LTX-Video's ltxv-13b-0.9.7-distilled version is the latest distillation model released by Lightricks on May 14, 2025. This model employs transformer and Video-VAE technology to efficiently generate high-resolution videos. On an Nvidia H100 GPU, it generated a 5-second 24fps video at a resolution of 768×512 in just 2 seconds, outperforming all existing models of similar scale. Furthermore, LTX-Video supports various video generation methods, including text-to-video, image-to-video, extended video, and video generation with multiple conditions. Related paper results are... LTX-Video: Realtime Video Latent Diffusion .
This tutorial uses a single A6000 computing resource and provides two examples of text-to-video and image-to-video generation for testing.
2. Effect display
Text to Video:
Image to Video:
3. Operation steps
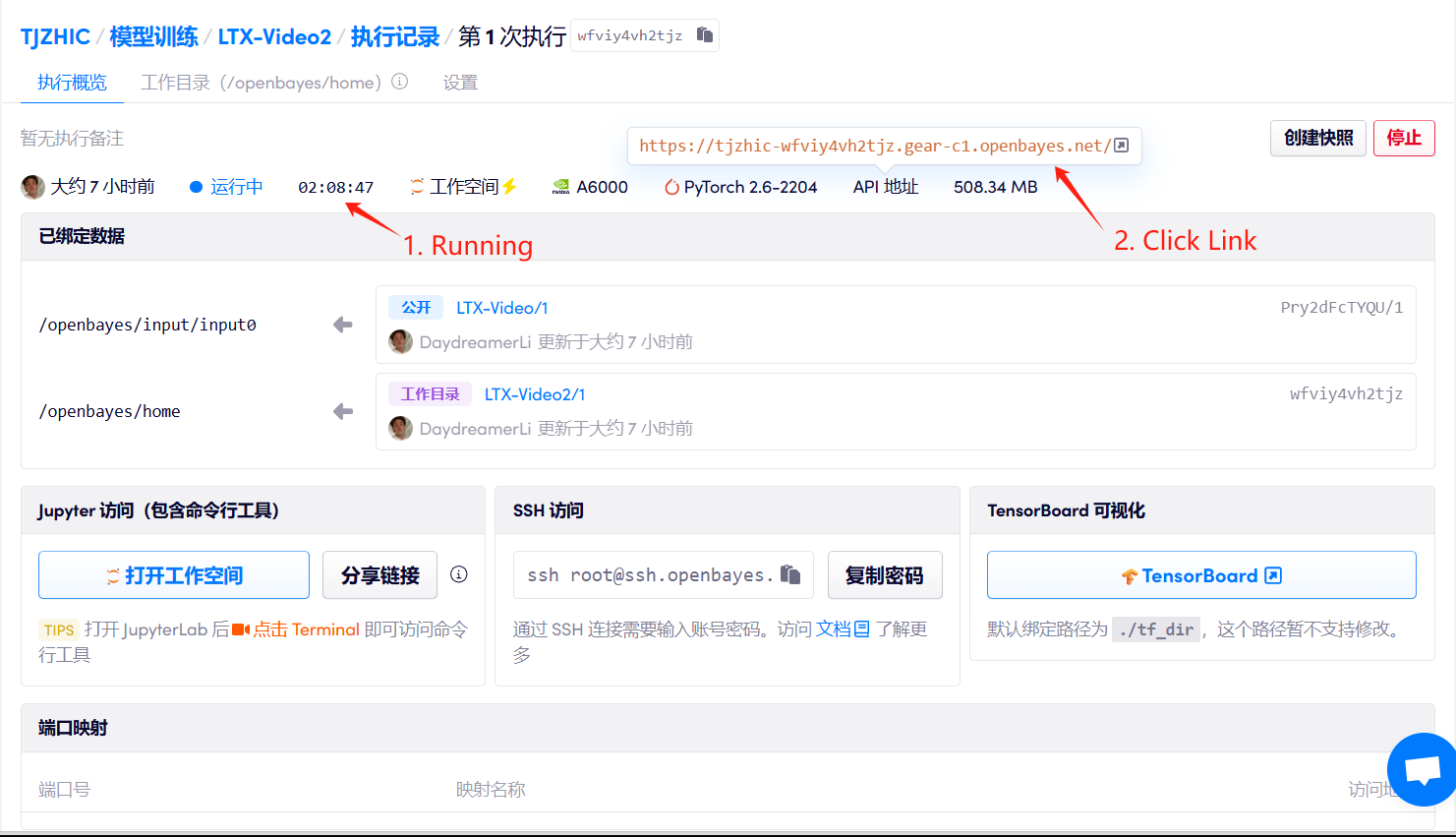
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2. Usage Examples
Prompt supports English only.
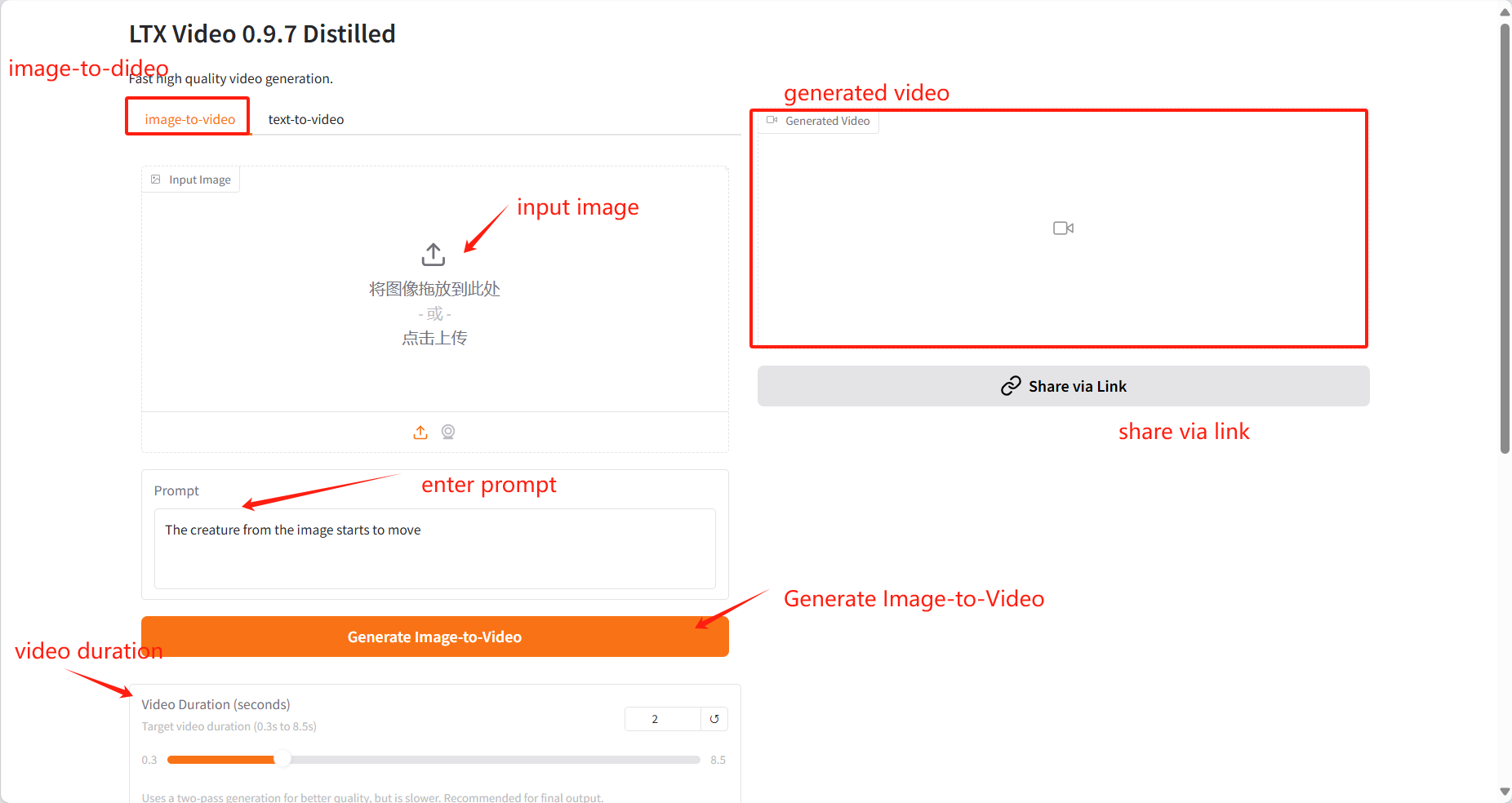
1. Image-to-video
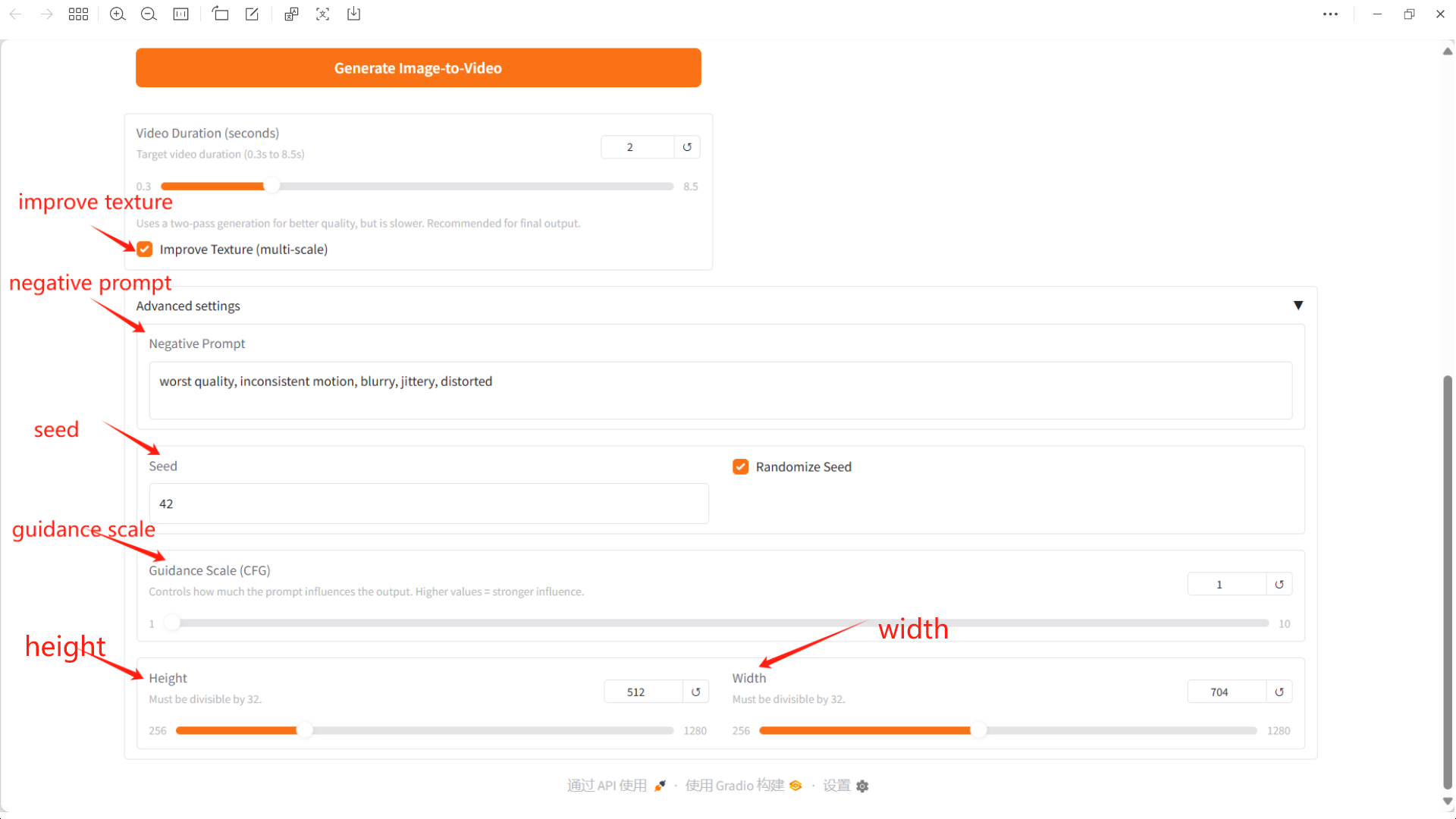
Specific parameters:
Upload Image: Here you can upload an image as the starting point for video generation.
Prompt: You can enter text to describe the video content here, and the model will generate a video based on this text.
Video Duration: Select the length of the generated video.
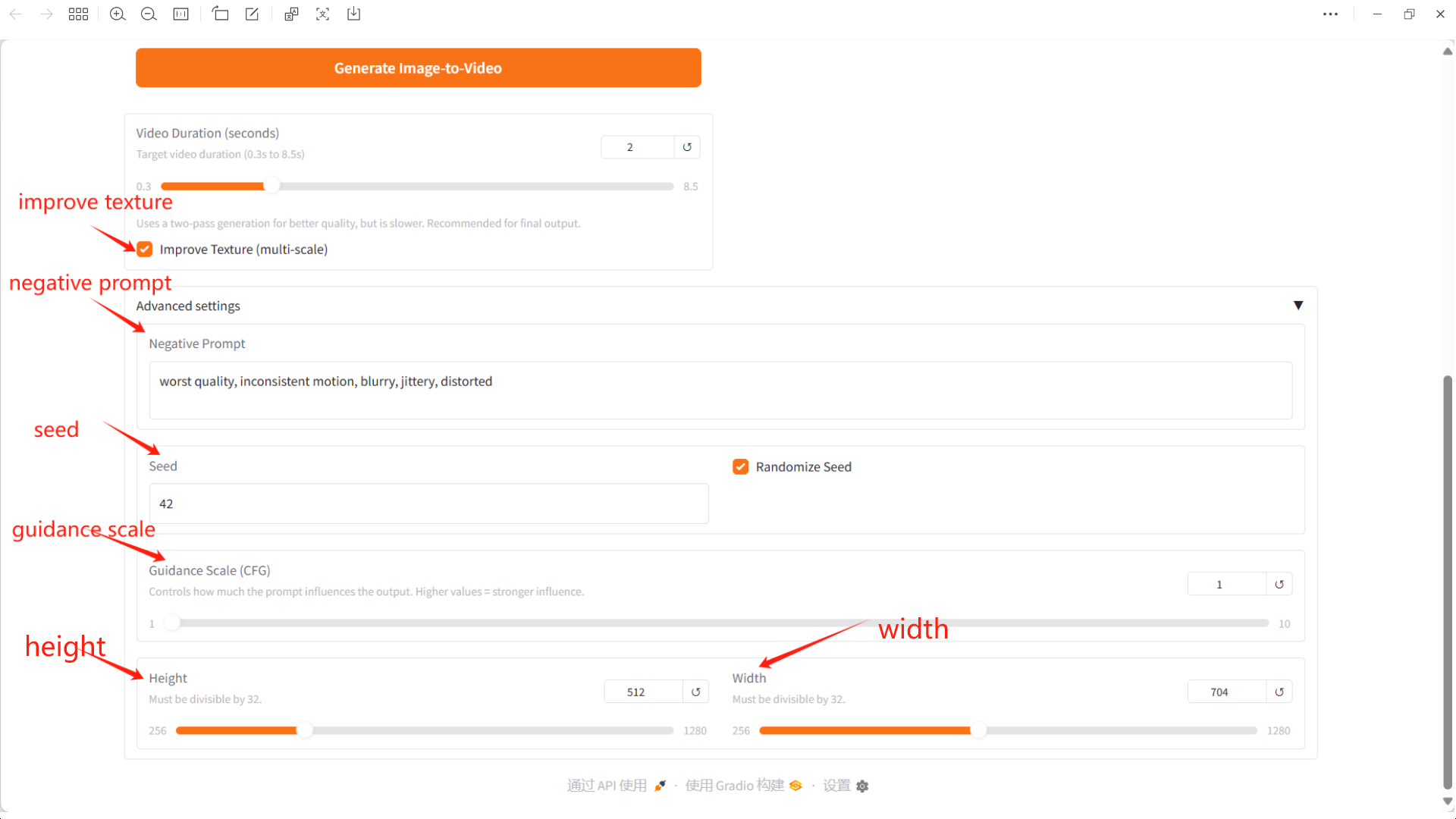
Negative Prompt: Here you can enter elements or features that you don't want to appear in the video, which helps avoid generating unwanted effects.
Seed: This number determines the randomness of video generation.
Guidance Scale (CFG): Controls how much influence the prompt has on the output. Higher values have a greater impact.
Height: height, must be divisible by 32.
Width: width, must be divisible by 32.
result
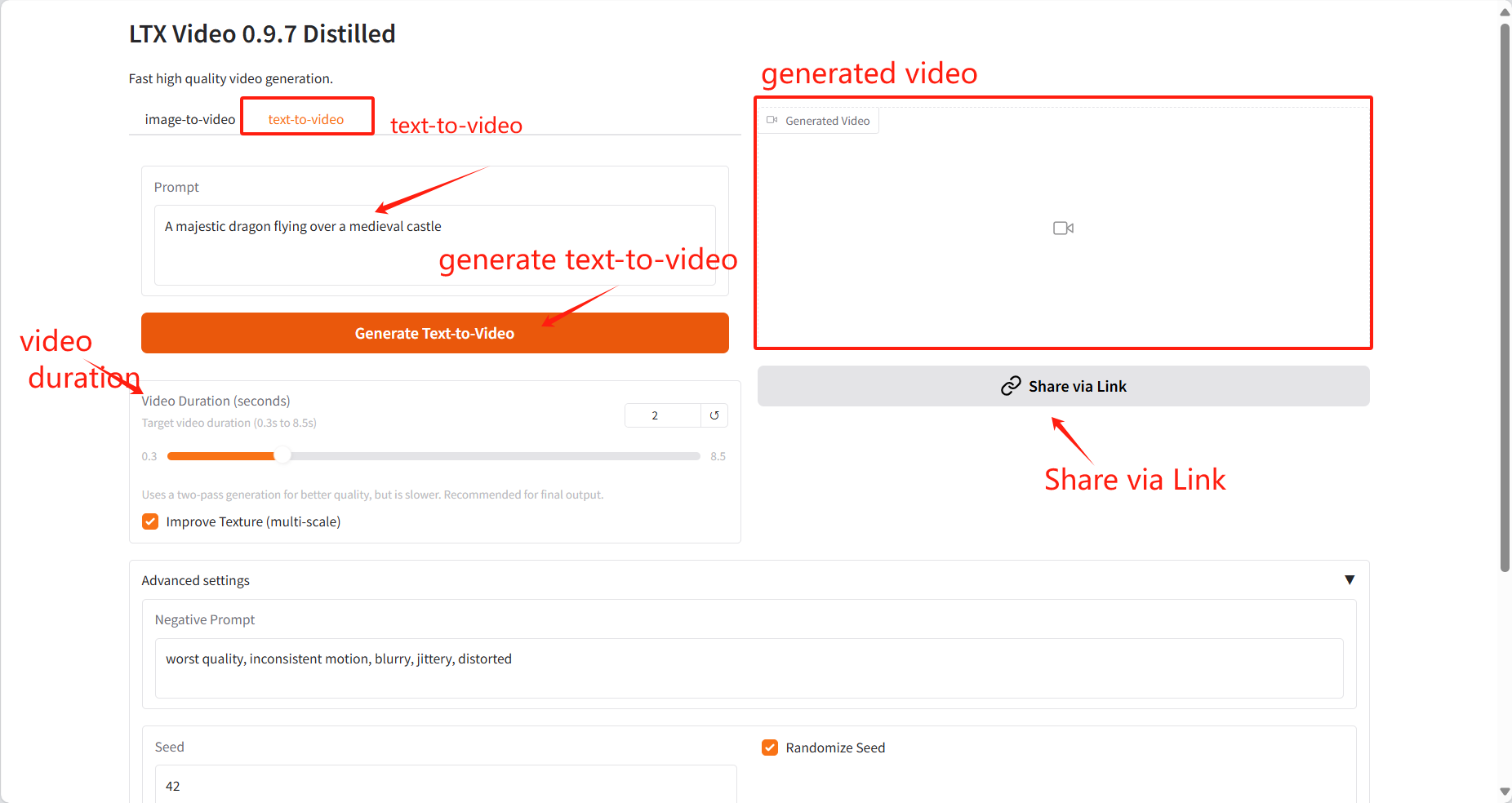
2. Text-to-video
Specific parameters:
Prompt: You can enter text to describe the video content here, and the model will generate a video based on this text.
Video Duration: Select the length of the generated video.
Negative Prompt: Here you can enter elements or features that you don't want to appear in the video, which helps avoid generating unwanted effects.
Seed: This number determines the randomness of video generation.
Guidance Scale (CFG): Controls how much influence the prompt has on the output. Higher values have a greater impact.
Height: height, must be divisible by 32.
Width: width, must be divisible by 32.
Result Output
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{HaCohen2024LTXVideo,
title={LTX-Video: Realtime Video Latent Diffusion},
author={HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir},
journal={arXiv preprint arXiv:2501.00103},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
LTX-Video's ltxv-13b-0.9.7-distilled version is the latest distillation model released by Lightricks on May 14, 2025. This model employs transformer and Video-VAE technology to efficiently generate high-resolution videos. On an Nvidia H100 GPU, it generated a 5-second 24fps video at a resolution of 768×512 in just 2 seconds, outperforming all existing models of similar scale. Furthermore, LTX-Video supports various video generation methods, including text-to-video, image-to-video, extended video, and video generation with multiple conditions. Related paper results are... LTX-Video: Realtime Video Latent Diffusion .
This tutorial uses a single A6000 computing resource and provides two examples of text-to-video and image-to-video generation for testing.
2. Effect display
Text to Video:
Image to Video:
3. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
2. Usage Examples
Prompt supports English only.
1. Image-to-video
Specific parameters:
Upload Image: Here you can upload an image as the starting point for video generation.
Prompt: You can enter text to describe the video content here, and the model will generate a video based on this text.
Video Duration: Select the length of the generated video.
Negative Prompt: Here you can enter elements or features that you don't want to appear in the video, which helps avoid generating unwanted effects.
Seed: This number determines the randomness of video generation.
Guidance Scale (CFG): Controls how much influence the prompt has on the output. Higher values have a greater impact.
Height: height, must be divisible by 32.
Width: width, must be divisible by 32.
result
2. Text-to-video
Specific parameters:
Prompt: You can enter text to describe the video content here, and the model will generate a video based on this text.
Video Duration: Select the length of the generated video.
Negative Prompt: Here you can enter elements or features that you don't want to appear in the video, which helps avoid generating unwanted effects.
Seed: This number determines the randomness of video generation.
Guidance Scale (CFG): Controls how much influence the prompt has on the output. Higher values have a greater impact.
Height: height, must be divisible by 32.
Width: width, must be divisible by 32.
Result Output
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Citation Information
The citation information for this project is as follows:
@article{HaCohen2024LTXVideo,
title={LTX-Video: Realtime Video Latent Diffusion},
author={HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir},
journal={arXiv preprint arXiv:2501.00103},
year={2024}
}
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.