Command Palette
Search for a command to run...
VibeVoice-Realtime TTS: Real-time Speech Synthesis Service
1. Tutorial Introduction

VibeVoice-Realtime TTS is a high-quality real-time text-to-speech (TTS) system built upon the VibeVoice-Realtime-0.5B streaming speech synthesis model released by the Microsoft Research team in December 2025. This system employs a novel next-token diffusion method to model continuous data in long, multi-speaker speech synthesis and introduces an efficient continuous speech segmenter, enabling the model to generate up to 90 minutes of speech within a 64K context window, supporting up to four speakers. It significantly improves computational efficiency while maintaining audio fidelity and capturing the atmosphere of realistic conversations. Related research papers are available. VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech The system supports multi-speaker speech generation, low-latency real-time inference, and visual interaction via the Grado web interface.
Core features:
- Real-time speech synthesis with multiple speakers
- Streaming inference, low-latency output
- High-fidelity 24000Hz voice sampling rate
- Supports CFG Scale Controllable Generation
- GPU-accelerated inference
- Complete local offline deployment, without relying on the external network.
This tutorial uses Grado to deploy the VibeVoice-Realtime-0.5B core model, employing an "RTX_5090" computing resource, which can stably support the operation of real-time speech synthesis services. This model only supports English text input.
2. Effect display
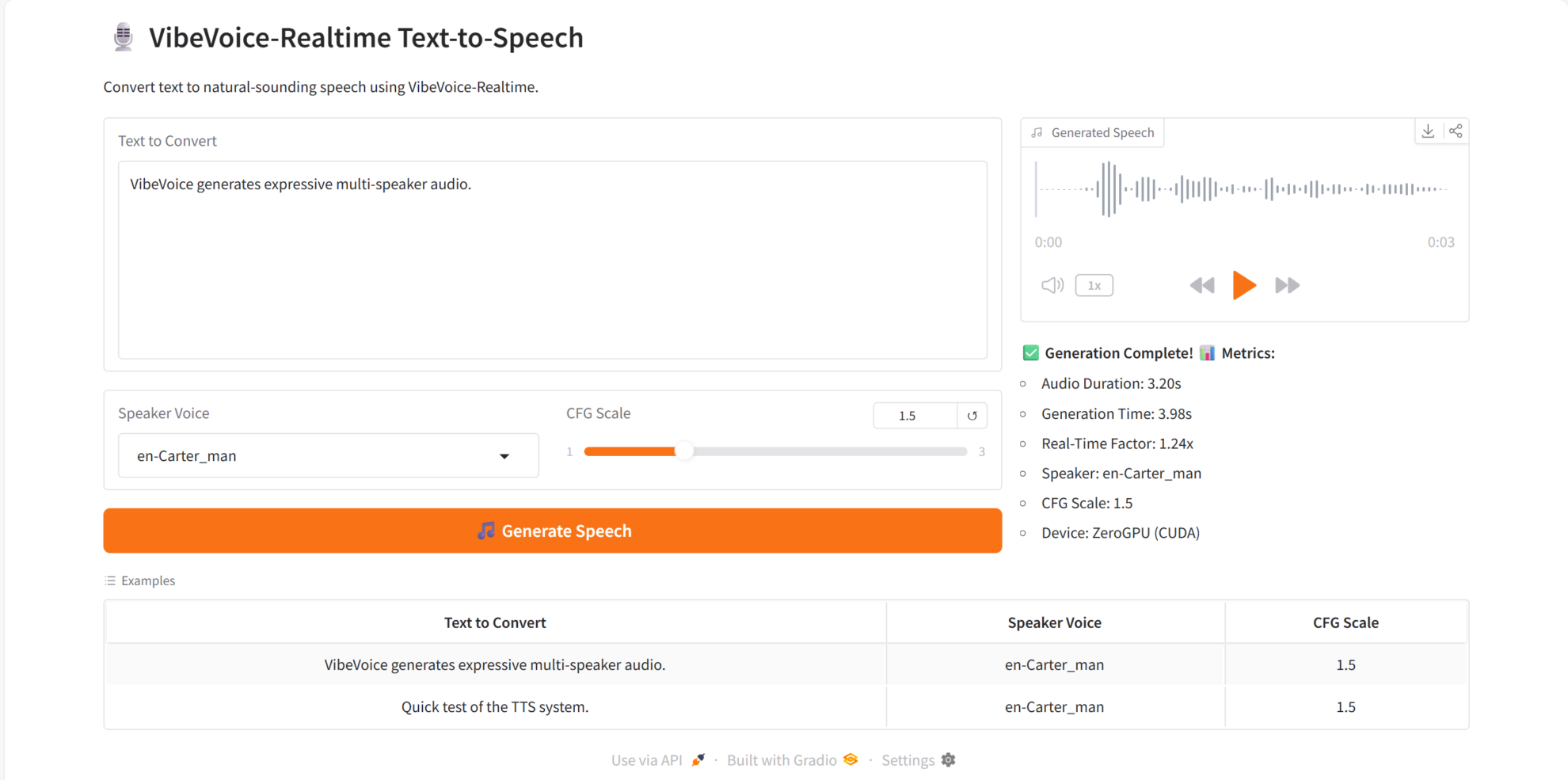
VibeVoice-Realtime excels in its core capabilities:
- Real-time TTS: Quickly generates speech output after inputting text.
- Multi-speaker support: Different voice styles can be switched for the same text.
- Highly natural speech quality: clear sound and natural intonation.
- Stable synthesis of long texts: No obvious punctuation or distortion issues.
- It has strong real-time interactive capabilities and is suitable for scenarios such as dialogue systems and voice assistants.
3. Operation steps
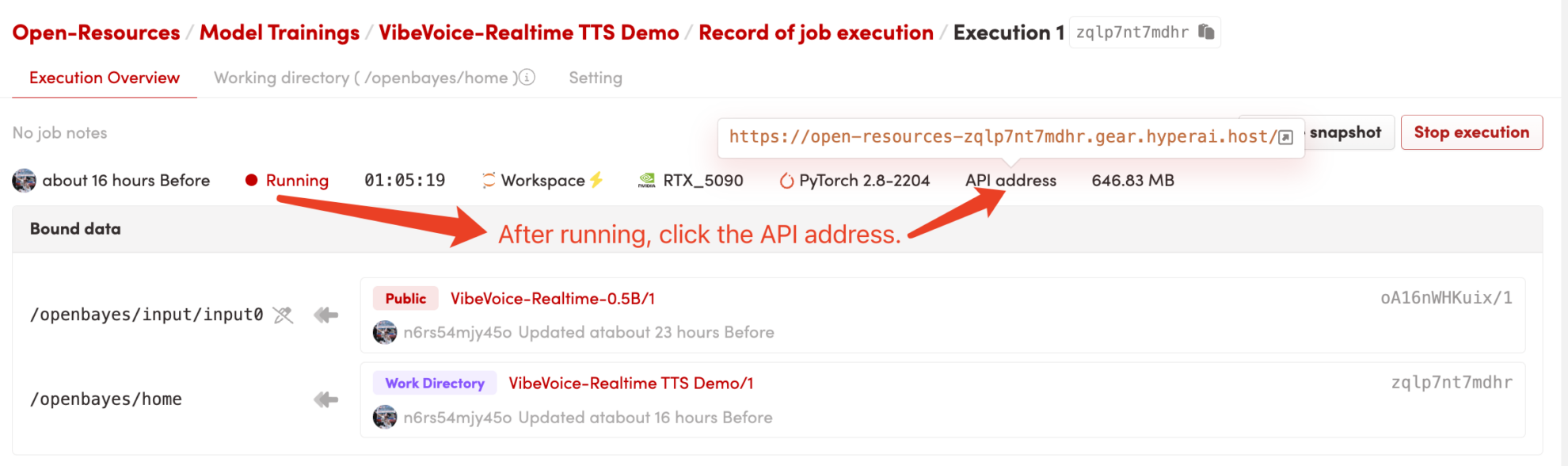
1. Start the container
After starting the container, click the API address to enter the Web interface
2. Getting Started
If "Bad Gateway" is displayed, it means that the model is being initialized. Since the model is large, please wait 1-2 minutes and then refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
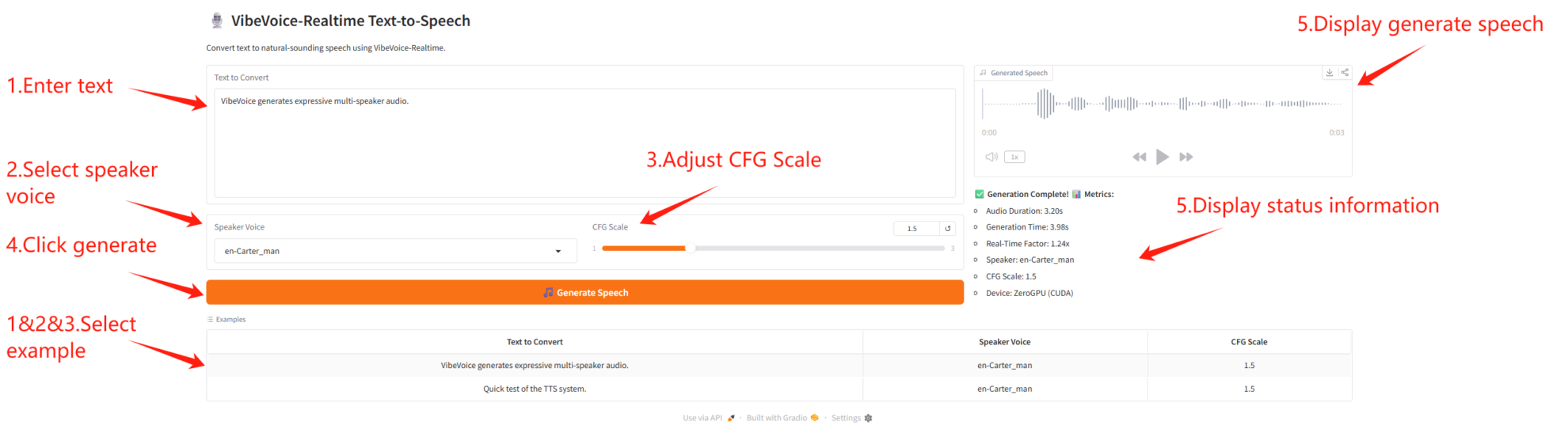
Parameter Description
- Speech generation parameters
- CFG Scale: Controls the intensity of speech style; the higher the value, the stronger the emotion.
- Speaker parameters
- Speaker Voice: Choose different speaker voices.

Citation Information
The citation information for this project is as follows:
@article{vibevoice2024,
title={VibeVoice: Real-Time Streaming Text-to-Speech with Multi-Speaker Support},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2412.08635},
year={2024}
}
@article{vibevoice2025,
title={VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2508.19205},
year={2025}
}Notebook Overview
Level
Topic
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.