Command Palette
Search for a command to run...
Collecting More Than 20 Spatiotemporal Data Sets and More Than 130 Million Sample Points, the Tsinghua Research Team Proposed Three Urban Complex System Modeling Methods Based on Generative AI

Michael Batty, known as one of the pioneers in the study of urban complex systems, once said in his book:"Cities are essentially complex adaptive systems whose structures and functions are constantly evolving and exhibit highly nonlinear and self-organizing characteristics."With the continuous development of modern cities, the complexity of urban systems is increasing.
This complexity makes it difficult for traditional modeling methods to cope with it. With the development of generative AI technology, generative modeling, as an emerging technical means, is gradually becoming an important tool for studying and understanding urban systems. Generative models of complex urban systems can not only simulate the evolution of urban structures, but also generate innovative urban planning schemes, providing new ideas for smart cities and sustainable development.
Focusing on the domestic situation, research on generative models of urban complex systems has made significant progress in recent years, and many universities and research institutes have achieved fruitful research results.
Recently, at the COSCon'24 AI for Science forum jointly produced by HyperAI,Ding Jingtao, a postdoctoral researcher from the Center for Urban Science and Computational Research, Department of Electronic Engineering, Tsinghua University, gave a speech titled "AI-driven modeling and law discovery of urban complex systems".We gave an in-depth explanation of the spatiotemporal generative modeling method for complex urban systems and the team’s latest research progress.
HyperAI has compiled and summarized Dr. Ding Jingtao’s in-depth sharing without violating the original intention. The following is the transcript of the speech.
Focus on generative modeling of urban complex systems and discover data distribution patterns
Our team's research in the field of smart cities and urban computing focuses on the modeling of complex urban systems.As a complex system, the city is similar to the operation of nature in an ecosystem. Humans living in it interact with the urban system in multiple dimensions, forming complex interactions. For example, in the process of urban construction, a variety of network systems such as transportation network, communication network, and power supply network are formed. The network elements at the physical level are intertwined with the social elements of human life, further exacerbating the complexity of the urban system.

In response to this, our team's research mainly focuses on the following three types of issues:
(1) The problem of predicting the evolution of urban states,That is, we should focus on the direction and process of the future development of the city, because urban development is essentially a dynamic process of spatiotemporal change, which is a typical spatiotemporal prediction problem;
(2) Simulation and deduction of urban elements,Similar to the concept of digital twins or metaverse, a digital environment is constructed through real data and deduced based on it to solve the "what if" problems in hypothetical scenarios;
(3) Urban governance decision-making optimization problem,Based on the aforementioned urban evolution predictions and simulations, urban governance decisions can be optimized to solve specific urban problems such as traffic congestion and natural disasters.
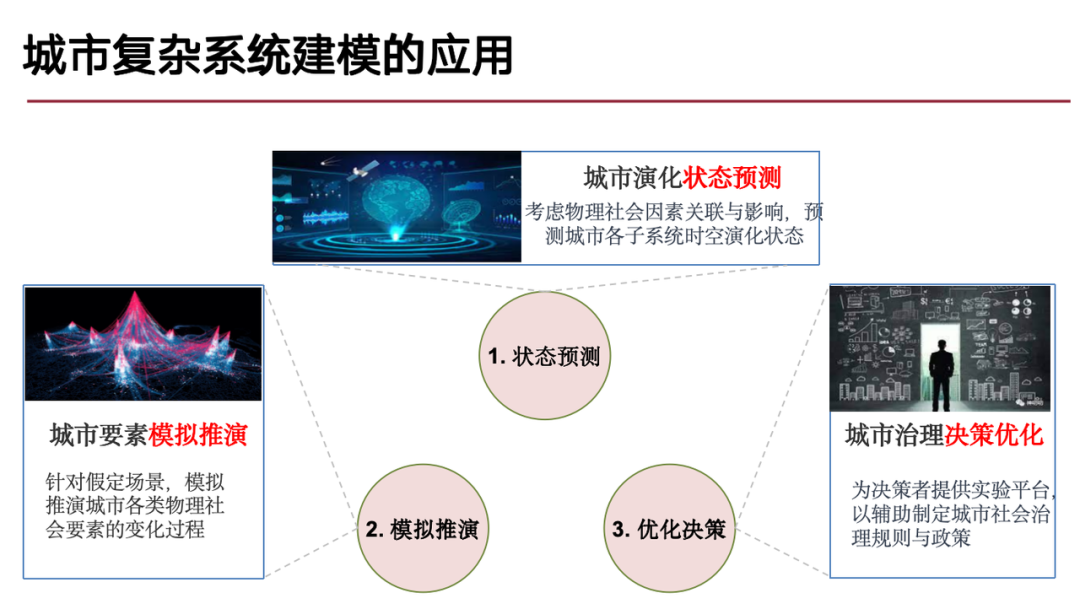
Our team’s current research focus is on generative modeling of complex urban systems.The core of the generative model is to learn the probability distribution behind the data, that is, to model the probability distribution based on the observed data and capture the generation process of the data.If the model has this capability, it can effectively solve the above three types of problems.
Introducing generative AI methods to solve modeling challenges
Generative AI is currently developing rapidly, mainly in two aspects: one is the development of language generation technology represented by large language models, and the other is the progress of visual content generation technology represented by diffusion models.Whether the generative AI method is applicable to the modeling of complex urban systems becomes the key of our research.
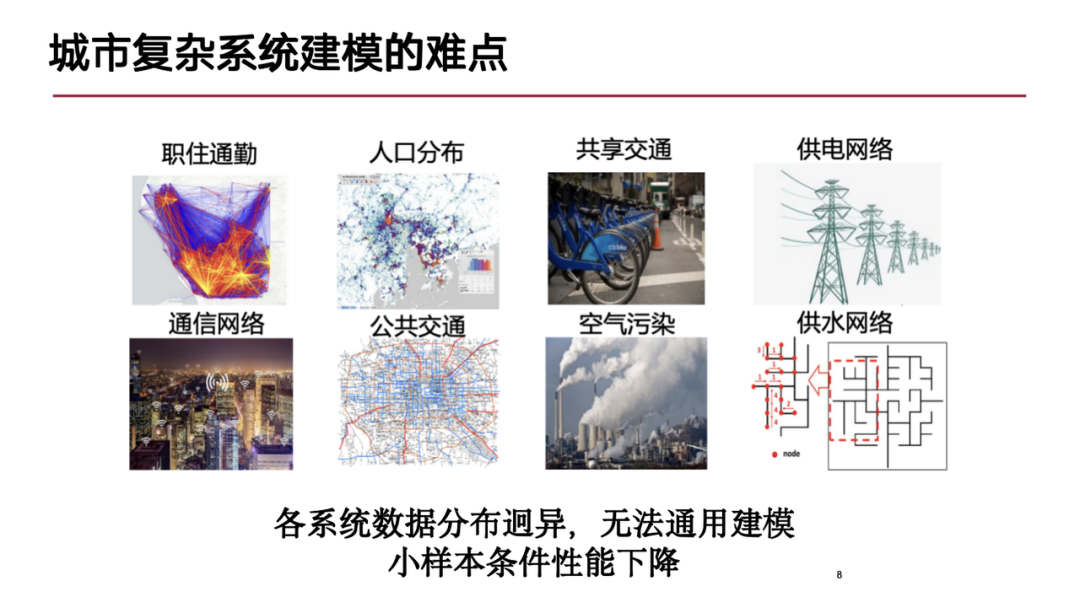
In urban complex systems, the difficulties in modeling are mainly reflected in the following aspects:noodle:First, urban complex systems have significant spatiotemporal characteristics, and the data modalities are very rich, including multiple spatiotemporal data forms, such as trajectory data of people moving in the city, which is similar to sequence data in natural language; in addition, there are spatiotemporal grid data used to prevent stampede accidents and topological structures in the city (such as the graph structure formed by roads and speed coils), etc. The mixture of these spatiotemporal data of different modalities brings modeling challenges.

Secondly, from the perspective of urban complex systems, a city is a giant system composed of multiple subsystems. These subsystems have complex interactions within them, and there is a certain degree of coupling between different subsystems (such as power systems and communication network systems). The interdependence and complex interactions of these subsystems put forward higher requirements for modeling.

Finally, the urban system is a dynamic process. Different subsystems can collect a variety of data, and these data have different forms, modes and distributions, which makes it difficult to model universally. This is also a problem that is difficult to overcome in the current research stage.
Based on the above challenges, today I will introduce our research progress in the following three areas:The first is the simulation of people flow.We propose a diffusion model guided by physics knowledge to more accurately deduce the movement of people in cities;The second is the prediction of resilience of complex systems; and the last is the general space-time prediction model.
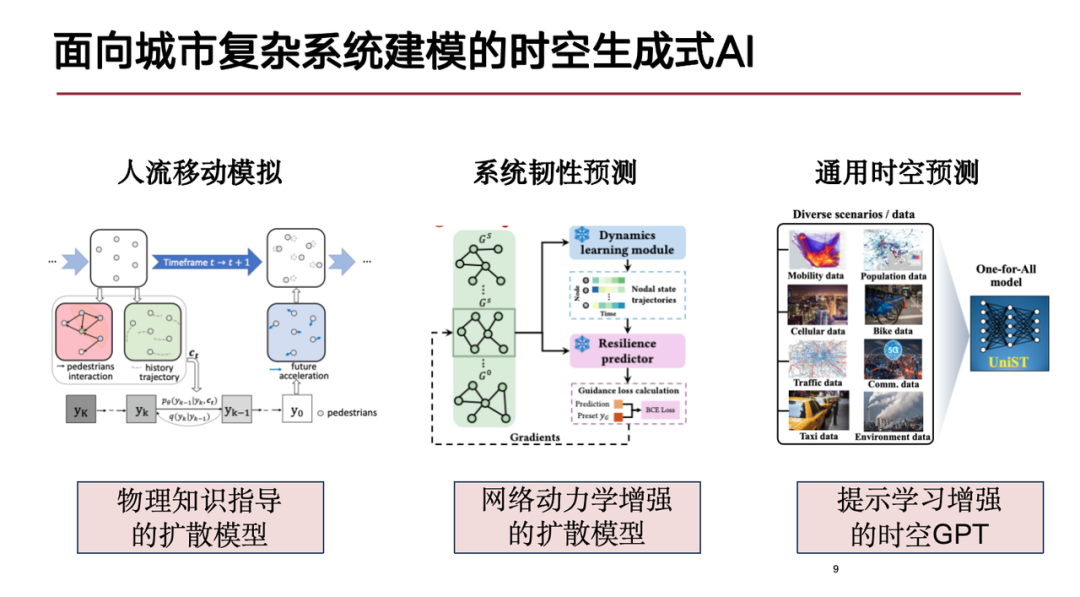
Simulating Crowd Movement—Diffusion Model Guided by Physics Knowledge
The purpose of pedestrian flow simulation is to reproduce the dynamic movement and interaction process of a large number of pedestrians in space. The core problem is: given the starting and ending points of pedestrians or individuals, generate their trajectories during the movement process.This simulation is of great value in many application scenarios, such as path planning for virtual characters (NPCs) in games and feasibility analysis of building designs in real life. In order to test the performance of architectural designs in specific scenarios, it is usually necessary to simulate large-scale pedestrian flows.

However, the main challenge of human flow simulation is that the simulation object is not a molecular system with clear physical laws, but an individual with autonomous decision-making capabilities - humans.The decision-making mechanism of human beings is complex and changeable: on the one hand, individual preferences are affected by the surrounding environment, leading to constant adjustment of their decisions; on the other hand, human behavior has inherent uncertainty. For example, when faced with an obstacle, different individuals will choose different coping strategies (some choose to go left, some choose to go right), and this uncertainty is difficult to describe with a deterministic formula.
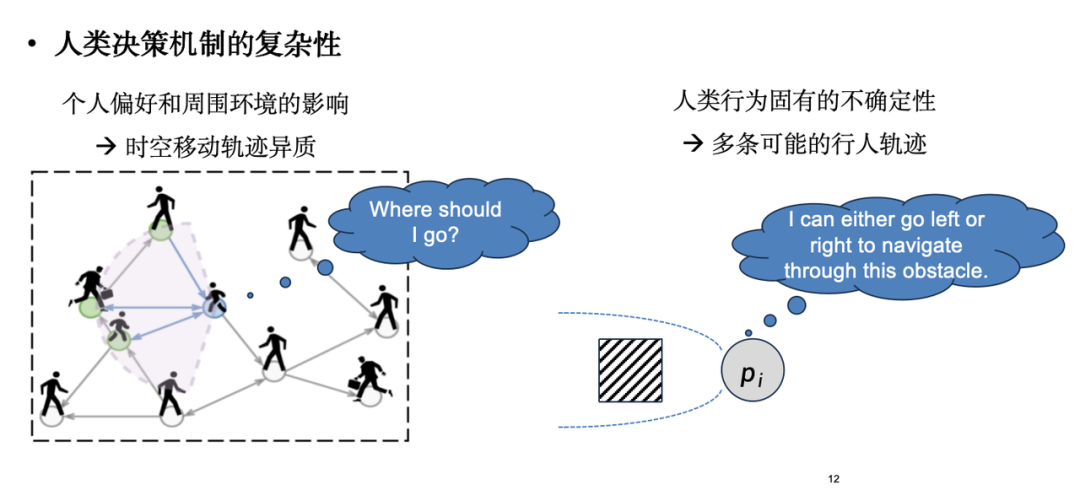
In practical applications, the most widely used crowd flow simulation model is the "social force model", which originates from the ideas in Newtonian mechanics and is one of the classic methods based on ABM (Agent-Based Modeling).The social force model considers human movement as a force-driven process. As shown in the figure below, individuals are not only attracted by the destination, but also repelled by obstacles and pedestrians around them. However, further observation shows that the social force model is insufficient in capturing the subtle features in real data.

Therefore, we explore how to combine generative AI techniques,Infusing physics knowledge into diffusion models.The reason for choosing the diffusion model is that the human decision-making mechanism is inherently uncertain and is a probability generation process. The diffusion model performs well in modeling high-dimensional data distribution and is suitable for simulating such uncertainty problems.
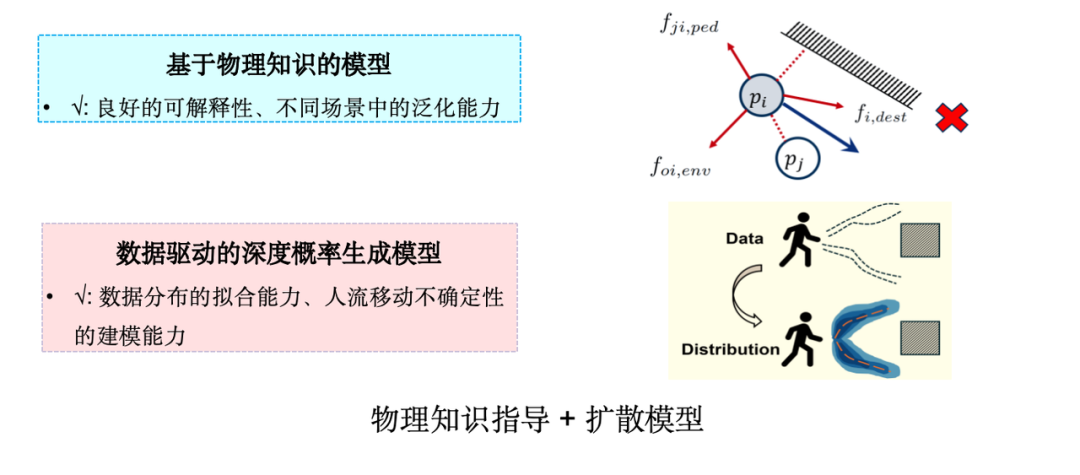
We designed a graph neural network based on the social force model, incorporated the attraction and repulsion terms in the social force into the model, and proposed a pedestrian flow simulation model SPDiff.
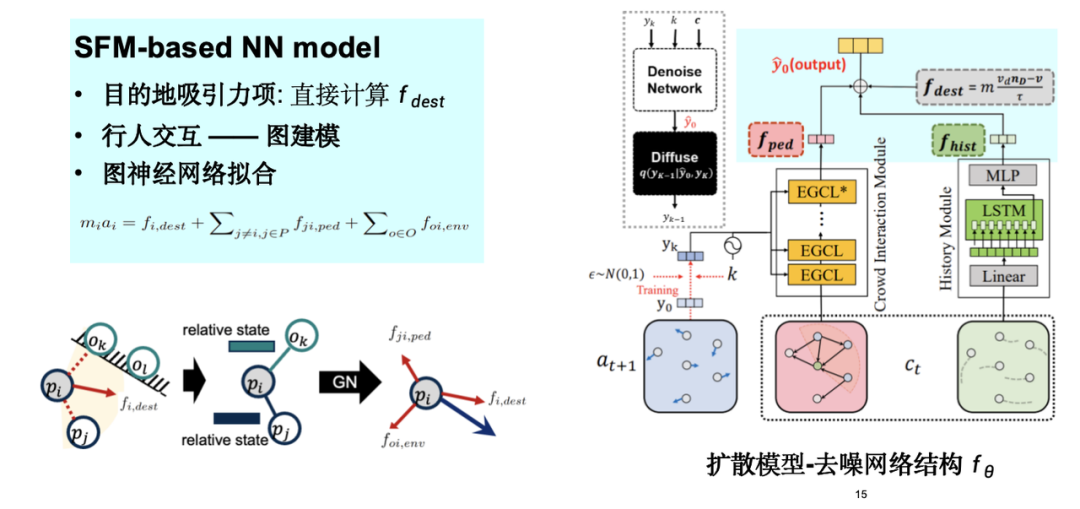
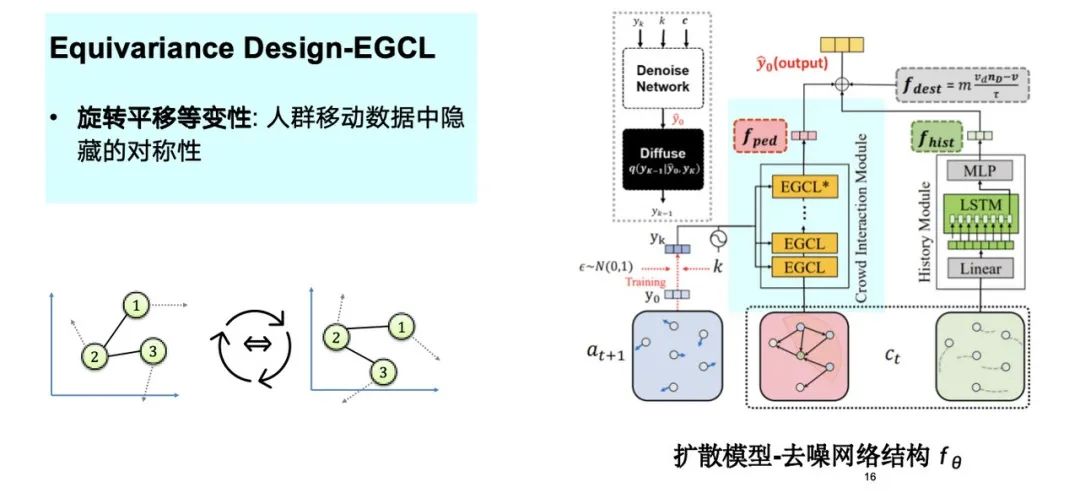
As shown in the figure below, we considered the hidden symmetries in crowd movement data, such as rotation and translation, and incorporated them into the model design process. The injection of this inductive bias helps optimize the entire simulation process.
We selected a dataset of real pedestrian movement to evaluate the model performance. The data source includes monitoring data of pedestrian movement in station squares and streets.
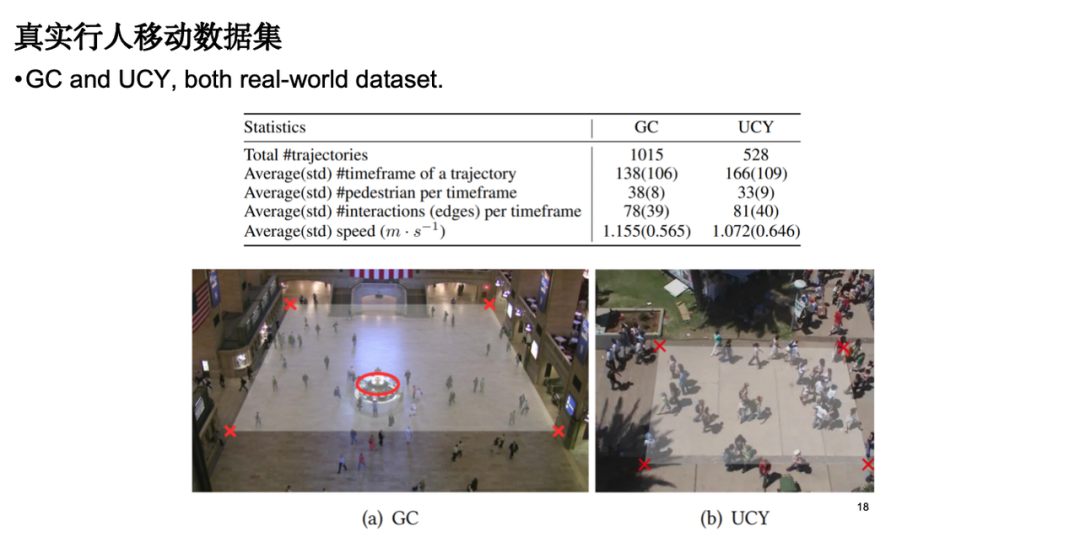
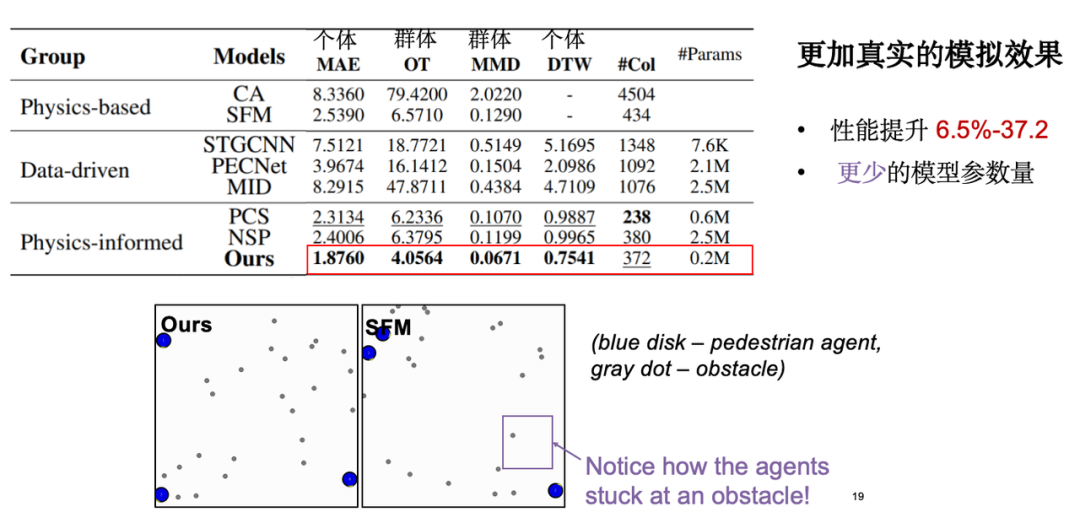
The following indicators are mainly concerned in model evaluation:The first is the individual movement error, that is, the absolute error between the simulated trajectory and the real observed trajectory; the second is the group distribution index, that is, we hope that the simulated trajectory is close to the real data at the distribution level. In addition, we also conducted a visualization analysis, and the results showed that compared with the classical social force model, our model performs more reasonably in terms of obstacle avoidance. It is worth mentioning that when we introduced physical knowledge, the number of model parameters was significantly reduced, which optimized the model efficiency.
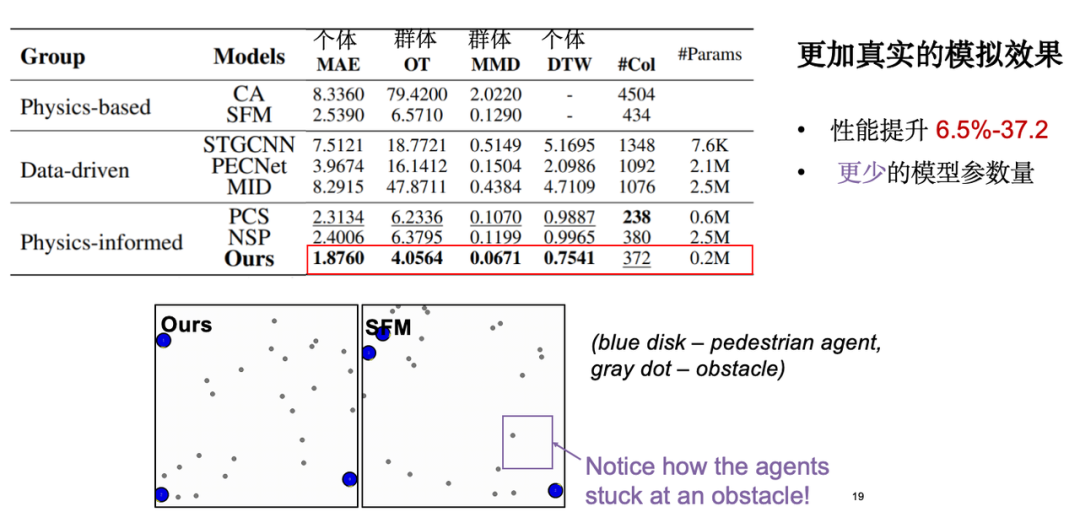
When we further explore the introduction of physical knowledge, we find that equivariance gives the model an advantage in small sample learning. As mentioned earlier, the moving trajectory is essentially symmetrical after rotation and translation.Therefore, the model only needs a small number of data samples to complete effective learning.Experiments show that when the amount of training data is reduced to 5%, the model effect is still close to the performance of the complete dataset.
The related research was titled "Social Physics Informed Diffusion Model for Crowd Simulation" and "Understanding and Modeling Collision Avoidance Behavior for Realistic Crowd Simulation", published in AAAI 2024 and CIKM 2023 respectively, and the code and data were open sourced.
Paper address:https://arxiv.org/abs/2402.06680
Open source project address:https://github.com/tsinghua-fib-lab/SPDiff
Paper address:https://dl.acm.org/doi/10.1145/3583780.3615098
Open source project address:https://github.com/tsinghua-fib-lab/TECRL
Predicting system resilience: a diffusion model enhanced by network dynamics
Resilience refers to the ability of a system to maintain its basic system functions when subjected to internal failures or external disturbances.For example, for ecosystems, resilience refers to the ability to maintain biodiversity under the influence of environmental changes. In human social systems, we hope that many engineering systems, such as supply chain networks, have such resilience to ensure the normal production and sales relationship between producers and consumers under special circumstances, thereby maintaining the normal operation of the economy.

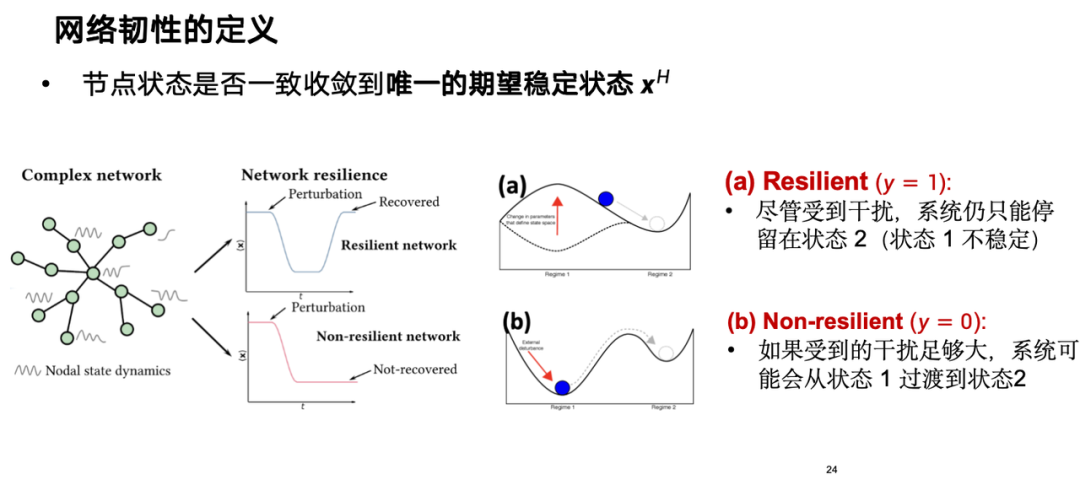
From a theoretical perspective, network resilience has some classic definitions. Resilience can be regarded as a node state, represented by x, which reflects whether the system can converge to the only expected stable state after a perturbation is applied to a node.If a system is resilient, it can still return to its expected state within a certain period of time even if it is disturbed; if it lacks resilience, it will be difficult to recover. As shown in the figure below, a resilient system can return to a stable state after a disturbance, while a non-resilient system may not be able to recover.
As early as 2017, an article in Nature proposed a theoretical modeling method, which is essentially to study an n-dimensional high-dimensional system. The number of nodes in such a system may reach tens of thousands or even millions.In theory, this method simplifies a high-dimensional system into one dimension through dimensionality reduction in order to obtain an expression for the system's resilience.
However, this theoretical tool has limitations in real systems and is only applicable to systems with uncorrelated degrees. However, real systems often have the same-matching effect, that is, the degree values of two nodes connected by an edge may be highly correlated. Therefore, this tool still has some problems in evaluating the resilience of actual systems.
Paper address:https://www.nature.com/articles/nature16948
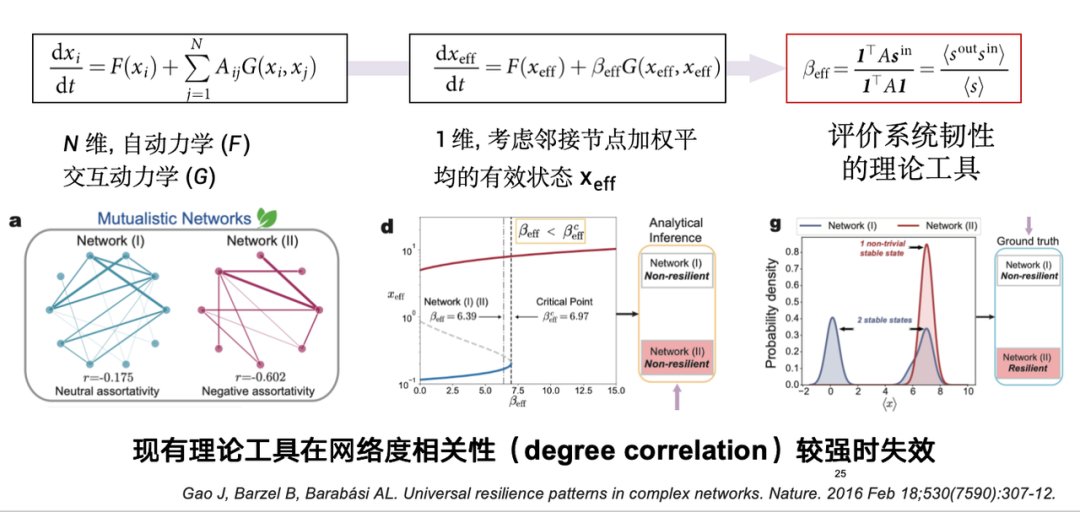
Based on this, our team proposed a data-driven network system resilience modeling method.As mentioned before, resilience is affected by the combined effects of node state evolution and network topology. Through data-driven or machine learning modeling, we divide the problem into two dimensions. On the one hand, the dynamic change process of node state is characterized by the state evolution trajectory; on the other hand, the influence of network topology must also be considered. The two work together to create the resilience of complex systems. Based on this, we design a data-driven resilience prediction model.
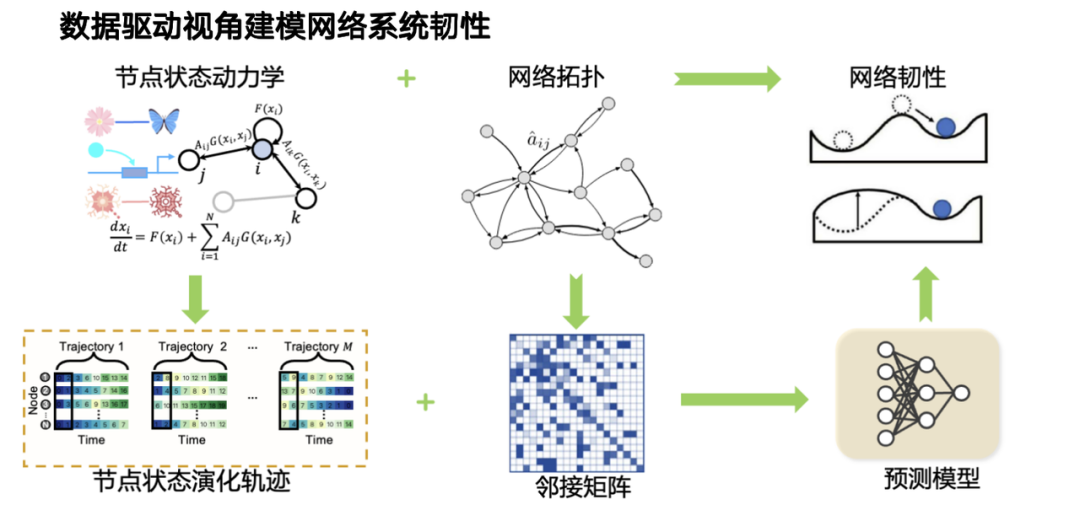
In terms of model architecture, we designed a structure that combines graph neural networks and Transformer:For the dynamic evolution part, we use Transformer to model the temporal relationship; for the complex topological relationship, we introduce graph neural network to model the high-order interaction between systems. The synergy of the two constitutes our observation of the resilience of the system.
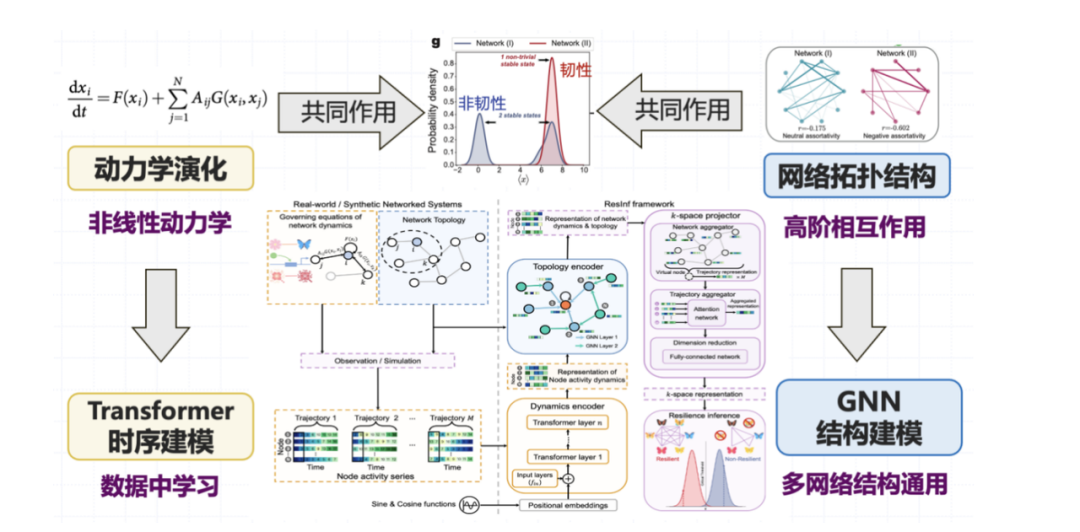
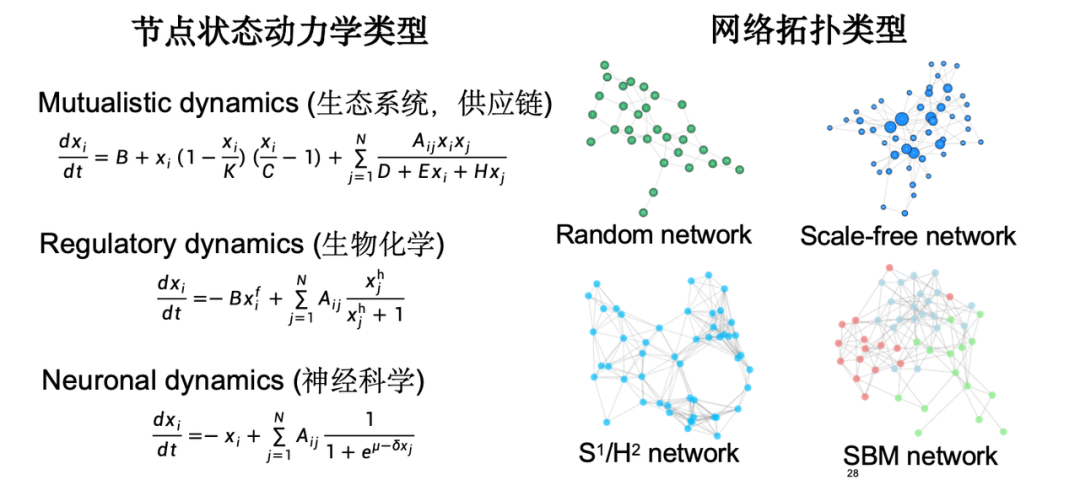
In the experiment, we considered various types of node state dynamics, such as ecosystem supply chain, gene regulation dynamics in biochemistry, neural signal transmission dynamics in neuroscience, etc.; in terms of topology, we chose the classic network topology type.
Experimental results show that our model has significantly improved prediction accuracy, a high F1 score, and a certain degree of interpretability, and realizes dimensionality reduction visualization of the decision plane.
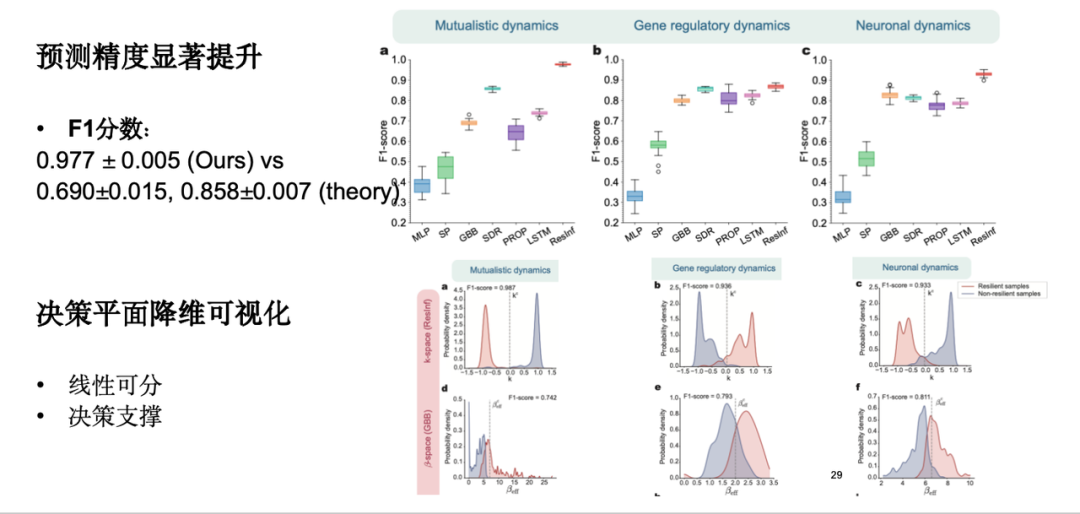
However, in practical applications, we found that the resilience of most systems is unknown, and it is difficult to determine whether they are resilient, resulting in insufficient resilience label data and biased model predictions. To this end, we enhance the model at the sample level to make it more robust in the case of small samples.
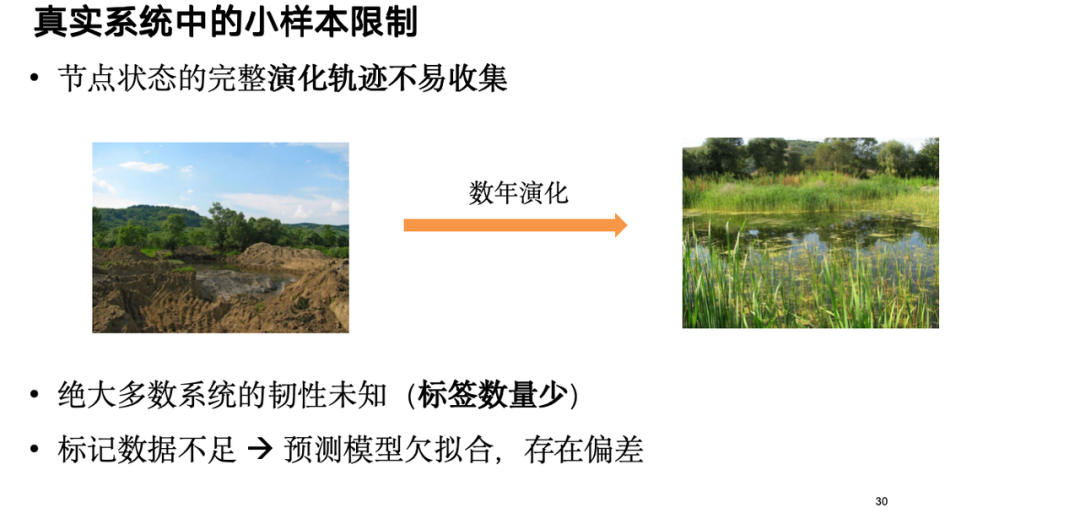
The specific strategy is to generate observation samples of resilient and non-resilient systems based on the diffusion model to enhance the prediction model. These samples cover the node topology and its state evolution trajectory. First, data enhancement is performed. The enhanced samples can better train the resilience prediction module, and the prediction results reversely guide the data enhancement module to generate more valuable samples, forming a positive feedback loop.
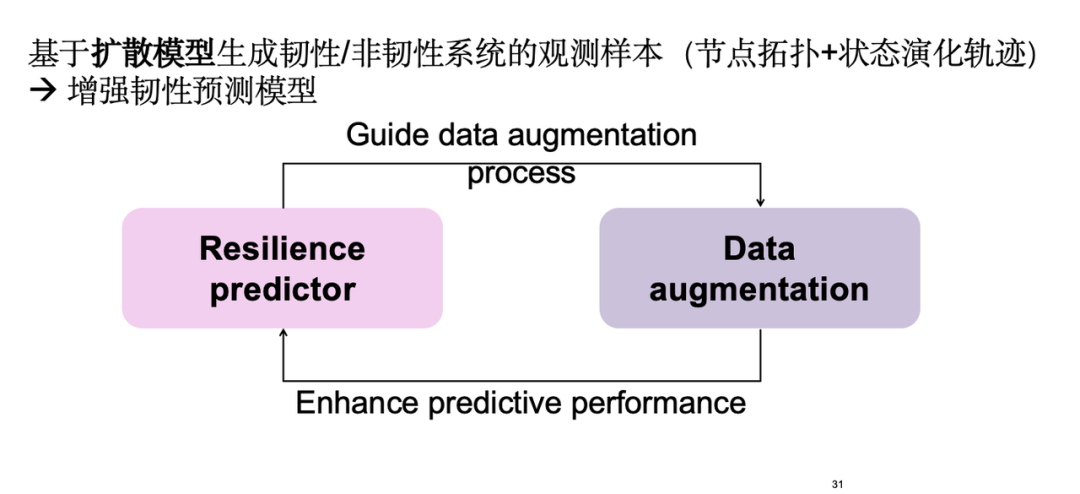
By leveraging the controllable generative capabilities of the diffusion model, namely the classifier-guidance technique, we generate samples with the desired level of resilience, thereby achieving data augmentation.
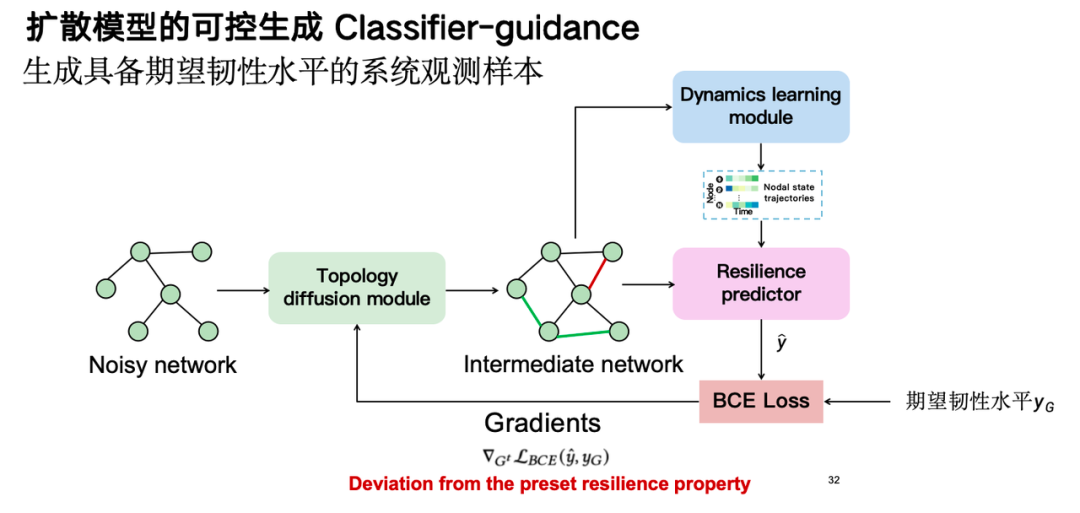
The small sample test results show that after the diffusion model enhancement, the model prediction accuracy can reach 87% using only 20 samples;Without data enhancement, the model prediction accuracy is only 62%. It is worth mentioning that we can achieve similar prediction accuracy with a shorter state evolution trajectory observation length, which is of great significance for systems that cannot be observed for a long time in actual observations.

The related research was titled "Deep learning resilience inference for complex networked systems" and "TDNetGen: Empowering Complex Network Resilience Prediction with Generative Augmentation of Topology and Dynamics", published in Nature Communications and KDD 2024 respectively, and the code and data were open sourced.
Paper address:
https://www.nature.com/articles/s41467-024-53303-4
Open source project address:
https://github.com/tsinghua-fib-lab/ResInf
Paper address:
https://arxiv.org/abs/2408.09825
Open source project address:
https://github.com/tsinghua-fib-lab/TDNetGen
General Spatiotemporal Prediction - Prompt Learning Enhanced Spatiotemporal GPT
Since 2017, spatiotemporal prediction has gradually attracted attention in the field of deep learning. Current research methods are mainly divided into two categories: one is to design corresponding deep learning models based on the spatiotemporal characteristics of specific data types or sources; the other is to use dynamic system methods such as reservoir calculation to model from the perspective of complex systems or applied mathematics. The common point of these two methods is that they both model a single subsystem.
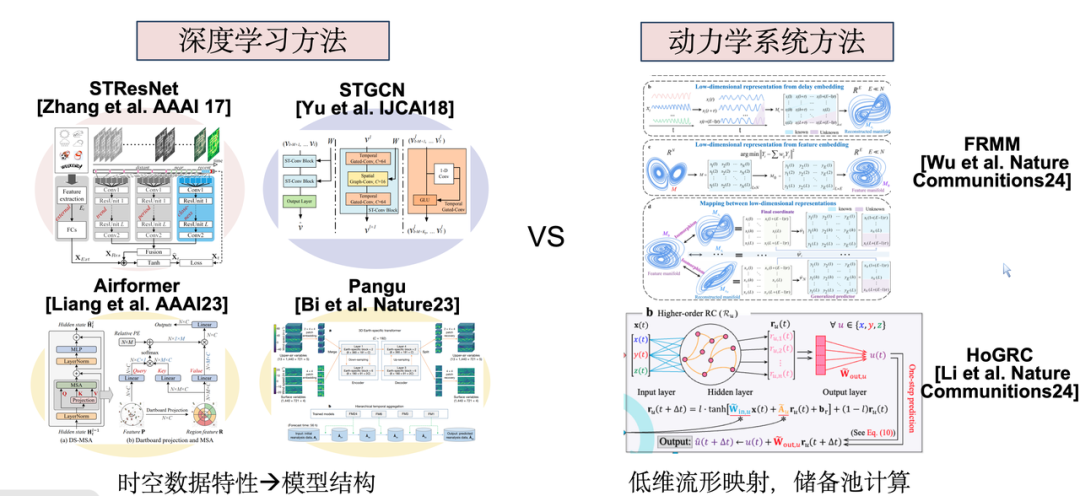
However, for urban systems, since there are high correlations between actual subsystems, we hope to achieve joint modeling in order to achieve a synergistic effect of 1 + 1 > 2. This is also the core goal of our research work.
In this framework, our conception is based on the following feasibility: although different types of spatiotemporal data vary in organization and distribution, they are essentially derived from human production and life in cities, and are the embodiment of some underlying universal mechanism in different dimensions. Therefore, as long as we can find the right method, we can integrate these heterogeneous data to achieve a synergistic effect of 1 + 1 > 2.
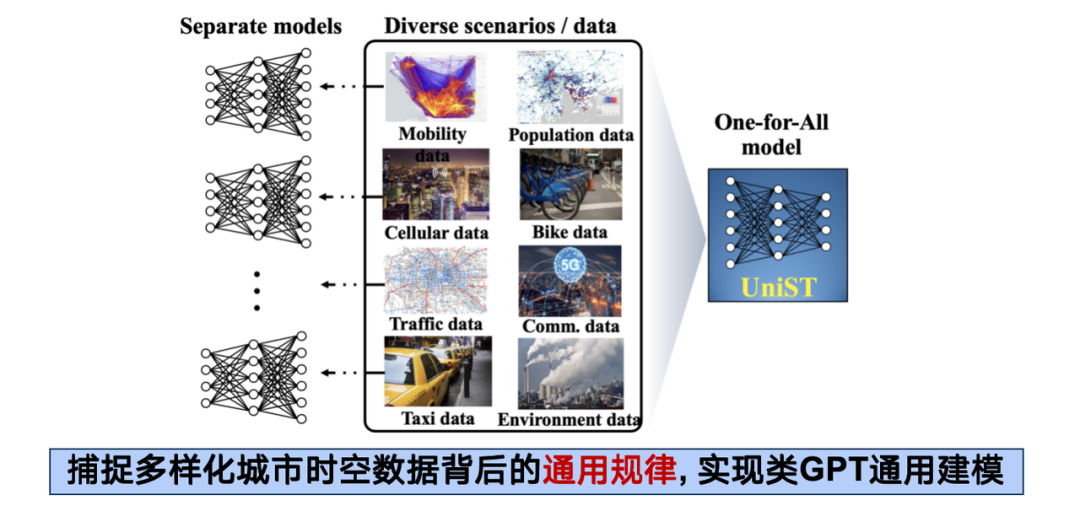
In actual operation, we have collected more than 20 spatiotemporal data sets and more than 130 million sample points, covering five subsystems such as transportation, cellular networks, and air pollution, and covering 14 cities at home and abroad.
In terms of model design, we continued the Transformer architecture, modeled various forms of spatiotemporal data as high-dimensional tensors, and processed them in a manner similar to ViT (Vision Transformer).Finally, the universal spatiotemporal prediction model UniST was formed.
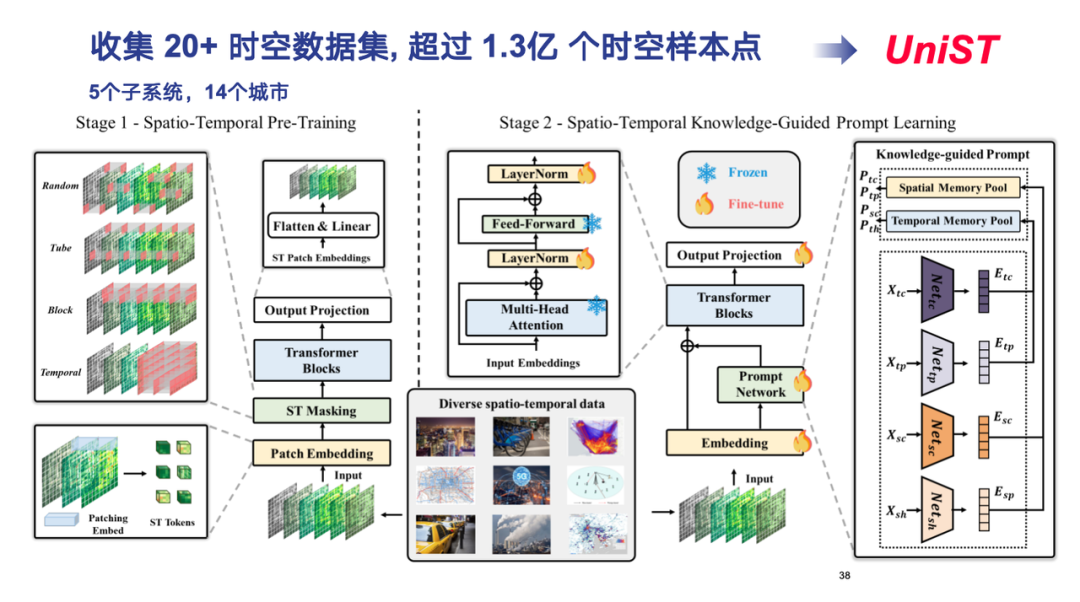
In the first stage of model training,We tokenize various types of spatiotemporal data, decompose high-dimensional tensors into small blocks, each of which corresponds to a token, and use different mask strategies to capture diverse spatiotemporal correlation characteristics.
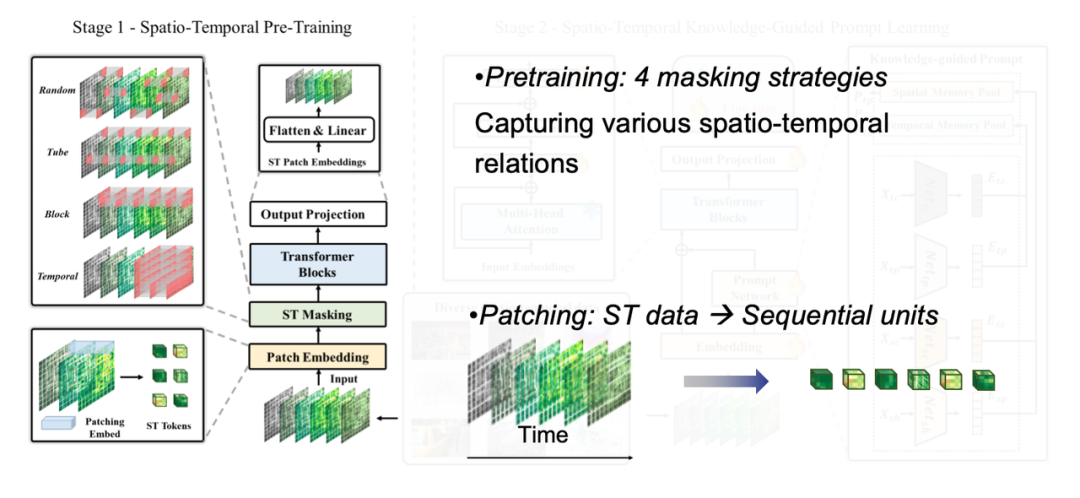
In the second stage of model training,We need to explore the common rules behind different forms of spatiotemporal data. The "knowledge" here refers to the classic evolution patterns that are prevalent in spatiotemporal data, such as temporal proximity, periodicity, and trend, as well as spatial proximity and hierarchy. By extracting this spatiotemporal domain knowledge and defining the corresponding patterns, we reduce the dimension of real data to several pattern spaces and pre-train on massive data. In this way, when processing new data, the model can quickly match the corresponding pattern and achieve accurate prediction of small samples or even zero samples in a similar way to RAG.

When evaluating the model's performance, we focus on two main tasks: first, long-term and short-term prediction capabilities; second, the most critical zero-shot capability, which is the model's ability to directly handle a task without having been exposed to a specific task or data.For example, if the model is trained based on a data set for Beijing, then for Shanghai data that is not included in the training, the model can still achieve accurate predictions based on Shanghai’s spatiotemporal series.
As shown in the figure below, the red dotted line represents the prediction effect of our method under zero-shot conditions, the red rectangle on the far left shows the prediction results of our method under 1%/5% sample conditions, and the others are baseline methods. It can be seen that our method is significantly better than the baseline method using 1%/5% samples in zero-shot transfer.
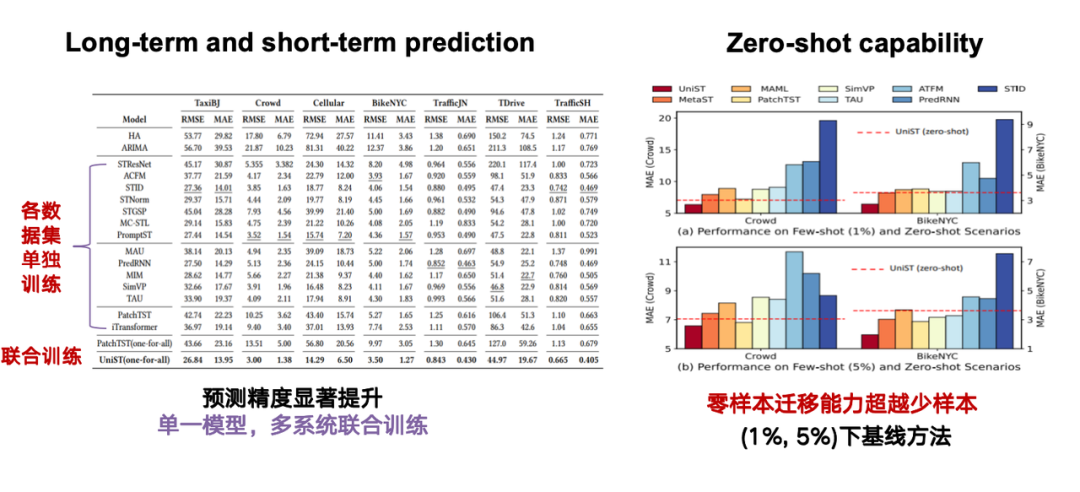
Why does this happen? By comparing the similarity of Beijing and Shanghai data in the figure, we can find that the data of Beijing Chang'an Avenue and Shanghai Jing'an District are very similar after Prompt calculation. This high similarity explains that the model can still form a similar prediction pattern based on Beijing data training without being trained on Shanghai data.

We also explored the performance of spatiotemporal data in terms of the scaling law, that is, whether increasing the amount of data will significantly improve the model capabilities. However, due to the limitations of the existing data volume and data types, we have not yet observed a clear scaling effect, and we need to further enrich the data types in this regard.

The related research, titled "UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction", was selected for KDD 2024.
Paper address:
https://arxiv.org/abs/2402.11838
Open source project address:
https://github.com/tsinghua-fib-lab/UniST
Guided by physical knowledge, new ideas are provided for modeling complex urban systems
Finally, I would like to discuss the future directions of urban complex system modeling and the latest progress of my team (Center for Urban Science and Computation, Department of Electronics, Tsinghua University).
We believe that physical knowledge can be further combined to improve the robustness and generalization ability of the model.For systems in cities where many mechanisms have not been fully explored, we can make comprehensive use of methods such as symbolic regression and network dynamics inference to try to extract symbolic formulas that describe the evolution laws of the system from real data.

The related research was published in ICLR 2023 under the title "Learning Symbolic Models for Graph-structured Physical Mechanism".
Paper address:https://openreview.net/pdf?id=f2wN4v_2__W
In the field of large-scale complex networks, there are already theoretical dimensionality reduction tools in statistical physics, such as the renormalization group, which can be applied to real large-scale network predictions to help identify the low-dimensional "skeleton" of evolutionary dynamics and achieve long-term predictions. This is also our recent research focus.

The related research was published in KDD 2024 under the title "Predicting Long-term Dynamics of Complex Networks via Identifying Skeleton in Hyperbolic Space".
Paper address:https://arxiv.org/abs/2408.09845
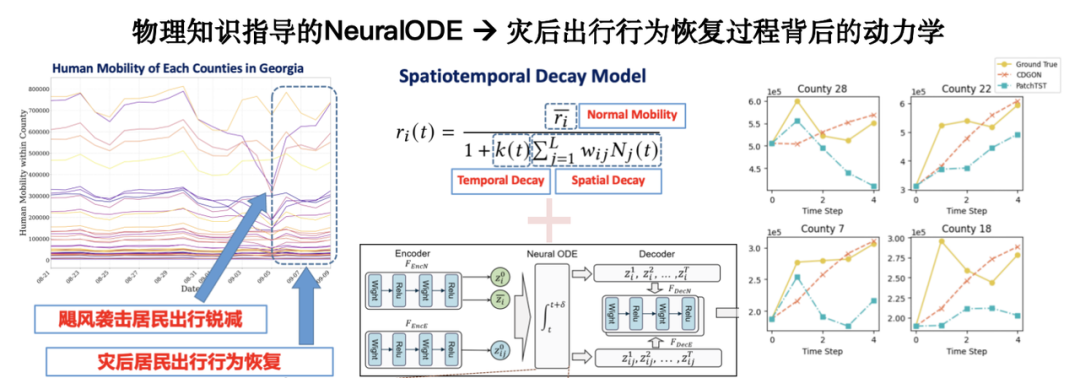
In addition, introducing physical knowledge to support small-sample learning will significantly enhance the generalization ability of the model.Taking post-disaster emergency response as an example, historical data on this scenario is scarce, but some scholars have constructed dynamic equations of post-disaster human behavior from a mechanism perspective. Combining these equations with real data models can achieve more robust predictions in the case of limited samples.
The related research was published in KDD 2024 under the title "Physics-informed Neural ODE for Post-disaster Mobility Recovery".
Paper address:https://dl.acm.org/doi/10.1145/3637528.3672027
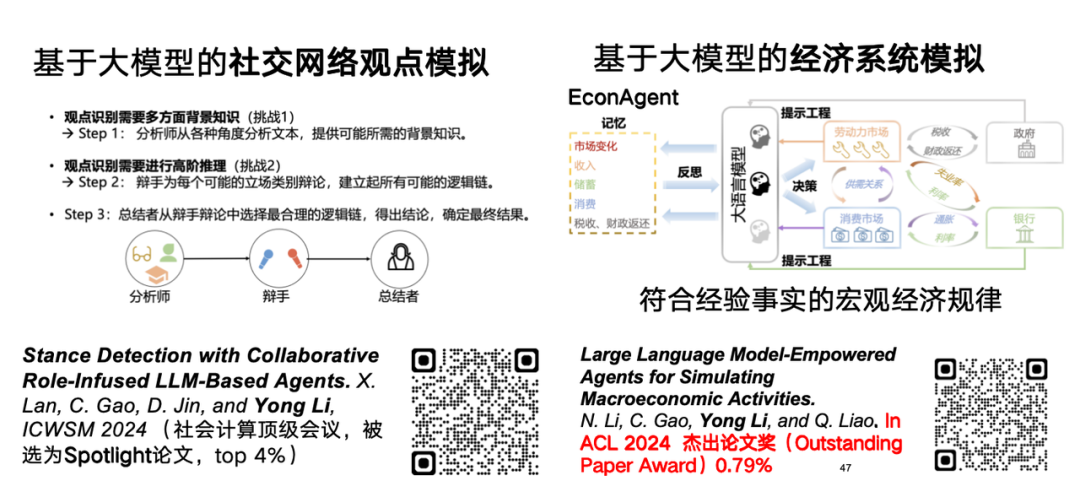
We also believe that large language models have the potential for reasoning and simulation in the domain of spatiotemporal data.For example, large language models can be used to simulate network opinions or economic systems. Regarding the research on large language models simulating network opinions, the relevant paper titled "Stance Detection with Collaborative Role-Infused LLM-Based Agents" was published at ICWSM 2024.
Paper address:https://arxiv.org/abs/2310.10467
Regarding the study of large language model simulation of economic systems, we used the large language model agent to effectively simulate the macroeconomic model that conforms to empirical laws.The related research, titled "EconAgent: Large Language Model-Empowered Agents for Simulating Macroeconomic Activities", won the ACL 2024 Outstanding Paper Award.
Paper address:https://arxiv.org/abs/2310.10436
Since large language models are trained based on a large amount of human-generated language data and have human-like reasoning and decision-making capabilities, our team is exploring their application in generating or simulating human behavior. Compared with the traditional generative model-based approach, with the help of large model pre-training knowledge, we found that only 200 samples are needed to achieve similar results to 100,000 training samples, achieving rapid generalization in specific scenarios.
The related research "Chain-of-Planned-Behaviour Workflow Elicits Few-Shot Mobility Generation in LLMs" has been uploaded to the preprint website arXiv.
Paper address:https://arxiv.org/abs/2402.09836
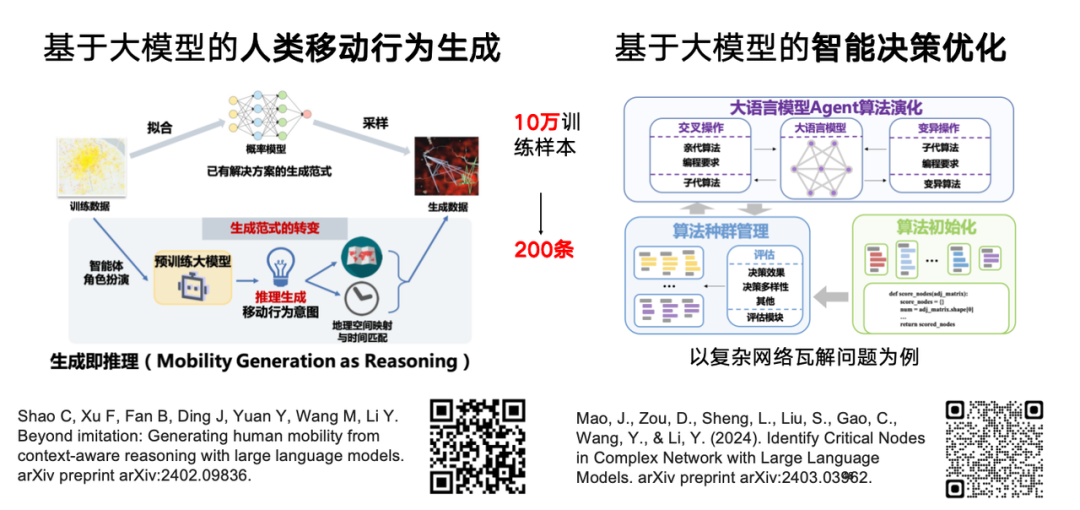
Our team is also exploring whether large language models can be further used for intelligent decision-making optimization.The related research "Identify Critical Nodes in Complex Network with Large Language Models" has been uploaded to the preprint website arXiv.
Paper address:https://arxiv.org/abs/2403.03962
About FIB LAB
The guest speaker of this talk is Dr. Jingtao Ding from the Center for Urban Science and Computing Research (FIB LAB) of the Department of Electronic Engineering, Tsinghua University.The research center focuses on urban science and computing research, takes urban science as the basic research problem, conducts research based on theories such as complex systems and computational sociology, and combines the new generation of "cognitive artificial intelligence" of data science and machine learning as the core technology to serve the application fields facing major national needs such as urban twins, urban governance, and wireless network twins. The team currently has 6 teachers and more than 60 students.

The team has published more than 150 academic papers in top international journals such as Nature's sub-journals and top international conferences such as KDD, NeurIPS, WWW, and UbiComp (7 sub-journals and more than 100 CCF A papers), with more than 25,000 citations. The team has won the Best Paper/Nomination Award at international conferences seven times.The team has presided over or participated in more than 15 projects including the Ministry of Science and Technology's key R&D plan and the National Natural Science Foundation of China, and related achievements have won the second prize of the National Science and Technology Progress Award.
The research center has always adhered to the integration of industry and academia. In recent years, it has established good cooperative relationships with companies such as Huawei, Tencent, Alibaba, Microsoft Research Asia, Meituan, Kuaishou, AutoNavi, SenseTime, Toyota and mobile operators, and has abundant corporate cooperation and internship opportunities.
Laboratory homepage:https://fi.ee.tsinghua.edu.cn/
Personal homepage:https://fi.ee.tsinghua.edu.cn/~dingjingtao/









