Command Palette
Search for a command to run...
Ensemble De Données Vocales WenetSpeech-Chuan Sichuan-Chongqing
Date
Organisation
URL du document
Licence
Apache 2.0
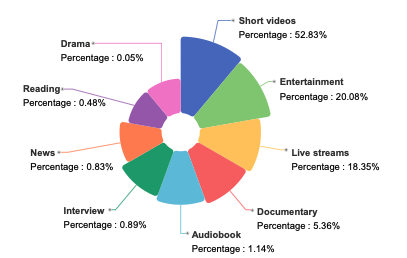
WenetSpeech-Chuan est un ensemble de données vocales à grande échelle en dialecte Sichuan-Chongqing, publié en 2025 par l'Université polytechnique du Nord-Ouest en collaboration avec Hillbeak, l'Institut de recherche en intelligence artificielle de China Telecom et d'autres institutions. L'article de recherche associé s'intitule « WenetSpeech-Chuan : un corpus sichuanais à grande échelle avec une annotation riche pour le traitement de la parole dialectale". Cet ensemble de données contient 10 013 heures d'enregistrements authentiques de dialectes du Sichuan et de Chongqing, dont 3 714 heures de données fortement annotées et 6 299 heures de données faiblement annotées. Les données couvrent neuf scénarios réels : 52 831 heures sont constituées de courtes vidéos, le reste comprenant des contenus de divertissement, des diffusions en direct, des livres audio, des documentaires, des interviews, des actualités, des lectures et des séries télévisées, offrant ainsi une distribution vocale très diversifiée et réaliste. Chaque enregistrement est accompagné d'annotations détaillées, incluant le contenu textuel, le niveau de confiance, la qualité vocale, le sexe et l'âge du locuteur, ainsi que des étiquettes émotionnelles.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.