Command Palette
Search for a command to run...
An MIT Team Has Improved Wireless Vision Systems by Using Generative AI to Reconstruct Fully Occluded Objects With High Accuracy, Achieving a Peak Accuracy of 851 TP3T.

In the fields of computer vision and intelligent sensing, reconstructing completely occluded objects has always been a challenging research problem. Imagine stacked packages in a logistics warehouse, complex equipment on a production line, or applications in augmented reality that need to identify hidden objects; traditional optical sensors such as cameras or LiDAR are often ineffective. They rely on the reflection of visible light or laser lines, but these signals are blocked when they encounter obstacles, making the objects unobservable.
In recent years, the emergence of millimeter wave (mmWave) technology has provided a new solution to this problem.Millimeter-wave signals can penetrate common obstructions such as cardboard boxes and fabric, while also being safe and gentle on the human body.This gives it enormous potential in fields such as industry, logistics, robotics, and augmented reality. Nevertheless,Millimeter-wave signals have specular reflection characteristics, high noise, and low spatial resolution, making it challenging to directly use them for complete 3D reconstruction.To overcome this problem, one approach is to apply existing vision-based shape completion models to millimeter-wave reconstruction. However, this strategy often fails to produce reliable reconstruction results because these models were originally designed for high-coverage, high-resolution visible light sensors and do not take into account the unique physical characteristics of millimeter-wave reflection.
In response to this pain point,Researchers from MIT have proposed a novel method called Wave-Former, which bridges the gap between wireless sensing and modern shape completion techniques by embedding the physical properties of millimeter waves into the learning process, enabling high-precision 3D shape reconstruction of completely occluded, diverse everyday objects.This method not only solves the problems of high signal noise and severe occlusion, but also achieves high-fidelity reconstruction in real-world environments based on synthetic data training through an innovative physical perception training framework. In a direct comparison with state-of-the-art baseline methods, Wave-Former improves recall from 541 TP3T to 721 TP3T while maintaining a high accuracy of 851 TP3T.
The related research findings, titled "Wave-Former: Through-Occlusion 3D Reconstruction via Wireless Shape Completion," have been published as a preprint on arXiv.
Research highlights:
* This paper proposes for the first time a millimeter-wave 3D shape completion framework for diverse objects, enabling the model to be trained entirely on synthetic data while simultaneously achieving 3D reconstruction on real data.
* This method improves the recall rate from 54% to 72% on the real MITO dataset, surpassing existing millimeter-wave reconstruction methods.
* When applied to millimeter-wave partial point clouds, it surpasses the native visual completion model, improving recall by 121 TP3T and achieving a peak accuracy of 851 TP3T.
Paper address:
https://arxiv.org/abs/2511.14152
Follow our official WeChat account and reply "millimeter wave" in the background to get the full PDF.
The 3D object dataset provides a rich sample.
To train and validate Wave-Former, the research team used three publicly available 3D object datasets—
* OmniObject3D:It contains a large amount of diverse point cloud data of everyday objects, covering categories such as furniture, tools, and toys.
* Toys4K-3D:Focusing on toys and small objects, it enriches the diversity of shapes and material properties.
* Objaverse Thingiverse subset:It provides an open-source platform for creating 3D models to generate synthetic training data.
These three datasets contain a total of over 25,000 3D point clouds.It provides a rich set of training samples for Wave-Former.
In the real-world evaluation, the research team used the MITO dataset, which contains 61 objects from the YCB dataset.These objects cover a variety of task scenarios, including kitchenware, tools, food, and toys. They are made of materials such as wood, metal, cardboard, and plastic, and come in a wide variety of complex shapes.This includes sharp edges, flat surfaces, and curved surfaces. Millimeter-wave measurements were performed on each object under both line-of-sight and complete occlusion conditions, providing a thorough test of the model's generalization ability.
Note: The YCB dataset, short for YCB Object and Model Set, is a classic and widely used standard dataset in the fields of robotics and computer vision.
It is worth mentioning that Wave-Former's training relies entirely on synthetic data. Through the physical perception training framework, the model can learn the characteristics of millimeter-wave signals, thus performing well in real-world measurements and avoiding the training difficulties caused by the scarcity of actual millimeter-wave data.
Wave-Former: Trained on synthetic data, it achieves 3D reconstruction on real data.
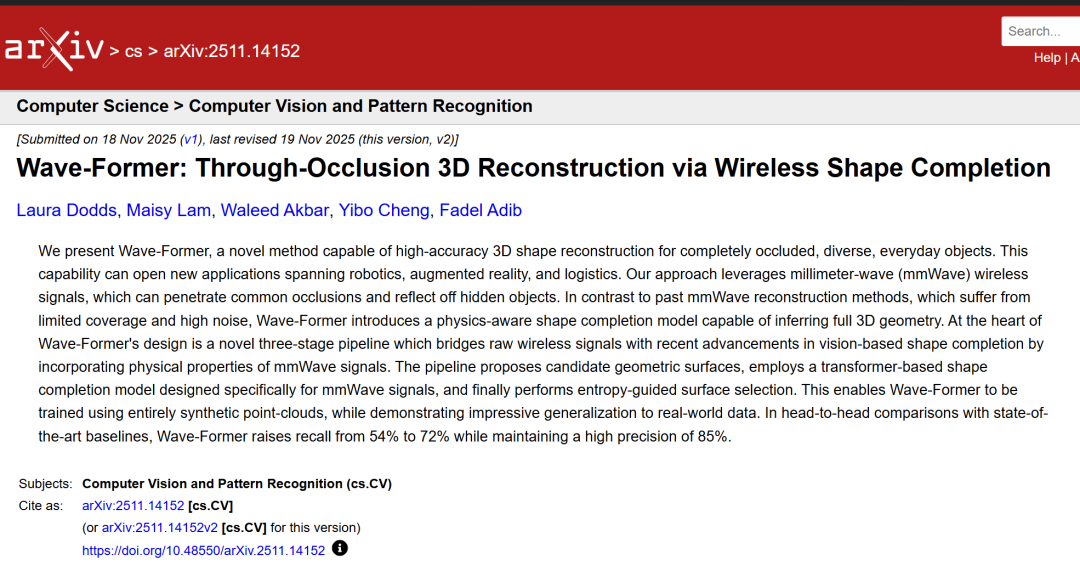
Wave-Former's core design consists of two parts: a physical perception training process and a real-world inference process.This design fully considers the characteristics of millimeter-wave signals: specular reflection, high noise, low spatial resolution, and visibility non-uniformity. The overall process is shown in the figure below:
Physics-aware training pipeline
Wave-Former's physics-aware training process incorporates physical properties into training through inductive bias of mirror reflection perception, reflection-dependent visibility patterns, and a joint optimization and completion framework, enabling the model to be trained entirely on synthetic data.
The first is the inductive bias of specular reflection perception.Existing vision-based completion models essentially encode an inductive bias consistent with visible light, but this bias is incompatible with millimeter-wave signals because their "camera-like" partial observations assume diffuse reflection and wide coverage. To address this issue, researchers have redefined the inductive bias through physically consistent partial observations to simulate the specular reflection of millimeter-wave signals.
The second is visibility that depends on reflection.Unlike optical sensors, millimeter-wave visibility exhibits strong anisotropy, meaning that measurable reflection depends on the angle of incidence and the intensity of reflection from the object. Therefore, even two objects with identical geometry can have significantly different visibility due to material properties.
To model this behavior,Researchers introduced a reflection-dependent visibility pattern.The attenuation surface points are determined by physical guidance and material constraints. This replaces the common isotropic coverage assumption, enabling the network to understand that millimeter-wave visibility is inherently non-uniform and angle-dependent.
The third is the combined noise reduction and completion.Existing vision-based shape completion models are designed for the typical noise and resolution characteristics of cameras or LiDAR sensors, thus assuming that the input partial point cloud can be directly stitched with the reconstructed points. However, millimeter-wave signals have significantly higher noise and reduced resolution, so existing stitching strategies propagate a large amount of distortion to the final reconstruction result.
To solve this problem,Researchers have proposed a joint optimization and completion method.Noise is introduced during training to simulate the characteristics of real millimeter-wave signals, and then the loss function is redefined so that the model can output a complete 3D shape (without stitching the input), thereby reinterpreting unreliable points instead of simply preserving them.
The entire training framework is based on the Transformer encoder-decoder architecture (PoinTr backbone), combined with a physically consistent observation model and a denoising and completion objective.This enables the model to be trained on fully synthetic data and to achieve high-fidelity reconstruction on real millimeter-wave signals.
Real-world inference process
Wave-Former's real-world inference process utilizes a three-stage pipeline to reconstruct complete 3D objects from real millimeter-wave signals.
Millimeter-wave surface candidate generation (stage one)
First, the researchers transformed the raw millimeter-wave measurements into a set of candidate partial surfaces, accurately capturing the geometric information contained in the reflections. Typically, millimeter-wave partial point cloud estimation relies on thresholding the millimeter-wave 3D power image; however, this generates a large number of erroneous points. The researchers utilized recent advances in millimeter-wave imaging to transform the raw reflections into a geometrically consistent partial surface space.
Physical perception shape completion (stage two)
The trained model is applied to each candidate surface to generate a set of physically consistent complete candidate reconstructions.
Entropy-sensing surface selection (Phase 3)
In cases of high noise or weak reflection, the continuity and planarity of the point cloud are measured by local entropy, and the candidate reconstruction with the lowest entropy is selected to obtain the final high-fidelity 3D point cloud.
This process enables Wave-Former to handle complex occlusion, low coverage, and high noise real-world scenarios, completing comprehensive 3D reconstruction.
Wave-Former represents a significant improvement over previous state-of-the-art millimeter-wave 3D reconstruction methods.
To evaluate performance, researchers compared Wave-Former with four state-of-the-art millimeter-wave reconstruction baselines:
* Backprojection: A classic and most widely used millimeter-wave imaging method, a volume reconstruction method based on first principles.
* mmNorm: A recently proposed state-of-the-art millimeter-wave 3D reconstruction method, also based on first principles, reconstructs the object surface by estimating surface normal vectors.
* RMap: A state-of-the-art learning-based millimeter-wave reconstruction method, originally developed for scene-level understanding.
* RMap (fine-tuned version): RMap is fine-tuned on the same training data as Wave-Former for object reconstruction.
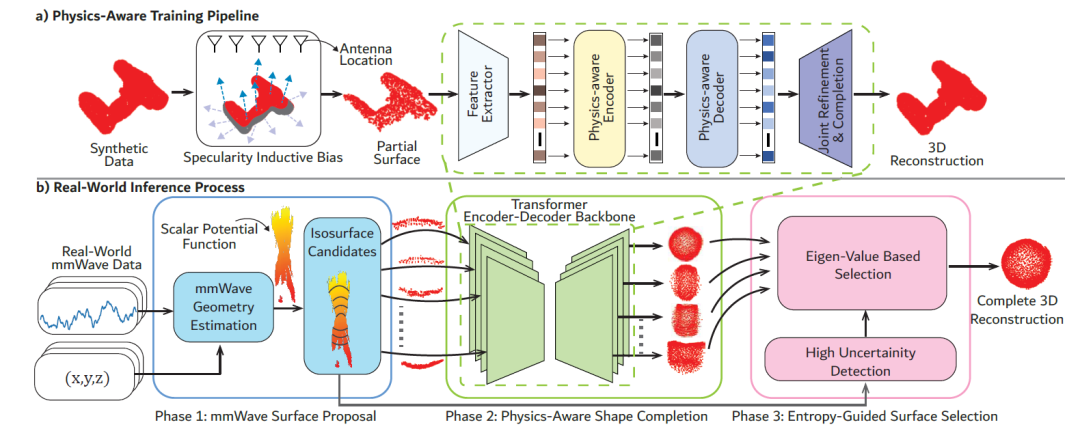
Qualitative performance
First, the researchers used real-world measurements to qualitatively compare Wave-Former with four baselines. The figure below shows isometric views of the real RGB (after segmentation) and point cloud of several fully occluded objects, as well as the reconstruction results of each method.
Visual comparison of millimeter-wave 3D reconstructions of completely occluded objects in the real world
Obviously,Wave-Former can reconstruct the complete shape of an object stably, even complex geometries such as drills or jigs.In contrast, baseline methods suffer from low accuracy, limited coverage, high noise, and in some cases, are almost unable to distinguish object geometry. These results demonstrate the significant advancement of Wave-Former over previous state-of-the-art millimeter-wave 3D reconstruction methods.
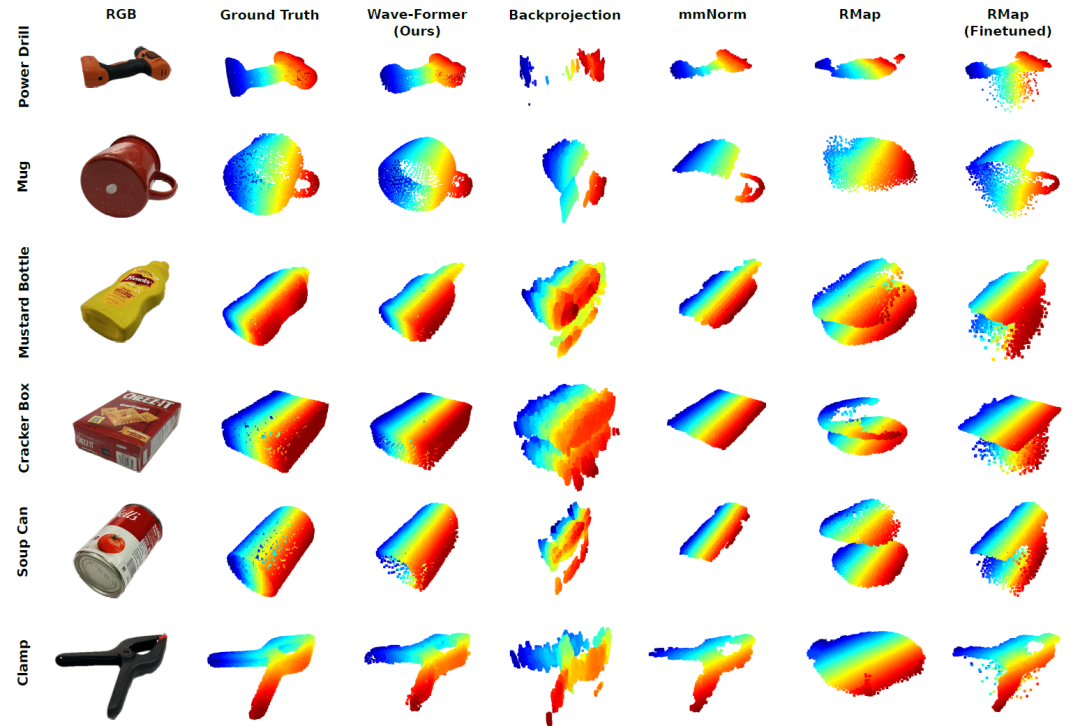
Quantitative results
The table below reports Wave-Former's performance compared to all baselines in terms of mean Chamfer distance, F-score, precision, and recall:
It is worth noting thatWave-Former's recall rate has been significantly improved, from 54% in the best baseline RMap (fine-tuned version) to 72%, while maintaining a high accuracy of 85%.Furthermore, Wave-Former exhibits the lowest Chamfer distance at 0.069, compared to the optimal baseline of 0.18. This fully demonstrates the value of the proposed method in achieving high-precision 3D reconstruction of fully occluded objects.
Compared with vision-based shape completion
Researchers also evaluated whether state-of-the-art native visual shape completion models could achieve high-precision millimeter-wave 3D reconstruction. The table below reports a performance comparison between Wave-Former and four state-of-the-art models:
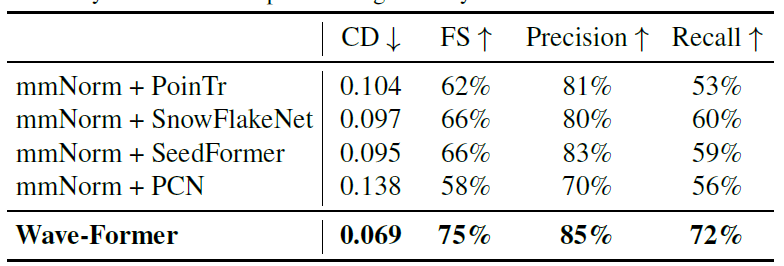
Wave-Former outperformed other models across all metrics, improving recall from 60% to 72% while achieving the highest precision of 85%.This demonstrates the importance of incorporating physical properties into shape completion models.
Ablation experiment
Finally, the researchers also analyzed the contribution of each design component of Wave-Former to the overall performance. The table below shows the average Chamfer distance (CD), 75th percentile CD, and marginal improvement percentage of Wave-Former compared to three different partial implementation schemes:

When specular reflection-perceived inductive bias and reflection-dependent visibility (Model A) are removed, performance degrades significantly: the average Chamfer distance increases by 521 TP3T, and the 75th percentile increases by 671 TP3T.
When the joint reconstruction and completion module (Model B) is further removed, the average Chamfer distance increases by 10%.
When the entropy-aware surface selection module (model C) is removed again, the 75th percentile CD increases by 19%.
In summary, these results clearly demonstrate the contribution of each component of Wave-Former to the overall performance.
Technological Extension: From "Reconstructing Objects" to "Reconstructing Space"
If Wave-Former has proven that, with the help of generative AI and millimeter-wave signals, it is possible to achieve high-precision 3D reconstruction of "completely occluded objects,"Another concurrent study by the MIT team takes this capability a step further—extending it from a single object to the entire space.
In this study, researchers no longer focus solely on the shape of the hidden objects.Instead, it utilizes the multipath millimeter wave reflections generated by the human body during indoor movement to reconstruct the complete indoor environment.Traditional methods typically discard such complex reflections as noise, but this study found that these so-called "ghost signals" actually contain important clues about spatial structure: when the signal reflects multiple times between the human body and walls and furniture, the changes in its path itself encode the geometric information of the environment.
The problem is that these signals are highly chaotic and have limited resolution, making them almost impossible to analyze directly using traditional physical modeling. To address this, the research team introduced generative AI to understand and complete these low-quality, sparse initial reconstruction results, enabling the model to learn the statistical patterns of multipath reflections and gradually infer the complete spatial layout.
Extensive experiments demonstrate that, compared to existing techniques in the field of layout reconstruction, RISE reduces the chamfer distance by 601 TP3T (down to 16 cm) and achieves millimeter-wave-based target detection for the first time, with an IoU of 581 TP3T. These results indicate that RISE lays a new foundation for geometric perception and privacy-preserving indoor scene understanding using a single static radar.
Paper Title: RISE: Single Static Radar-based Indoor Scene Understanding
Paper link:https://arxiv.org/abs/2511.14019
From a broader perspective, these two studies together reveal a clear technological path: AI is no longer just about improving sensor accuracy, but is beginning to compensate for the lack of information itself. Whether it's Wave-Former's completion of occluded objects or RISE's inference of indoor spaces, their essence is to use generative models to transform incomplete or even highly distorted inputs into a structurally complete and physically plausible three-dimensional world. This means that future perception systems may no longer depend on "how much can be seen," but rather on "how much can be inferred." Under this trend, fields such as robotics, smart homes, and even augmented reality are expected to gain a completely new capability—reconstructing reality from the invisible.
References:
1.https://arxiv.org/abs/2511.14152
2.https://news.mit.edu/2026/generative-ai-improves-wireless-vision-system-sees-through-obstructions-0319
3.https://arxiv.org/abs/2511.14019








