Command Palette
Search for a command to run...
Ovis-Image: High-quality Image Generation Model
Date
Paper URL
License
Apache 2.0
GitHub
1. Tutorial Introduction

Ovis-Image is a high-quality text-to-image (T2I) generation model system, built upon the Ovis-Image-7B high-fidelity text-to-image generation model released by the AIDC-AI team in November 2025. This system employs a multi-scale Transformer encoder and an autoregressive generative architecture, demonstrating outstanding performance in high-resolution image generation, detail representation, and multi-style adaptation. Through optimized noise sampling and classifier-free guidance techniques, Ovis-Image can generate natural, coherent, and detailed images at 1024×1024 resolution, supporting various styles including realistic, cyberpunk, anime, and science fiction. Related research papers are available. Ovis-Image 7B: Text-to-Image Generation with Multi-Scale Transformer .
Core features:
- High-resolution native generation: Supports native generation up to 1024×1024 resolution, achieving clear and detailed results without the need for additional super-resolution models.
- Multi-scale semantic modeling: Based on a multi-scale Transformer encoding structure, it takes into account both overall composition and local texture details.
- High-quality detail reproduction: Stable performance in terms of characters, materials, lighting, and environmental complexity.
- Strong versatility across multiple styles: natively supports various mainstream styles such as realism, cyberpunk, anime, science fiction, and illustration.
- Highly controllable generation capability: Fine and controllable generation is achieved through Guidance Scale, sampling steps, resolution, and random seeds.
- Balancing inference accuracy and efficiency: Supports BF16 low-memory inference, while utilizing FP32 Decode to improve final image accuracy.
This tutorial uses Grado to deploy the Ovis-Image 7B core model, with "RTX_5090" computing resources, which can achieve 1024×1024 high-resolution text generation without any video memory/memory bottlenecks.
2. Effect display

The Ovis-Image 7B performs exceptionally well on core tasks:
- Complex Scene Generation: Generating natural and logically sound images from detailed text prompts.
- Multiple style support: Can generate various visual styles such as realistic, cyberpunk, anime, and science fiction.
- High-resolution detail: Rich textures, shadows, and lighting.
- Controllability: The generated effect can be adjusted by changing the number of steps, guidance scale, and resolution.
3. Operation steps
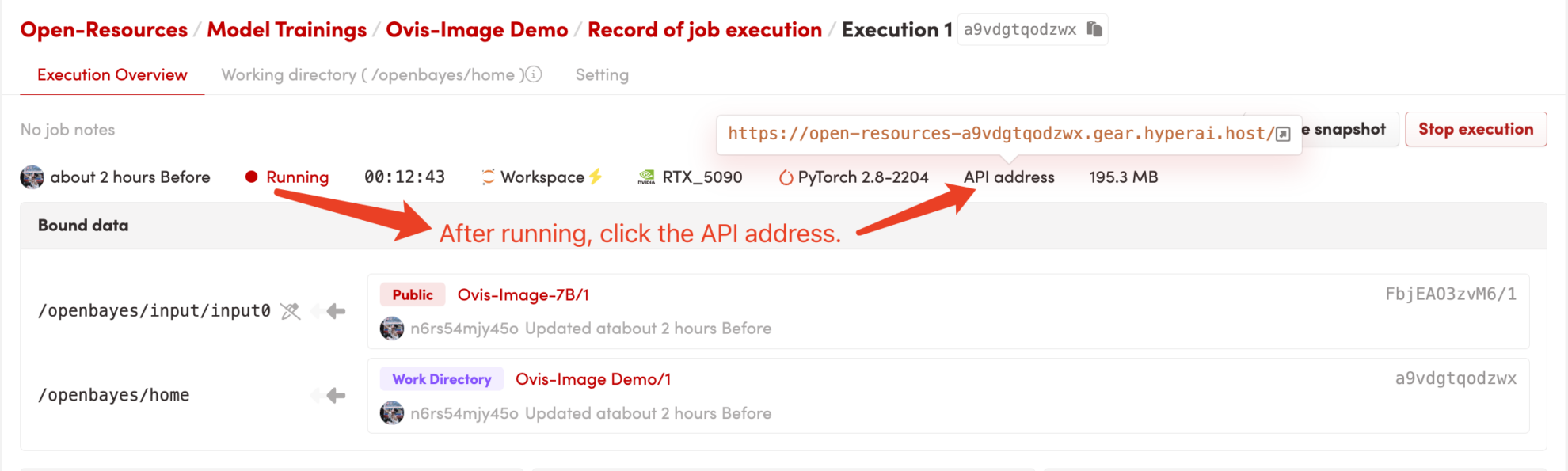
1. Start the container
After starting the container, click the API address to enter the Web interface
2. Getting Started
If "Bad Gateway" is displayed, it means the model is being initialized. Since the model is large, please wait 2-3 minutes and then refresh the page.
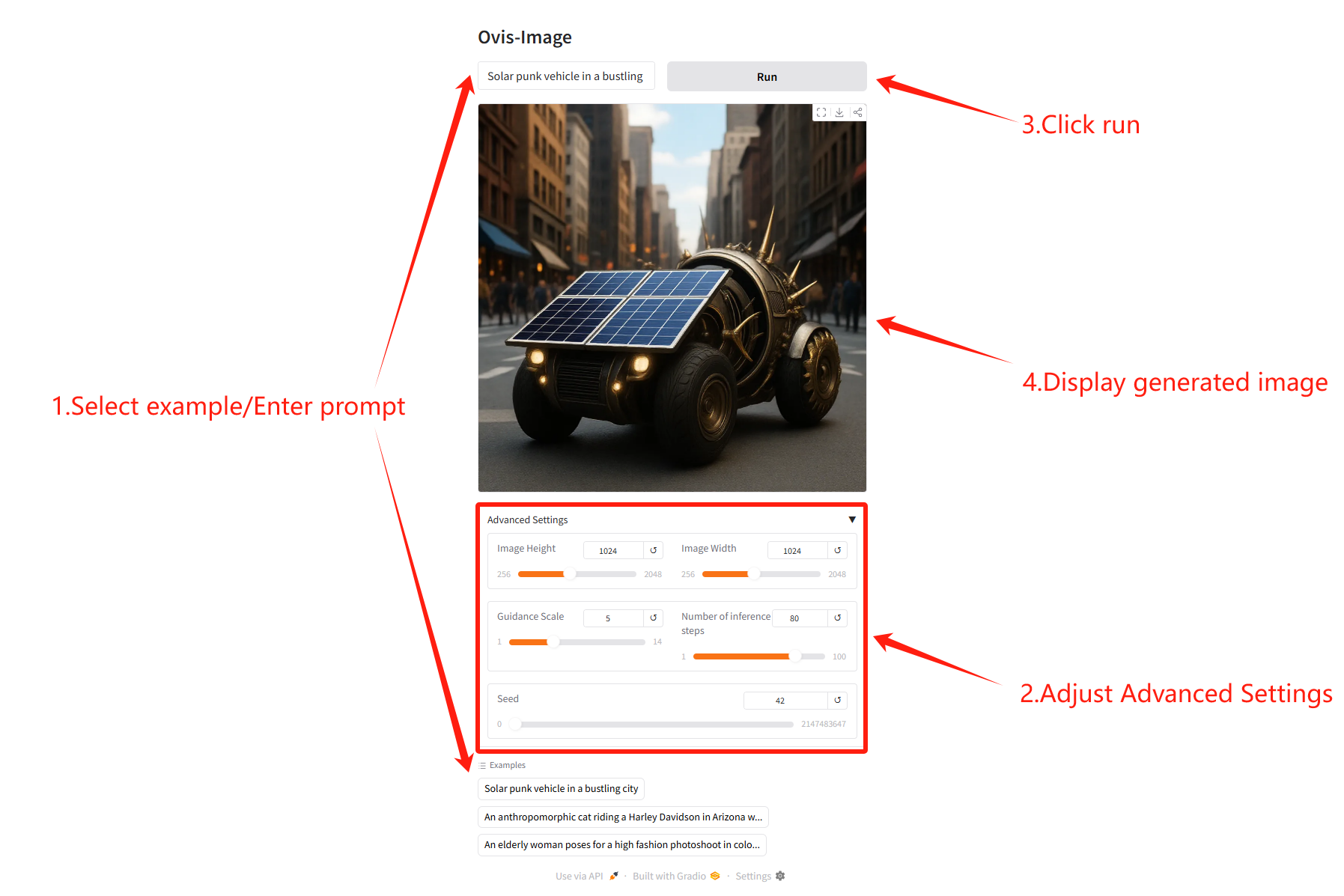
Parameter Description
- Image Height / Width: Generate the height and width of the image, with a step size of 32.
- Number of inference stepsThe more steps generated, the richer the image details.
- Guidance ScaleText prompt strength; the higher the value, the closer the image is to the prompt.
- SeedRandom seed ensures reproducible generation.
Citation Information
The citation information for this project is as follows:
@article{ovisimage7b,
title={Ovis-Image 7B: Text-to-Image Generation with Multi-Scale Transformer},
author={AIDC-AI Team},
journal={arXiv preprint arXiv:2511.22982},
year={2025}
}Notebook Overview
Level
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.