Command Palette
Search for a command to run...
Lyft Releases Largest L5 Autonomous Driving Prediction Dataset and Launches Motion Prediction Competition
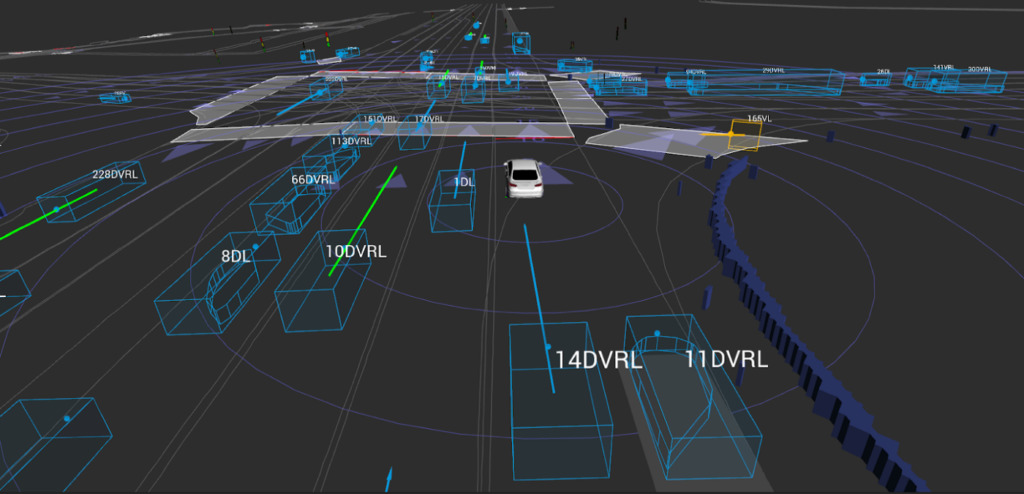
Lyft recently released a Level 5 autonomous driving prediction dataset, which contains more than 1,000 hours of driving records. In addition, the company also launched an autonomous driving motion prediction challenge with a prize pool of US$30,000.
Lyft has released a new dataset.
Last July, Lyft released an L5 autonomous driving perception dataset, which contains more than 55,000 3D annotated frames marked by humans. At that time, it was officially called the largest public dataset of its kind.
Just one year later, Lyft released a set of L5 autonomous driving prediction data sets.

Application download address: https://www.catalyzex.com/paper/arxiv:2006.14480/dataset
170,000 scenes and more than 2,500 kilometers of road data
The dataset released by Lyft this time focuses on motion prediction.Officials said a long-standing research problem in the field of autonomous driving is to create models that are robust and reliable enough to predict traffic movements.
The data was collected over a four-month period by a fleet of 23 autonomous vehicles on a fixed route in Palo Alto, California.Contains driving logs of cars, pedestrians, and other obstacles encountered.
The dataset specifically includes:
- 1000 hours:More than 1,000 hours of autonomous vehicle movement records;
- 170,000 scenes:Each scene lasts about 25 seconds and includes traffic lights, aerial maps, sidewalks, etc.;
- 16,000 miles: 16,000 miles (2,575 kilometers) of data from public roads;
- 15242 annotated images:Includes a high-definition semantic map of the labeled elements and a high-definition bird's-eye view of the area.

This motion data is collected by a sensor array mounted on the roof of Lyft vehicles, which captures lidar, camera, and radar data as the vehicles travel tens of thousands of miles.
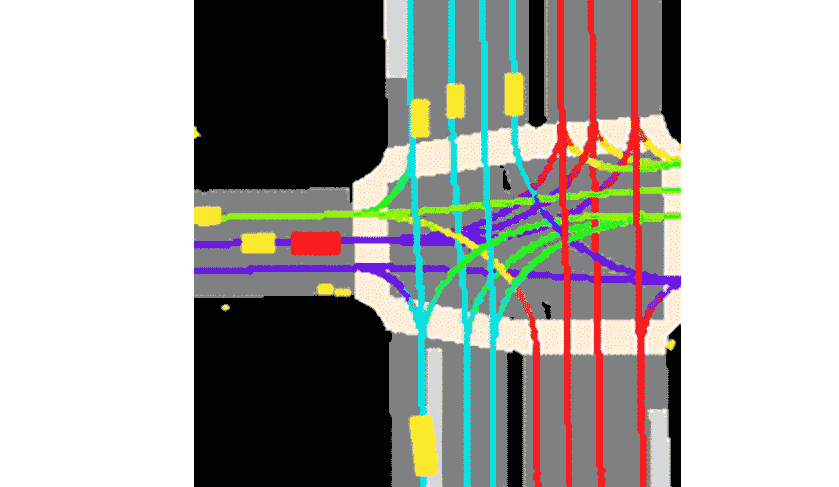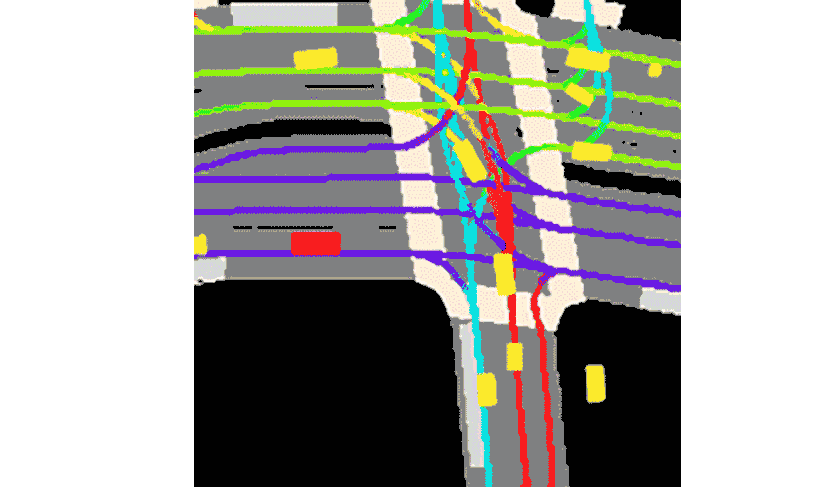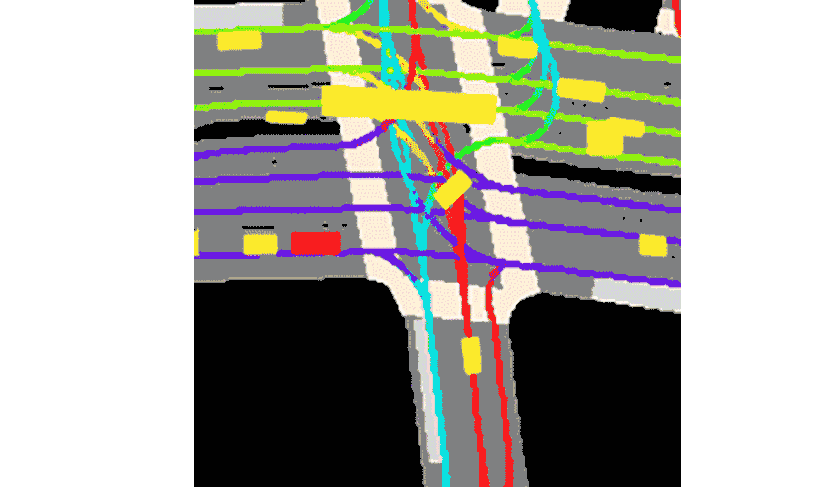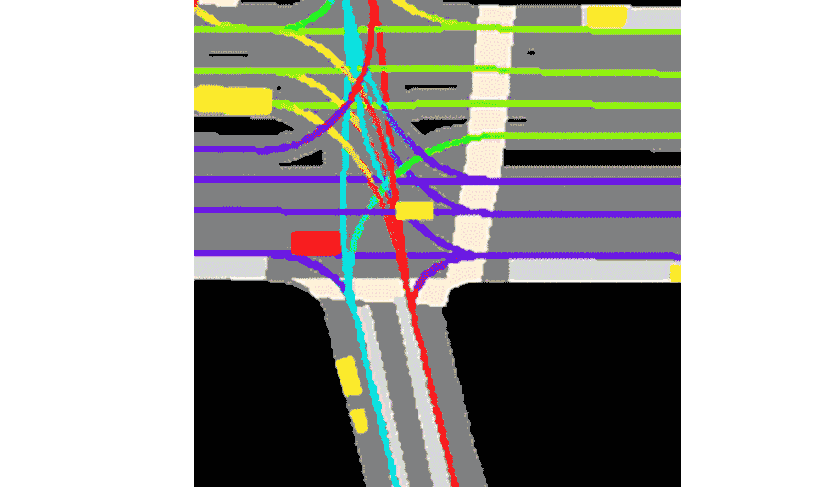
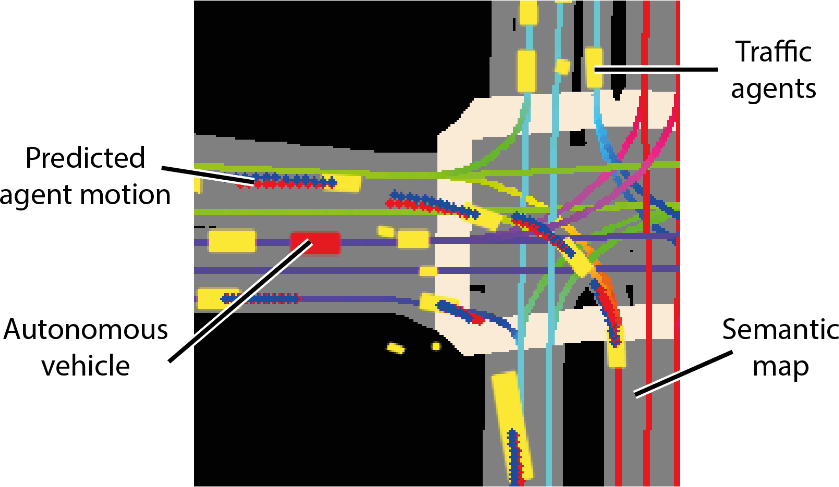
Lyft said the collection comes with the toolkit provided.This constitutes the largest, most complete and most detailed data set to date.Used for developing autonomous driving, machine learning tasks such as motion prediction, planning, and simulation.
Currently, only some subsets of the dataset are available for download, including:
- Sample Dataset (53 MB)
- Training dataset (divided into three parts, totaling 69.4 GB)
- Bird's Eye View (2 GB)
- Semantic Graph (2 MB)
Download address:
Launch a challenge with a prize pool of 30,000 US dollars
at the same time,Lyft also plans to launch a challenge that will begin in August on the Google Kaggle platform and award a total of $30,000 in prizes.

The highlights of this challenge:
- Competition requirements:Contestants predict the movement of vehicles;
- Preparation:Official reminder: researchers and engineers can download the training dataset and Python-based software packages from now on to experiment with the data, as the test and validation suites will be released as part of the competition;
- Ultimate goal:Empowering the research community and accelerating innovation through datasets and competitions.
Lyft senior director of engineering Sacha Arnoud and director of audio and video research Peter Ondruska wrote in a blog post:“Data is the driving force behind trying the latest machine learning techniques.Access to large-scale, high-quality autonomous driving data is limited, but this should not prevent us from experimenting with this research.”
“We believe that autonomous vehicles will become a more convenient, safer and sustainable part of the transportation system,” Arnoud and Ondruska said.“By sharing data with the research community, we hope to identify important and unsolved challenges in autonomous driving."
ClickRead the original article, you can get more high-quality data sets!
Blog address:
Paper address:
https://arxiv.org/pdf/2006.14480.pdf
GitHub address:
https://github.com/lyft/l5kit/
-- over--








