Command Palette
Search for a command to run...
Une Équipe De l'Université Purdue Obtient Une Représentation Tactile Efficace Des Données Pour l'apprentissage Des Robots En Simulant La Préhension Réactive Humaine

Le toucher est un élément indispensable du parcours des robots vers l’apprentissage autonome, car il donne aux machines la capacité de percevoir les détails du monde physique. Cependant, la formation des systèmes de perception tactile traditionnels repose souvent sur une collecte massive de données, ce qui est coûteux et inefficace. À mesure que les limites des approches basées sur les données deviennent apparentes,La manière d’améliorer les performances de l’apprentissage tactile grâce à une représentation efficace des données est devenue l’un des axes de recherche actuels en robotique.
Ces dernières années, des technologies innovantes basées sur l’apprentissage auto-supervisé, la représentation clairsemée et la perception intermodale ont émergé rapidement, fournissant de nouvelles idées pour la simplification et l’optimisation de la représentation tactile.

Les avancées dans ce domaine permettront non seulement aux robots de s’adapter rapidement à des tâches complexes avec des données limitées, mais aussi d’améliorer considérablement leur capacité à interagir avec les humains et l’environnement.Dans ce changement révolutionnaire, la technologie de représentation tactile efficace en termes de données ouvre de nouvelles portes à la perception et à l’apprentissage des robots.
Le 18 décembre, lors du quatrième événement de partage en ligne « Newcomers on the Frontier » organisé par la communauté Embodied Touch et co-organisé par HyperAI,Xu Zhengtong, étudiant en troisième année de doctorat à l'Université Purdue, a partagé avec tout le monde les deux principaux résultats de recherche scientifique de LeTac-MPC et UniT et leurs itinéraires techniques de recherche sous le thème « Représentation tactile efficace en termes de données pour l'apprentissage des robots ».
HyperAI a compilé et résumé le partage approfondi du Dr Xu Zhengtong sans violer l'intention initiale.
L'optimisation différenciable est un outil puissant dans l'apprentissage des robots
L’optimisation est un outil très important et efficace dans le domaine de la robotique et a démontré de nombreux excellents résultats dans la planification de trajectoire et l’interaction homme-ordinateur.Avant de discuter de l’optimisation,Tout d’abord, nous devons introduire un concept : l’optimisation différentiable.Pour expliquer ce concept, nous commençons par la formulation générale des problèmes d’optimisation.
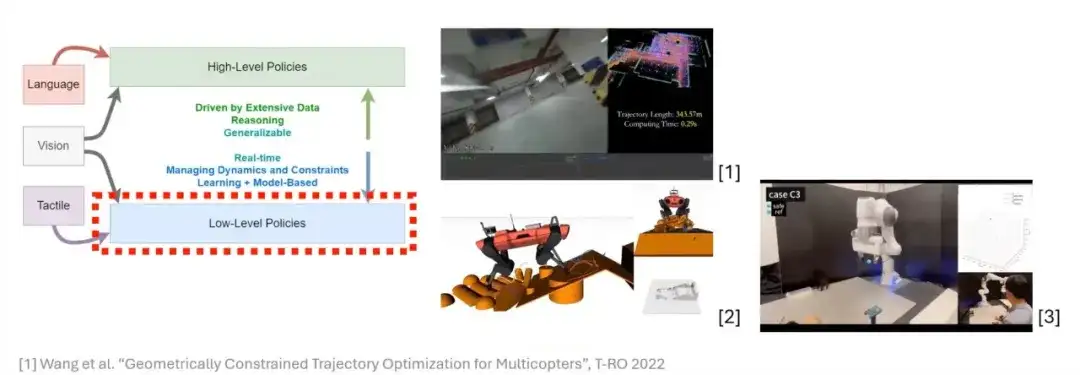
L’idée principale de l’optimisation est de construire une fonction objective (fonction de coût) pour des scénarios d’application spécifiques.Ces fonctions objectives contiennent généralement beaucoup de connaissances préalables et peuvent être soumises à une série de contraintes. Par conséquent, lors de la formulation de problèmes d’optimisation, il est souvent nécessaire d’ajouter ces contraintes à la fonction objectif.
Suivant,Nous nous concentrerons sur une forme d’optimisation de base : la programmation quadratique (QP).C'est l'une des formes les plus simples dans le domaine de l'optimisation et elle offre encore un large éventail de scénarios dans les applications pratiques.

Sur cette base, nous introduisons le concept de « différentiable ». Ce que l'on appelle différentiable signifie que dans un réseau neuronal, la sortie d'une couche peut calculer des dérivées partielles de ses paramètres internes.L’importance de l’introduction de la programmation quadratique différentiable (QP différentiable) est queLorsque nous souhaitons ajouter une couche d’optimisation à un réseau neuronal, nous devons nous assurer que la couche est différentiable. C'est seulement de cette manière que les paramètres de la couche d'optimisation peuvent être naturellement mis à jour et transmis via les informations de gradient pendant la formation et l'inférence du réseau. Par conséquent, si nous pouvons rendre le problème de programmation quadratique différentiable, nous pouvons l’incorporer dans le réseau neuronal et en faire une partie du réseau.
De plus, les problèmes d’optimisation dans l’apprentissage des robots s’appuient souvent sur des connaissances préalables dans des scénarios spécifiques, tels que la conception de fonctions objectives et de contraintes. En formulant un problème d’optimisation différentiable, nous pouvons exploiter pleinement ces connaissances préalables et les intégrer efficacement dans la conception du modèle. Cependant, dans certains cas, nous ne pouvons pas décrire le problème de manière basée sur un modèle (c’est-à-dire que nous ne pouvons pas construire une représentation basée sur un modèle). À cet égard,Vous pouvez essayer d’utiliser des méthodes basées sur les données pour permettre au modèle d’apprendre lui-même les règles de ces parties. C’est l’idée centrale des problèmes d’optimisation différentiables.
En résumé, le problème de programmation quadratique a la propriété d’être différentiable, nous pouvons donc l’introduire comme faisant partie du réseau neuronal.Cette approche fournit non seulement de nouveaux outils pour la conception de réseaux, mais injecte également plus de flexibilité et de possibilités dans la conception de modèles dans l’apprentissage des robots.
LeTac-MPC : Recherche sur les méthodes de préhension réactive et de contrôle de modèles basées sur des signaux tactiles
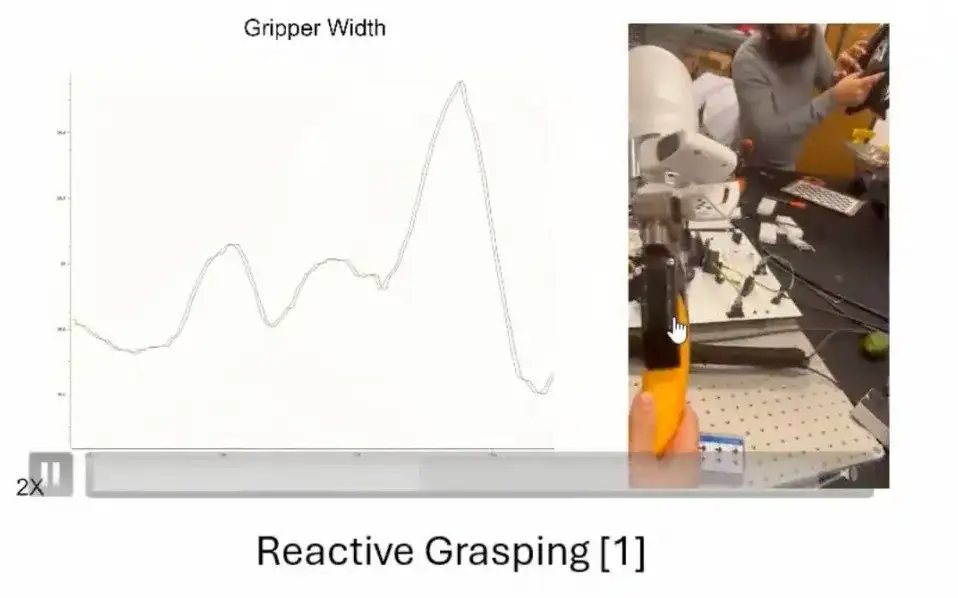
Nous proposons un concept appelé préhension réactive.En observant le processus de saisie des objets par les humains, nous avons constaté que les humains perçoivent généralement les propriétés et les états des objets à travers leurs doigts et ajustent les mouvements de leurs doigts en fonction du retour d'information. Par exemple:
* Lorsque nous saisissons un œuf, nous le percevons comme dur mais fragile, nous utilisons donc une force appropriée pour éviter de l'endommager. À mesure que la pression exercée par les doigts augmente, nous affaiblissons notre prise.
* Lorsque vous saisissez un morceau de pain, comme le pain est mou, le mouvement de vos doigts sera ajusté en conséquence pour éviter qu'il ne soit pressé et déformé.
* Lorsque vous prenez une bouteille de lait, si vous secouez la bouteille, le fait de secouer le lait modifiera l'inertie de l'objet. Les doigts détectent ces changements et ajustent dynamiquement leur action de préhension pour empêcher la bouteille de glisser en raison de l'inertie.

Mise en œuvre d'un robot de préhension réactif
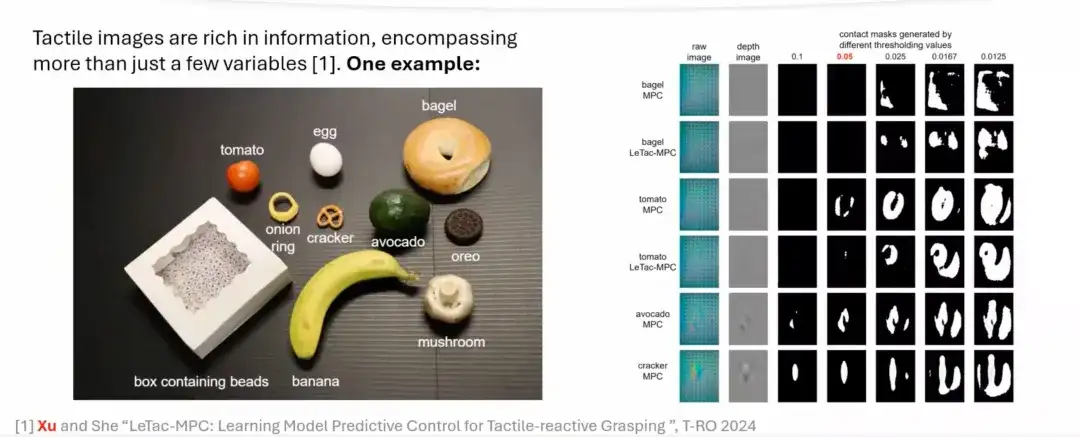
En nous appuyant sur le processus de saisie humain, nous explorons comment simuler ce processus grâce à une approche basée sur un modèle.Grâce à des capteurs tactiles basés sur la vision tels que GelSight,Nous pouvons extraire les caractéristiques clés de l'image d'origine, générer une image de profondeur ou une image de différence grâce à un traitement simple et calculer la zone de contact grâce à une opération de seuillage. La zone de contact peut refléter l’ampleur de la force appliquée. Plus la force est grande, plus la surface de contact est grande ; plus la force est faible, plus la surface de contact est petite.
De plus, en utilisant la technologie de flux optique pour suivre le mouvement des marqueurs, une autre quantité importante peut être obtenue : le déplacement.Cette quantité est liée à la force latérale. En combinant ces signaux, nous pouvons construire une méthode de contrôle basée sur un contrôleur proportionnel-dérivé (PD) pour obtenir une préhension tactile-réactive.
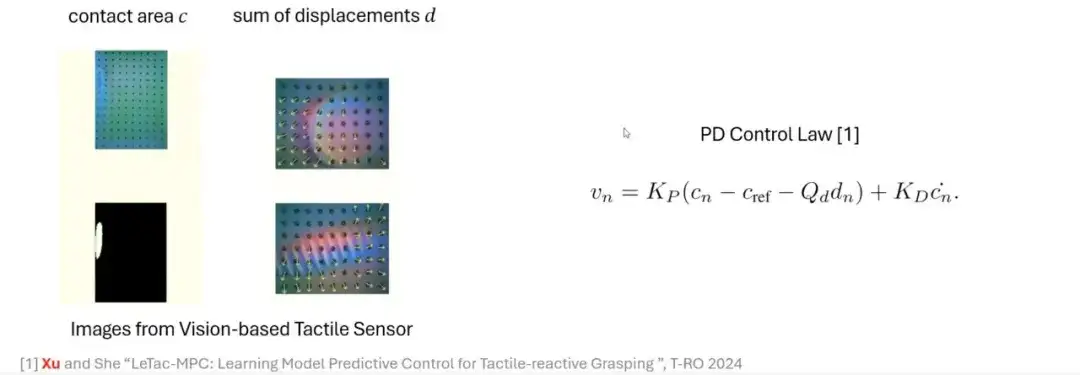
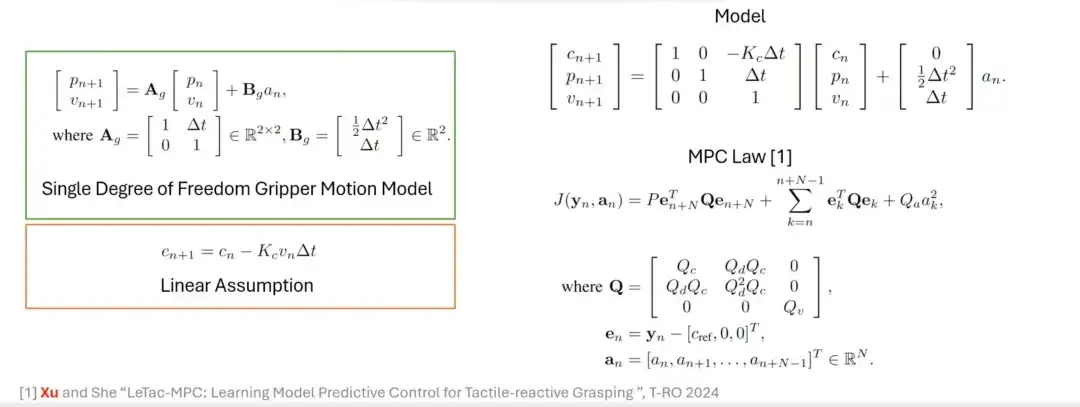
Du contrôleur PD au contrôleur MPC
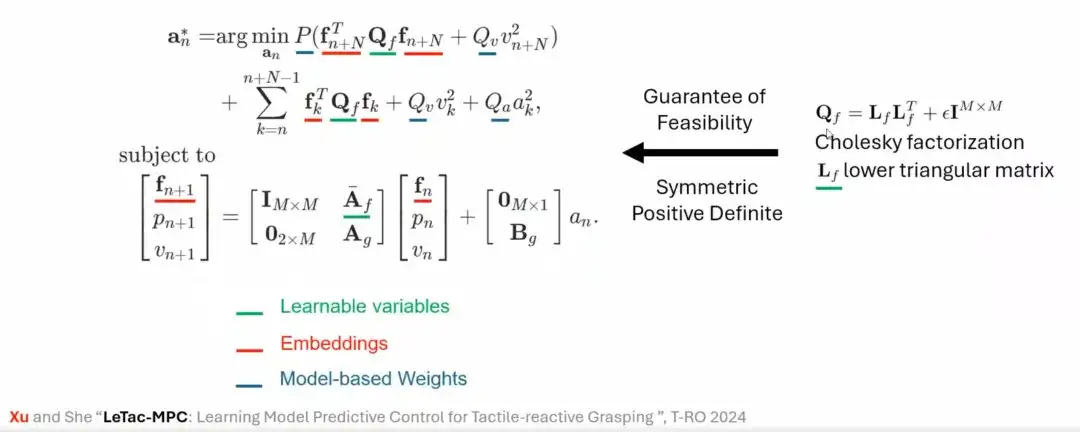
En plus du contrôleur PD, nous avons également conçu une méthode de préhension basée sur un contrôleur prédictif modèle (MPC). L'objectif de contrôle du MPC est similaire à celui du contrôleur PD, mais ses caractéristiques sont basées sur une hypothèse linéaire et un modèle Gripper. Par exemple, l'hypothèse linéaire et le modèle de mouvement de la pince à un seul degré de liberté sont d'abord introduits, puis les deux sont unifiés et modélisés, et enfin la loi de commande basée sur MPC est construite.
Applications et limites des contrôleurs MPC
Le modèle de contrôleur MPC fonctionne bien dans de nombreux scénarios.Je liste ici deux applications.La première application est,Lors du déplacement de la banane, la pince peut ajuster la force en fonction du retour dynamique de la banane pour assurer une préhension stable. Lorsque la force externe est supprimée (comme lorsqu'une personne lâche la banane), le contrôleur convergera progressivement vers un état stable.
Adresse du document :
https://ieeexplore.ieee.org/document/10684081
La deuxième application est le résultat proposé par un autre membre de notre groupe à l'IROS.Autrement dit, une pince à plusieurs degrés de liberté est utilisée pour réaliser des tâches d'opération complexes, et le contrôleur MPC que nous avons proposé est adopté.
Adresse du document :
https://arxiv.org/abs/2408.00610

Cependant, les contrôleurs basés sur des modèles présentent certaines limites et sont difficiles à généraliser à la plupart des objets du quotidien dans la vie réelle.Cela est principalement dû aux hypothèses simplifiées du processus de modélisation, qui ne fonctionnent souvent pas pour certains objets réels. Comme le montre la figure ci-dessous, pour les objets mous ou les objets aux formes complexes, il est difficile d'extraire avec précision la zone de contact en définissant simplement un seuil. Cependant, pour les objets plus durs tels que les avocats et les biscuits, leurs signaux tactiles (images tactiles) sont plus forts, de sorte que la zone de contact peut être extraite avec précision.
Trois avantages majeurs du contrôleur LeTac-MPC
Pour résoudre ce problème, nous utilisons des méthodes mathématiques (telles que la factorisation de Cholesky) pour assurer la solvabilité du problème d'optimisation, stabilisant ainsi le processus de formation du contrôleur, et avons finalement proposé LeTac-MPC.
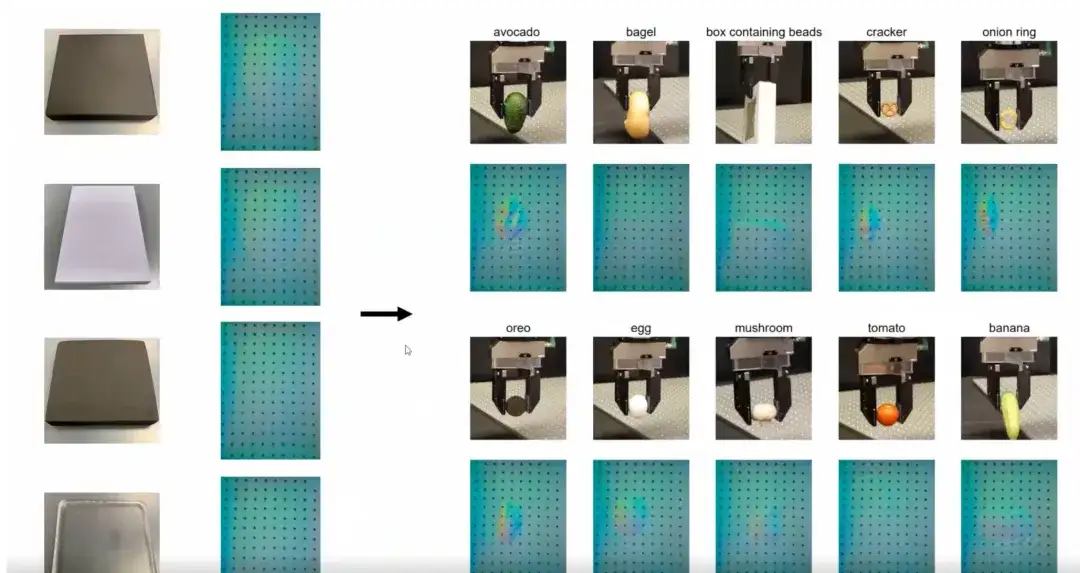
La figure ci-dessous montre les résultats d’entraînement les plus intuitifs. Nous avons été formés sur un ensemble de données contenant seulement 4 objets de dureté différente. Ces objets ont une rigidité différente. Malgré des données de formation limitées, nous formons des contrôleurs qui se généralisent à des objets du quotidien de tailles, de formes, de matériaux et de textures variés.Cette capacité de généralisation basée sur un apprentissage sur de petits échantillons est un avantage majeur du contrôleur.
Deuxièmement, nous entraînons le contrôleur à être robuste aux interférences avec l’objet saisi.La méthode et la force de préhension peuvent être ajustées en temps réel afin que l'objet saisi ne tombe pas en raison d'interférences externes.
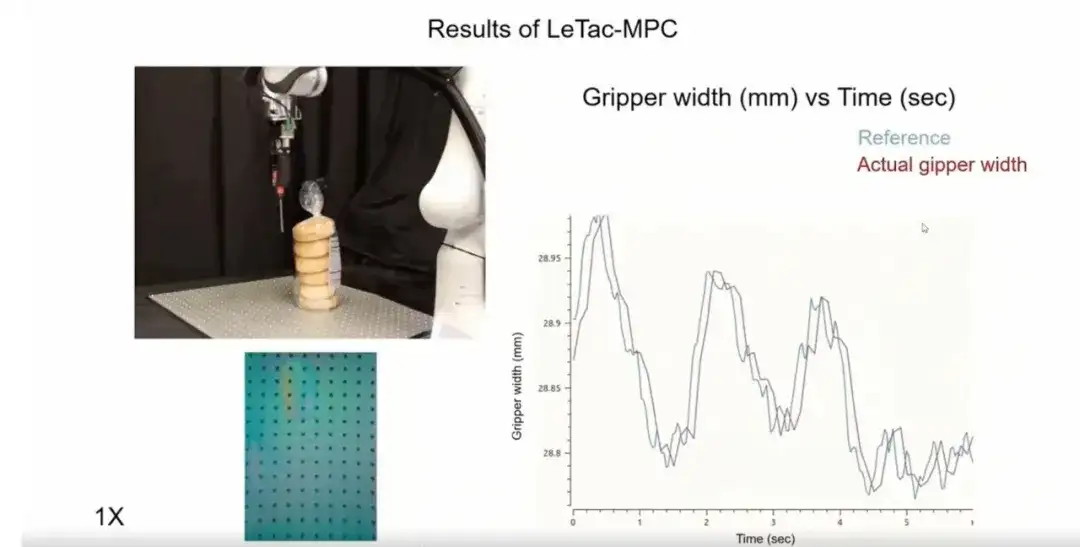
Troisièmement, le contrôleur que nous formons est très réactif.Comme le montre la figure ci-dessous, dans les scénarios avec des mouvements intenses ou des changements d'inertie (comme une boîte remplie de débris), le contrôleur peut réagir rapidement aux changements dynamiques de l'objet.
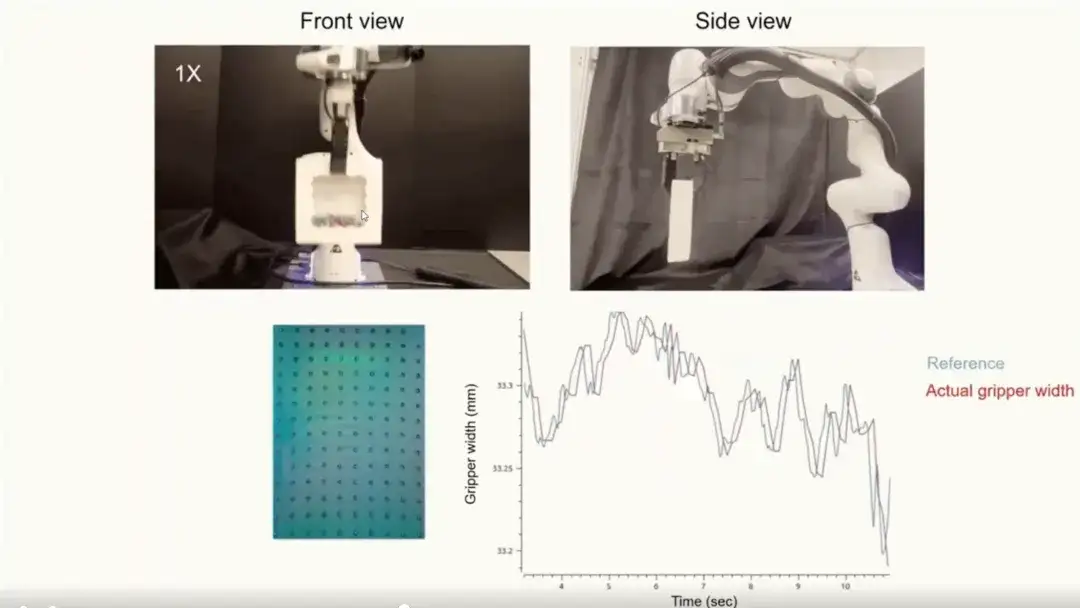
UniT : Représentation tactile unifiée pour l'apprentissage des robots
Dans la recherche ci-dessus, nous avons obtenu la capacité de généralisation du contrôleur. Pouvons-nous apprendre une représentation tactile unifiée à l’aide d’un seul objet simple ?
Comme le montre la figure ci-dessous, un seul objet simple peut être un objet géométriquement simple tel qu'une petite boule ou une clé (comme une clé Allen). Étant donné que les images tactiles de ces objets sont relativement simples, notre méthode est également relativement simple.

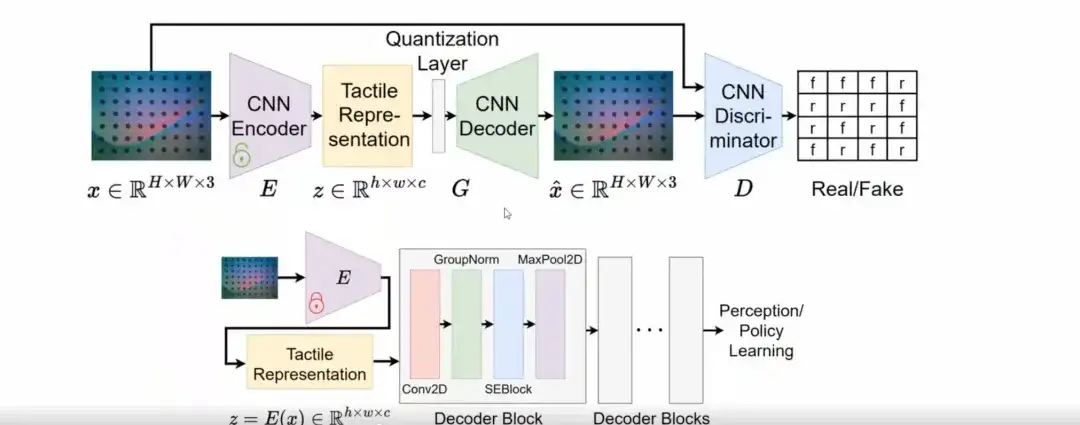
Plus précisément, au lieu de concevoir une structure de réseau complètement nouvelle, nous avons constaté que VQGAN peut apprendre efficacement des représentations tactiles avec des capacités de généralisation.
Dans la phase de formation, nous adoptons le modèle VQGAN pour apprendre les représentations tactiles. Dans la phase d'inférence, l'espace latent de VQGAN est décodé via une simple couche convolutionnelle pour se connecter à des tâches en aval telles que la perception ou l'apprentissage des politiques.
Adresse du document :
https://arxiv.org/abs/2408.06481
Expérience de reconstruction
Pour vérifier l’efficacité de la représentation, nous avons mené des expériences de reconstruction sur Allen Key et Small Ball.
La première est l’expérience de la clé Allen.Comme le montre la figure ci-dessous, bien que les données d'entraînement proviennent uniquement d'Allen Key, nous pouvons toujours reconstruire l'image originale de l'objet invisible via l'espace latent, ce qui montre que l'espace latent contient la plupart des informations utiles de l'image originale. Comparé au MAE, nous constatons qu'il est difficile pour le MAE de reconstruire avec précision l'image d'origine, ce qui indique que le MAE peut subir une perte d'informations pendant le processus de décodage.

La deuxième est l’expérience de la petite balle.Comme le montre la figure ci-dessous, bien que les données d'entraînement proviennent uniquement de Small Ball et que l'effet de reconstruction ne soit pas aussi bon que celui d'Allen Key, le modèle peut toujours reconstruire le signal d'origine d'objets complexes dans une certaine mesure.

De plus, l'espace latent capture non seulement les informations géométriques tactiles (telles que la forme et la configuration du contact), mais contient également implicitement les informations de mouvement des marqueurs. Par exemple, en suivant les marqueurs de l’image originale et de l’image reconstruite, nous avons constaté que leurs performances en matière de suivi des marqueurs sont très similaires.

Tâches et repères en aval
Nous avons testé les capacités de représentation de la méthode UniT sur plusieurs benchmarks, notamment l'estimation de pose 6D, l'estimation de pose 3D et les benchmarks de classification.
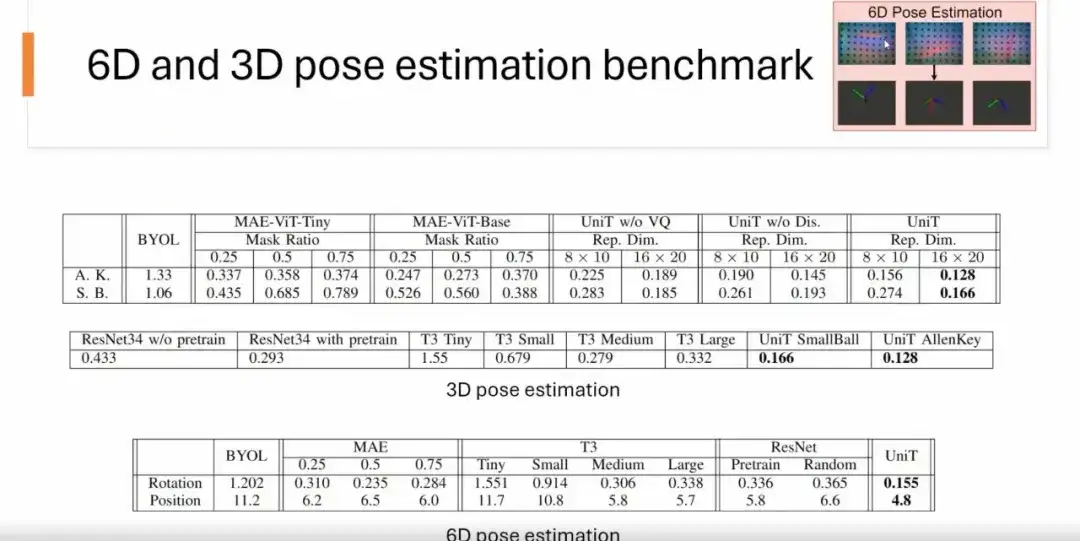
Pour l'estimation de la pose 6D,Nous entrons une image brute tactile (comme une image tactile d'une prise USB) pour prédire sa position et sa rotation. Les résultats montrent que par rapport aux méthodes MAE, BYOL, ResNet et T3, le modèle UniT surpasse les autres méthodes en termes de précision.
Pour l'estimation de la pose 3D,Nous prédisons uniquement la pose rotationnelle de l'objet. Comme le montre la figure ci-dessous, UniT fonctionne mieux que les autres méthodes.
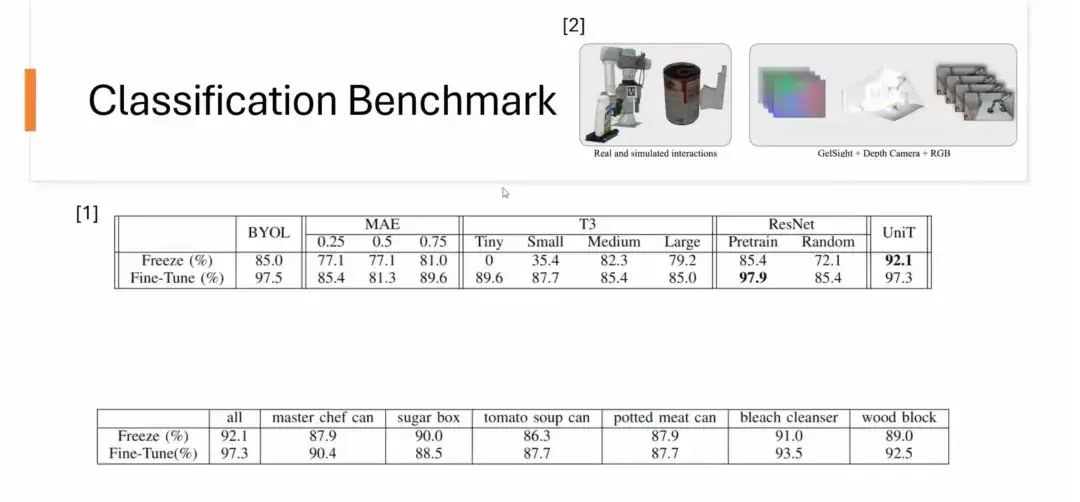
Deuxièmement, nous avons également réalisé un benchmark de classification.L'ensemble de données provient de YCBSight-Sim de CMU. Bien que l'ensemble de données soit petit, UniT montre de bonnes performances dans les tâches de classification. En particulier, après avoir appris la représentation tactile sur un seul objet, elle peut naturellement se généraliser aux tâches de classification d'autres objets invisibles. Par exemple, une représentation formée uniquement sur Master Chef peut être appliquée avec succès à la classification de 6 objets différents avec d'excellents résultats. Certaines représentations formées sur un seul objet surpassent même celles formées sur un grand nombre d’objets.
Expérience d'apprentissage stratégique
Nous avons également appliqué la représentation tactile aux expériences d’apprentissage des politiques.Vérifier ses performances sur des tâches complexes. L'expérience a utilisé les données Allen Key pour la formation et a évalué les trois tâches suivantes :
* Insertion de clé Allen (voir à gauche) : Tâche d'insertion de précision, nécessitant une précision extrêmement élevée.
* Préhension de copeaux (voir photo) : réalisation de tâches délicates de préhension d'objets fragiles.
Cuisses de poulet suspendues (voir à droite) : une tâche à deux bras impliquant une préhension et un contrôle dynamiques à long terme.

Nous avons comparé trois méthodes différentes :Les trois méthodes sont : Vision-Only (s'appuyant uniquement sur des signaux visuels), Visuo-Tactile à partir de zéro (entraînement conjoint de la vision et du toucher) et Visuo-Tactile avec UniT (utilisant des représentations tactiles extraites par UniT pour l'apprentissage de stratégies). Comme le montre la figure ci-dessous, la méthode d’apprentissage des politiques utilisant la représentation UniT est la plus performante dans toutes les tâches.

À l’avenir, HyperAI aidera également la communauté tactile incarnée à continuer d’organiser des activités de partage en ligne, en invitant des experts et des universitaires nationaux et étrangers à partager des résultats et des idées de pointe. Restez à l'écoute!








