Command Palette
Search for a command to run...
The Hong Kong University of Science and Technology and Others Proposed the Incremental Weather Forecast Model VA-MoE, Which Has Simplified Parameters by 75% and Still Achieves SOTA performance.

Weather forecasting, a key area influencing social operations and disaster prevention decisions, has always faced enormous challenges brought about by the complex and ever-changing atmospheric system. Every improvement in forecasting capabilities has profound implications for human production and life. Numerical Weather Prediction (NWP) has long been the mainstream approach in this field. Relying on the atmospheric dynamics equations, it simulates the evolution of key variables such as temperature, air pressure, and wind speed by solving partial differential equations, thereby achieving numerical deduction of weather systems.
In recent years, with the breakthrough of artificial intelligence technology, deep learning has shown great potential in meteorological modeling with its powerful spatiotemporal pattern recognition ability.This has given rise to the emerging cross-disciplinary field of "Artificial Intelligence for Weather (AI4Weather)".However,Most existing AI meteorological models are based on an ideal assumption that all meteorological variables can be obtained simultaneously during training and prediction. This is seriously inconsistent with the reality of actual observations, where data sources are diverse and the frequency of data collection varies.For example, high-altitude temperature relies on satellites or radiosondes, which update slowly. Meanwhile, surface precipitation and wind speed are monitored in real time by densely populated stations. This data asynchrony necessitates complete retraining of the model when new variables are introduced, resulting in extremely high computational costs.
To meet this challenge,Research teams from the Hong Kong University of Science and Technology, Zhejiang University and other institutions have designed a new paradigm for "Incremental Weather Forecasting (IWF)" and launched the "Variable Adaptive Mixture of Experts (VA-MoE)".The model uses phased training and variable index embedding mechanisms to guide different expert modules to focus on specific types of meteorological variables. When new variables or stations are added, the model can be expanded without full retraining, significantly reducing computational overhead while ensuring accuracy.
The related research results, titled "VA-MoE: Variables-Adaptive Mixture of Experts for Incremental Weather Forecasting", have been accepted by ICCV25, the top international conference in the field of computer vision.
Research highlights:
* The first systematic exploration of a new paradigm for incremental learning in weather forecasting, establishing a benchmark for quantifiable evaluation of model scalability and generalization capabilities
* Propose VA-MoE, the first framework designed specifically for incremental atmospheric modeling, which achieves expert specialization through contextual variable activation driven by variable index embedding
* Large-scale experiments based on the ERA5 dataset show that VA-MoE significantly outperforms similar models in forecasting high-altitude variables when the data size is halved and the number of parameters is reduced to 25%.

Paper address:
https://arxiv.org/abs/2412.02503
Follow the official account and reply "VA-MoE" to get the full PDF
More AI frontier papers:
Division of upper-air and ground variables in the ERA5 dataset
This study uses the mainstream atmospheric reanalysis dataset ERA5 released by the European Centre for Medium-Range Weather Forecasts (ECMWF) as the experimental basis, covering continuous meteorological observation data from 1979 to the present. Conventional experiments use a 0.25° spatial resolution (corresponding to a grid size of 721×1440); only in the ablation experiment, in order to control the computational complexity, a 1.5° resolution version (grid size of 128×256) is used to ensure a balance between data adaptability and computational efficiency in different experimental scenarios.
From the time dimension, the data set is clearly allocated to different stages of the experiment:
* The initial training phase uses 40 years of data from 1979 to 2020 to lay the foundation for the model's basic meteorological knowledge reserve;
* The incremental training phase uses 20 years of data from 2000 to 2020 to adapt to the parameter optimization requirements after the introduction of new variables;
* During the testing phase, meteorological variable data for the entire year of 2021 were selected to use independent data to verify the model's generalization ability on unseen samples, avoiding the impact of data leakage on the credibility of the results.
* In terms of variable configuration, as shown in the figure below, the experiment involves 5 upper-air variables and 5 surface variables:
* Upper-air variables: These include five types: Z (geopotential height), Q (specific humidity), U (east-west wind speed), V (north-south wind speed), and T (temperature). Each type is defined at 13 different pressure layers and is primarily used in the initial model training phase to build core atmospheric dynamics modeling capabilities.
* Ground variables: including 2-meter temperature T2M, 10-meter east wind speed U10, 10-meter south wind speed V10, mean sea level pressure MSL, surface pressure SP, etc., are introduced as incremental variables in the second stage of the model (incremental training stage) to simulate the scenario of dynamic expansion of variables in actual observations.
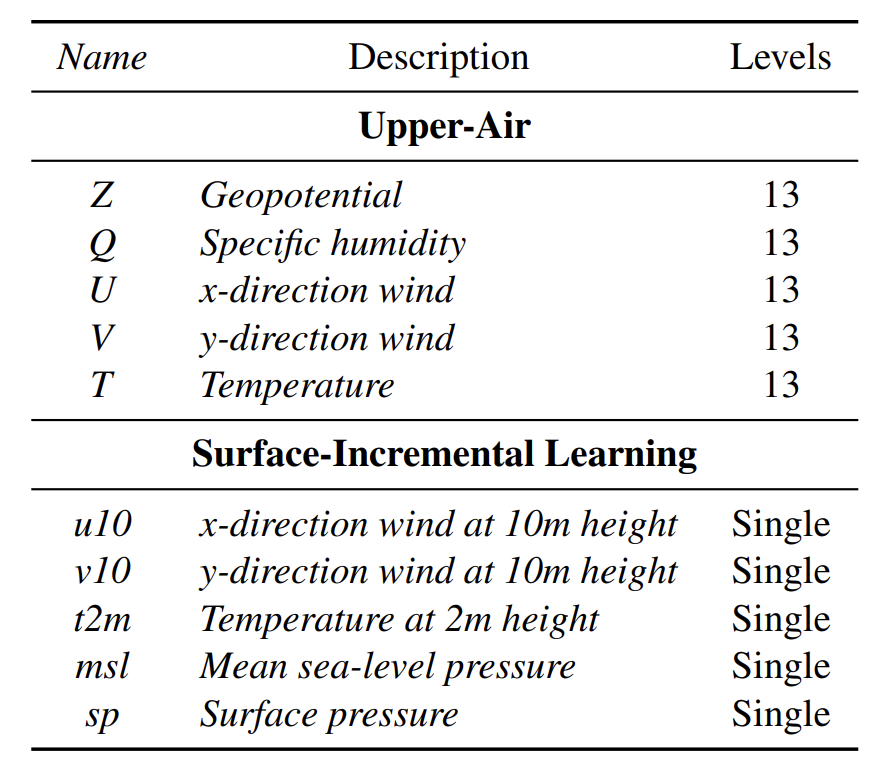
VA-MoE: A variable-adaptive weather forecast model architecture for incremental learning
The core operating logic of VA-MoE revolves around the "two-stage training paradigm".As shown in the figure below, it fully simulates the "gradual expansion of data" scenario in actual observations: the first stage is the "initial stage", in which only high-altitude variables are used to train the model, allowing the model to first grasp the core dynamic laws of the upper atmosphere; the second stage is the "incremental stage", in which ground-based variables are added while freezing the trained parameters of the first stage, and only the modules newly added for the new variables are trained, ultimately forming a complete model.

From the perspective of the architecture, as shown in the figure below,VA-MoE uses Transformer as its core backbone, but has made key optimizations for the multi-scale and strongly correlated characteristics of meteorological data.When the model processes input data, the input features extracted by the encoder first pass through a normalization layer and a self-attention layer. The output of the self-attention layer is fused with a residual connection. It then passes through another normalization layer before being input into the VA-MoE core module for variable adaptive calculation. To avoid knowledge gaps caused by "vanishing gradients" during deep network training, the framework also integrates a "residual connection" mechanism: after each calculation step, some original features are retained, ensuring that high-level networks can still effectively inherit basic meteorological information extracted by lower layers (such as the impact of terrain on near-surface wind speed), significantly improving the modeling stability of long-term meteorological series.
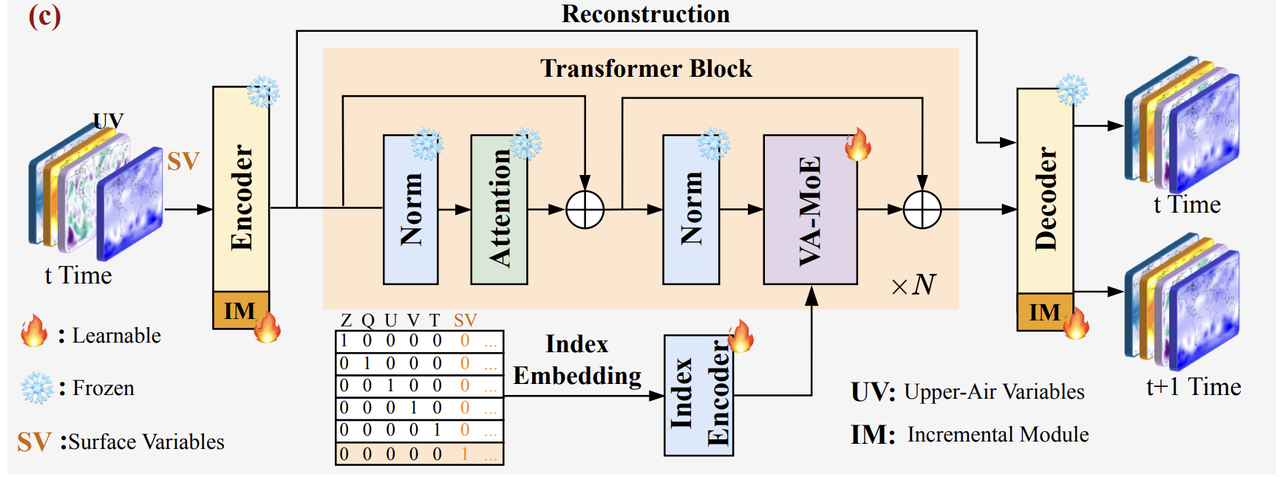
At the training optimization level, VA-MoE adopts a "multi-task joint loss" mechanism to balance prediction accuracy and physical consistency.This mechanism consists of two core components: a dynamic prediction loss, which optimizes weights based on the physical properties of the variables. Fast-changing variables like temperature and wind speed are given higher weights to enhance the ability to capture transient changes. For slowly varying variables like geopotential height, a gradual weight adjustment is used to maintain long-term forecast stability, thus overcoming the loss of key dynamic features often associated with traditional models. Furthermore, the model introduces a reconstruction loss as an auxiliary task. Through an encoder-decoder structure, the model is required to first accurately restore the original meteorological field, learning essential characteristics such as atmospheric conservation of energy and mass in the process, before performing the forecasting task.
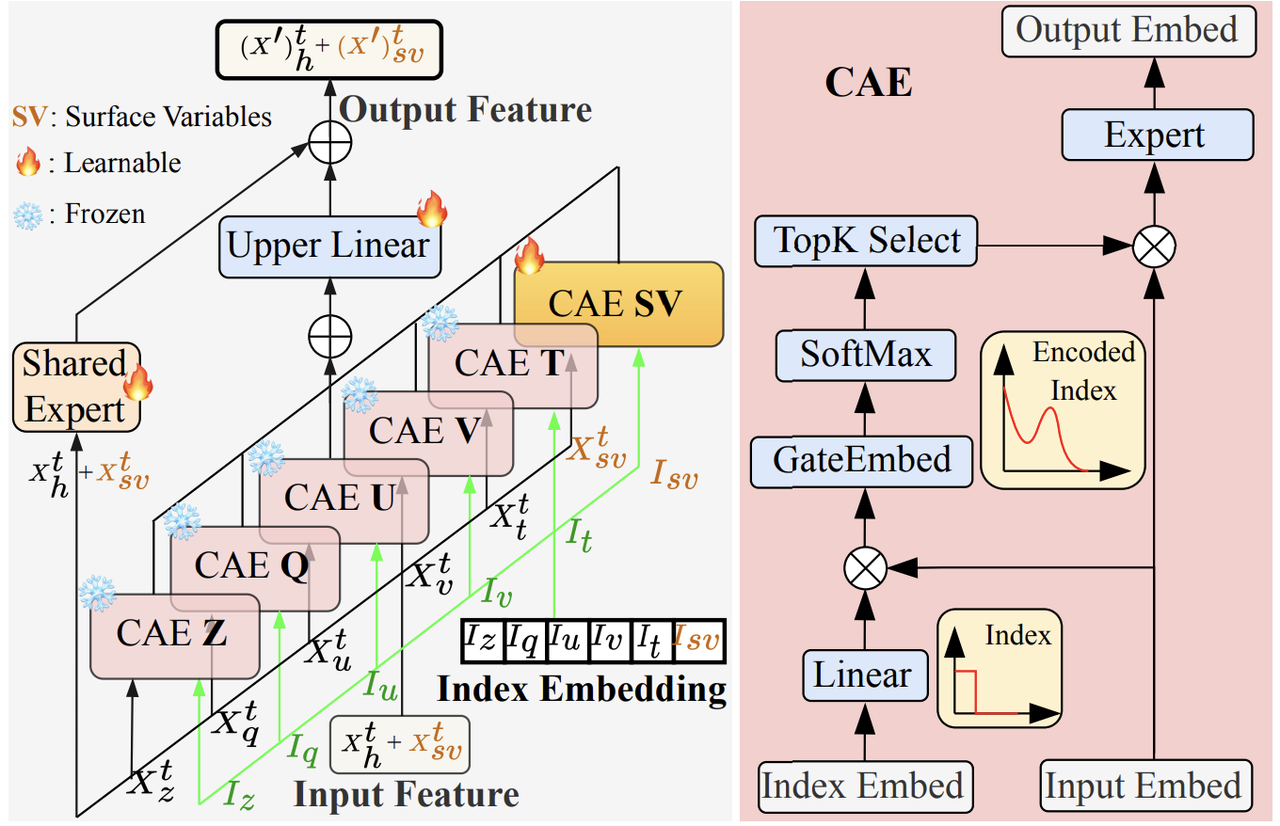
On this basis, as shown in the figure below,The model builds an expert system of "specialization + collaboration".For the five core variables in the training phase (such as Z500, temperature, and wind speed), independent "Channel-Adaptive Experts (CAEs)" are configured for each variable. For example, the temperature CAE focuses solely on the spatiotemporal evolution of temperature, combining the temperature's "identity tag" to screen key features (such as the diurnal temperature difference and sudden temperature changes during frontal passage), improving the accuracy of single-variable forecasts through specialized modeling. Furthermore, a "Shared Expert" module is set up to integrate the local information output by all CAEs and capture system-level correlations between multiple variables (such as the chain reaction of increased temperature → decreased air pressure → increased wind speed). This avoids "missing the forest for the trees" due to over-specialization and ensures that the model can restore the overall dynamic behavior of the atmospheric system.
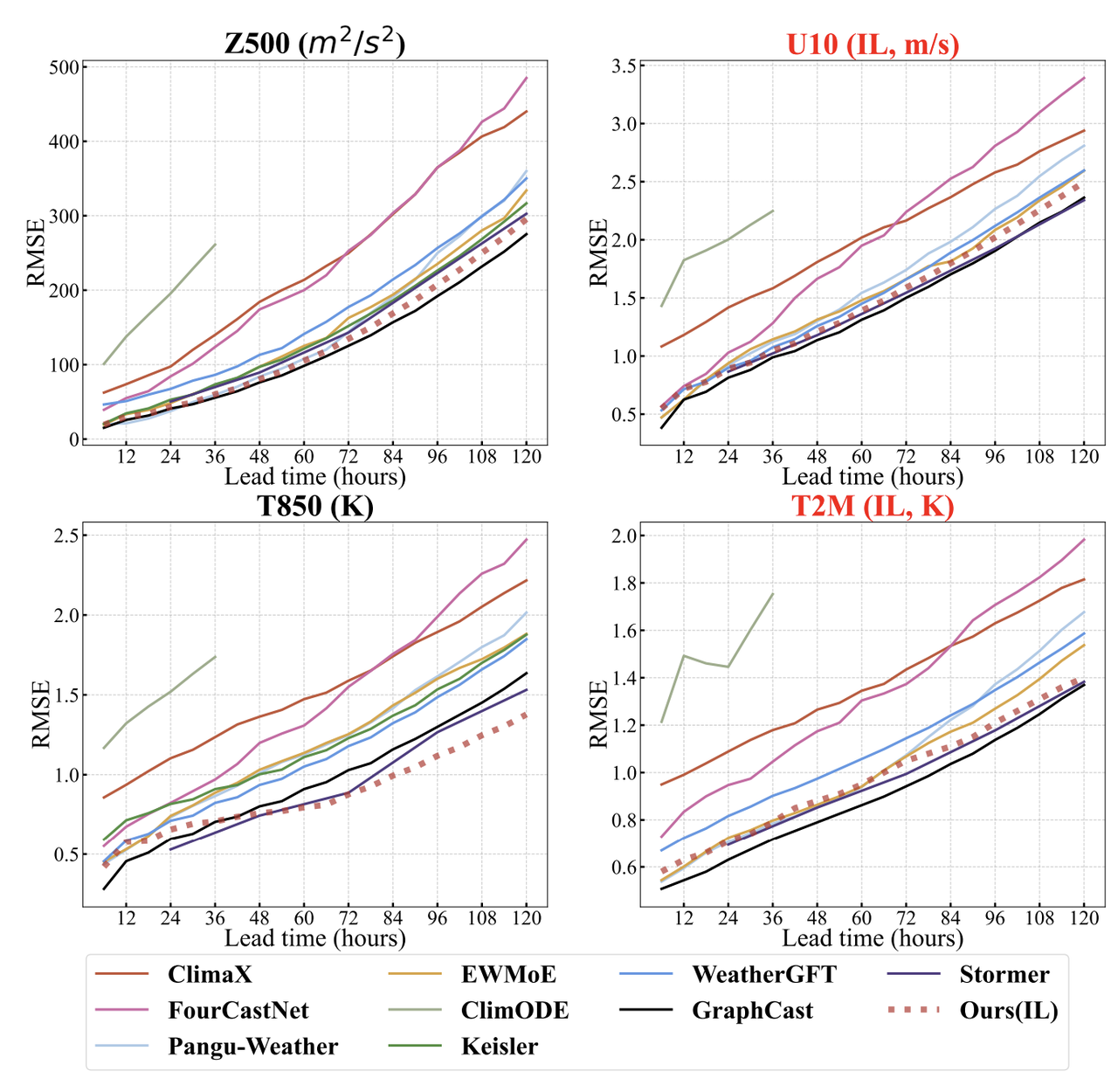
VA-MoE performance verification: Accuracy comparable to mainstream models, with significant incremental learning advantages
To systematically evaluate the actual effectiveness of VA-MoE in weather forecasting, the research team built a complete experimental system based on real meteorological data, focusing on the three dimensions of "accuracy, efficiency, and scalability."
The core of the experiment is to compare VA-MoE with nine current mainstream meteorological AI models (including Pangu-Weather, GraphCast, ClimaX, etc.), including 500hPa geopotential height Z500, 10-meter easterly wind speed U10, 850hPa temperature T850, 2-meter temperature T2M, etc., focusing on evaluating their forecast performance within 5 days. The key difference lies in the training logic: the compared models mostly use the traditional method of "one-time joint training of high-altitude and ground variables".VA-MoE adopts a two-stage incremental strategy of "high altitude first, then ground", highlighting its advantages in variable expansion.
In terms of forecast accuracy,As shown in the figure below, VA-MoE performs well in both surface and upper-air forecasting. For key surface variables such as T2M and U10, VA-MoE's forecast accuracy is comparable to Stormer and GraphCast, and significantly outperforms models like ClimaX and FourCastNet, maintaining stability across both short- and long-term forecasts. Expanding to variables like V10 and sea level pressure (MSL), VA-MoE's advantage becomes even more pronounced, falling slightly behind GraphCast only for T2M and on par with mainstream models like FengWu and FuXi.
In terms of training efficiency,VA-MoE, trained in incremental mode based on 40 years of data, can achieve similar accuracy with only half the standard number of iterations; even if the data is reduced to 20 years and the number of iterations is reduced to one-quarter, the model can still maintain business-usable accuracy, significantly reducing the computational cost caused by variable expansion.
The upper-air variable prediction further verifies the incremental advantage of VA-MoE.The study compared three training strategies: VA-MoE trained solely on upper-air variables, VA-MoE incrementally incorporating ground variables (IL), and a traditional joint training model. Results showed that VA-MoE trained solely on upper-air variables achieved accuracy comparable to GraphCast and outperformed IFS and Pangu-Weather. Furthermore, the incremental VA-MoE showed no degradation in its predictive performance for upper-air variables after incorporating ground variables, and even improved its accuracy in long-term forecasts of 500hPa geopotential height (Z500), demonstrating its ability to "learn new things without losing old ones."
To further validate the effectiveness of the model structure, the team conducted ablation experiments comparing VA-MoE with the Visual Transformer (ViT) and its expert-based extension (ViT+MoE). Although ViT+MoE has nearly twice the number of parameters as VA-MoE, VA-MoE still achieved significantly higher accuracy at the 6-hour, 3-day, and 5-day forecast intervals. This demonstrates the advantages of its "channel-adaptive expert" mechanism even in parameter-constrained scenarios, making it particularly well-suited for business environments with dynamically expanding variables.
AI drives innovation in weather forecasting, pushing the boundaries of traditional numerical models
In the direction of VA-MoE's focus on "efficiently adapting to multiple variables, reducing update costs, and improving forecast accuracy," the global academic and business communities are working together to continuously promote in-depth innovation in the meteorological modeling paradigm.
The academic community has made important breakthroughs in model architecture innovation and data utilization efficiency by focusing on core technology bottlenecks.Aardvark Weather, jointly developed by the University of Cambridge, the Alan Turing Institute, and Microsoft Research, is the first end-to-end AI system that is completely free from traditional numerical frameworks.It has achieved direct mapping from multi-source observation data to high-resolution forecasts, which not only significantly reduced the dependence on supercomputing resources, but also shortened the development cycle of special models from several months to several weeks, fully verifying the business feasibility of the pure data-driven path.
Paper Title:End-to-end data-driven weather prediction
Paper address:https://www.nature.com/articles/s41586-025-08897-0
The FuXi-Weather system was developed by Fudan University in collaboration with the Shanghai Institute of Science and Technology Intelligence, the China Meteorological Administration, and other institutions.It has pioneered the realization of complete end-to-end modeling from satellite brightness temperature to forecast results, breaking away from the dependence on the initial field of traditional numerical models. Even in sparsely observed areas such as Africa, its forecast accuracy still steadily surpasses the HRES system of the European Centre for Medium-Range Weather Forecasts.
Paper Title:A data-to-forecast machine learning system for global weather
Paper address:https://www.nature.com/articles/s41467-025-62024-1
The business community focuses on technology implementation and scenario adaptation, demonstrating outstanding engineering capabilities.GraphCast launched by Google DeepMind is based on the advanced graph neural network architecture.After training with ERA5 reanalysis data, it can complete global weather forecasts for the next 10 days within 1 minute. Its indicator accuracy exceeds 90% among 1,380 test variables, which is better than that of the HRES system. It can also effectively identify extreme weather signals such as cyclones and atmospheric rivers 3 days in advance. Its open source strategy further promotes the popularization of technology.
Paper Title:UT-GraphCast Hindcast Dataset: A Global AI Forecast Archive from UT Austin for Weather and Climate Applications
Paper address:https://arxiv.org/abs/2506.17453
The Aurora large model developed by Microsoft adopts a two-stage strategy of "pre-training-fine-tuning".With a flexible architecture of 1.3 billion parameters, it achieves a comprehensive accuracy of 89% in multiple tasks such as weather, air quality and wave forecasting. The computing speed is 5,000 times faster than traditional numerical models, and it can be quickly adapted to various business scenarios through light fine-tuning.
Paper Title:A foundation model for the Earth system
Paper address:https://www.nature.com/articles/s41586-025-09005-y
Looking ahead, with the continuous enrichment of multi-source observation data and the continuous evolution of basic models, meteorological AI is expected to play a greater role in extreme weather warning, climate change assessment, and professional industry services, gradually transforming its role from "auxiliary forecasting" to "driving decision-making", and providing more intelligent technical support for human society to cope with weather and climate challenges.








