Command Palette
Search for a command to run...
Online Tutorial: How Does Shiji Niangniang Instantly Become a "Sichuan and Chongqing Girl"? Step-Audio-TTS Realizes Voice cloning/music synthesis/speech Synthesis in One

The global enthusiasm caused by DeepSeek open source is still there. Recently, Step Star and Geely Auto Group have once again made a move and open-sourced the Step-Audio-TTS-3B model, which has once again triggered widespread discussion in the industry.
once Upon a time,The diversity and complexity of dialect data and the high demand for model generalization make the voice cloning model perform poorly on dialects.Step-Audio-TTS-3B can vividly interpret the characteristics of local languages. It is trained based on the large-scale synthetic data set of the LLM-Chat paradigm, deeply understands the structure of the language, and grasps the subtle changes of the language from the lines. Whether it is the passionate Sichuan dialect or the nine-tone and six-tone Cantonese, it can accurately grasp its rhythm and tone, showing the strong local customs.
Not only that, it is also the first TTS model to realize RAP and humming generation, filling the gap in music speech synthesis. In the past, creating a rhythmic RAP content required professional singers. But now, with the help of Step-Audio-TTS-3B, users can quickly generate a RAP vocal with precise rhythm and smooth flow, inspiring unlimited possibilities.
Currently, the "Step-Audio-TTS-3B production-level dialect speech generation model" has been launched in the "Tutorial" section of HyperAI's official website.This tutorial includes three functions: speech synthesis, music synthesis, and voice cloning. Come and experience it yourself~
Tutorial address:
Demo Run
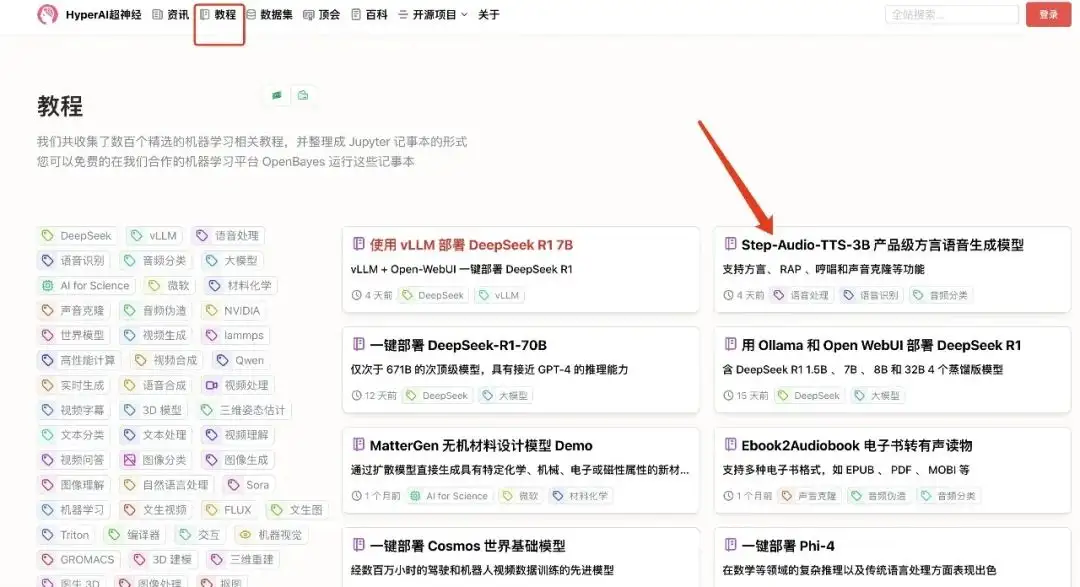
1. Log in to hyper.ai, on the Tutorial page, select Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model, and click Run this tutorial online.
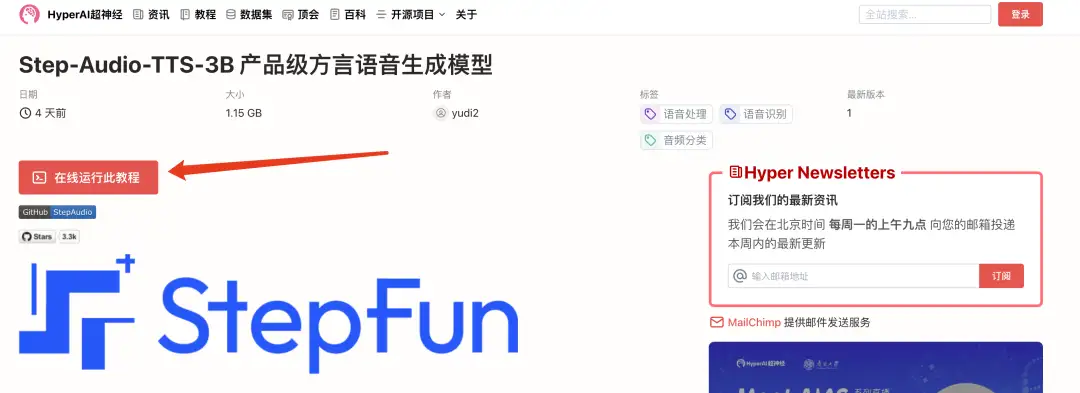
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
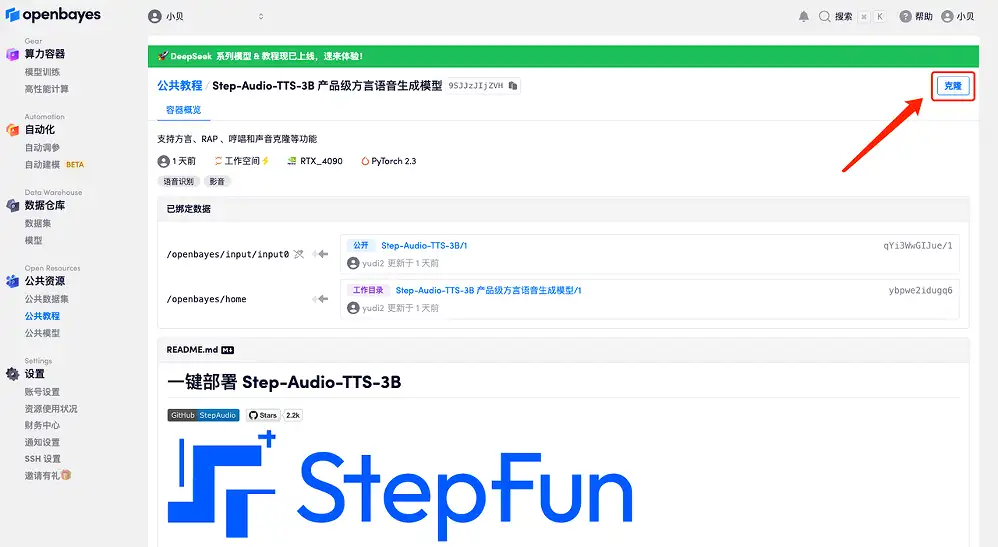
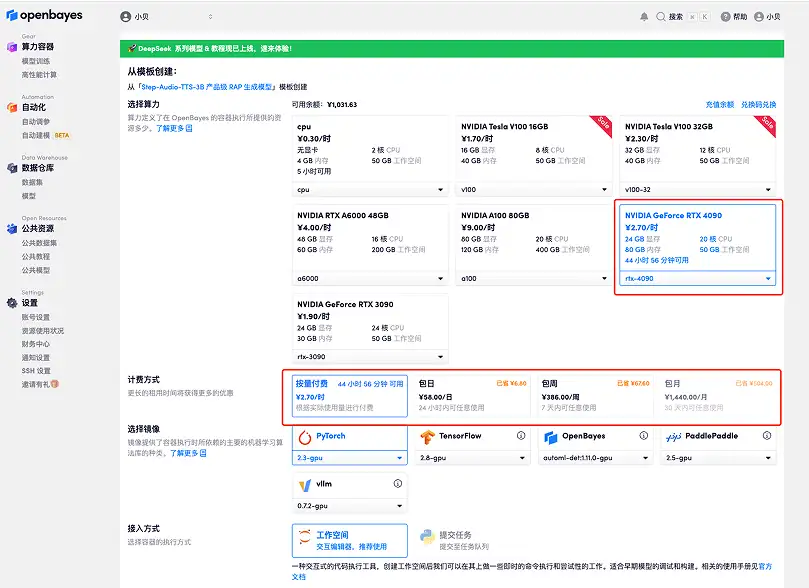
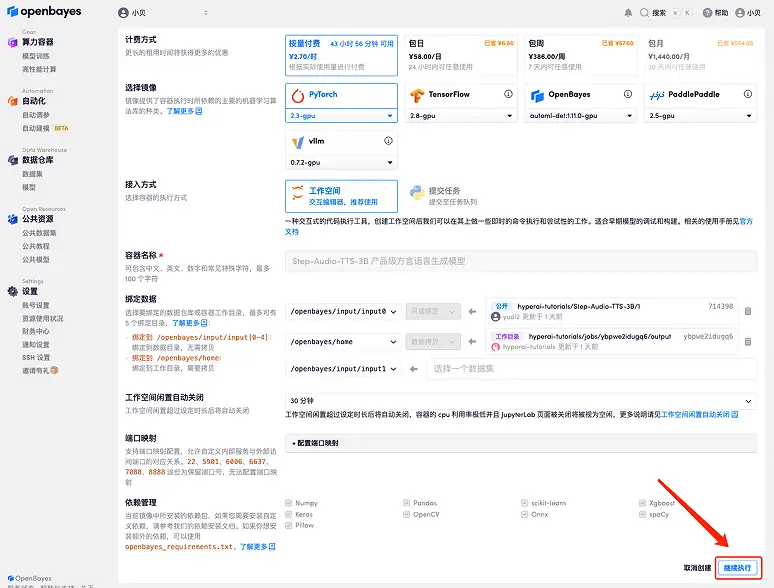
3. Select "NVIDIA RTX A6000" and "PyTorch" images. The OpenBayes platform has launched a new billing method. You can choose "pay as you go" or "daily/weekly/monthly" according to your needs. Click "Continue". New users can register using the invitation link below to get 4 hours of RTX 4090 + 5 hours of CPU free time!
HyperAI exclusive invitation link (copy and open in browser):
https://openbayes.com/console/signup?r=Ada0322_QZy7
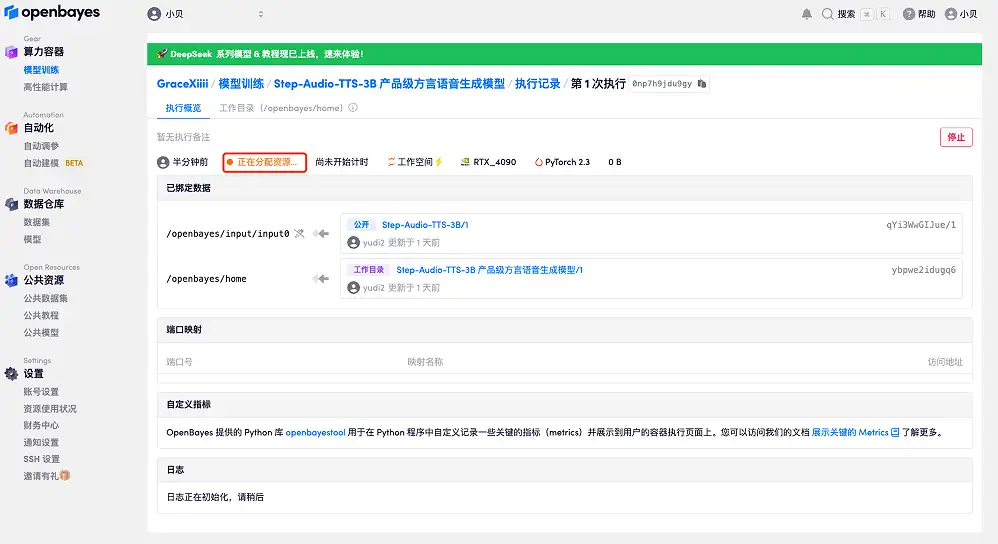
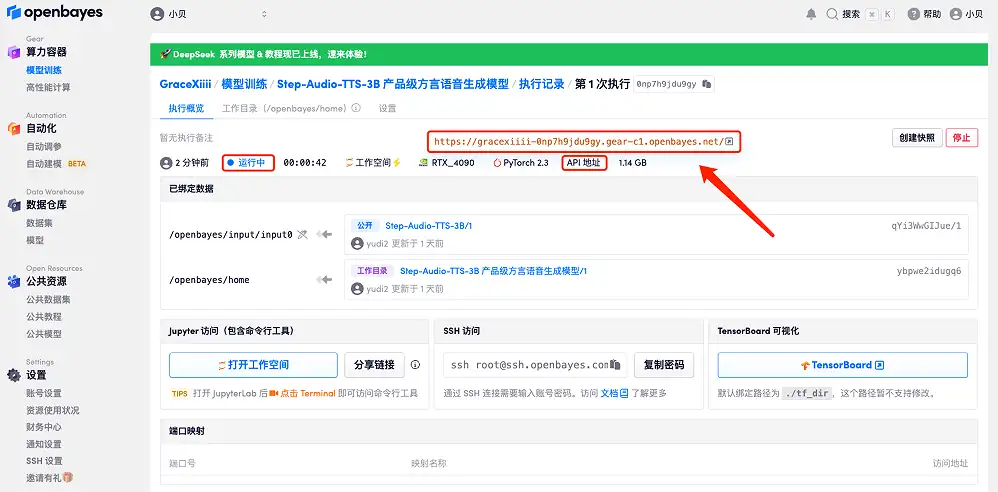
4. Wait for resources to be allocated. The first clone will take about 2 minutes. When the status changes to "Running", click the jump arrow next to "API Address" to jump to the Demo page. Please note that users must complete real-name authentication before using the API address access function.

Effect display
This tutorial includes three functions: general speech synthesis, music synthesis and speech cloning.
1. General speech synthesis
This feature presets the official default voice character Tingting and the newly added voice Nezha, and supports multi-language generation, emotions, dialects and other settings.
Speech synthesis tone description
* The sound Tingting is generated by the official 4s audio prompt file
* The sound of Nezha is generated from the 14s audio prompt "I am Nezha the Third Prince, I am uninhibited and love to write poetry, I walk with my hands in my pockets, and I can make a curved road straight" file
On the Demo page, select "Normal Speech Synthesis", enter text, select the speaker (default is Tingting), select the emotion (happy, angry, sad and coquettish), select the language/dialect (Chinese, English, Japanese, Mandarin, Sichuanese, Cantonese and Guangdong dialect), select the speaking speed (fast or slow). Click "Generate Speech".
2. Music Synthesis
This function presets the official website's default voice character Tingting and the newly added Nezha timbre, and supports RAP and humming.
RAP Sound Description
* The sound Tingting is generated by the official 11s audio prompt file
* The sound of Nezha is generated by the 14s audio prompt "I am so scared of the thunder rolling in the sky, it strikes me all over, I blow the trumpet to change my fate, I laugh to get through the calamity, tick-tick-tick-tick-tick" file
Humming Tone Description
* The sound Tingting is generated by a 12s audio prompt file
* The sound of Nezha is generated by the 14s audio prompt "I am born fearless, no matter who is my father or whoever, if the master takes out the ruler, he will never be able to command me" file
Select "Music Synthesis" on the Demo page, enter the text, select the speaker (default is Tingting), select the mode (RAP or Humming), and click "Generate RAP / Humming".

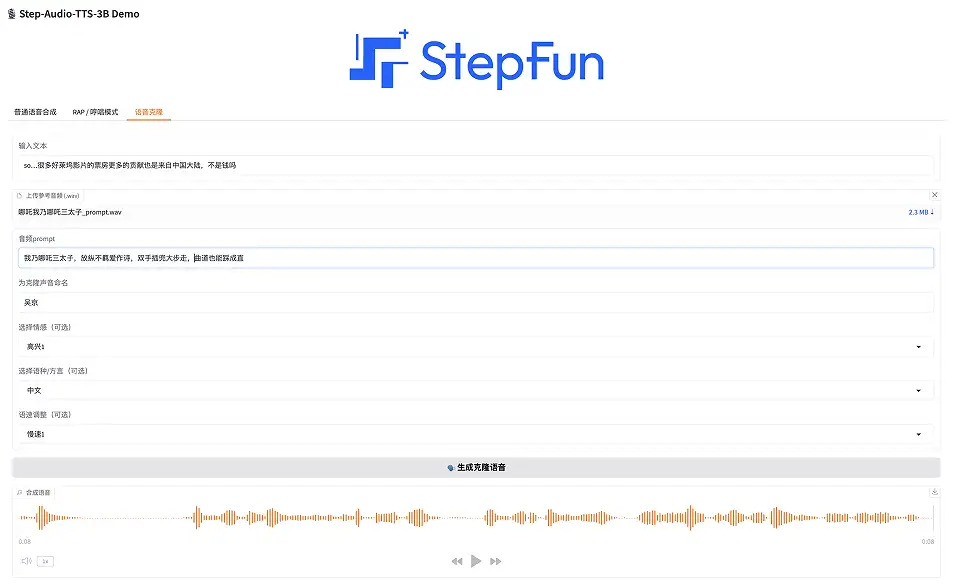
3. Voice cloning
This function supports users to upload custom-timbre audio and generate personalized voice.
Select "Voice Cloning" on the Demo page, enter text, upload reference audio (.wav format), name the cloned voice, select emotion (happy, angry, sad and coquettish), select language/dialect (Chinese, English, Japanese, Mandarin, Sichuanese, Cantonese and Guangdong dialect), select speech speed (fast or slow). Click "Generate Clone Voice".