Command Palette
Search for a command to run...
Ensemble De Données De Reconnaissance De Texte CC-OCR
Date
Taille
Organisation
URL de publication
URL du document
Balises
L'ensemble de données CC-OCR a été développé conjointement par Alibaba Group, l'Université des sciences et technologies de Huazhong et l'Université de technologie de Chine du Sud en 2024 pour fournir une référence complète et stimulante pour évaluer les performances de grands modèles multimodaux dans les tâches de reconnaissance de texte (OCR).CC-OCR : une référence OCR complète et exigeante pour l'évaluation de grands modèles multimodaux en alphabétisation".
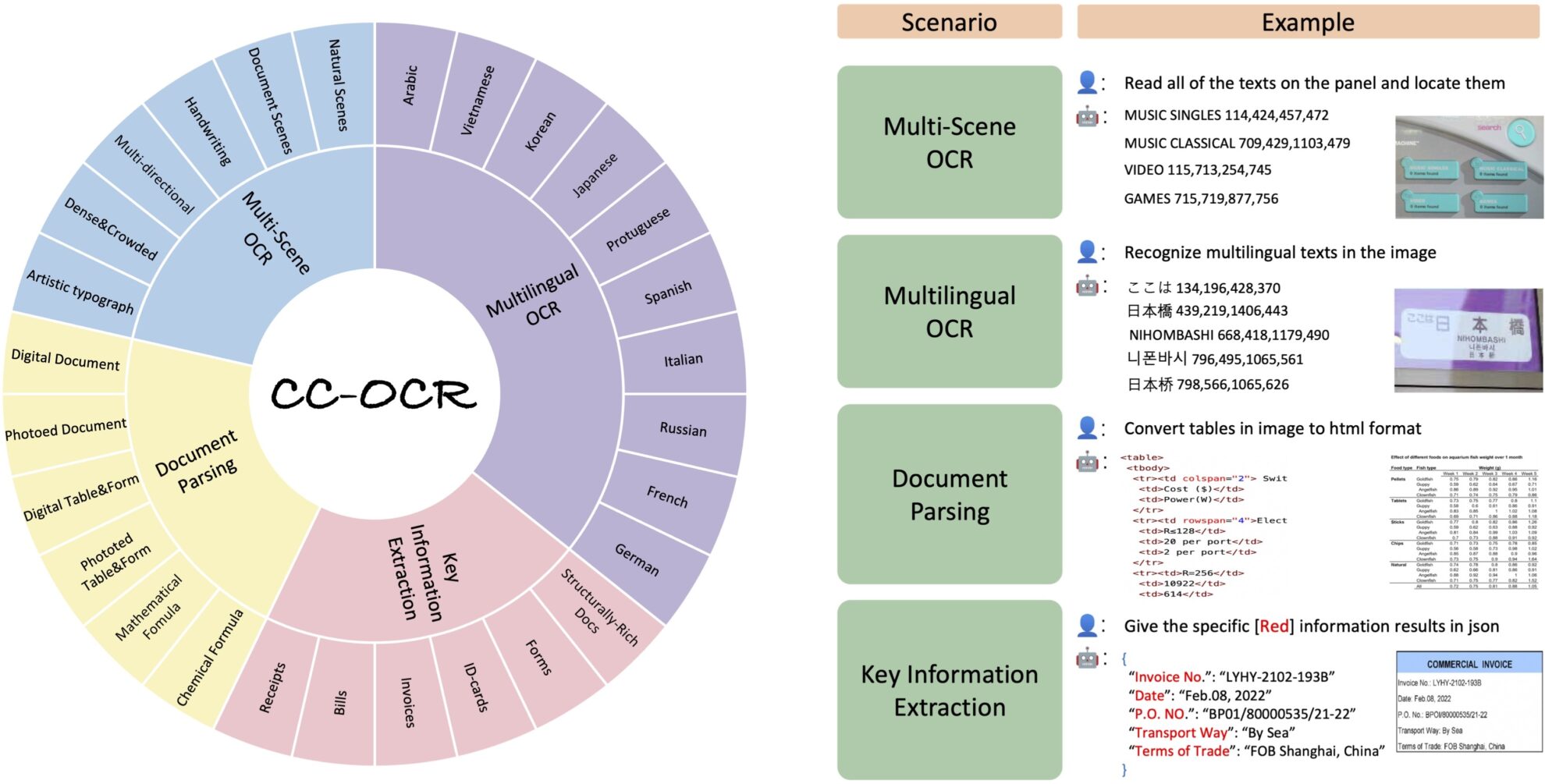
L'ensemble de données couvre quatre tâches principales : la lecture de texte multi-scènes, la lecture de texte multilingue, l'analyse de documents et l'extraction d'informations clés, et contient 39 sous-ensembles et 7 058 images entièrement annotées. Le lancement de CC-OCR comble le vide dans l’évaluation des modèles multimodaux actuels dans les structures complexes et les défis visuels à granularité fine, et est d’une grande importance pour promouvoir les progrès des modèles multimodaux dans les applications pratiques.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.