Command Palette
Search for a command to run...
Information Retrieval, Path Planning, E-commerce, What Are the Battlefields of KDD?

KDD 2020, the top international conference in the field of data mining, will kick off next week. Of the 2,035 papers submitted this year, 338 were accepted. Among them, domestic technology giants such as BAT, Didi, and Huawei performed well.
The annual international conference on data mining and knowledge discovery ACM SIGKDD 2020 (Conference on Knowledge Discovery and Data Mining, referred to as KDD),It will be held online from August 23 to 27.

With the development of database technology and the continuous accumulation of data, the field of data mining has received more and more attention.
The number of submissions to KDD has also been growing at a visible rate in recent years, from 1,115 in 2016 to 2,035 this year. Among these papers, the contribution of Chinese people is also increasing, and the results are very impressive.
KDD is in its 26th year, and the scientific research strength of Chinese people is increasing year by year
KDD started in 1995 and is held annually by the ACM Special Committee on Data Mining and Knowledge Discovery (SIGKDD).Recommended by CCF (China Computer Federation) as a Class A international conference.It is known as the "World Cup" in the field of data mining.
As the highest-level international conference in the field of data mining in the world, KDD is famous for its strict paper acceptance rate, with the annual acceptance rate not exceeding 20%, and this year is no exception.
On May 25, KDD 2020 officially announced the accepted papers.This year, a total of 1,279 papers were submitted to the research track (academic papers for the research community), and 216 were accepted, so the acceptance rate was 16.8%.
There are 756 papers submitted to the Applied Data Science track (the practical track for industry).121 papers were accepted, with an acceptance rate of 16%.
This year is the 26th KDD. According to statistics on the number of papers published and awards won, the participation of Chinese in KDD has increased year by year in recent years, their performance has become stronger and stronger, more and more papers have been selected, and they have won many awards.
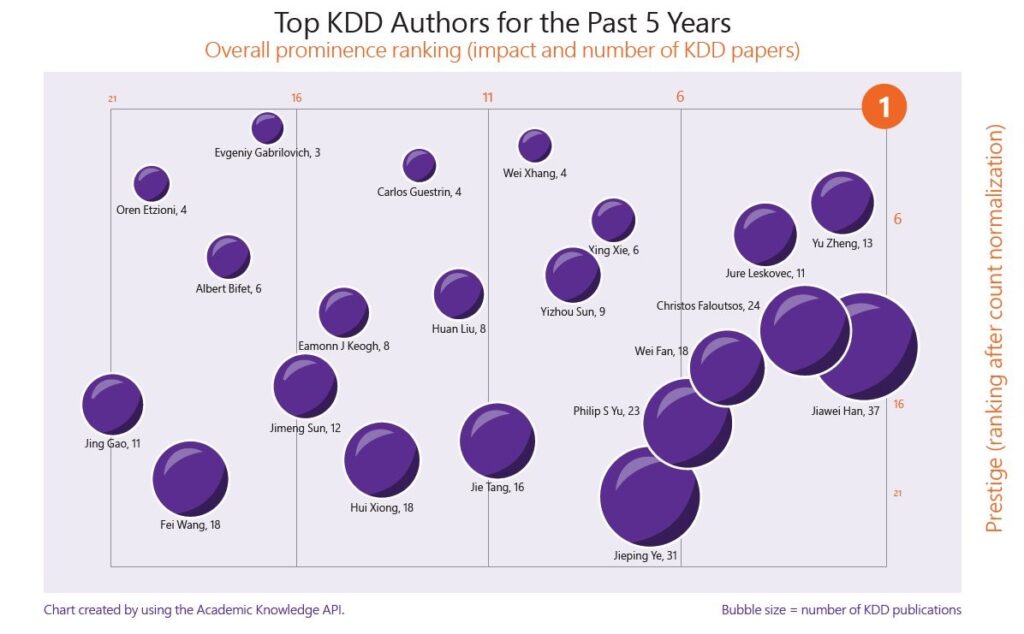
In recent years, the achievements of major domestic technology companies in KDD have become increasingly impressive.
According to statistics, the three major companies BAT published a total of 12 articles in 2018. This year, Alibaba alone published 25 papers, Tencent published 10 papers, Baidu published 9 papers, and Didi, Huawei and JD published 6 papers each.
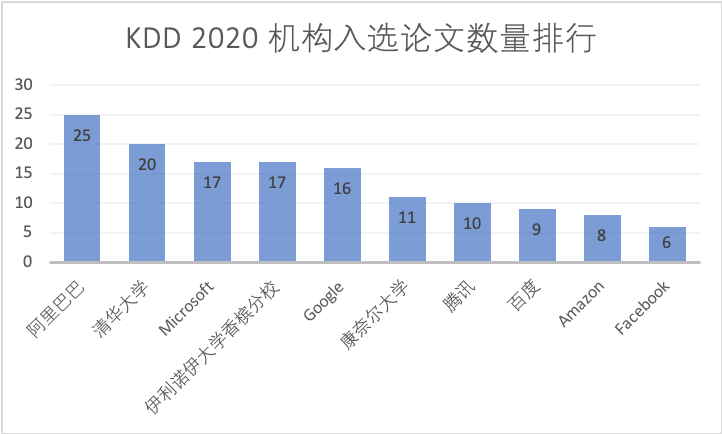
KDD 2020: Where is the battlefield for big companies?
We have organized the accepted papers of domestic manufacturers by application scenarios for your reference. Some of the papers have been published to arXiv, so you can have a sneak peek.
Information Retrieval 《Extracting Privileged Features of Taobao Recommendations》

Unit: Alibaba
summary:Features play an important role in e-commerce prediction tasks. To ensure consistency between offline training and online serving, we usually use the same features for both. However, this consistency ignores some distinctive features. For example, when estimating the conversion rate (CVR), which is the likelihood that a user will purchase the product after clicking on it, features such as dwell time on the product detail page provide information. However, CVR prediction should be done for online ranking before the click occurs.We define the discriminative features that can only be used in training as privileged features. Based on the distillation technique that bridges the gap between training and inference, this paper proposes a feature distillation (PFD) algorithm.We conducted experiments on two basic prediction tasks for Taobao recommendations, namely, click-through rate for coarse-grained ranking and CVR for fine-grained ranking. By extracting interactive features that are disabled during service for CTR and post-hoc features for CVR, we achieved significant improvements over their strong baselines. During online A/B testing, the click metric improved by +5.0% in the CTR task. In the CVR task, the conversion metric improved by 2.3%. In addition, by addressing several issues with PFD training, we achieved comparable training speed as the baseline without any distillation.
Paper address:
https://arxiv.org/abs/1907.05171
Information Retrieval 《Controllable Multi-Interest Recommendation Framework》

Unit: Alibaba
summary:In recent years, with the rapid development of deep learning technology, neural networks have been widely used in e-commerce recommendation systems. We formalize the recommendation system recommendation problem as a sequential recommendation problem, aiming to predict the next item that a user may interact with. Recent works usually give an overall embedding from the user's behavior sequence. However, a unified user embedding cannot reflect the user's multiple interests over a period of time. In this paper, we propose a new controllable multi-interest framework for sequential recommendation called ComiRec. Our multi-interest module obtains multiple interests from user behavior sequences and can be used to retrieve candidate items from a large-scale item pool. These items are then fed into an aggregation module to obtain overall recommendation information. The aggregation module uses controllable factors to balance the accuracy and diversity of recommendations. We conduct sequential recommendation experiments on two real-world datasets, Amazon and Taobao.Experimental results show that our framework achieves significant improvements over the state-of-the-art models. Our framework has also been successfully deployed on Alibaba's offline distributed cloud platform.
Paper address:
https://arxiv.org/abs/2005.09347
Information Retrieval 《An Accurate and Diverse Recommendation Framework Based on Bayesian Graph Convolutional Neural Network》

Company: Huawei
summary:In the recommendation system, it is a very important topic to accurately learn the expression of users and items. With the extensive research and application of graph convolutional networks, the application of graph convolutional networks to recommendation systems has attracted more and more attention. Existing graph-based recommendation models all regard the observed user-item interaction graph as the ground-truth between users and items. However, in the recommendation system scenario, this setting is not always reasonable. For example, this setting will treat interactions without edges in the interaction graph as negative examples, while such unobserved interactions may be potential interactions in the future; on the other hand, some observed edges may be unreal or caused by noise. In order to solve this problem,In this work, we use Bayesian Graph Convolutional Network (BGCN) to model uncertainty in user-item interaction graphs.
We proposed a detailed BPR loss function for the training process and discussed in detail how to make predictions under our model. We verified it on four public data sets and found that our BGCN model outperformed existing graph-based recommendation models in all evaluation indicators. We also verified it on product data sets and found that the accuracy of the BGCN model was also improved.In addition, we also found that the recommendation results of our BGCN model take into account both accuracy and diversity, and the recommendation effect on "cold start" users is more significant.
Related Links:
https://zhuanlan.zhihu.com/p/142812078
Path Planning 《Polestar: A Smart, Efficient, Nationwide Public Transportation Path Engine》

Unit: Baidu
summary:Public transportation plays an important role in people's daily lives. It has been proven that public transportation is more environmentally friendly, more efficient, and more economical than any other form of transportation. However, due to the ever-expanding transportation network and more complex travel situations, it is difficult for people to effectively find the best route from one place to another through the public transportation system. To this end, in this paper, we propose Polaris, a data-driven engine for smart and efficient public transportation routing. Specifically, we first propose a novel Public Transportation Graph (PTG) model for public transportation systems with various travel costs, such as time or distance. Then, we introduce a generalA route search algorithm and an effective site binding method are proposed to efficiently generate candidate routes. On this basis, a dual-path candidate ranking model is proposed to capture user preferences in dynamic travel scenarios. Finally, experiments on two real-world datasets demonstrate the advantages of Polaris in terms of efficiency and effectiveness.In fact, at the beginning of 2019, Polaris was deployed on Baidu Maps, one of the largest map services in the world. So far, Polaris has provided services to more than 330 cities, answered more than 100 million queries per day, and achieved a significant increase in user click-through rate.
Paper address:
https://arxiv.org/abs/2007.07195
Path Planning Hybrid Spatiotemporal Graph Convolutional Networks: Improving Traffic Prediction with Navigation Data

Unit: Alibaba
summary:Traffic forecasting has attracted increasing interest recently due to the popularity of online navigation services, ride-sharing, and smart city projects. Due to the non-stationary nature of road traffic, the lack of contextual information can fundamentally limit the accuracy of predictions. To address this issue, we propose a Hybrid Spatio-Temporal Graph Convolutional Network (H-STGCN), which is able to "infer" future travel times by leveraging upcoming traffic volume data. Specifically, we propose an algorithm to obtain upcoming traffic from an online navigation engine. Exploiting the piecewise linear flow-density relationship, a novel transformer structure transforms the upcoming volume into an equivalent travel time. We combine this signal with the commonly used travel time signal and then apply graph convolution to capture the spatial dependencies.In particular, we construct a composite adjacency matrix that reflects the proximity of innate traffic. We conduct extensive experiments on real-world datasets. Results show that H-STGCN significantly outperforms state-of-the-art methods on various metrics, especially in predicting non-repetitive congestion.
Paper address:
https://arxiv.org/abs/2006.12715
Path Planning 《Prediction of individual processing effects in large-scale team competitions under the shared bicycle economy》

Unit: Didi
summary:To maximize the cumulative user engagement (e.g., cumulative clicks) in sequential recommendations, one usually needs to balance two potentially conflicting objectives, namely, pursuing higher immediate user engagement (e.g., click-through rate) and encouraging users to browse (i.e., more items).Existing works often study these two tasks separately, thus often leading to suboptimal results.In this paper, we study this problem from an online optimization perspective and propose a flexible and practical framework to explicitly trade off longer user browsing time and higher immediate user engagement. Specifically, by viewing items as actions, user requests as states, and user departures as absorbing states, we formulate each user's behavior as a personalized Markov decision process (MDP), thereby reducing the problem of maximizing cumulative user engagement to a stochastic shortest path (SSP) problem. At the same time, through the estimation of immediate user engagement and exit probabilities, we show that the SSP problem can be effectively solved by dynamic programming.Experiments on real-world datasets demonstrate the effectiveness of the proposed method. In addition, this method has been deployed on a large e-commerce platform, improving the cumulative number of clicks by more than 7%.
Paper address:
Consumer Services Maximizing Cumulative User Engagement in Continuous Recommendations: An Online Optimization Perspective

Unit: Alibaba
summary:In order to maximize the cumulative user engagement (e.g., cumulative clicks) in sequential recommendations, it is usually necessary to balance two potentially conflicting objectives, namely, pursuing higher immediate user engagement (e.g., click-through rate) and encouraging user browsing (i.e., more item exposure). Existing studies often study these two tasks separately, which often leads to suboptimal results.
In this paper, we study this problem from an online optimization perspective and propose a flexible and practical framework to explicitly trade off longer user browsing time and higher immediate user engagement. Specifically, by considering items as actions, user requests as states, and user departures as absorbing states, we formulate each user's behavior as a personalized Markov decision process (MDP) and simplify the user cumulative engagement maximization problem to a stochastic shortest path (SSP) problem. At the same time, by estimating the immediate user engagement and exit probabilities, we prove that dynamic programming can effectively solve the SSP problem.Our experiments on real datasets demonstrate the effectiveness of our approach. In addition, this approach has been deployed on a large e-commerce platform, improving the cumulative number of clicks by more than 7%.
Paper address:
Consumer Services "Building Intelligent Chatbots for Customer Service: Learning to Respond in a Timely Manner"

Unit: Didi
summary:
In recent years, intelligent chatbots have been widely used in the field of customer service. One of the main challenges for chatbots to maintain a smooth conversation with customers is how to respond at the right time. However, most advanced chatbots follow an interaction-by-interaction approach.Such chatbots respond after every utterance from the customer, which in some cases can lead to inappropriate responses and mislead the conversation process.
In this paper, we propose a Multi-Round Response Trigger Model (MRTM) to address this problem. MRTM learns from large-scale human-machine dialogues between customers and agents via a self-supervised learning scheme.It uses the semantic matching relationship between context and response to train a semantic matching model, obtains the weights of co-occurring utterances in the context through an asymmetric self-attention mechanism, and then uses the weights to determine whether a given context should be responded to.
We conduct extensive experiments on two conversation datasets collected from real-world online customer service systems. The results show that MRTM significantly outperforms the baseline. In addition, we integrate MRTM into Didi’s customer service chatbot. With the ability to identify the appropriate response time, the chatbot can incrementally aggregate information across multiple rounds of conversations and make more intelligent responses at the right time.
Paper address:
https://dl.acm.org/doi/10.1145/3394486.3403390
E-commerce "Dual Heterogeneous Graph Attention Networks to Improve Long-Tail Performance of Store Search in E-commerce"

Unit: Alibaba
summary:
Dual Heterogeneous Graph Attention Networks to Improve Long-Tail Performance of Store Search in E-Commerce
With the huge growth of Taobao users and stores, store search faces several unique challenges:
1) Many store names cannot fully express the products they sell, i.e., the semantic gap between user queries and store names;
2) Due to the lack of user interaction, it is difficult to provide good search results for long-tail queries and difficult to retrieve long-tail stores that are highly relevant to the query. To address these two key challenges, we turn to graph neural networks (GNNs). Specifically,Using user interaction data from store search and product search, we propose a Dual Heterogeneous Graph Attention Network (DHGAT) integrated with a two-tower architecture.First, we construct a heterogeneous graph in the context of store search by leveraging first-order and second-order proximity from user search behavior, user click behavior, and user purchase history. Then, DHGAT is designed to focus on adopting heterogeneous and homogeneous neighbors of queries and stores to enhance its own representation, which helps alleviate the long-tail phenomenon.Furthermore, DHGAT alleviates the semantic gap by combining the titles of related items, thus enriching the semantics of query text and store names.
Paper address:
https://dl.acm.org/doi/10.1145/3394486.3403393
An advertising plan with request-level guaranteed delivery: prediction and allocation》
Company: Tencent
summary:Existing research on online advertising usually models the service as a group-level or user-level supply allocation problem and assumes that search results are available and contracts have been signed, thus focusing on searching for the best allocation for online service. However, these techniques are not sufficient to meet the needs of today's industry trends:
1) Advertisers pursue more precise targeting, which requires not only user-level attributes but also request-level attributes;
2) Users prefer more friendly advertising services, which will bring more restrictions on advertising;
3) The bottleneck for publishers’ revenue growth lies not only in advertising services, but also in forecasting accuracy and sales strategies.
Since the scale of request-level models is several orders of magnitude larger than that of population-level or user-level models, solving these problems is non-trivial.
Facing the challenge, we proposed a holistically designed request-level, guaranteed-delivery advertising scheduling system, and carefully optimized three key elements including impression forecasting, sales, and service.Our system has been deployed in Tencent's online guaranteed delivery advertising system and has served billions of users for nearly a year. Evaluations on large-scale real-world data and the performance of the deployed system show that our design can significantly improve the accuracy and delivery speed of request-level impression prediction.
Paper address: Not yet published
Medical predictions INPREM: An explainable and trustworthy healthcare prediction model

Company: Tencent
summary:
Building predictive models for personalized medicine based on historical electronic health records has become an active research area. Thanks to its powerful feature extraction capabilities, deep learning methods have achieved good results in many clinical prediction tasks. However, due to the lack of interpretability and credibility, it is difficult to apply it to actual clinical decision-making cases.
To address this problem, in this paper, we propose an interpretable and trustworthy predictive model (INPREM) for healthcare. First, INPREM is designed as an interpretable linear model to achieve interpretability. At the same time, nonlinear relationships are encoded into the learned weights to model the dependencies between and within each visit.This allows us to obtain the contribution matrix of the input variables,As evidence of the predicted results, it helps doctors understand why the model makes such a prediction, making the model more interpretable.Second, for reliability, we place a random gate (following Bernoulli distribution to turn on or off) on each weight of the model, as well as an additional branch to estimate data noise. The model can capture the uncertainty of each prediction using Monte Carlo sampling and an objective function that considers data noise. In turn, the captured uncertainty allows doctors to know the confidence of the model, making the model more credible. Our experience shows that the proposed INPREM has significant advantages over existing methods.
Paper address:
https://dl.acm.org/doi/abs/10.1145/3394486.3403087
Registration for KDD 2020 Online Conference is open
KDD 2020 is in progress, and registration for the conference is now open:
https://www.kdd.org/kdd2020/#!
The full agenda has been announced. Interested students can attend the conference remotely via Zoom. Student tickets are $50. One of the most anticipated sessions, the opening ceremony and award ceremony, will be held on August 25th from 8:00 to 10:00 local time. Please stay tuned.
For the full schedule, please see:
https://www.kdd.org/kdd2020/schedule
Sources:
https://www.kdd.org/kdd2020/accepted-papers#ads-papers
https://www.aminer.cn/conf/kdd2020/papers
-- over--








