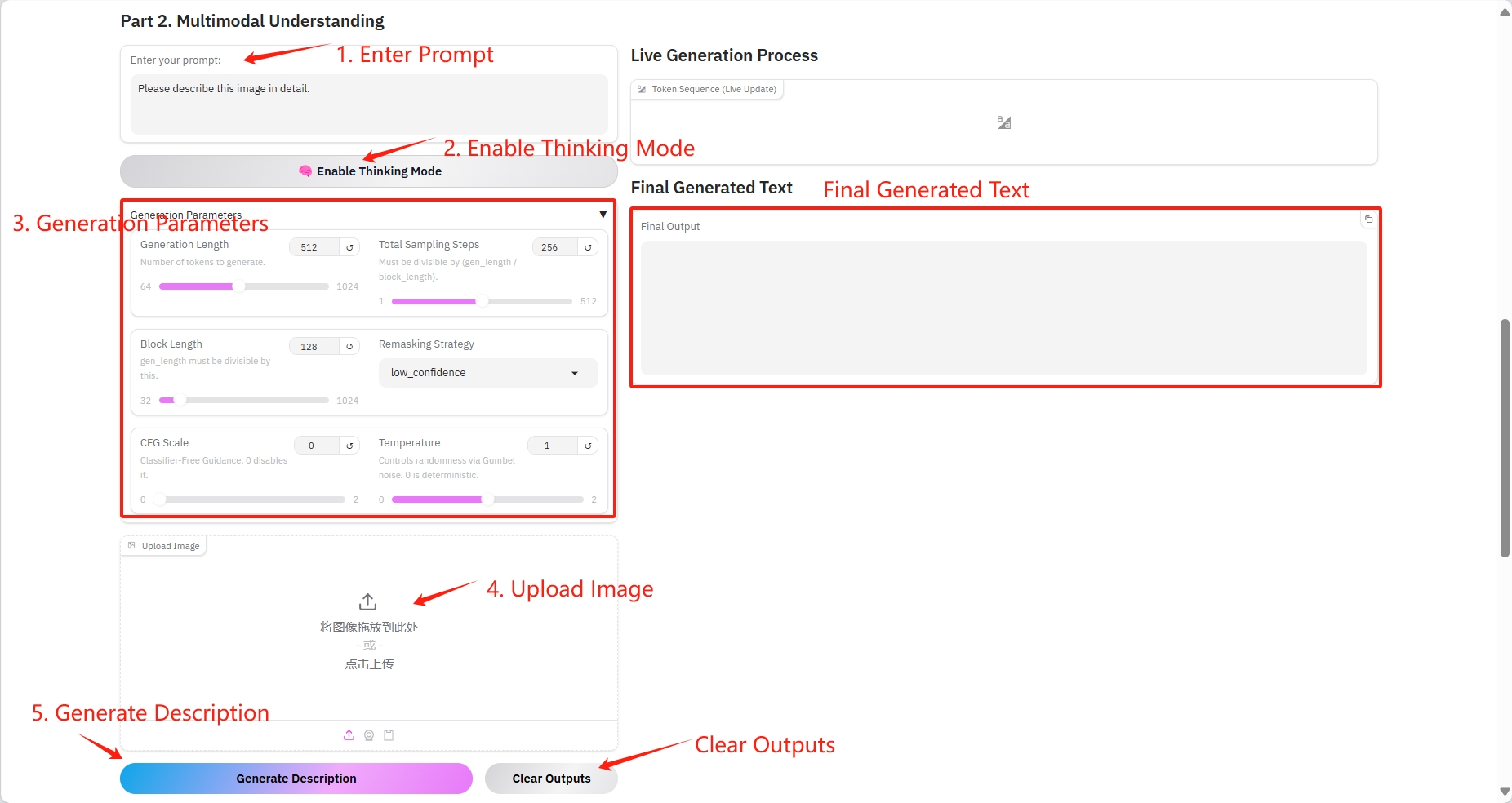
Résultat de sortie
3. Génération de texte en image
Paramètres spécifiques :
- Invite : Vous pouvez saisir du texte ici.
- Nombre total d'étapes d'échantillonnage : doit être divisible par (gen_length / block_length).
- Échelle de guidage : aucune orientation du classificateur. 0 le désactive.
- Planificateur :
- cosinus : La similarité cosinus calcule la similarité des paires de phrases et optimise les vecteurs d'intégration.
- sigmoïde : classification multi-étiquettes.
- Linéaire : la couche linéaire mappe le vecteur d'intégration du patch d'image à une dimension supérieure pour le calcul de l'attention.
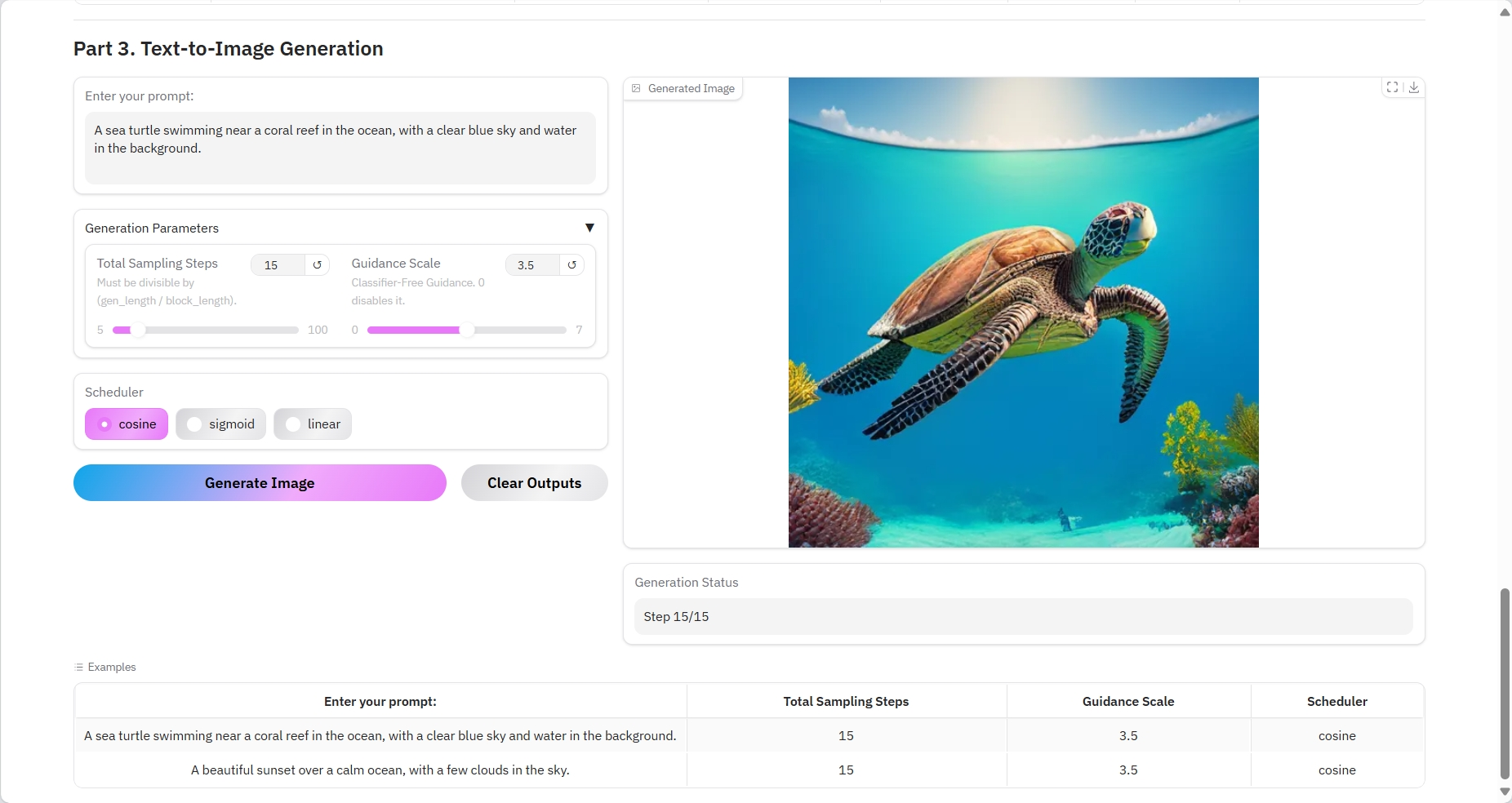
Résultat de sortie
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Merci à l'utilisateur Github SuperYang Déploiement de ce tutoriel. Les informations de citation pour ce projet sont les suivantes :
@article{yang2025mmada,
title={MMaDA: Multimodal Large Diffusion Language Models},
author={Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi},
journal={arXiv preprint arXiv:2505.15809},
year={2025}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.