Command Palette
Search for a command to run...
Publié Dans La Revue Nature ! L'Université Des Sciences Et Technologies De Huazhong a Proposé Un Modèle d'IA De Stratégie De Fusion Pour Obtenir Une Prédiction Précise Du Risque De Mortalité Par Choc Septique Dans Plusieurs Centres Et Dans Toutes Les Spécialités

Le choc infectieux (également appelé choc septique) fait référence à un syndrome de troubles circulatoires graves et de troubles métaboliques cellulaires causés par une septicémie, qui peut être considéré comme le « stade terminal » du développement de la septicémie dans les manifestations cliniques. Le choc septique a un taux de mortalité extrêmement élevé et est actuellement l’une des maladies les plus mortelles dans les unités de soins intensifs.Selon un rapport de recherche basé sur la base de données nationale des soins intensifs du Royaume-Uni, le taux de mortalité à l'hôpital des patients souffrant de choc septique peut atteindre 55,5%.
Face à cette maladie évolutive avec un taux de mortalité élevé, l’accent clinique sur le choc septique est « le temps c’est la vie », et une détection précoce, une intervention précoce et un traitement précoce sont préconisés pour réduire le taux de mortalité. Cependant,En raison de la complexité de l’état des patients atteints de choc septique et de la rareté des données médicales cliniques, il est très difficile de fournir un avertissement précoce de la progression des patients atteints de choc septique., qui constitue également le principal obstacle à une intervention efficace dans la détérioration de la septicémie en choc septique.
À l’heure actuelle, avec l’approfondissement des technologies de l’information en médecine de soins intensifs, l’intégration croisée de l’intelligence artificielle et de la médecine de soins intensifs a rendu l’alerte précoce du sepsis plus difficile, mais la recherche sur le choc septique a pris du retard. Cela est dû au fait que la plupart des études ont des échantillons de petite taille, s’appuient sur un seul algorithme d’apprentissage automatique et n’ont pas réussi à passer la validation multicentrique, ce qui rend difficile leur promotion dans la pratique clinique de prédiction précoce des risques pour les patients atteints de choc septique.
Dans ce contexte, le professeur Ye Qing de l'hôpital Tongji affilié au Tongji Medical College de l'université des sciences et technologies de Huazhong et le professeur Wu Hong de l'école de gestion médicale et de santé ont mis au point un modèle de fusion de classification (TCF) basé sur TOPSIS (technique de préférence d'ordre par similarité avec une solution idéale) pour prédire le risque de décès dans les 28 jours chez les patients atteints de choc septique en unité de soins intensifs.Le modèle intègre 7 modèles d’apprentissage automatique et présente une stabilité et une précision élevées dans la validation interprofessionnelle et multicentrique.Il fournit aux cliniciens un outil auxiliaire fiable pour l’alerte précoce du risque de décès par choc septique.
Les résultats de la recherche ont été publiés dans la revue filiale de Nature, npj Digital Medicine, sous le titre « Modèles de prédiction de la mortalité multispécialité basés sur l'intelligence artificielle pour le choc septique dans une étude rétrospective multicentrique ».
Points saillants de la recherche :
* L'étude a adopté une stratégie de fusion efficace pour construire un modèle de fusion avec une capacité de généralisation et une robustesse élevées basées sur plusieurs modèles de classification de base, surmontant ainsi le problème de la faible performance des cohortes de petits échantillons et des modèles de classification uniques dans les scénarios cliniques.
* Les résultats de la recherche ont permis une avancée majeure dans la difficulté de prédire le risque de décès précoce en cas de choc septique, en fournissant aux cliniciens un outil de prise de décision clinique efficace, stable et fiable qui aide les médecins à surveiller de près la progression de l'état des patients plus tôt et à prendre des mesures de traitement plus actives.

Adresse du document :
https://go.hyper.ai/faMLL
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensembles de données : données volumineuses, traitement précis
Afin de construire un modèle de prédiction de choc septique avec une large applicabilité,L’équipe de recherche a intégré les données cliniques de 4 872 patients atteints de choc septique en soins intensifs provenant de trois hôpitaux de février 2003 à novembre 2023.Les antécédents des participants sont complexes et divers, ce qui aidera l’équipe de recherche à mener une validation multicentrique et interspécialisée pour démontrer la validité et l’applicabilité du modèle. Comme le montre la figure suivante :
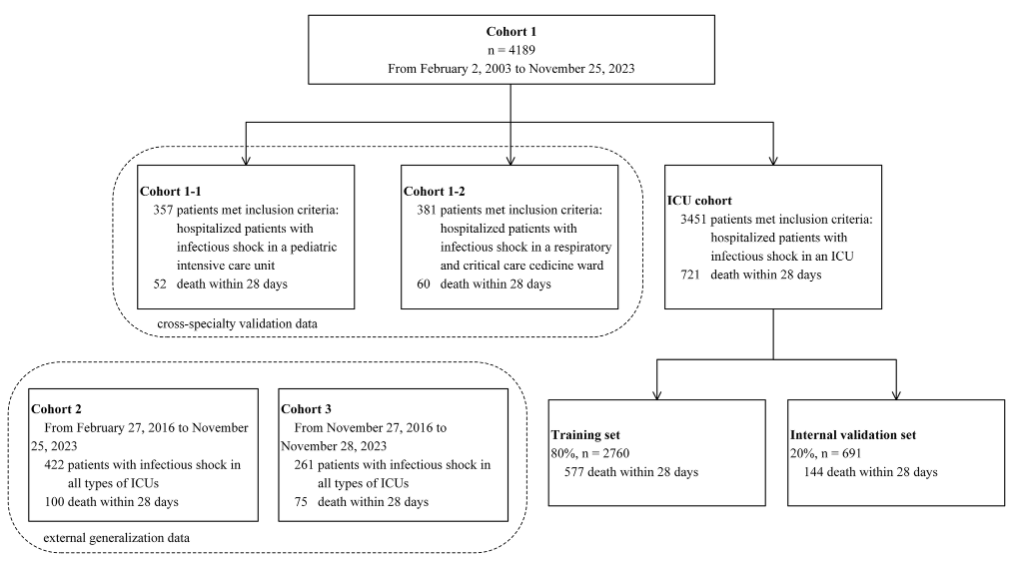
Spécifiquement,La cohorte 1 comprenait 4 189 participants.Parmi eux, il y avait 3 451 patients en réanimation générale (721 positifs et 2 730 négatifs) ; 357 patients en USI pédiatrique (cohorte 1-1) (52 positifs) ; et 381 patients en réanimation respiratoire (cohorte 1-2) (60 positifs).
* Les résultats positifs sont ceux des participants qui ont connu un décès toutes causes confondues dans les 28 jours suivant l'hospitalisation en USI, et les participants qui n'ont pas connu de décès toutes causes confondues sont marqués comme des résultats négatifs (les mêmes ci-dessous)
Parmi eux, l’ensemble de données générales des patients des unités de soins intensifs a été utilisé comme population de recherche principale et pour la construction du modèle et la validation interne.Les données de formation et les données de validation ont été divisées en 8:2, avec respectivement 2 760 sujets (577 positifs) et 691 sujets (144 positifs).Les ensembles de données des patients pédiatriques en soins intensifs et des patients en soins respiratoires intensifs ont également permis d'évaluer l'applicabilité et la stabilité du modèle dans différentes unités de soins intensifs spécialisées.
Les cohortes 2 et 3 comprenaient des patients atteints de choc septique provenant de différentes unités de soins intensifs, avec respectivement 422 participants (100 positifs, 322 négatifs) et 261 participants (75 positifs, 186 négatifs).Ces deux parties de l’ensemble de données sont principalement utilisées pour la validation externe afin d’évaluer sa capacité de généralisation et son efficacité dans différents centres.
De plus, afin d’obtenir des résultats expérimentaux précis,L’équipe de recherche a extrait 93 caractéristiques cliniques communes.Incluant des informations démographiques, l'historique des maladies et des traitements, des informations sur les signes vitaux, etc., il a finalement été optimisé à 34 éléments pour l'expérience.
Spécifiquement,Le prétraitement des données comprend 5 parties :Dans la première étape, l’équipe de recherche a d’abord calculé le taux manquant et supprimé 23 variables avec des taux manquants supérieurs à 30% ; dans la deuxième étape, la variance des caractéristiques booléennes a été calculée selon la formule de variance de Bernoulli, et les variables aléatoires discrètes avec une cohérence dépassant 90% ont été à nouveau supprimées ; dans la troisième étape, la méthode d'interpolation des valeurs manquantes (interpolation multiple par régression logistique) a été utilisée pour optimiser davantage jusqu'à 61 variables ; dans la quatrième étape, les caractéristiques de corrélation élevée ont été à nouveau examinées (coefficient de corrélation de Pearson ≥ 0,7), et il restait 50 variables à ce moment-là. Comme le montre la figure suivante :
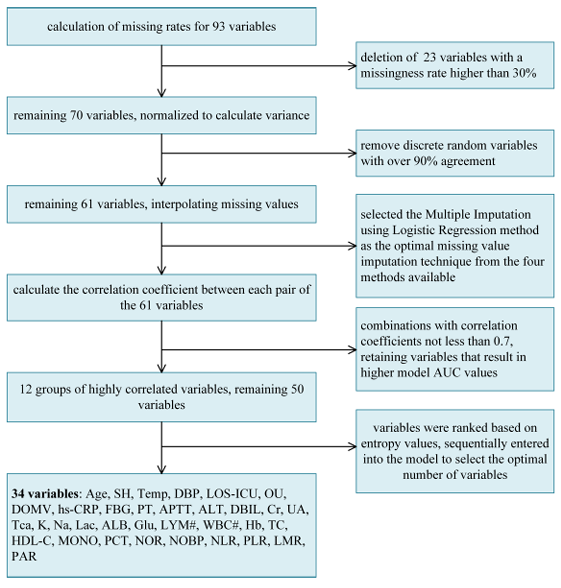
Dans la cinquième étape, les chercheurs ont trié les variables en fonction de l’entropie de l’information (de la plus élevée à la plus faible) et ont finalement sélectionné 34 variables clés pour l’expérience, y compris des facteurs importants tels que l’âge, les antécédents chirurgicaux, la température corporelle et la pression artérielle diastolique.
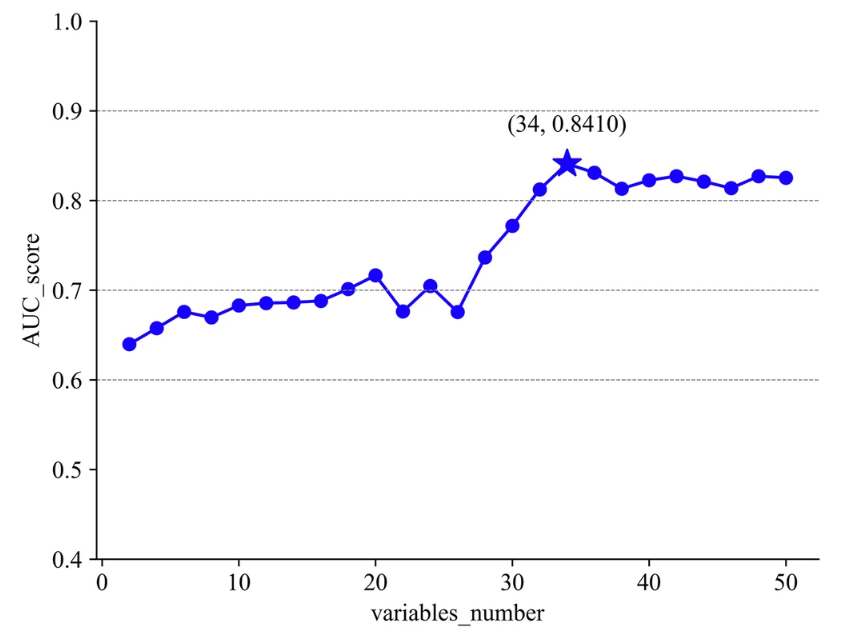
Il convient de noter qu’afin de protéger la confidentialité des participants, toutes les données ont été anonymisées avant l’analyse.
Architecture du modèle : modèle de fusion, prédiction précise
La recherche du modèle TCF est principalement divisée en trois étapes :La première étape consiste à établir 7 sous-modèles à partir des données d’hospitalisation des patients atteints de choc septique, chacun produisant des résultats pour 6 indicateurs d’évaluation ; la deuxième étape consiste à intégrer les sous-modèles dans un modèle de fusion basé sur la stratégie de fusion et à vérifier que le modèle est supérieur aux autres modèles ; la troisième étape consiste à tester différents ensembles de données pour vérifier les performances du modèle et effectuer une analyse d'interprétabilité sur le modèle (expliquée dans la section des résultats expérimentaux).
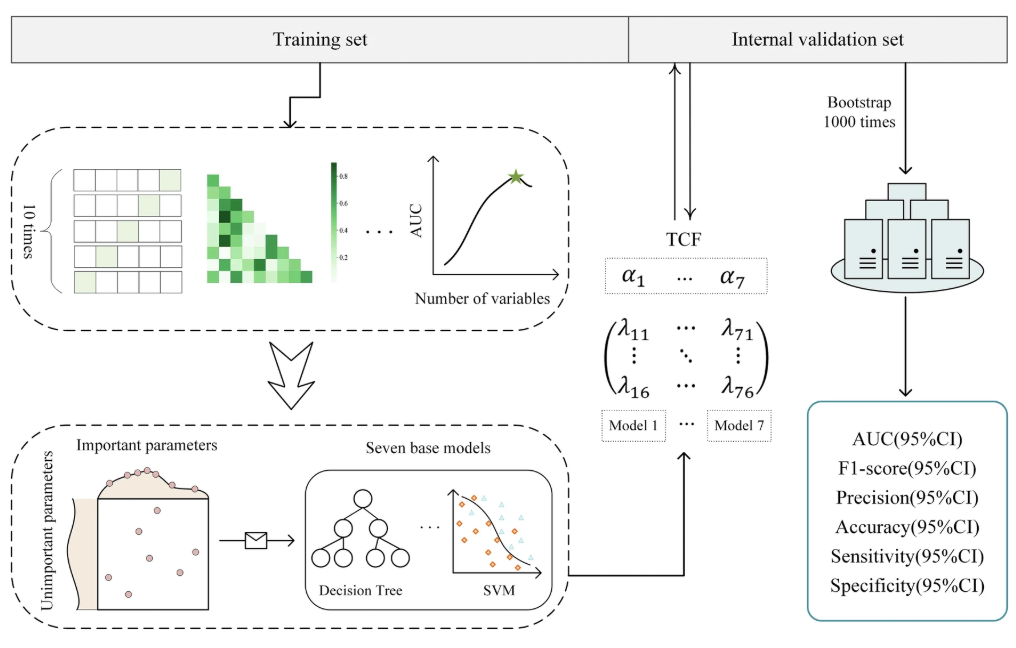
Spécifiquement,Dans la première étape, l’équipe de recherche a d’abord formé et testé 7 sous-modèles à l’aide de l’ensemble de données ICU commun traité par caractéristiques.La technique de suréchantillonnage des minorités synthétiques (SMOTE) a été appliquée à l'ensemble d'entraînement selon la règle 1:1 pour atténuer l'impact négatif du déséquilibre des classes. Après la normalisation min-max, la combinaison optimale de paramètres a été déterminée par une validation croisée quintuple et une recherche aléatoire, et 7 sous-modèles ont été formés sur l'ensemble d'entraînement, à savoir Decision Tree (DT), Random Forest (RF), XGBoost (XGB), LightGBM (LGBM), Naive Bayes (NB), Support Vector Machine (SVM) et Gradient Boosted Decision Tree (GBDT).
Enfin, l’équipe de recherche a utilisé des données de validation internes pour vérifier les résultats des tests.La performance du modèle est évaluée à l’aide de 6 indicateurs d’évaluation.Il s'agit de l'aire sous la courbe ROC (AUC), du score F1, de la précision (PRE), de l'exactitude (ACC), de la sensibilité (SEN) et de la spécificité (SPE).
Dans la deuxième étape, l’équipe de recherche a intégré ces sept sous-modèles, chacun avec ses propres avantages et inconvénients.Un modèle de fusion de classification TCF basé sur TOPSIS a été conçu pour combiner les résultats d'évaluation de sept modèles afin de fournir un résultat de prédiction complet pour le diagnostic du choc septique. Les poids des sous-modèles ont été calculés par le score TOPSIS, et la probabilité de prédiction pondérée était la probabilité de prédiction du TCF. Les résultats de classification du TCF ont été dérivés avec 0,5 comme valeur critique.
L'algorithme spécifique de fusion du modèle TCF est le suivant :
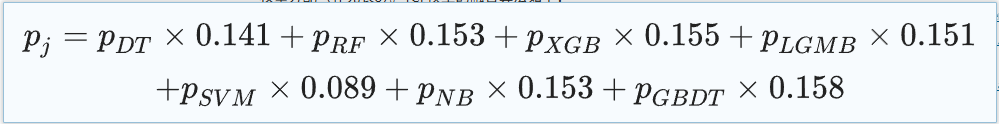
En termes d'analyse statistique, pour les caractéristiques continues, les statistiques de la médiane, du quartile supérieur et du quartile inférieur sont données ; pour les caractéristiques discrètes, la proportion de chaque catégorie est indiquée.Dans cette étude, le plus petit ensemble de données est la cohorte 3 et, selon le théorème de la limite centrale, la distribution moyenne des caractéristiques continues peut être considérée comme une distribution normale.
Alors,L’étude a utilisé le test de Levene pour déterminer l’homogénéité des caractéristiques entre deux ensembles de données.Le test du Chi carré a été utilisé pour comparer les différences dans les caractéristiques discrètes entre d'autres données et l'ensemble de validation interne, et les différences dans les caractéristiques continues ont été testées à l'aide du test t d'échantillon indépendant ou du test t de Welch, et 1 000 échantillons bootstrap ont été utilisés pour calculer les intervalles de confiance 95% des indicateurs d'évaluation.
Afin d’acquérir une compréhension plus approfondie du processus de raisonnement du modèle, l’équipe de recherche a également visualisé l’importance des fonctionnalités en dessinant une carte thermique d’importance des fonctionnalités SHAP. Prenons comme exemple le modèle GBDT avec les meilleures performances AUC, comme illustré dans la figure suivante :
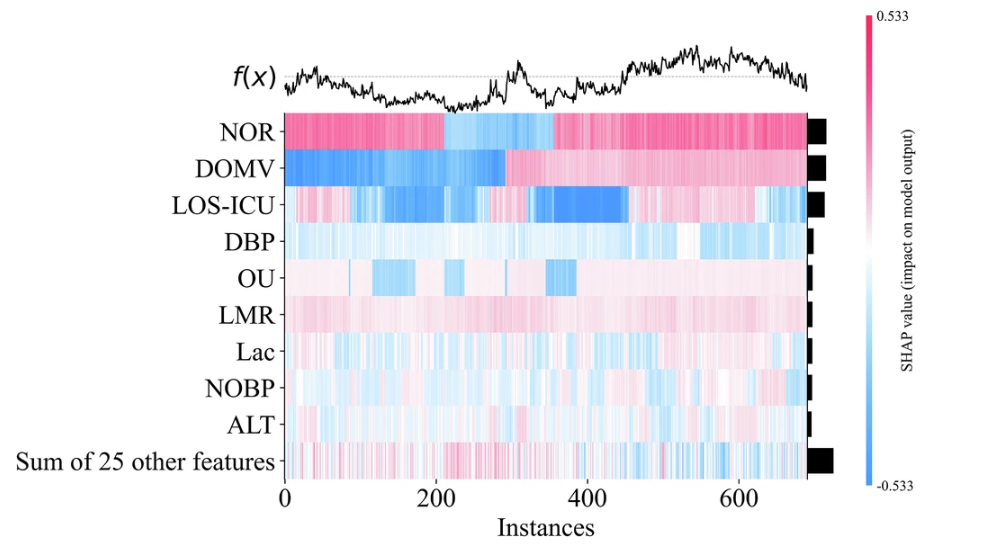
Le classement de l’importance des fonctionnalités peut non seulement améliorer la transparence et la crédibilité des modèles de prédiction clinique, mais également fournir une référence précieuse pour la pratique médicale. De cette façon,Le modèle répond non seulement à la demande des médecins en matière de transparence, mais quantifie également le bénéfice clinique net.Il permet à la fois une interprétabilité clinique et une praticabilité, posant ainsi les bases de l’application du modèle dans la pratique clinique.
Résultats expérimentaux : vérification multidimensionnelle, fiable et facile à utiliser
Pour vérifier les performances du modèle de fusion (TCF), l’équipe de recherche l’a d’abord comparé aux sous-modèles. Les résultats sont présentés dans la figure ci-dessous :
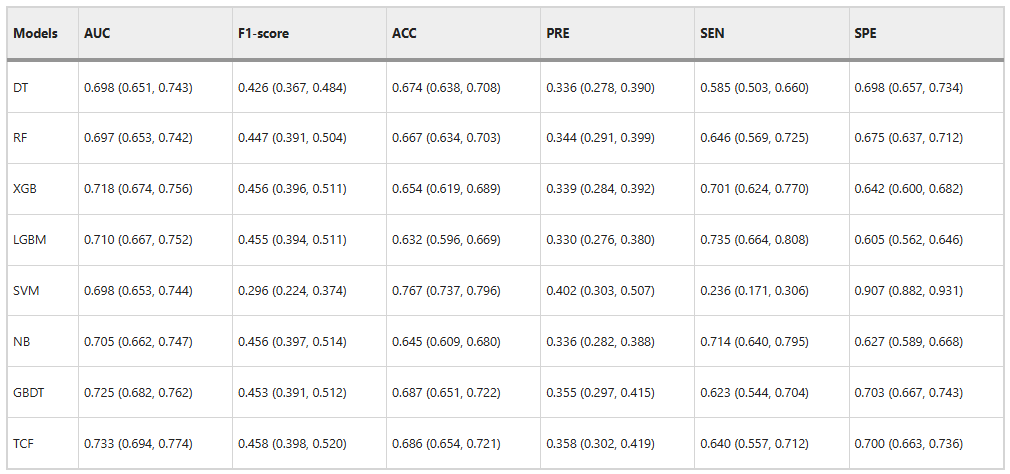
Le TCF surpasse les sous-modèles dans les deux indicateurs d’évaluation complets de l’ensemble de validation interne.L'ASC est de 0,733 et le score F1 est de 0,458. De plus, l'ACC de 0,686 et le PRE de 0,358 sont également plus élevés que la plupart des sous-modèles. Cela démontre son excellente capacité de classification.
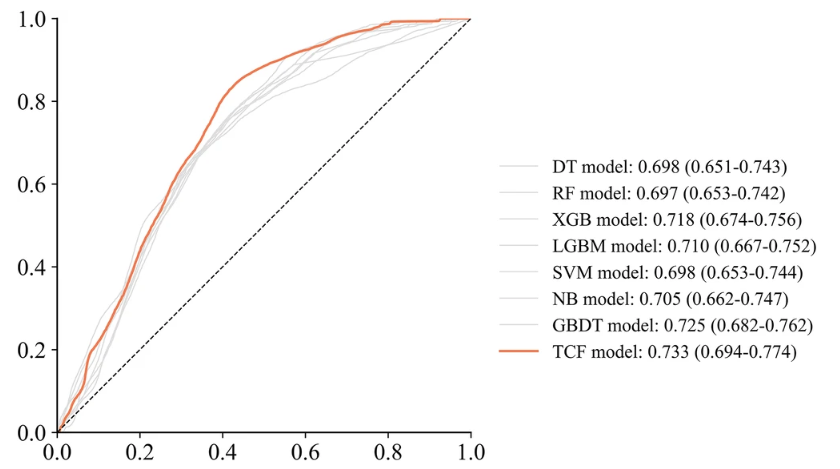
Bien que les scores du modèle TCF sur SEN et SPE ne soient pas aussi bons que les meilleures performances, qui sont respectivement de 0,640 et 0,700,Mais il peut identifier l’effet à travers l’écart de l’ensemble du sous-modèle, obtenant ainsi la meilleure performance globale.Comme le montre la figure ci-dessous.
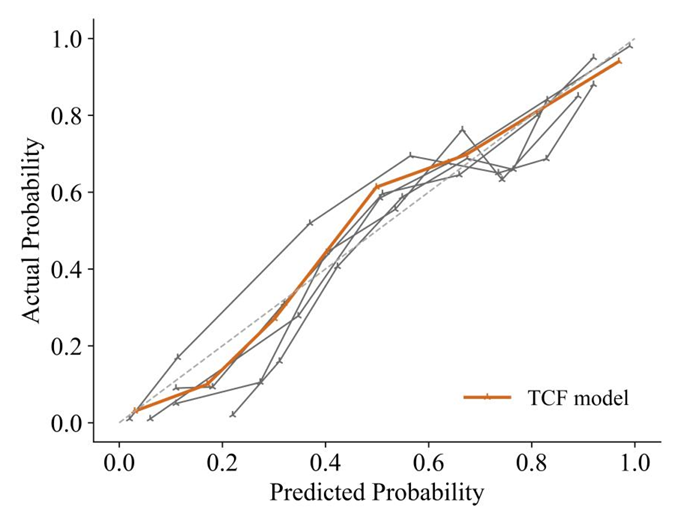
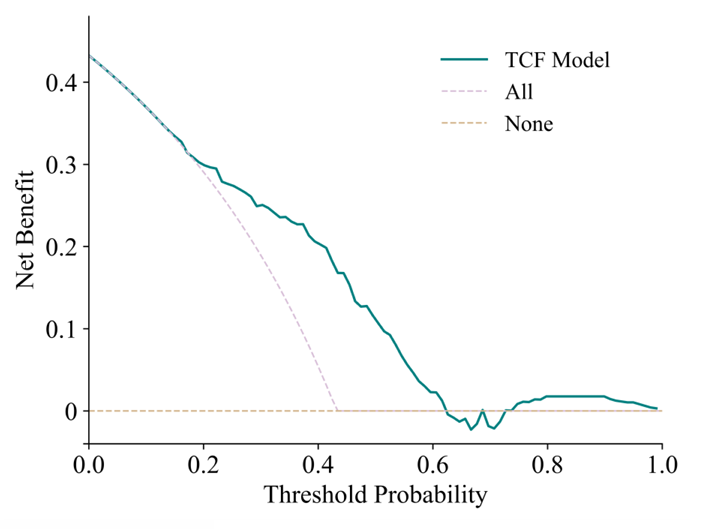
La courbe d'étalonnage et la courbe d'analyse de la courbe de décision (DCA) montrent que les résultats prédits du modèle TCF sont cohérents avec les résultats réels.Premièrement, la courbe d’étalonnage du modèle TCF est la plus proche de la ligne diagonale, ce qui indique qu’il présente les meilleures performances d’étalonnage parmi tous les modèles. Deuxièmement, la courbe du modèle TCF est toujours meilleure que les stratégies « Tout » et « Aucun » sous la plupart des probabilités de seuil, en particulier dans la plage de probabilité de 0,1 à 0,5, montrant des rendements nets plus élevés. Cela suggère que le modèle TCF a une valeur d’application clinique potentielle dans une certaine gamme et peut aider les cliniciens à prendre des décisions plus favorables.
L’équipe de recherche a ensuite procédé à une validation multicentrique, qui a pu démontrer plus précisément les performances prédictives du modèle TCF et l’hétérogénéité entre les différents ensembles de données. Comme le montre la figure suivante :
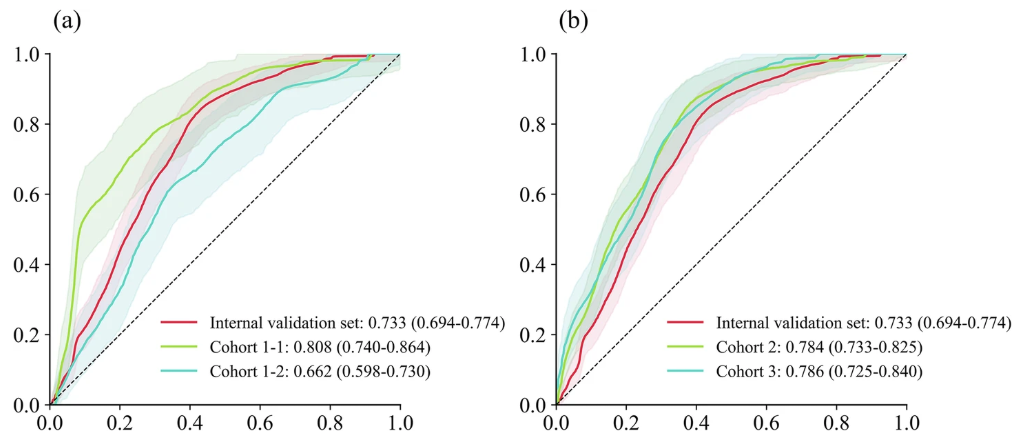
On peut voir que contrairement à la plupart des études où l’effet de prédiction multicentrique est légèrement inférieur à celui de l’ensemble d’entraînement et de l’ensemble de validation interne, dans cette étude, à l’exception d’une légère diminution de l’ASC (0,662) de la cohorte 1-2 (ensemble de données de patients en USI respiratoire),Les ASC de la cohorte 1-1 (ensemble de données de patients pédiatriques en USI), de la cohorte 2 et de la cohorte 3 se sont toutes améliorées.Ils sont respectivement de 0,808, 0,784 et 0,786.
De plus, en raison du nombre limité d’échantillons multicentriques,L’équipe de recherche a spécifiquement combiné 4 ensembles de données de validation externes pour la prédiction (1 421 données de patients, dont 287 cas positifs).Son ASC était de 0,7705, ce qui indiquait que le modèle TCF pouvait distinguer efficacement les patients présentant de faibles facteurs de risque de choc septique et avait une bonne capacité d'étalonnage.
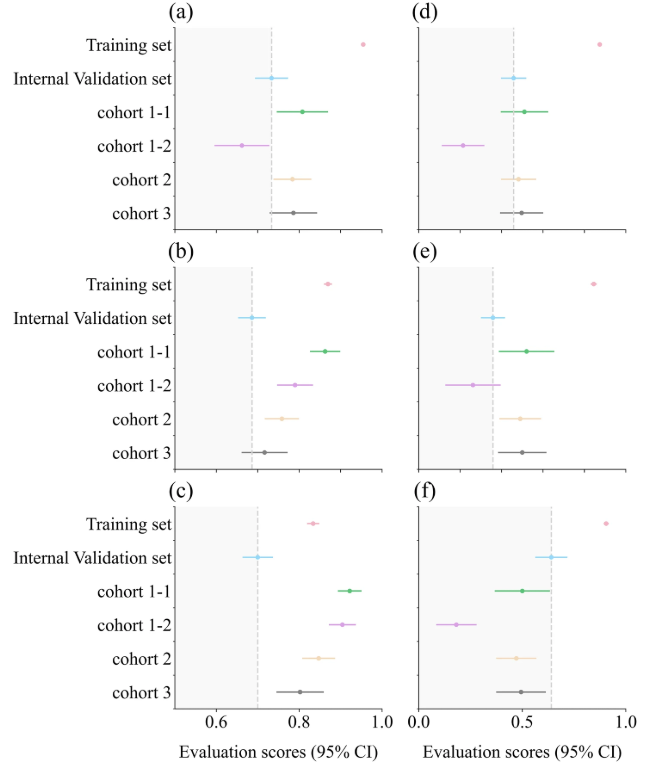
Parmi eux, a est le box plot AUC ; b est le diagramme en boîte de l'ACC ; c est le diagramme en boîte SPE ; d est le diagramme en boîte du score F1 ; e est le box plot PRE ; et f est le diagramme en boîte SEN. La ligne pointillée grise indique les résultats de l'ensemble de validation interne, et les scores d'évaluation des autres ensembles de données se situent dans la zone gris foncé, indiquant une diminution des performances par rapport à l'ensemble de validation interne.
En résumé, le modèle TCF a obtenu des performances cohérentes et bonnes à la fois sur l’ensemble de données interne et sur l’ensemble de validation externe, montrant des performances supérieures par rapport aux modèles uniques dans la prédiction du risque de mortalité dans les 28 jours chez les patients atteints de choc septique.Ce modèle fournit aux cliniciens des unités de soins intensifs un outil de prédiction fiable et facile à utiliser, en particulier dans les premiers stades critiques de la détérioration de l’état d’un patient. Il peut aider efficacement les médecins à fournir des interventions de traitement efficaces et personnalisées pour différents patients et à améliorer le pronostic des patients.
L'intelligence artificielle joue un rôle important dans le traitement du sepsis/choc septique
Avec le développement continu de la science et de la technologie, l’intégration croisée de l’intelligence artificielle et de la médecine de soins intensifs est depuis longtemps devenue un domaine de grande préoccupation pour les chercheurs concernés. Cette étude constitue sans aucun doute une exploration à valeur pionnière. Comme mentionné ci-dessus, la septicémie/le choc septique est une crise de santé publique mondiale avec une mortalité et une morbidité élevées, et une détection et une intervention précoces sont nécessaires de toute urgence pour améliorer le taux de survie des patients.
Par le passé, les recherches sur les modèles d’alerte précoce pour la septicémie ont déjà prospéré et de nombreux laboratoires ont présenté des résultats de recherche pertinents.
Par exemple, une étude intitulée « Apprentissage automatique pour la détection précoce du sepsis : une étude de validation interne et temporelle » publiée par Armando D Bedoya et al. de l'Université Duke aux États-Unis.Il introduit et vérifie un modèle de prédiction MGP-RNN basé sur l'apprentissage profond (processus gaussien multi-sorties et réseau neuronal récurrent).En comparaison avec trois méthodes d'apprentissage automatique, dont la forêt aléatoire, la régression de Cox et la régression logistique pénalisée, ainsi que trois scores cliniques, le modèle a surpassé les autres modèles et scores cliniques dans tous les indicateurs et peut détecter la septicémie 5 heures à l'avance.
Adresse du document :
https://pmc.ncbi.nlm.nih.gov/articles/PMC7382639
De plus, une équipe d’une société californienne appelée Dascena a également donné son avis dans une étude utilisant une méthode de recherche rétrospective.À partir des données de 32 000 patients de la base de données clinique MIMIC II, un algorithme d’alerte précoce pour la septicémie appelé InSight a été développé en corrélant neuf mesures courantes des signes vitaux.Les résultats ont montré que l’algorithme avait une sensibilité de 0,90 et une spécificité de 0,81 pour prédire la septicémie 3 heures avant l’apparition du syndrome de réponse inflammatoire systémique soutenu (SIRS), surpassant les méthodes de détection de biomarqueurs existantes. La recherche a été publiée sous le titre « Une approche informatique pour la détection précoce du sepsis ».
Adresse du document :
https://www.sciencedirect.com/science/article/abs/pii/S0010482516301123?via%3Dihub
L’intégration de l’intelligence artificielle et de la médecine de soins intensifs a rendu l’alerte précoce en cas de septicémie plus facile, et cette étude comble sans aucun doute le manque d’alerte rapide lorsque la septicémie se développe jusqu’à un stade critique, et constitue une exploration ayant une plus grande valeur médicale. Bien sûr, ce qui est plus important est la stratégie de fusion mentionnée dans cette étude, qui améliore les performances globales de l’ensemble du modèle en équilibrant les avantages de sensibilité et de spécificité des sous-modèles. Cela ouvre la voie à la résolution de problèmes connexes grâce à l’intégration multi-modèles à l’avenir et inspire davantage de recherches pour résoudre les difficultés pratiques dans les scénarios médicaux grâce à des méthodes similaires.








