Command Palette
Search for a command to run...
NeuTTS-Air: Ein Leichtes Und Effizientes Modell Zum Klonen Von Stimmen
1. Einführung in das Tutorial

NeuTTS-Air ist ein End-to-End-Sprachsynthesemodell (TTS), das im Oktober 2025 von Neuphonic veröffentlicht wurde. Basierend auf dem 0,5B Qwen LLM-Backbone und dem NeuCodec-Audiocodec zeigt es Few-Shot-Learning-Fähigkeiten bei der On-Device-Bereitstellung und sofortigem Voice-Cloning. Die Systembewertung zeigt, dass NeuTTS Air das SOTA-Niveau unter den Open-Source-Modellen erreicht hat, insbesondere bei Benchmarks für ultrarealistische Synthese und Echtzeit-Inferenz. Es lässt sich auch auf neue Szenarien wie eingebettete Agenten und Stilübertragung generalisieren, unterstützt 3-Sekunden-Audio-Cloning und generiert natürliche Gesprächsinhalte. Nach dem Training werden GGML/ONNX-Unterstützung und ein Wasserzeichenmechanismus eingeführt, was im Open-Source-Bereich bei der On-Device-TTS- und Leistungsoptimierungsbewertung führend ist und in einigen Szenarien mit Closed-Source-Modellen vergleichbar ist.
Dieses Tutorial verwendet eine einzelne RTX 5090-Karte als Ressource und das Modell unterstützt nur Englisch.
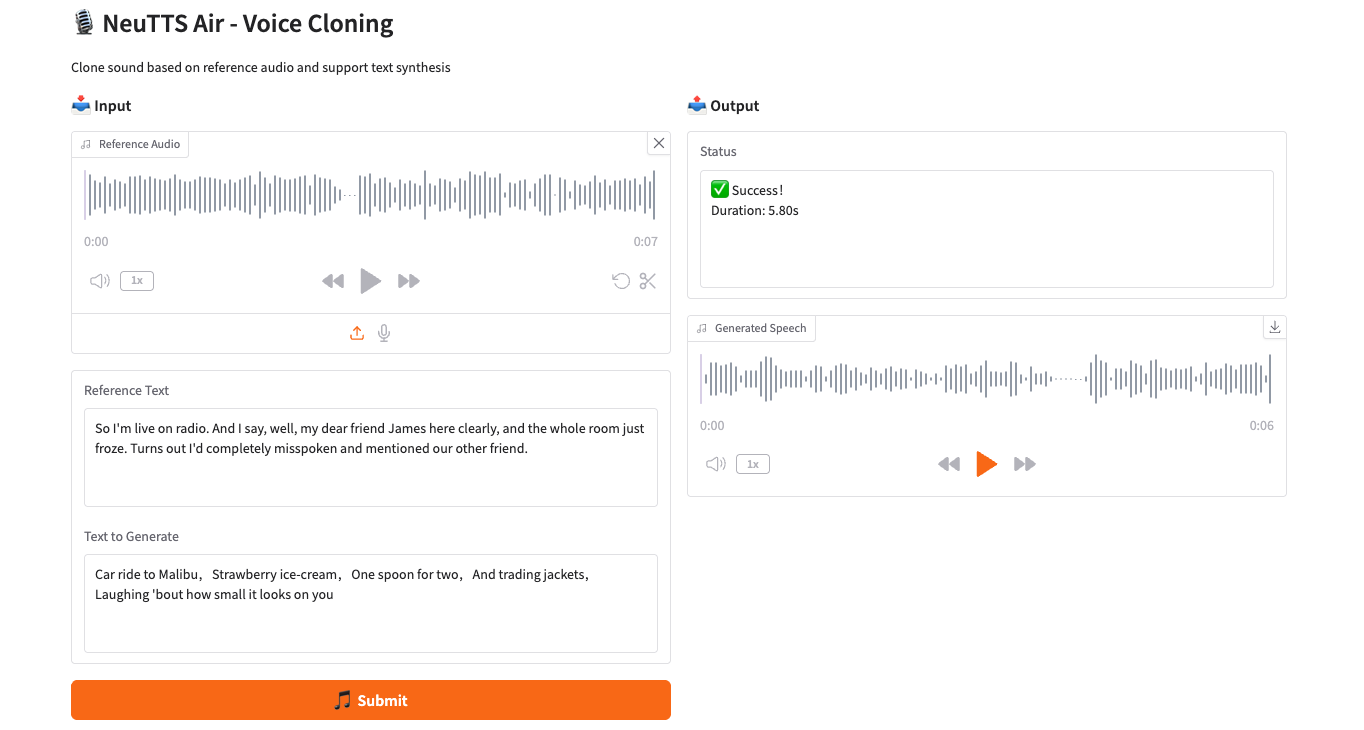
2. Projektbeispiele
3. Bedienungsschritte
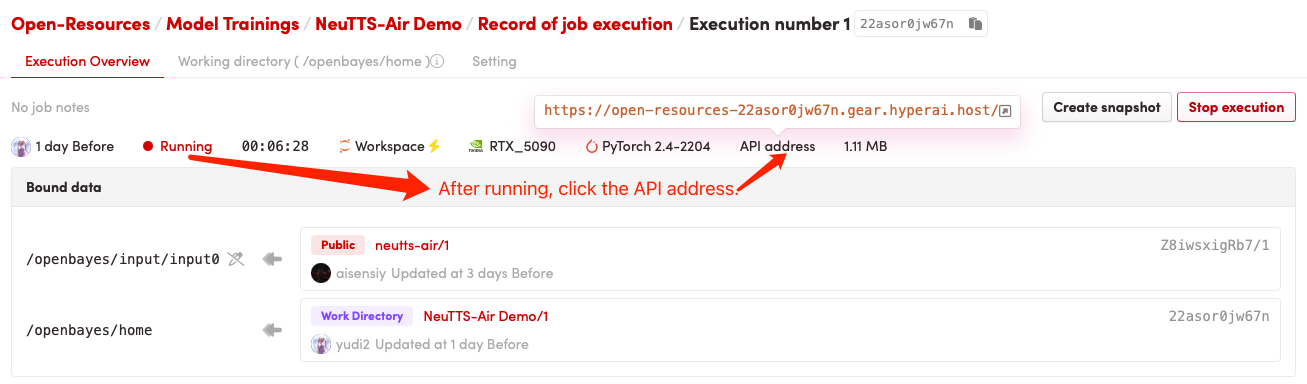
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
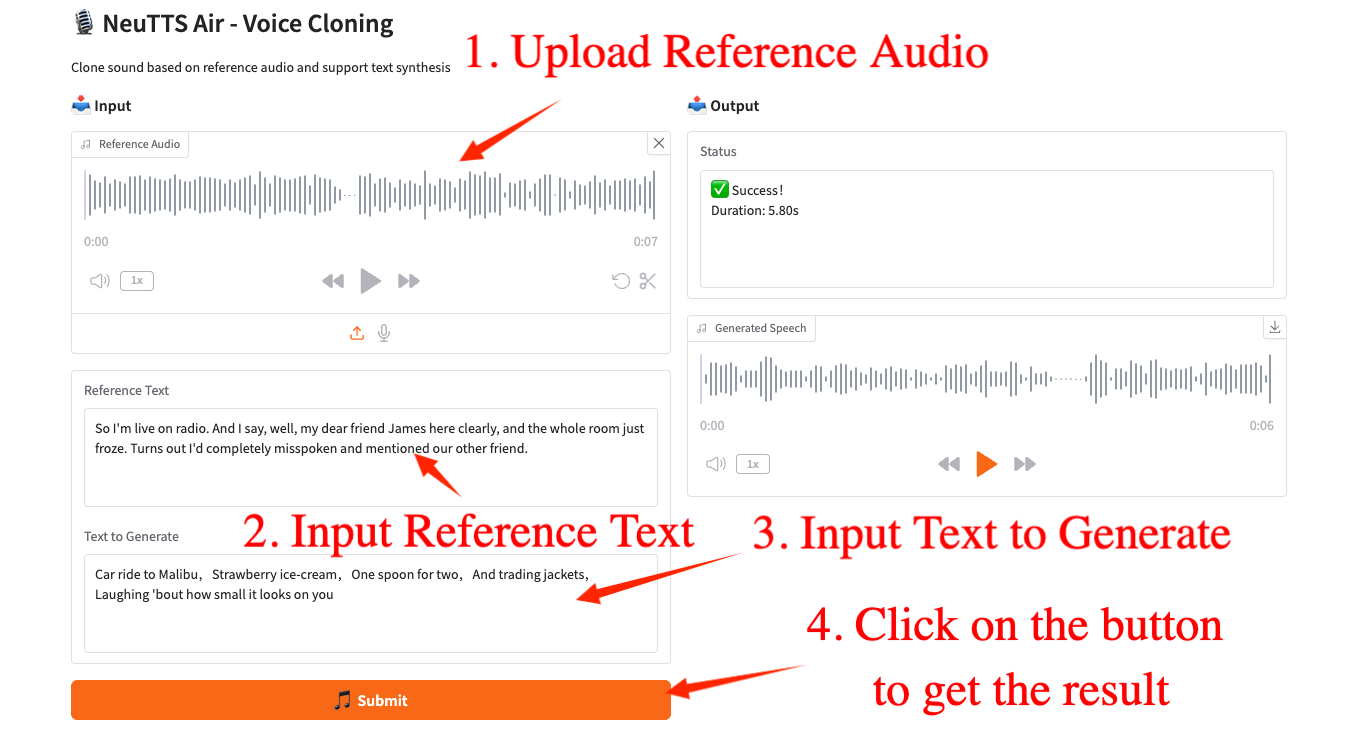
2. Sobald Sie die Webseite betreten, können Sie das Modell verwenden
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass der Code im Hintergrund ausgeführt wird. Bitte warten Sie etwa 2-3 Minuten und aktualisieren Sie die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Anwendung
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.