Command Palette
Search for a command to run...
Déploiement En Un Clic De Qwen-Image-Lightning
Date
Organisation
Licence
Apache 2.0
1. Introduction au tutoriel

Qwen-Image-Lightning est une série de modèles de génération et d'édition d'images haute performance lancée par l'équipe Qwen à partir d'août 2025. Grâce à une technologie de distillation avancée, elle permet de générer des images de haute qualité avec un nombre minimal d'étapes d'inférence. Tout en conservant les puissantes capacités de génération visuelle de Qwen, cette série optimise considérablement la vitesse d'inférence et l'utilisation des ressources.
Ce déploiement exploite le modèle Qwen-Image-Lightning optimisé le plus récent pour créer un système de génération de contenu visuel extrêmement flexible. Le système prend en charge trois modes : édition guidée d’une seule image, fusion de deux images et création de texte pur, permettant aux utilisateurs de choisir librement les conditions d’entrée en fonction de leurs besoins créatifs. Grâce à un flux de travail de génération intégré et optimisé, cette solution peut générer des images sémantiquement cohérentes et de haute qualité visuelle en seulement quatre étapes d’inférence, abaissant ainsi considérablement le seuil technique pour la synthèse d’images de haute qualité et l’édition sémantique. Elle convient à divers scénarios créatifs nécessitant une visualisation rapide, tels que la création de contenu, la conception publicitaire et les médias interactifs.
Pour répondre aux besoins créatifs les plus pointus, le système propose également des options de configuration avancées, permettant un contrôle précis du processus de génération en ajustant des paramètres tels que la graine aléatoire, les étapes d'inférence, le ratio CFG, le ratio de guidage et les invites négatives, permettant ainsi d'obtenir le meilleur équilibre entre vitesse de génération, qualité d'image et liberté créative.
Ce tutoriel utilise la [version bf16] de [Qwen-Image-Lightning] comme démonstration, avec des ressources de puissance de calcul d'une seule carte RTX PRO 6000.
2. Étapes de l'opération
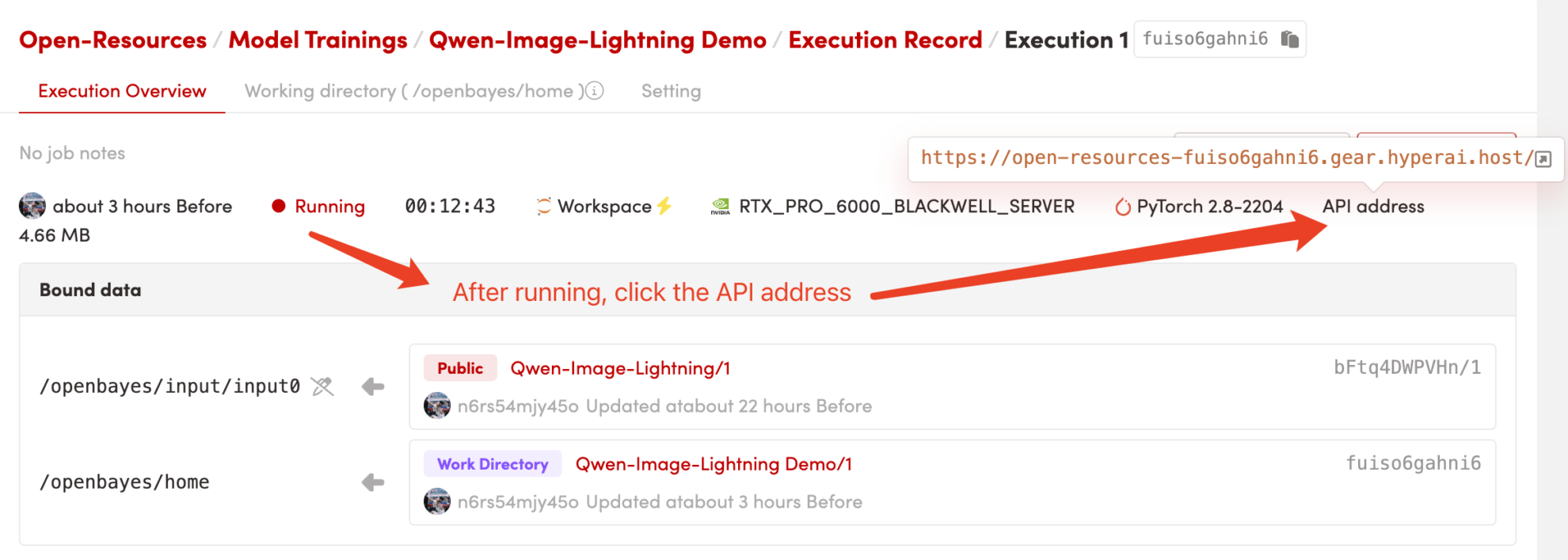
1. Démarrez le conteneur
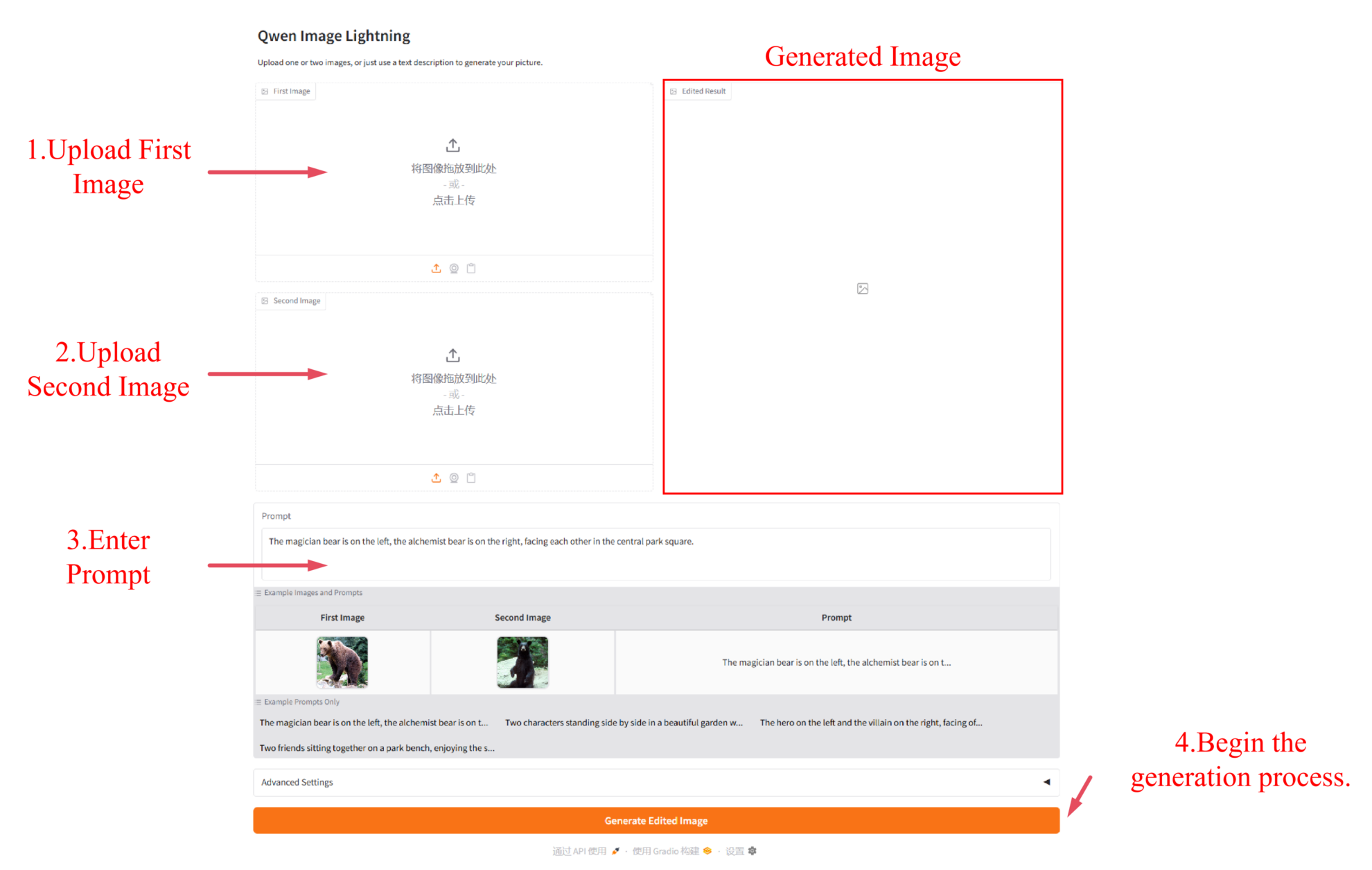
2. Exemples d'utilisation
Une fois la page web accessible, vous pouvez interagir avec le modèle. Si le message « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Compte tenu de sa taille importante, veuillez patienter environ 5 minutes, puis actualiser la page.
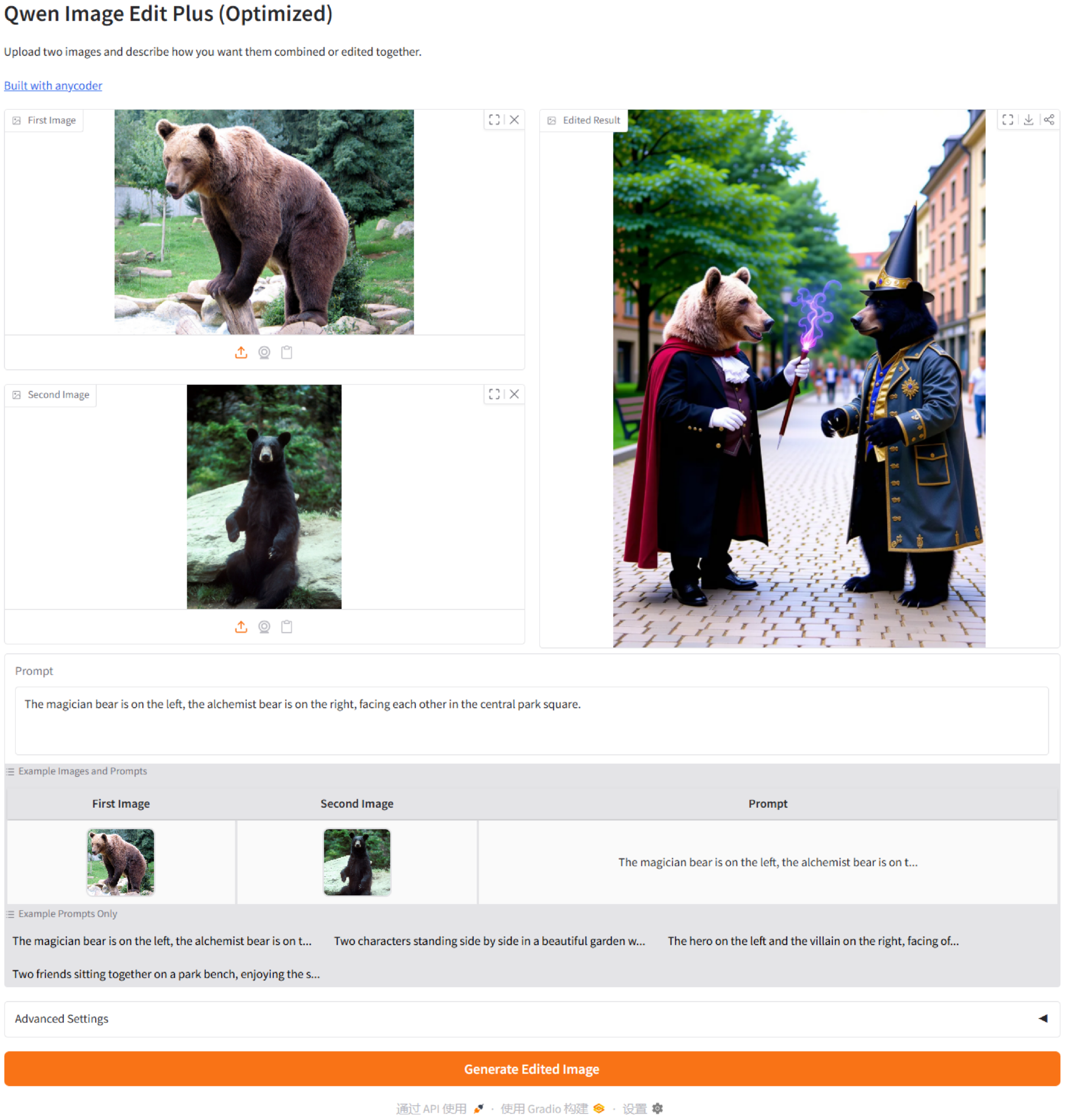
3. Génération des résultats
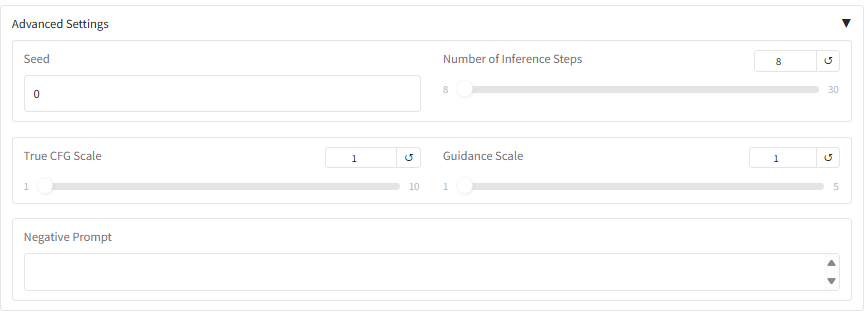
4. Paramètres avancés
Après avoir accédé aux paramètres avancés, vous pouvez affiner le processus de génération en ajustant les paramètres principaux suivants :
- Graine aléatoire : fixe le caractère aléatoire des résultats générés ; la même graine peut reproduire le résultat.
- Nombre d'étapes d'inférence : contrôle le nombre d'itérations de génération, ce qui influe sur la richesse des détails et le temps de génération.
- Échelle CFG : Ajuste le degré d’adhésion aux mots-clés ; plus la valeur est élevée, plus les mots-clés sont suivis strictement.
- Échelle de guidage : Équilibre l’importance relative de la génération conditionnelle et de la génération inconditionnelle.
- Indication négative : Spécifie les éléments de contenu qui doivent être exclus.
Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.