Command Palette
Search for a command to run...
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Zhaoyang Wang Canwen Xu Boyi Liu Yite Wang Siwei Han Zhewei Yao Huaxiu Yao Yuxiong He
Abstract
Recent advances in large language model (LLM) have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.
One-sentence Summary
Researchers from Snowflake Labs and UC San Diego propose Agent World Model (AWM), a synthetic environment generator enabling scalable, code-driven agent training with 1,000 diverse scenarios and 35 tools each, outperforming LLM-simulated environments and boosting out-of-distribution generalization via executable, database-backed states.
Key Contributions
- We introduce Agent World Model (AWM), a scalable, open-source pipeline that generates 1,000 diverse, code-driven, database-backed environments for training tool-using agents, ensuring reliable state transitions and efficient interaction compared to LLM-simulated or real-world setups.
- AWM enables large-scale reinforcement learning by providing executable environments with accessible states and tool interfaces via MCP, allowing design of robust reward functions through automated state verification and self-correcting code generation.
- Experiments on three benchmarks show that agents trained exclusively in AWM environments achieve strong out-of-distribution generalization, demonstrating the value of synthetic, non-benchmark-tailored training for real-world tool-use tasks.
Introduction
The authors leverage large language models to build Agent World Model (AWM), a scalable pipeline that generates 1,000 executable, database-backed environments for training tool-using agents via reinforcement learning. Prior work either relied on small, handcrafted environments or simulated state transitions with LLMs—both approaches suffer from poor scalability, hallucination, or high cost. AWM overcomes these by decomposing environment synthesis into structured components (tasks, database schema, tool interfaces, and verification code), ensuring consistent state transitions and enabling efficient, parallel RL training. Its key contributions include an open-source generation pipeline, a large-scale set of diverse environments with 35,000+ tools, and empirical evidence that agents trained on AWM generalize well to unseen benchmarks.
Dataset

The authors use a synthetically generated dataset to train agents on stateful, database-backed applications—focusing on CRUD operations rather than static content. Here’s how the dataset is built and used:
-
Dataset Composition & Sources:
- Starts with 100 seed domain names (popular websites) and scales to 1,000 diverse scenarios using a Self-Instruct style LLM expansion.
- Each scenario represents a real-world application domain (e.g., e-commerce, CRM, banking, travel) requiring database interactions.
- Scenarios are filtered to exclude read-only or content-heavy sites (like news or blogs) and capped by category to ensure diversity.
-
Key Subset Details:
- Scenario Generation:
- LLM classifier scores candidates on CRUD suitability (rejects non-interactive content).
- Embedding-based deduplication (cosine similarity threshold: 0.85) ensures distinctness.
- Final set: 1,000 unique, stateful scenarios across 20+ domains (see Figures 6, 7, Table 9).
- Task Generation:
- For each scenario, LLM generates 10 specific, API-solvable tasks per scenario (no UI dependencies).
- Tasks include concrete parameters (e.g., product IDs, user names) and assume post-authentication context.
- Output: 10,000 total tasks (Table 11), designed to drive schema and toolset synthesis.
- Scenario Generation:
-
How Data Is Used in Training:
- Tasks are used to synthesize full-stack environments: database schemas, FastAPI endpoints, and MCP-compatible tools.
- Each environment includes ~2,400 lines of code, 25+ database models, and 45+ discoverable tools (Figure 25).
- Environments are isolated and launched via config (env vars, DB paths) for RL training.
- Tools are dynamically discoverable via MCP protocol; agents interact through structured API calls.
-
Processing & Metadata:
- Synthesized data includes numbers, entities, status values, short text, timestamps, and geographic data—excluding long-form content, media, or AI inference.
- High-suitability domains (e.g., e-commerce, banking) are prioritized; medium-suitability (e.g., Spotify playlists) focus on CRUD aspects only.
- Verification uses structured JSON output with reasoning, confidence scores, classification, and evidence (Figure 22) to reward RL agents.
- All generated code and schemas are valid, runnable, and include OpenAPI metadata for tool discovery.
Method
The authors leverage a fully automated pipeline to synthesize executable, agentic reinforcement learning environments grounded in structured relational state. The overall framework, as shown in the figure below, progresses through five sequential stages: scenario synthesis, task generation, database and data synthesis, interface and environment implementation, and finally, verification coupled with online RL training. Each stage is driven by large language models (LLMs) and incorporates a self-correction mechanism to ensure functional correctness.
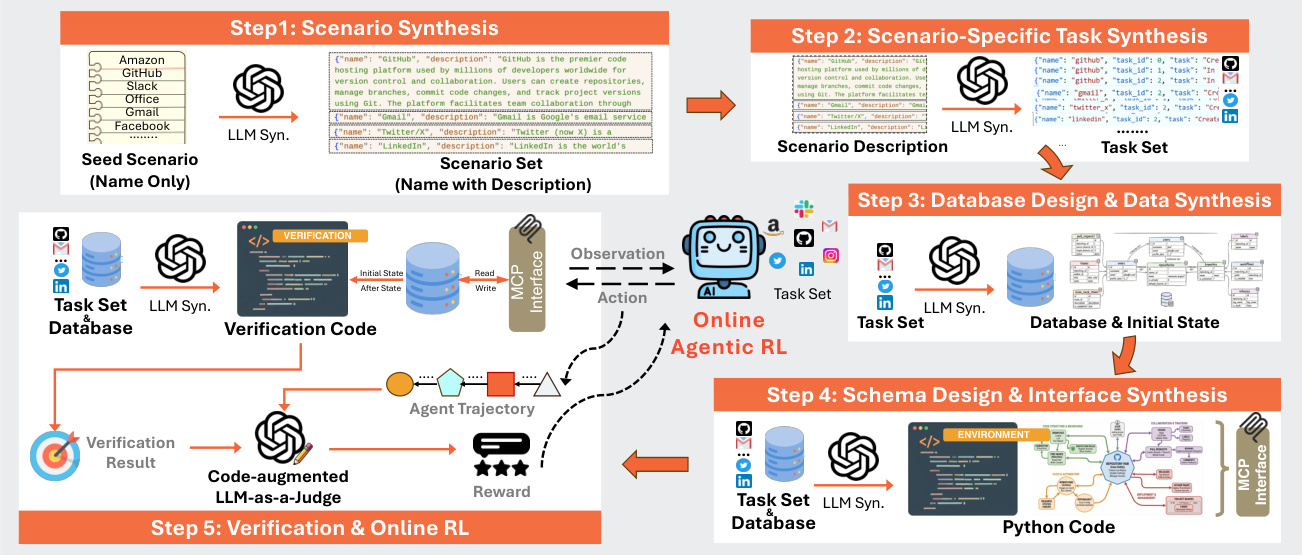
The process begins with scenario synthesis, where the LLM generates a descriptive context for a target platform (e.g., GitHub, Gmail) from a seed name. This description then drives the generation of a diverse set of k=10 executable user tasks per scenario, ensuring API-solvability and post-authentication context. These tasks serve as functional requirements for the environment, dictating the necessary entities and operations.
In the database synthesis phase, the LLM infers a minimal SQLite schema from the task set, defining the state space SEi with explicit keys and constraints. To ensure tasks are executable from the start, the LLM also synthesizes sample data that satisfies task preconditions, populating the database with realistic initial state s0. Both schema and data generation are validated through an execution-based self-correction loop: if generated SQL fails, an LLM summarizes the error and regenerates the code, with a 10% failure threshold for acceptance.
The interface layer is synthesized in two stages. First, the LLM designs a machine-readable API specification based on the task set and schema, defining a minimal set of atomic, composable endpoints. This specification includes typed parameters, response schemas, and summaries that serve as documentation for agents. Second, the LLM generates a complete Python implementation using FastAPI and SQLAlchemy ORM, exposing the endpoints via the Model Context Protocol (MCP). Each environment averages 2,000 lines of code and 35 tools, and is validated by launching the server and checking health endpoints.
For reward design, the authors adopt a hybrid approach. At each step t, the agent’s tool call is validated for format correctness using rule-based checks; violations trigger early termination with a reward of rt=−1.0. If the rollout completes normally, a task-level reward Rτ is assigned via a code-augmented LLM-as-a-Judge. This judge combines structured verification signals—extracted by comparing database states before and after execution—with the agent’s trajectory to determine outcomes: Completed (reward 1.0), Partially Completed (reward 0.1), or otherwise (reward 0.0).
To align training with inference, the authors implement history-aware training under Group Relative Policy Optimization (GRPO). Instead of optimizing policies using full interaction histories, they truncate the history to a fixed window w during training, matching the context window used at inference time. The GRPO objective is:
LGRPO=Eτ,Ei,{y(k)}[G1k=1∑GA(k)t=1∑Tklogπθ(at(k)∣httrunc,(k))]where A(k) is the group-relative advantage computed from rollout rewards. This ensures the policy is optimized under the same context constraints it will face during deployment.
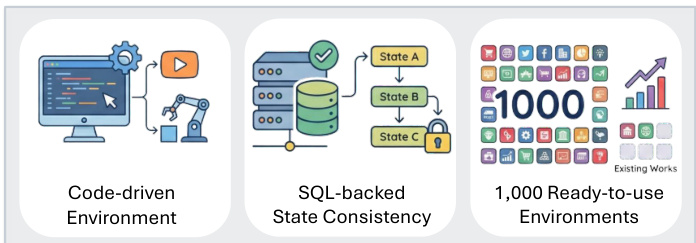
The entire synthesis pipeline is designed for robustness and scalability, producing 1,000 ready-to-use environments with SQL-backed state consistency, as highlighted in the figure below.
Experiment
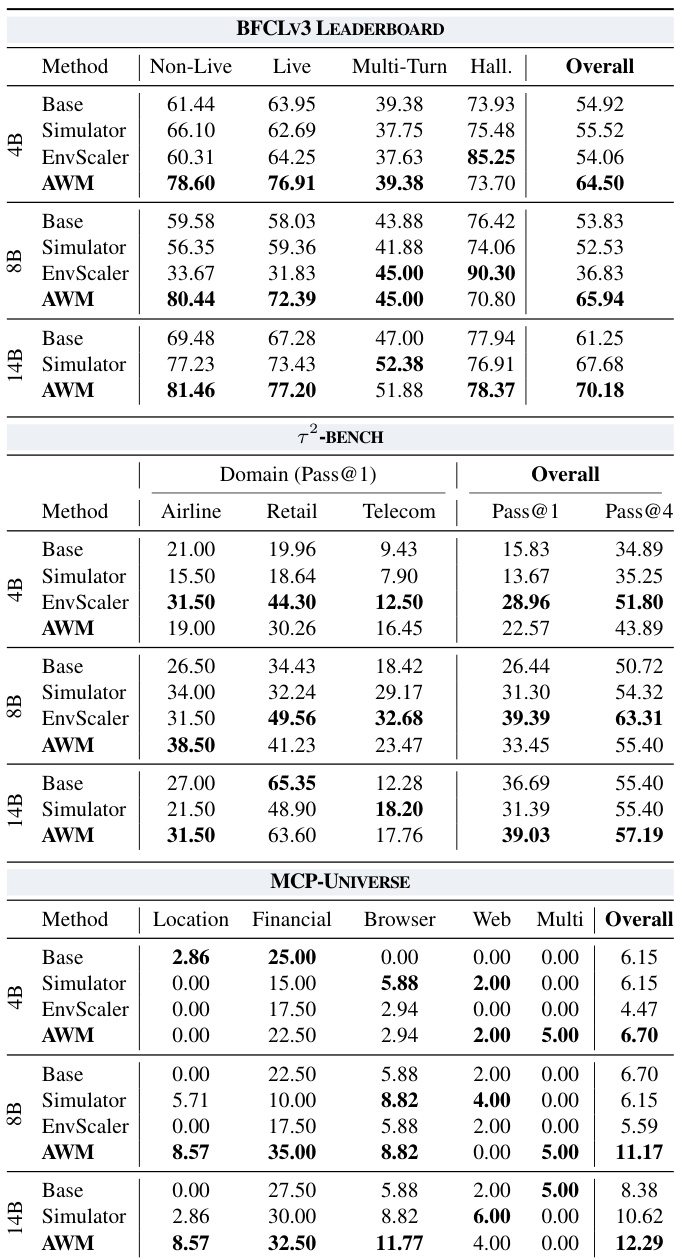
- AWM successfully synthesizes 1,000 executable environments and 10,000 tasks with over 85% success, requiring minimal human input and outperforming prior methods like EnvScaler by 5x in scale while maintaining state consistency via SQL.
- Training agents on AWM environments improves performance across diverse benchmarks (BFCLv3, τ²-bench, MCP-Universe), demonstrating strong out-of-distribution generalization, especially in financial and location tasks, and surpassing both simulated and concurrent synthesis baselines.
- AWM environments exhibit high quality and diversity: LLM-as-a-Judge evaluations confirm superior task feasibility, data alignment, and toolset completeness; semantic and topical diversity remains stable as scale increases, avoiding collapse into duplicates.
- The code-augmented verification strategy—combining structured database checks with LLM reasoning—proves more robust than LLM-only or code-only methods, effectively handling environment imperfections while adding negligible latency.
- History-aware training under truncated contexts improves performance and reduces distribution shift between training and inference, validating that history management should be optimized as part of policy learning.
- Environment scaling shows monotonic performance gains: 10 environments cause overfitting, 100 yield substantial improvement, and 526 further enhance results, suggesting AWM supports scaling beyond 1,000 environments with sustained benefits.
- Step-level format correctness reward significantly reduces tool-calling errors, accelerates training convergence, and boosts task completion rates, proving critical for stable and efficient RL in synthetic environments.
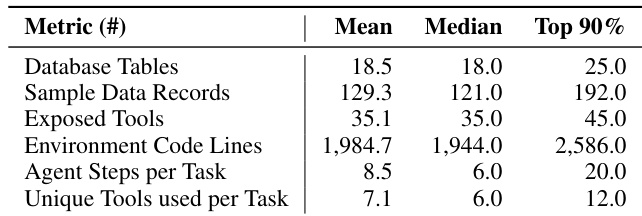
The authors use AWM to generate complex, executable environments with substantial codebases and diverse toolsets, as shown by metrics including nearly 2,000 lines of code and over 35 exposed tools per environment on average. Results show these environments support non-trivial, multi-step agent interactions while maintaining structural richness far beyond toy setups. This scale and complexity confirm the pipeline’s ability to synthesize realistic, high-fidelity training environments efficiently.
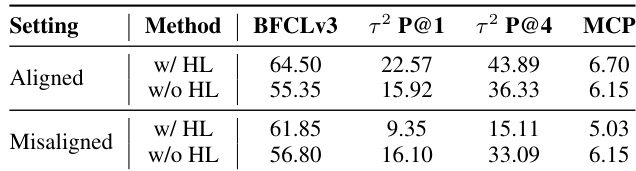
The authors evaluate history-aware training under aligned and misaligned settings, finding that training with history truncation (w/ HL) yields superior performance when inference conditions match training. When settings are misaligned, models trained without history limits (w/o HL) show greater robustness, sometimes even improving slightly due to reduced interference from irrelevant context. This suggests that history management should be integrated into policy optimization rather than treated as a separate inference-time adjustment.
The authors use LLM-as-a-Judge to evaluate synthesized environments across task feasibility, data alignment, and toolset completeness, with AWM consistently scoring higher than EnvScaler under both GPT-5.1 and Claude 4.5. Despite generating environments with more code, AWM exhibits fewer bugs per environment and significantly fewer blocked tasks, indicating better scalability and reliability for reinforcement learning. Results confirm that AWM maintains higher end-to-end consistency from task to database to interface, reducing training disruptions caused by environment errors.

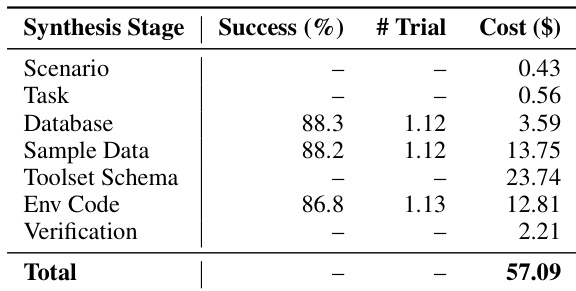
The authors use AWM to synthesize executable environments through a multi-stage pipeline, achieving high success rates across database and environment code generation stages while maintaining low average iteration counts for self-correction. Results show the pipeline is cost-effective and scalable, with verification and toolset schema stages contributing significantly to overall cost but enabling robust, non-toy environments suitable for training agents. The design supports large-scale synthesis with minimal human input, confirming its feasibility for generating diverse, executable environments at scale.
The authors use AWM to synthesize large-scale executable environments for training agents, achieving higher success rates and greater scalability than prior methods with minimal human input. Results show that agents trained on AWM consistently outperform baselines across multiple out-of-distribution benchmarks, particularly in real-world tool-use scenarios, indicating strong generalization from synthetic to real environments. The hybrid code-augmented verification design further enhances training stability and reward reliability despite environment imperfections.