Command Palette
Search for a command to run...
Selected for NeurIPS 2025, the Zhiyuan, Peking University, and Beijing University of Posts and Telecommunications Proposed a multi-stream Control Video Generation Framework That Achieves Precise audio-visual Synchronization Based on Audio demixing.

Compared to text, audio inherently possesses a continuous temporal structure and rich dynamic information, enabling more precise temporal control for video generation. Therefore, with the development of video generation models, audio-driven video generation has gradually become an important research direction in the field of multimodal generation. Currently, related research covers multiple scenarios such as speaker animation, music-driven video, and audio-visual synchronization generation; however, achieving stable and accurate audio-visual alignment in complex video content remains highly challenging.
The main limitation of existing methods stems from the way audio signals are modeled. Most models introduce the input audio as a holistic condition into the generation process, failing to distinguish the functional roles of different audio components such as speech, sound effects, and music at the visual level. This approach reduces modeling complexity to some extent.However, this also blurs the correspondence between audio and visuals, making it difficult to simultaneously meet the requirements of lip-sync, event timing alignment, and overall visual atmosphere control.
To address this issue,The Beijing Academy of Artificial Intelligence, Peking University, and Beijing University of Posts and Telecommunications jointly proposed a framework for audio-visual synchronized video generation based on audio demixing.The input audio is split into three audio tracks: speech, sound effects, and music, each used to drive different levels of visual generation. This framework, through a multi-stream temporal control network and a corresponding dataset and training strategy, achieves a clearer audio-visual correspondence at both the temporal and global levels. Experimental data show that this method achieves stable improvements in video quality, audio-visual alignment, and lip-sync, validating the effectiveness of audio demixing and multi-stream control in complex video generation tasks.
The related research findings, titled "Audio-Sync Video Generation with Multi-Stream Temporal Control," have been selected for NeurIPS 2025.
Paper address:
https://arxiv.org/abs/2506.08003
Research highlights:
* We construct the DEMIX dataset, which consists of five overlapping subsets for audio-synchronized video generation, and propose a multi-stage training strategy for learning audiovisual relationships.
* Proposes an MTV framework that splits audio into three tracks: speech, sound effects, and music. These tracks control different visual elements such as lip movements, event timing, and overall visual atmosphere, enabling more precise semantic control.
* Design a multi-stream time control network (MST-ControlNet) to simultaneously handle fine synchronization of local time intervals and global style adjustment within the same generation framework, structurally supporting differentiated control of different audio components on a time scale.
Multifunctional generation capability
MTV has multi-functional generation capabilities, such as character-centric narratives, multi-character interactions, sound-triggered events, atmosphere created by music, and camera movement.
The DEMIX dataset introduces demixed track annotations to enable phased training.
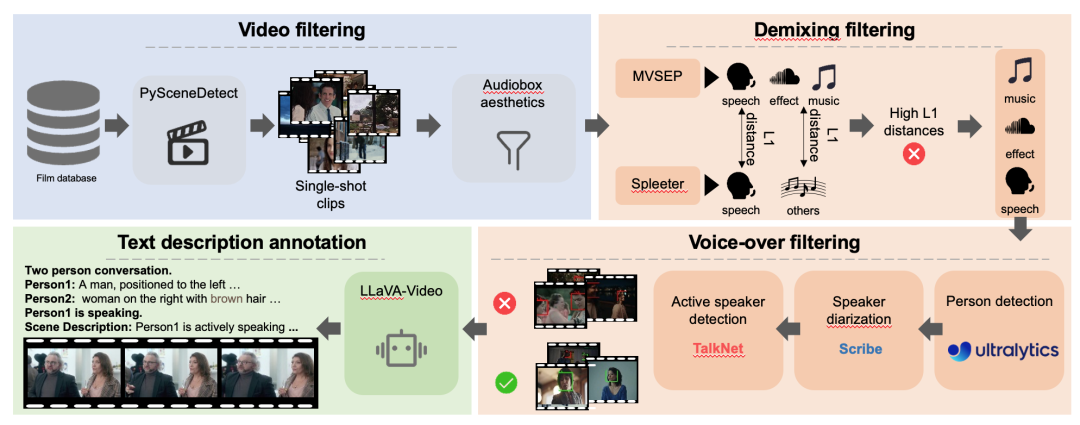
This paper first obtains the DEMIX dataset through a detailed filtering process. The filtered DEMIX data is then structured into five overlapping subsets:Basic facial features, single-person effects, multi-person effects, event sound effects, and environmental atmosphere. Based on five overlapping subsets.This paper introduces a multi-stage training strategy.The model is progressively scaled up. First, the model is trained on a basic facial subset to learn lip movements; then, it learns human pose, scene appearance, and camera movement on a single-person subset; subsequently, it is trained on a multi-person subset to handle complex scenes with multiple speakers; next, the training focus shifts to event timing, and the subject understanding is extended from humans to objects using an event sound effects subset; finally, the model is trained on an ambient atmosphere subset to improve its representation of visual emotions.
Based on a multi-stream timing control mechanism, precise audiovisual mapping and accurate time alignment are achieved.
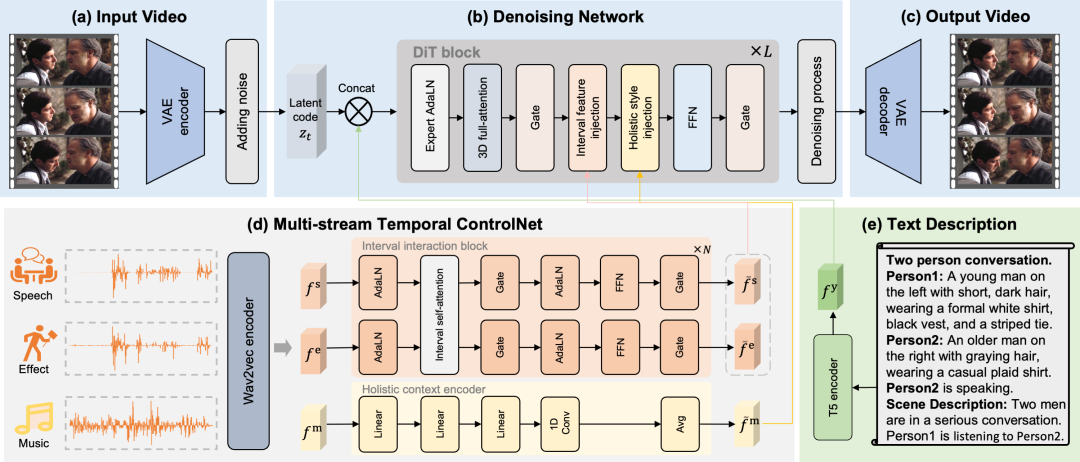
This article explicitly divides audio into three distinct control tracks: speech, sound effects, and music.These distinct tracks enable the MTV framework to precisely control lip movements, event timing, and visual emotion, resolving the problem of ambiguous mapping. To make the MTV framework compatible with various tasks, this paper creates a template to construct the text description. This template begins with a sentence indicating the number of participants, such as "Two person conversation." It then lists each person, starting with a unique identifier (Person1, Person2) and briefly describing their appearance. After listing the participants, the template explicitly identifies the person currently speaking. Finally, a sentence provides an overall description of the scene. To achieve precise time alignment, this paper proposes a multi-stream time control network that controls lip movements, event timing, and visual emotion through explicitly separated speech, effects, and musical tracks.
Interval feature injection
Regarding voice and sound effects featuresThis paper designs interval flow to accurately control lip movements and event timing.The features of each audio track are extracted by the interval interaction module, and the interaction between speech and sound effects is simulated by the self-attention mechanism. Finally, the interactive speech and sound effect features are injected into each time interval by cross attention, which is called the interval feature injection mechanism.
Global Feature Injection
Regarding musical characteristics,This paper designs an overall flow to control the visual emotion of the entire video segment.Since musical features are an expression of overall aesthetics, the overall visual emotion is first extracted from the music through a global context encoder, and average pooling is applied to obtain the global features of the entire segment. Finally, the global features are used as embeddings, and the video latent code is modulated through AdaLN, which is called the global feature injection mechanism.
Accurately generate cinematic-quality audio-synchronized video.
Comprehensive evaluation indicators
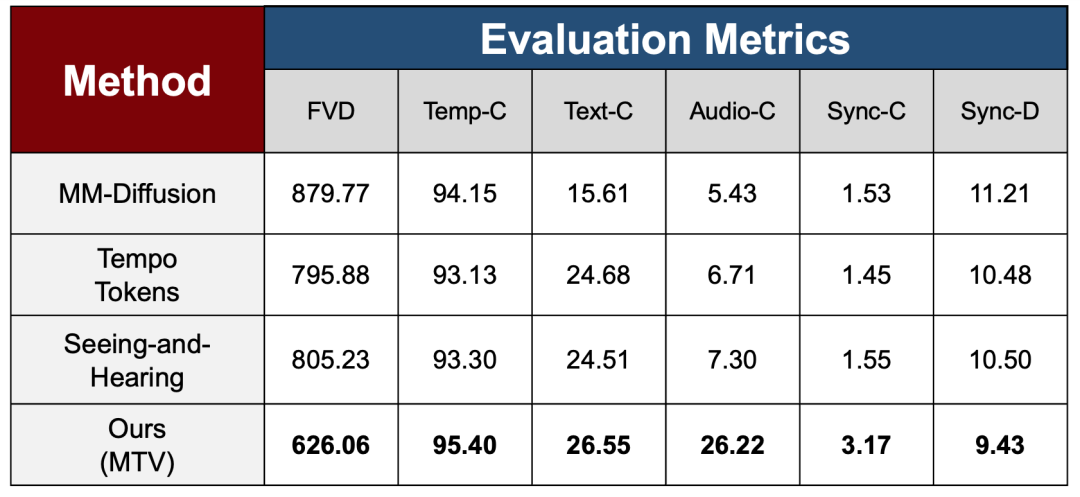
To verify the effectiveness of the multi-stage training strategy in different learning stages, the paper uses a set of comprehensive evaluation metrics covering video quality, temporal consistency, and multimodal alignment capability in the experimental section to systematically evaluate the overall stability and consistency performance of the model after gradually introducing complex control signals, and compares it with three state-of-the-art methods.
Regarding generation quality and temporal stability, the study uses FVD to measure the difference in distribution between generated and real videos, and uses Temp-C to evaluate the temporal continuity between adjacent frames. The results show that MTV significantly outperforms existing methods on FVD, indicating that the model does not sacrifice overall generation quality while maintaining high temporal stability on Temp-C, even with the introduction of more complex audio control.
At the multimodal alignment level, the study measures the consistency between video and text/audio using Text-C and Audio-C metrics, respectively. MTV showed a significant improvement in the Audio-C metric, far exceeding the comparison methods, reflecting the effectiveness of audio demixing and multi-stream control mechanisms in strengthening the audio-visual correspondence.
To address key issues in voice-driven scenarios, this paper introduces two synchronization metrics, Sync-C and Sync-D, to evaluate synchronization confidence and error magnitude, respectively, and achieves optimal performance.
Comparison results

As shown in the figure above, researchers compared the MTV framework with current state-of-the-art (SOTA) results. From a visual perspective, existing methods generally suffer from insufficient stability when handling complex text descriptions or cinematic scenes.
For example, even after fine-tuning MM-Diffusion over 320,000 steps on eight NVIDIA A100 GPUs using the official code, it still struggles to generate visually coherent and narrative-structured images, with the overall style leaning towards splicing fragments. TempoTokens, on the other hand, is prone to producing unnatural facial expressions and movements in complex scenes, especially in multi-person or high-dynamic-range scenarios, significantly impacting the realism of the generated results. Regarding audio-visual synchronization, Xing et al.'s method struggles to achieve audio synchronization for specific event sequences, leading to rendering errors in character gestures during guitar playing (as shown on the right side of the image above).
In contrast, the MTV framework can maintain high visual quality and stable audio-visual synchronization in various scenarios, and can accurately generate audio-synchronized videos with cinematic quality.
Reference Links:
1.https://arxiv.org/abs/2506.08003








