Command Palette
Search for a command to run...
Meta's Largest Video Segmentation Dataset Is Now Online, 50 Times Larger Than Similar Datasets; 9K Stars! Kuaishou Digital Human Demo Starts With One Click!

How does AI give life to static portraits, making their smiles, blinks, and even subtle facial expressions come alive? Recently, the Kuaishou team open-sourced LivePortrait, which can transform a static photo into a dynamic portrait with rich expressions by simply uploading it. It has already received 9K stars on GitHub.This tutorial is now available on HyperAI. Come and experience it now!
LivePortrait Tutorial Link:
From July 29 to August 2, hyper.ai official website updates:
* High-quality public datasets: 11
* Selection of high-quality tutorials: 3
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 4
Visit the official website:hyper.ai
Selected public datasets
1. SA-V Video Segmentation Dataset
The SA-V dataset is a large-scale video segmentation dataset built by Meta in 2024 for training and evaluating Meta Segment Anything Model 2. It contains approximately 51,000 real-world videos and 643K spatiotemporal mask annotations, which is about 50 times larger in size than other similar datasets.
Direct use:https://go.hyper.ai/X4DGI
To promote the effective development of AI systems in the field of biology, researchers from FutureHouse Inc. launched the Language Agent Biology Benchmark Dataset LAB-Bench, which is used to evaluate the performance of AI systems in actual biological research such as literature retrieval and reasoning, graph interpretation, and understanding and processing of DNA and protein sequences. The results have been submitted to the top conference NeurlPS 2024.
Direct use:https://go.hyper.ai/UznkS
3. NuminaMath-CoT Mathematics Competition Problem Dataset
This dataset contains 860k+ math competition question-solution pairs, each of which uses the Chain of Thought (CoT) reasoning template. The sources of the dataset include Chinese high school math exercises, American and International Mathematical Olympiad contest questions. The data is mainly collected from online test paper PDFs and math discussion forums.
Direct use:https://go.hyper.ai/svElx
4. Taptap reviews game review dataset
This dataset contains 4,888 data examples of tagged reviews of about 300 games on the mobile game app TapTap, which can be used for sentiment analysis tasks. User reviews with less than 3 stars (maximum 5 stars) are considered 0 (unsatisfied), and others are 1 (satisfied). The ratio of these two categories is approximately 1:1.
Direct use:https://go.hyper.ai/ISf7c
5. CCPD Dataset Chinese License Plate Detection Dataset
The CCPD dataset is a large, diverse, and carefully annotated license plate recognition dataset. The dataset is mainly collected in parking lots in Hefei, China, and contains license plate photos in a variety of complex environments, such as blur, tilt, rainy and snowy days, which makes the dataset more challenging in the license plate recognition task.
Direct use:https://go.hyper.ai/gZ37Y
6. TinyStories short story synthesis dataset
This dataset is a synthetic dataset of short stories generated by GPT-3.5 and GPT-4, with a vocabulary limited to the range of comprehension of 3 to 4-year-old children. This dataset can be used to train models to generate fluent, consistent, diverse, and grammatically near-perfect short stories.
Direct use:https://go.hyper.ai/m9ouS
7. Wildfire Smoke Wildfire Smoke Detection Dataset
This dataset was jointly released by AI for Mankind and HPWREN in 2019. It contains 737 images in total, including 516 training images, 147 verification images, and 74 test images, with the annotation format of COCO. It aims to improve the model's ability to distinguish between clouds/fog and smoke and establish an end-to-end feedback loop.
Direct use:https://go.hyper.ai/ofGHZ
This is a public domain speech dataset containing 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. Transcriptions are provided for each clip. The clips range in length from 1 to 10 seconds, with a total length of approximately 24 hours.
Direct use:https://go.hyper.ai/Eo1bK
The dataset contains 8,508 images of the twelve Chinese zodiac categories. The dataset has been pre-split into training, validation, and testing with a ratio of 85:7.5:7.5.
Direct use:https://go.hyper.ai/ps2es
10. DISC-Law-SFT High-quality Chinese Legal Supervision Fine-tuning Dataset
This dataset contains nearly 300,000 training data and is designed specifically for the Chinese legal field. It aims to improve the model's capabilities in legal text processing, legal reasoning thinking, and knowledge retrieval and compliance in the judicial field.
Direct use:https://go.hyper.ai/zh9Ij
11. Free Spoken Digit Dataset (FSDD) Digital Recognition Audio Dataset
The Free Spoken Digit Dataset (FSDD) is an audio dataset consisting of digital speech recordings in wav files with a sampling rate of 8kHz. The recordings are cropped to minimize the silence at the beginning and end.
Direct use:https://go.hyper.ai/HZ00d
For more public datasets, please visit:
Selected Public Tutorials
HiDiffusion is an open-source high-resolution framework developed by Megvii Technology. It not only supports text-generated images and image-generated images, but also has image restoration functions. HyperAI Super Neural Network has launched the "HiDiffusion can quickly generate high-quality 8k image demo" tutorial, which can be started with one-click cloning without entering any commands.
Run online:https://go.hyper.ai/yZ5K5
2. LivePortrait Kuaishou open source image-generated video digital human demo
LivePortrait is a portrait video generation framework. Its main functions include generating vivid animations from a single image, accurately controlling the movements of eyes and lips, processing seamless stitching of multiple portraits, supporting multi-style portraits, generating high-resolution animations, etc. This tutorial is a one-click run demo of LivePortrait. The relevant environment and dependencies have been installed. You can experience it by cloning and starting it with one click.
Run online:https://go.hyper.ai/oTs66
3. AuraSR GAN-based super-resolution image enlargement demo
AuraSR is a high-definition image restoration model based on deep learning. It can intelligently identify the details in the image and automatically fill in the missing details while enlarging the image. Compared with traditional image enlargement methods, AuraSR not only has better results, but also is easy to operate and can be easily used without professional skills. You can experience the model with one-click cloning.
Run online:https://go.hyper.ai/y2wIU
Community Articles
Aitomatic, a leading AI innovation company in the industrial field, announced the launch of SemiKong, the world's first open source AI large language model designed specifically for the semiconductor industry. The company has previously launched an AI agent called aiKO, which builds exclusive agents for enterprise users based on their expertise and data, and the enterprise has "full ownership" of its agent.
View the full report:https://go.hyper.ai/A7eCi
2. Highlights: Huang Renxun and Zuckerberg's "Conversation of the Century"
In the early morning of July 30, at the 51st SIGGRAPH graphics conference, Nvidia founder and CEO Huang Renxun and Meta founder and CEO Mark Zuckerberg had a "fireside chat". HyperAI has compiled the highlights and complete Chinese subtitles for the video.
View the full report:https://go.hyper.ai/rbU2u
The MIT research team reused highly accurate single-state predictors such as AlphaFold and ESMFold and fine-tuned them under a custom flow matching framework to obtain sequence-conditioned protein structure generation models, called AlphaFLOW and ESMFLOW. This article is a detailed interpretation and sharing of the relevant papers.
View the full report:https://go.hyper.ai/qupG9
The Life Basic Model Laboratory of the Department of Automation at Tsinghua University, in collaboration with Xiangya Hospital of Central South University, proposed a precise pathological diagnosis AI basic model ROAM based on large regional interests and pyramid Transformer, which is used for clinical-level diagnosis and molecular marker discovery of gliomas, and can be extended to pathological diagnosis of other types of tumors.
View the full report:https://go.hyper.ai/w4tsr
Popular Encyclopedia Articles
1. Neural Radiance Field (NeRF)
2. Group Query Attention GQA
3. Data Augmentation
4. Large-scale Multi-task Language Understanding (MMLU)
5. Long Short-Term Memory
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
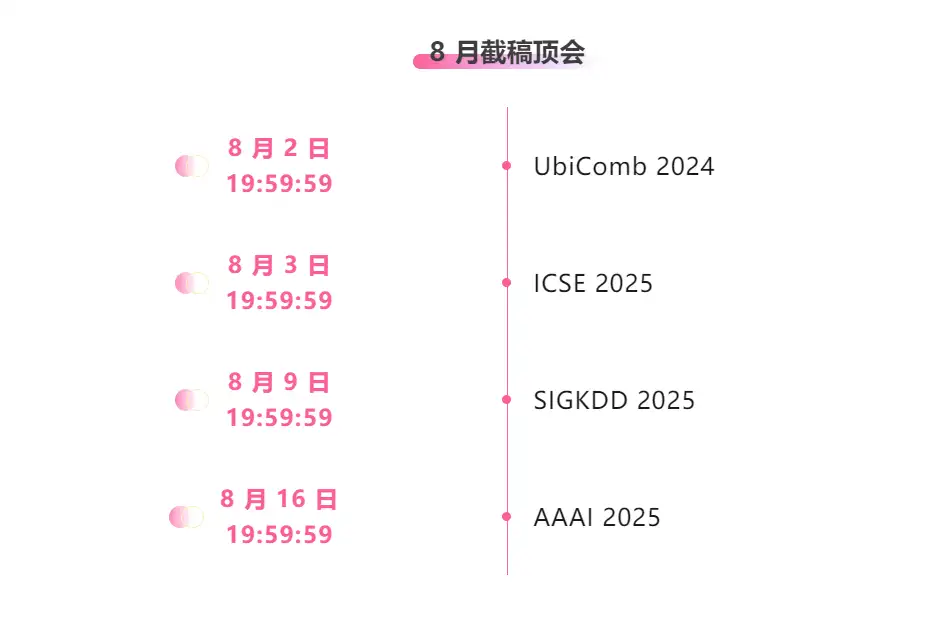
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








