Command Palette
Search for a command to run...
Depth-Anything-3: Restoring Visual Space From Any Perspective
Date
Organization
Paper URL
License
Apache 2.0
1. Tutorial Introduction

Depth-Anything-3 (DA3) is a groundbreaking visual geometry model released by the ByteDance-Seed team in November 2025. The related research paper is as follows: Depth Anything 3: Recovering the Visual Space from Any Views .
This model revolutionizes visual geometry tasks with its "minimalist modeling" concept: it uses only a single, ordinary Transformer (such as the vanilla DINO encoder) as the backbone network, replacing complex multi-task learning with "depth ray representation," enabling it to predict spatially consistent geometric structures from any visual input (both known and unknown camera poses). Its performance significantly surpasses previous models like DA2 (monocular depth estimation) and similar solutions like VGGT (multi-view depth/pose estimation). All models are trained on publicly available academic datasets, balancing accuracy and reproducibility.
Core features:
- Multi-task integration: A single model supports tasks such as monocular depth estimation, multi-view depth fusion, camera pose estimation, and 3D Gaussian generation.
- High-precision output: Achieved monocular depth accuracy of 94.6% on the HiRoom dataset; ETH3D reconstruction accuracy surpasses models such as VGGT.
- Multi-model adaptation: Provides Main (all-rounder), Metric (depth measurement), Monocular (monocular only), and Nested (nested fusion) series models.
- Flexible export: Supports formats such as GLB, NPZ, PLY, and 3DGS video, seamlessly integrating with downstream 3D tools (such as Blender).
This tutorial uses Grado to deploy the DA3 core model, with "RTX_5090" computing resources, which can fully run heavy tasks such as 3D Gaussian generation (high resolution) and multi-view 3D reconstruction without any video memory/memory bottlenecks.
2. Effect display
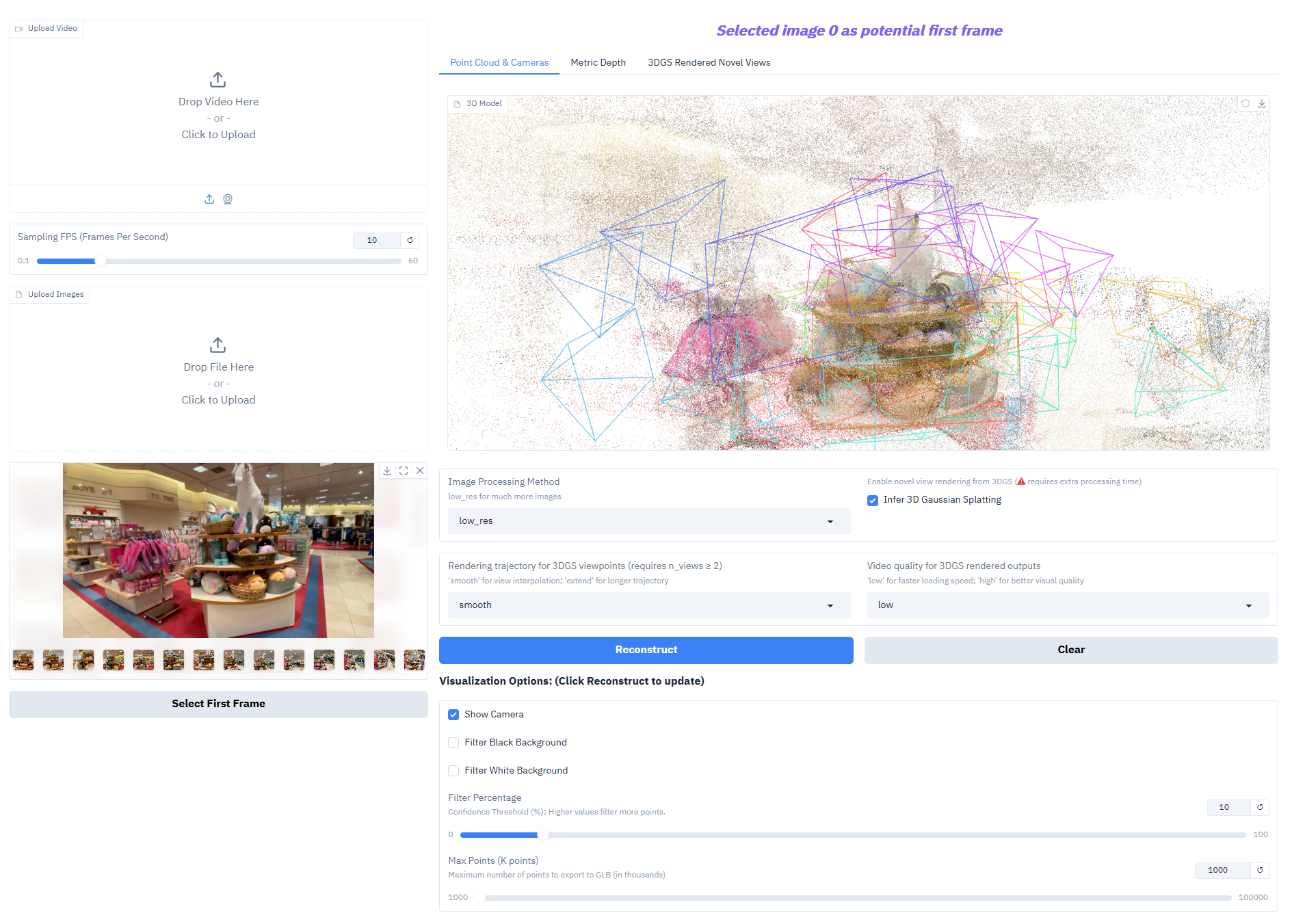
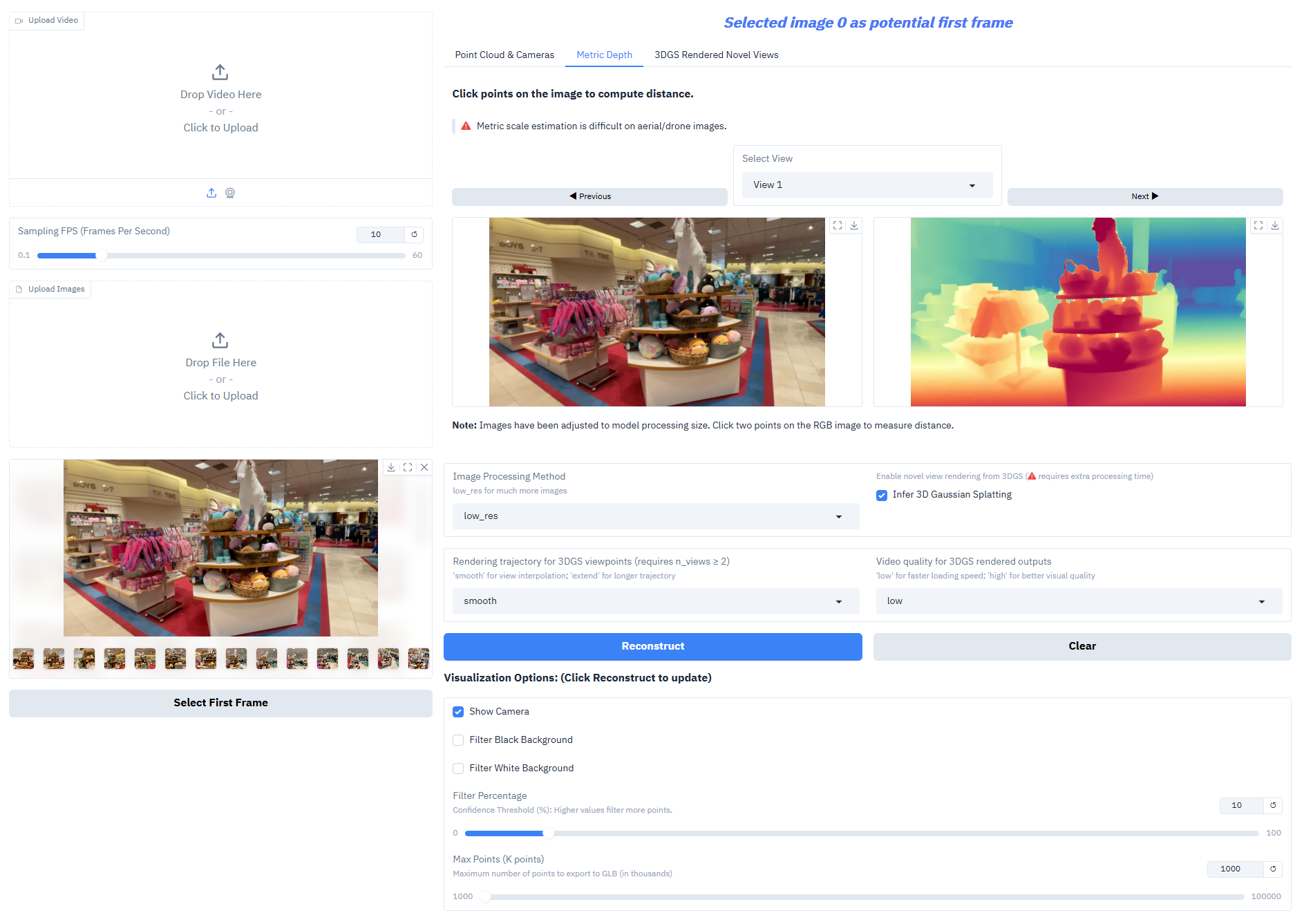
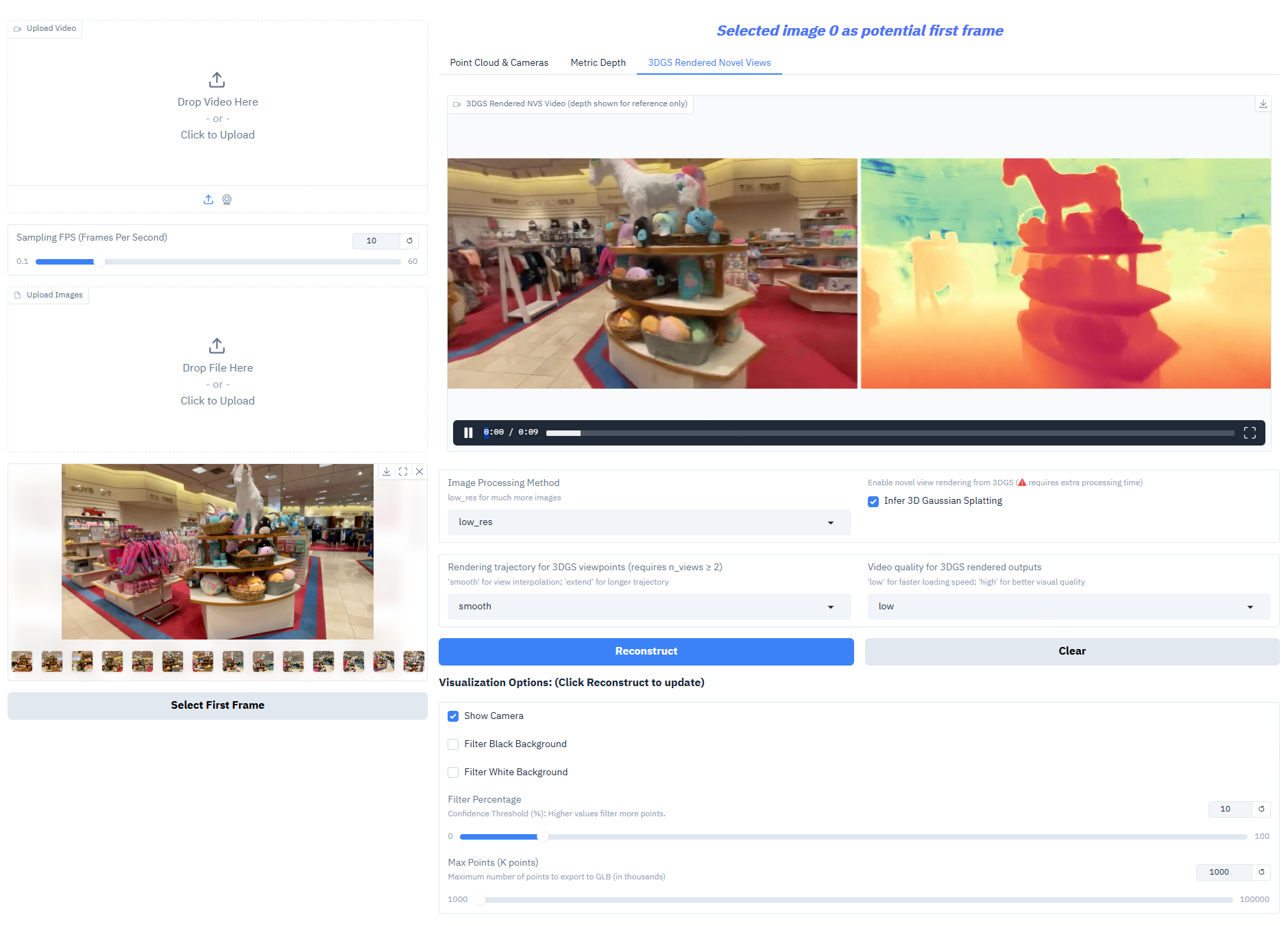
Depth-Anything-3 performs exceptionally well on core tasks:
- Monocular depth estimation: Generating high-precision depth maps from a single RGB image to reconstruct scene spatial hierarchy.
- Multi-view depth fusion: Generates a consistent depth field based on multiple images of the same scene, supporting high-quality 3D reconstruction.
- Camera pose estimation: Accurately predict camera intrinsic and extrinsic parameters (extrinsic parameters [N,3,4], intrinsic parameters [N,3,3]), adapting to multi-view collaborative tasks.
- 3D Gaussian Generation: Directly outputs high-fidelity 3D Gaussian models, supporting novel view composition (frame rate ≥ 30 fps).
- Depth Measurement Output: Nested series models can generate realistic-scale depth, meeting the needs of surveying, interior design, and other scenarios.
3. Operation steps
1. Start the container
After starting the container, click the API address to enter the Web interface
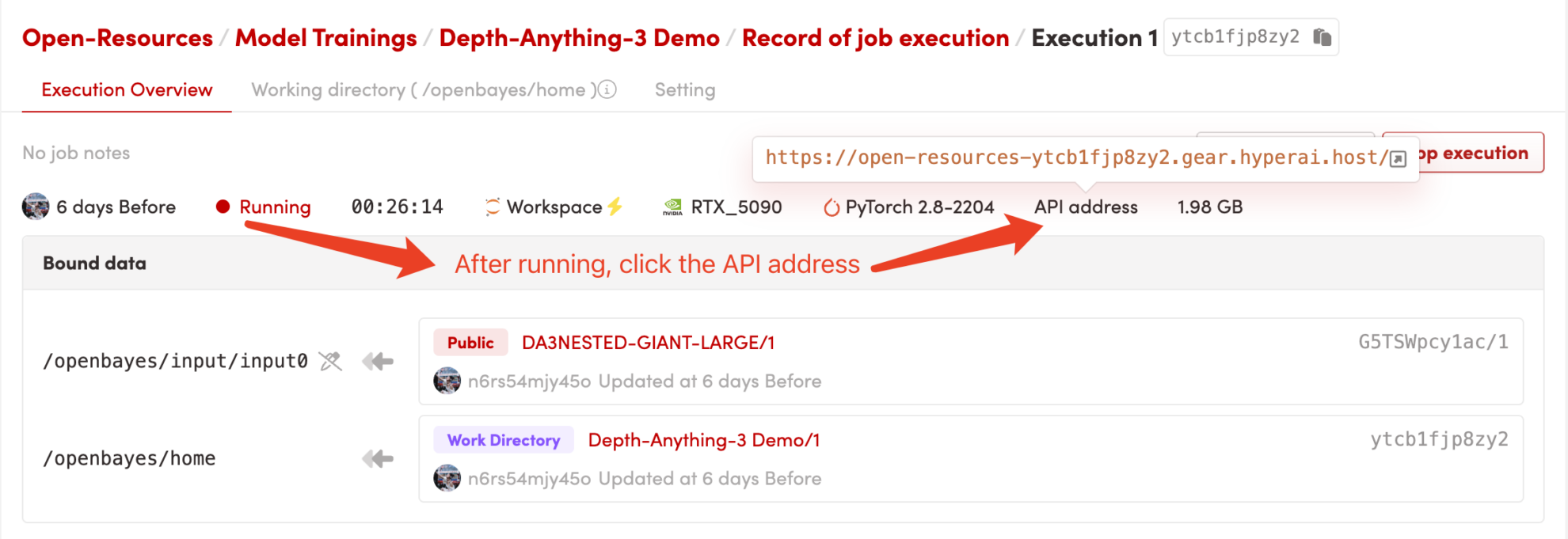
2. Getting Started
If "Bad Gateway" is displayed, it means that the model is being initialized. Since the model is large, please wait 2-3 minutes and refresh the page.
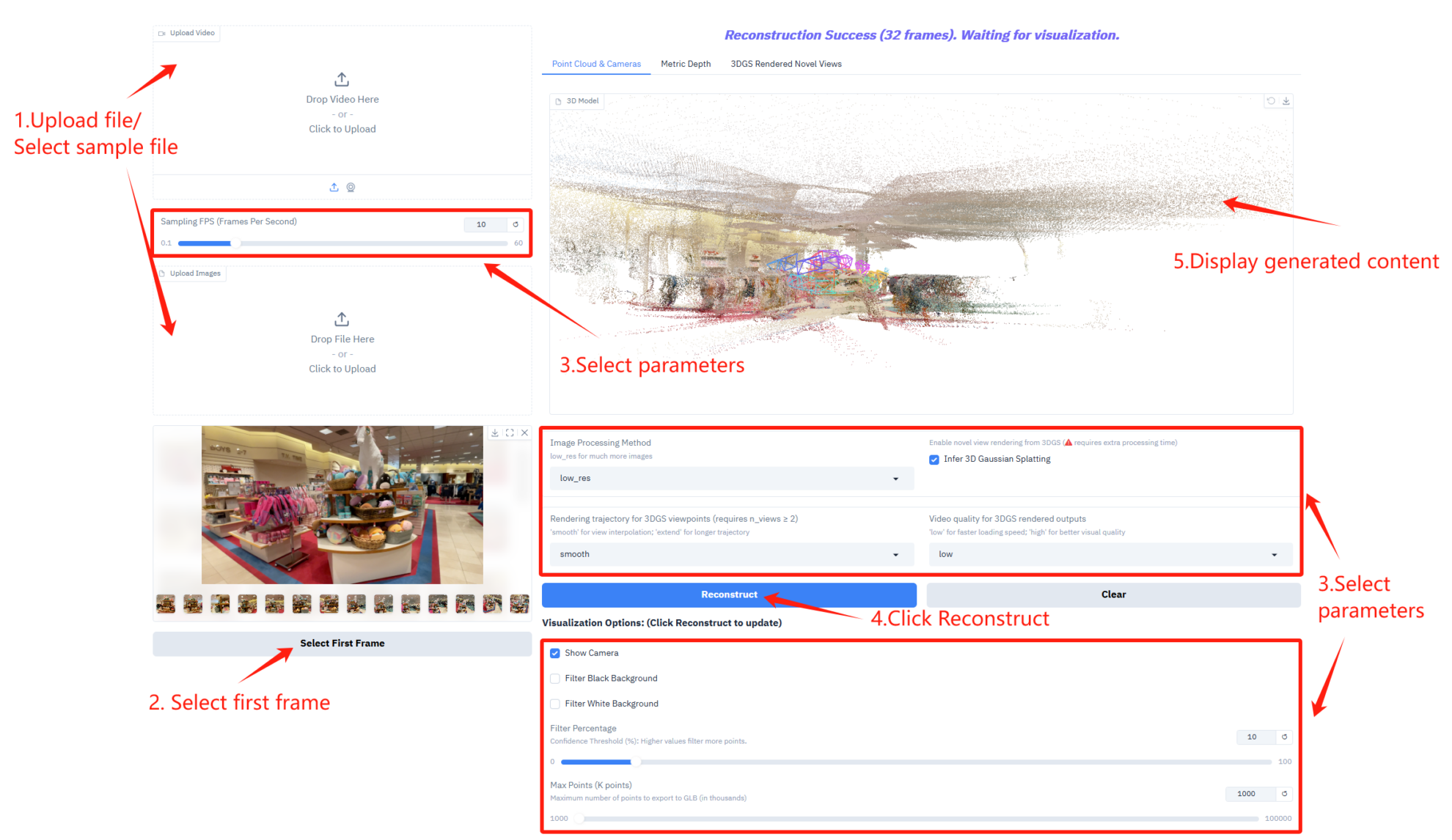
Parameter Description
- Sampling frame rate settings
- Sampling FPS (Frames Per Second): Controls the number of frames per second used for video sampling.
- Image Processing and 3D Inference Setup
- Image Processing Method: Select the image processing mode to accommodate a larger number of images.
- Infer 3D Gaussian Splatting: Enabling 3D Gaussian sputtering inference requires additional processing time to generate 3D models.
- Rendering trajectory and video quality settings
- Rendering trajectory for 3DGS viewpoints: Select the type of rendering trajectory for the 3DGS viewpoint.
- Video quality for 3DGS rendered outputs: Controls the video quality of 3DGS rendered outputs.
- Visualization options
- Show Camera: Displays the camera trajectory in a 3D view.
- Filter Black Background: Filters out the black background area in the point cloud.
- Filter White Background: Filters out white background areas in the point cloud.
- Filter Percentage: Controls the filtering intensity of the point cloud.
- Max Points (K points): Sets the maximum number of points for exporting a 3D model in GLB format.
Citation Information
The citation information for this project is as follows:
@article{depthanything3,
title={Depth Anything 3: Recovering the visual space from any views},
author={Haotong Lin and Sili Chen and Jun Hao Liew and Donny Y. Chen and Zhenyu Li and Guang Shi and Jiashi Feng and Bingyi Kang},
journal={arXiv preprint arXiv:2511.10647},
year={2025}
}Notebook Overview
Level
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.