Command Palette
Search for a command to run...
Ensemble De Données De Référence Pour La Collecte d'informations WideSearch
Date
Organisation
URL du document
Licence
Other
*Cet ensemble de données prend en charge l'utilisation en ligne.Cliquez ici pour sauter.
WideSearch est le premier ensemble de données de référence d'évaluation d'agent conçu pour la « recherche d'informations large » publié par l'équipe Seed de ByteDance en 2025. Les résultats de l'article associé sont «WideSearch : analyse comparative de la recherche d'informations à grande échelle", qui vise à évaluer et à promouvoir systématiquement la fiabilité et l'intégrité des grands modèles linguistiques dans la collecte de faits à grande échelle, la synthèse et la production structurée vérifiable. Le benchmark se compose de 200 questions de haute qualité (100 en anglais et 100 en chinois), soigneusement sélectionnées et nettoyées manuellement par l'équipe de recherche à partir de requêtes réelles d'utilisateurs. Ces questions proviennent de plus de 15 domaines différents.
Champs de données:
- instance_id : ID unique de la tâche (correspondant au nom du fichier CSV doré).
- requête : une instruction en langage naturel, spécifiant généralement les noms de colonnes requis et les exigences de sortie de la table Markdown.
- évaluation : un objet sérialisé (chaîne) utilisé pour l'évaluation automatique, contenant :
- unique_columns : colonnes de clé primaire (pour l’alignement des lignes) ;
- obligatoire : nom de la colonne qui doit apparaître ;
- eval_pipeline : configuration d'évaluation au niveau de la colonne (comme le prétraitement, la métrique, le critère).
- langue : Langue de la tâche, la valeur peut être en ou zh.
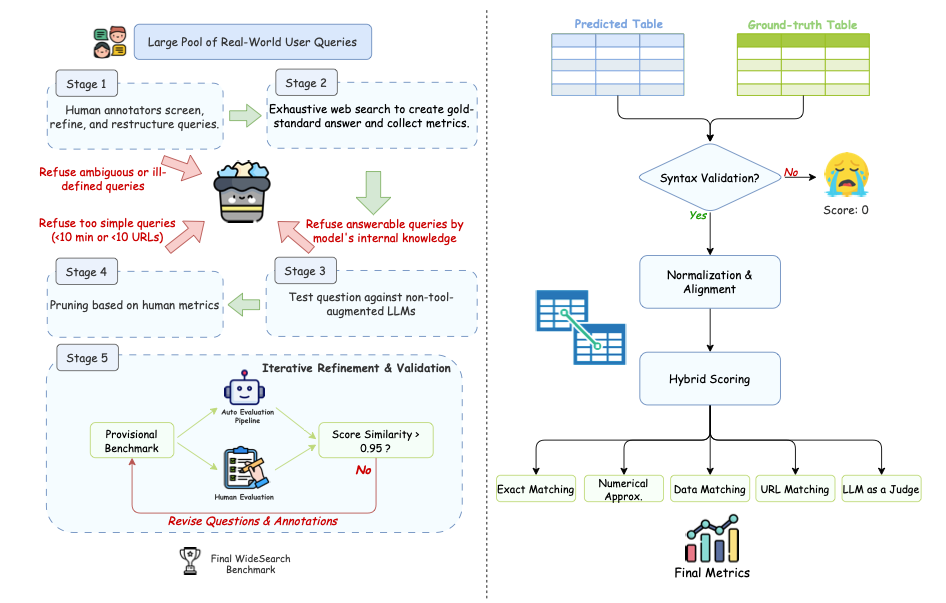
Diagramme de flux de construction et d'évaluation automatique des données
Citation
@misc{wong2025widesearchbenchmarkingagenticbroad,
title={WideSearch: Benchmarking Agentic Broad Info-Seeking},
author={Ryan Wong and Jiawei Wang and Junjie Zhao and Li Chen and Yan Gao and Long Zhang and Xuan Zhou and Zuo Wang and Kai Xiang and Ge Zhang and Wenhao Huang and Yang Wang and Ke Wang},
year={2025},
eprint={2508.07999},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.07999},
}
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.