Command Palette
Search for a command to run...
One-click Experience GLM-4-9B-Chat

Recently, Zhipu AI The latest open source result of the large base model GLM-4, GLM-4-9B, was released, which has multimodal capabilities for the first time.Official data show that compared with the Llama-3-8B model with more training, GLM-4-9B has improved by 50% in Chinese subjects and is comparable to GPT-4V in multimodality.
In terms of context length, GLM-4-9B has achieved an upgrade leap from 128K to 1M, which is equivalent to being able to digest 125 papers in one go! In addition, its model vocabulary has been upgraded from 60,000 to 150,000, and the encoding efficiency of languages other than Chinese and English has increased by an average of 30%, which can process tasks in small languages faster.
In order to let everyone experience this open source model that claims to "surpass Llama3-8B" as soon as possible,OpenBayes The "GLM-4-9B-Chat" model is now available on the platform's public model section, which supports one-click input, skipping the long download and upload time and directly starting happy deployment.
Public model address:
https://go.openbayes.com/F7pbS
In addition, "One-click deployment of GLM-4-9B-Chat Demo" has also been simultaneously launched on the public tutorial section of the OpenBayes platform. You can immediately start experiencing the excellent performance of GLM-4-9B-Chat without entering any commands and clicking clone.
Public tutorial address:
https://go.openbayes.com/ulmZe
Procedure
PART 1 Demo operation phase
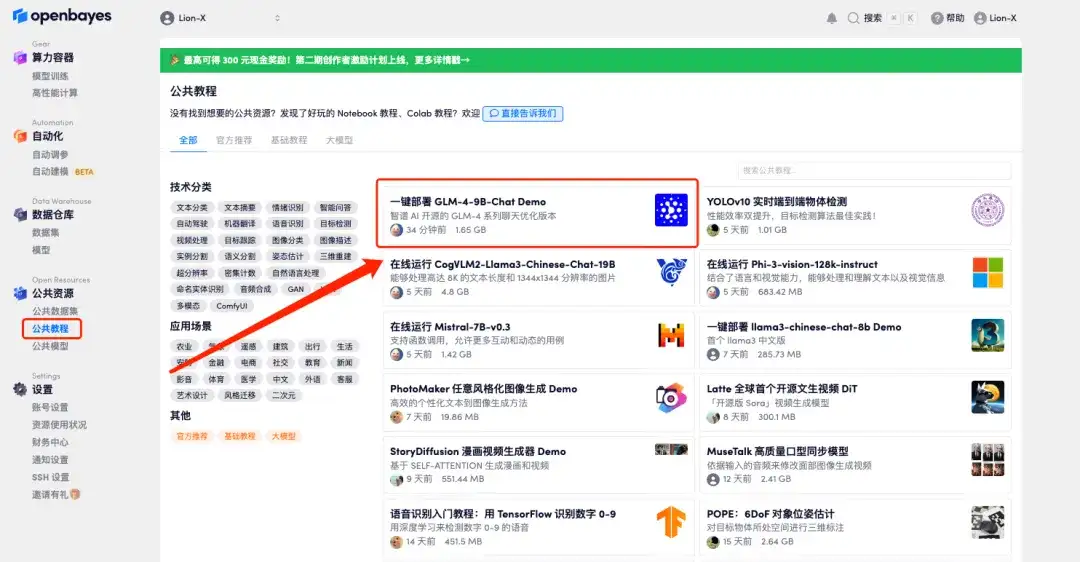
1. Log in http://OpenBayes.com, on the "Public Tutorial" page, select "One-click deployment of GLM-4-9B-Chat Demo".
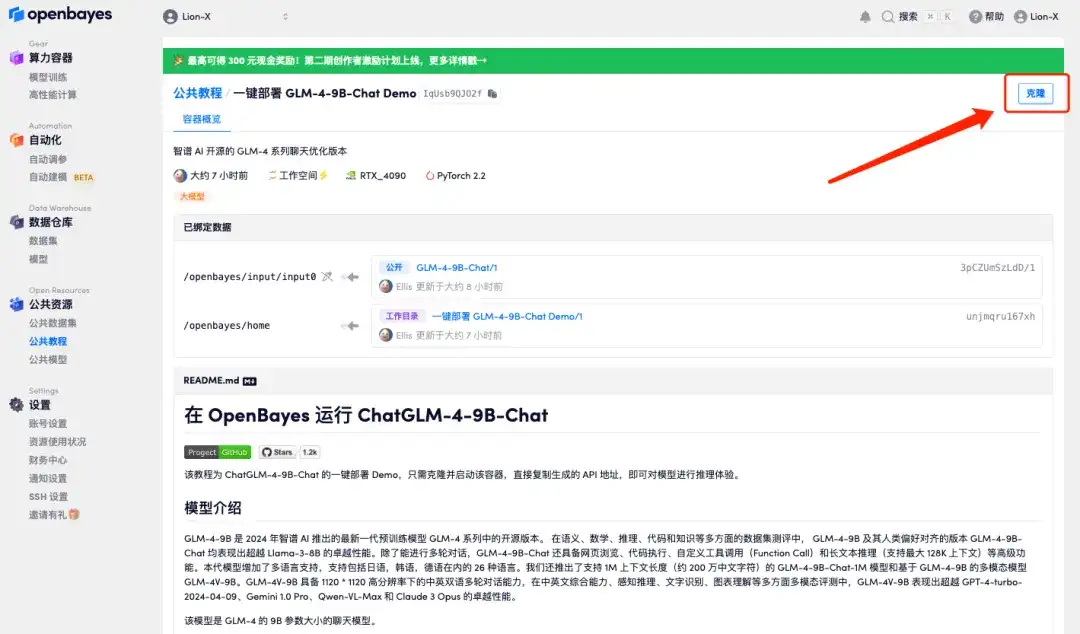
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
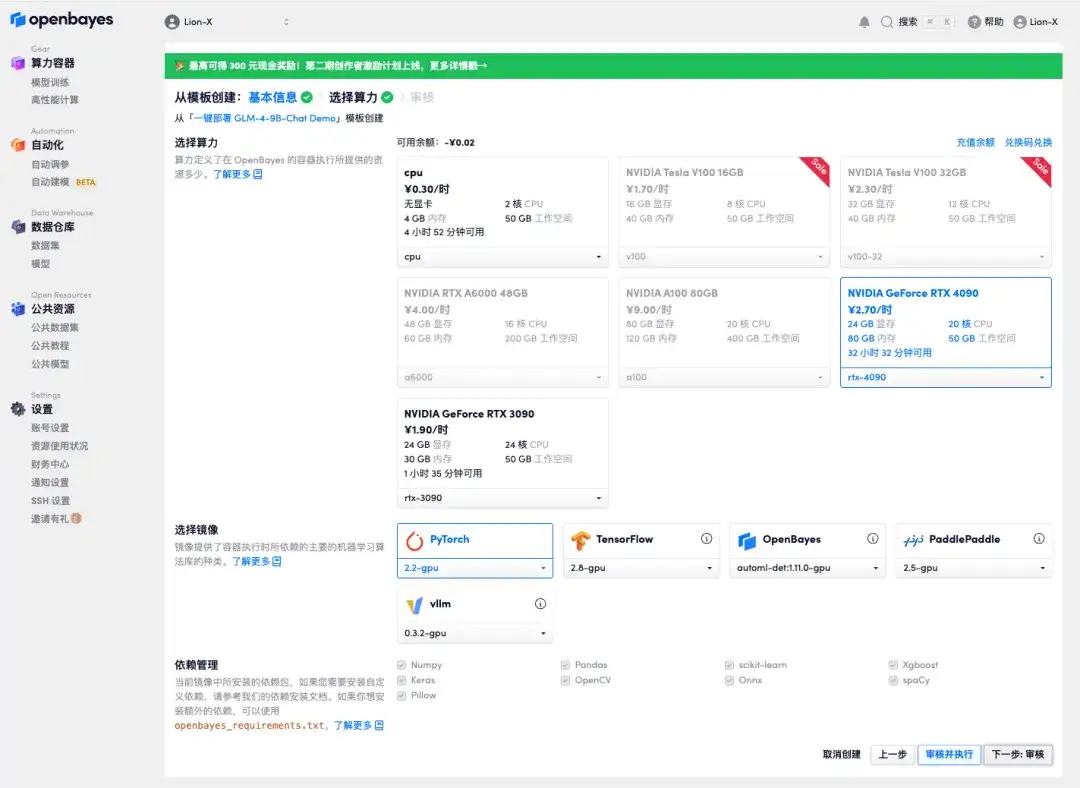
3. Click "Next: Select Hashrate" in the lower right corner.

4. After the jump, select "NVIDIA GeForce RTX 4090" and click "Next: Review".New users can register using the invitation link below to get 4 hours RTX 4090 + 5 hours of free CPU!
Xiaobei's exclusive invitation link (copy and open in browser):https://go.openbayes.com/9S6Dr
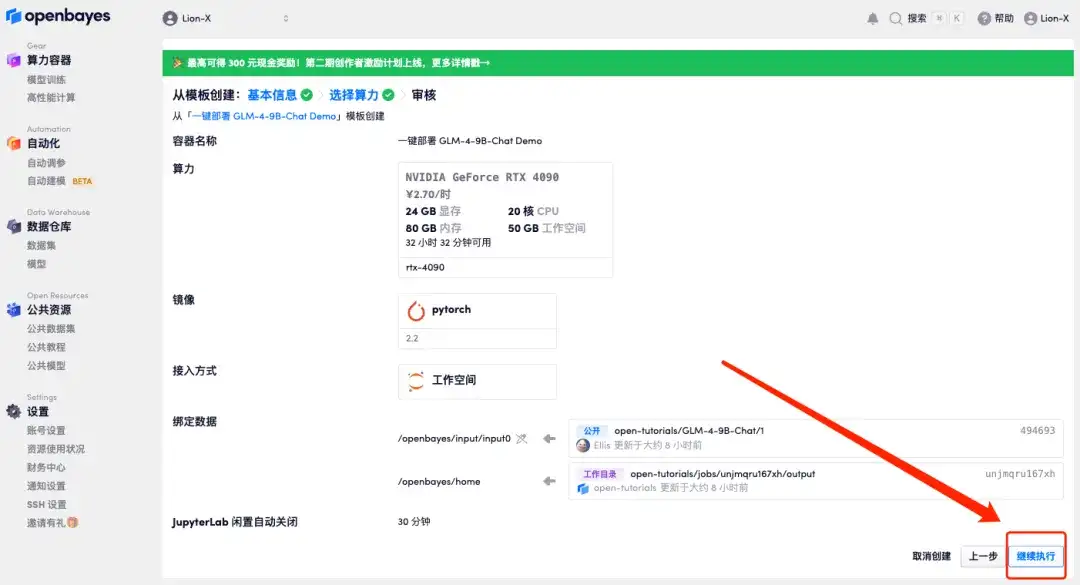
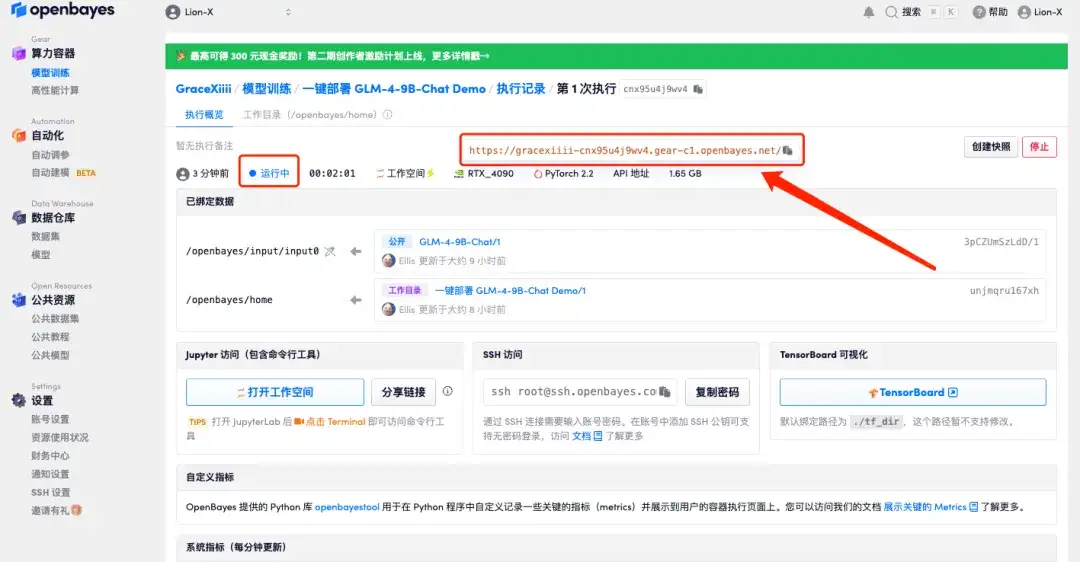
5. Click "Continue" and wait for resources to be allocated. The first clone will take about 3 minutes. When the status changes to "Running", move the mouse to "API Address", copy the address and open it in a new tab to jump to the GLM-4-9B-Chat Demo page.Please note that users must complete real-name authentication before using the API address access function.
If the issue persists for more than 10 minutes and remains in the "Allocating resources" state, try stopping and restarting the container. If restarting still does not resolve the issue, please contact the platform customer service on the official website.
PART 2 Demo operation phase
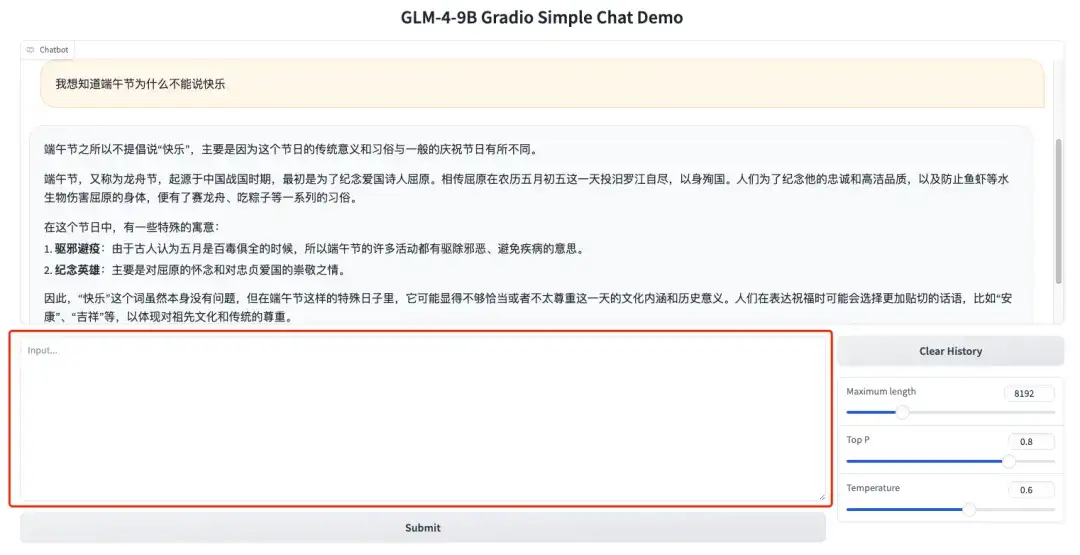
1. Open the GLM-4-9B-Chat Demo page, enter text in the dialog box, and click "Submit" to start the conversation.

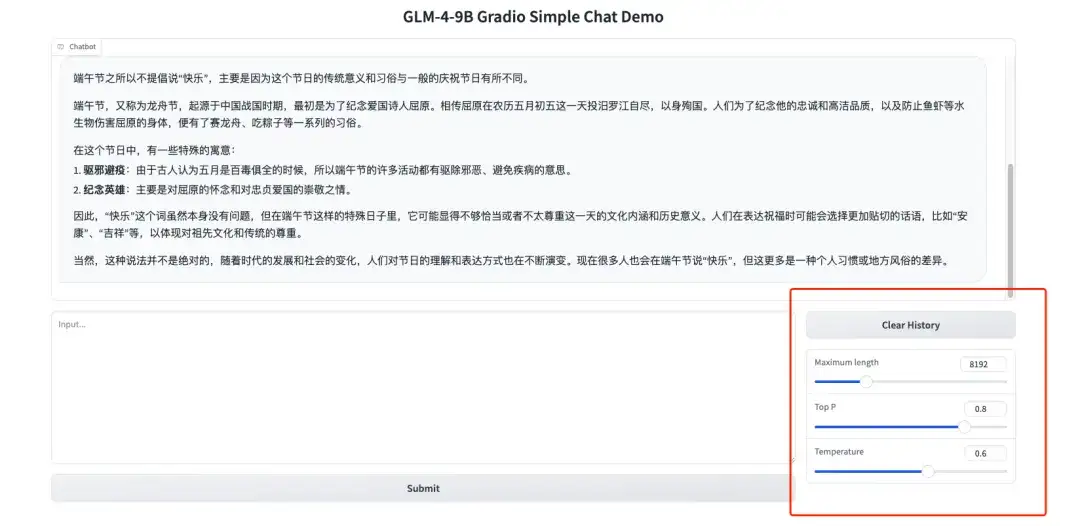
2. The hyperparameter panel on the right represents:
* Maximum length: the maximum number of words that the model can output;
* Top P: controls the range of candidate words selected from the probability distribution output by the model. A larger value means that a larger set of words will be considered during text generation.
* Temperature: A hyperparameter that controls randomness. The larger the value, the more random the generated text will be.
New User Benefits
Registration benefits:Click the invitation link below to register and you will get 4 hours of RTX 4090 + 5 hours of CPU free computing time, valid forever!
Xiaobei's exclusive invitation link (copy and open in browser):








