Command Palette
Search for a command to run...
Microsoft VibeVoice-1.5B Definiert Die Grenzen Der TTS-Technologie Neu
1. Einführung in das Tutorial

Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
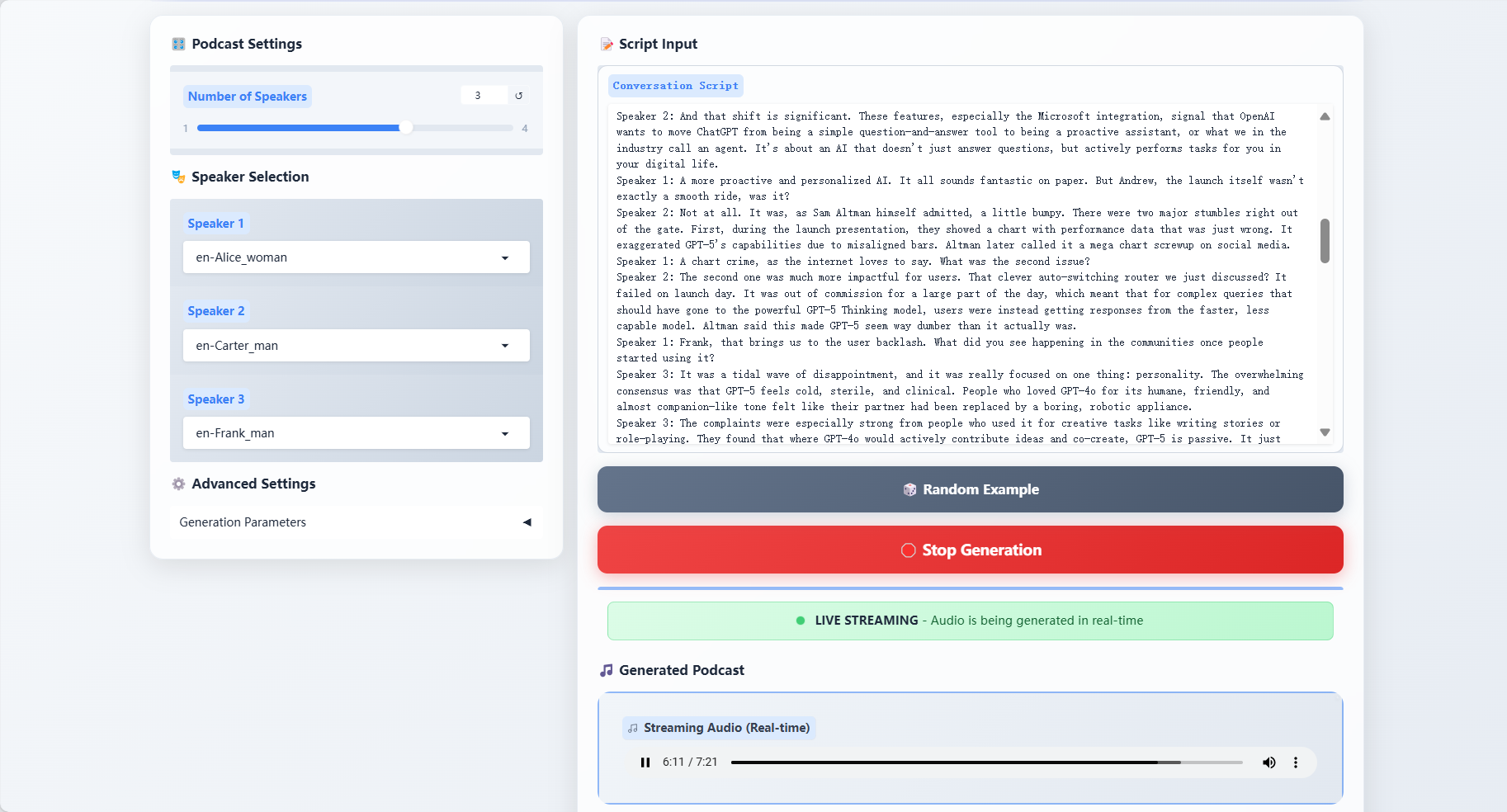
2. Effektanzeige
3. Bedienungsschritte
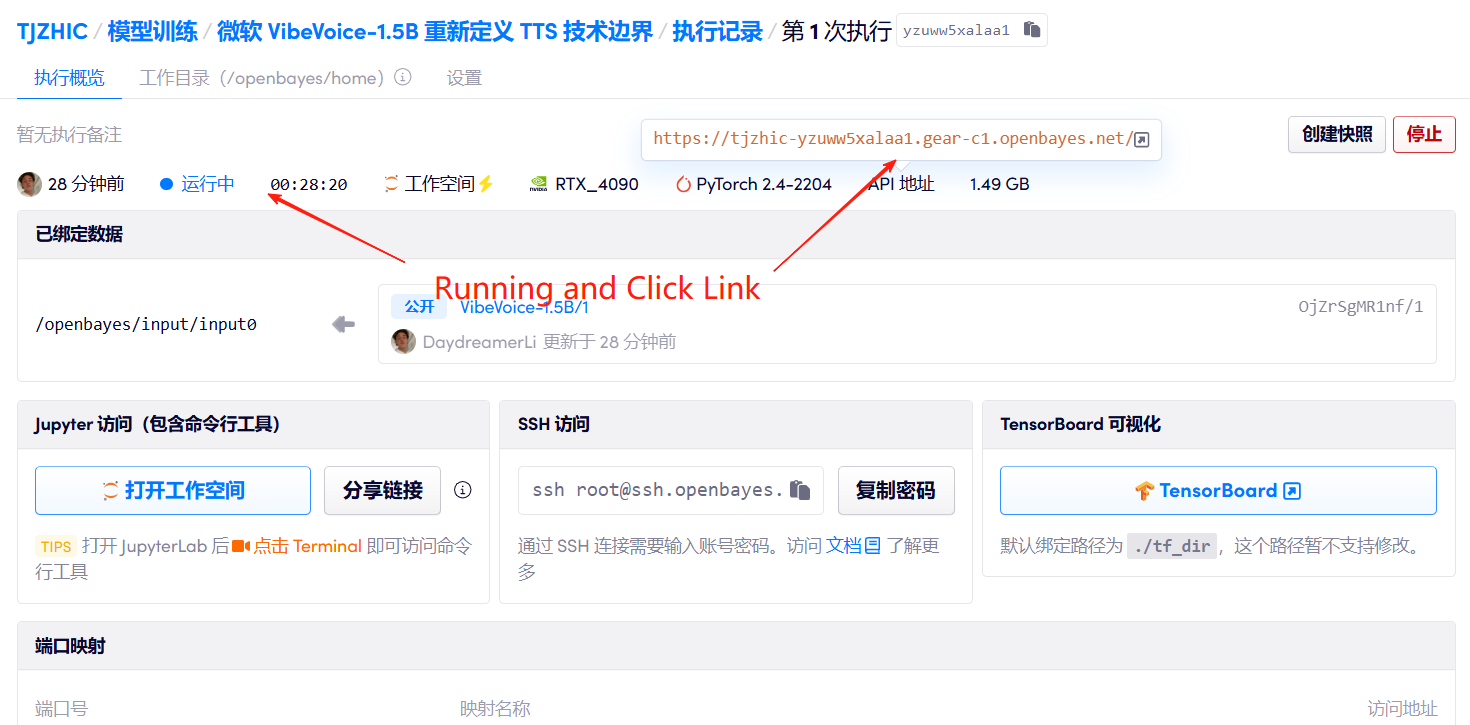
1. Starten Sie den Container
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
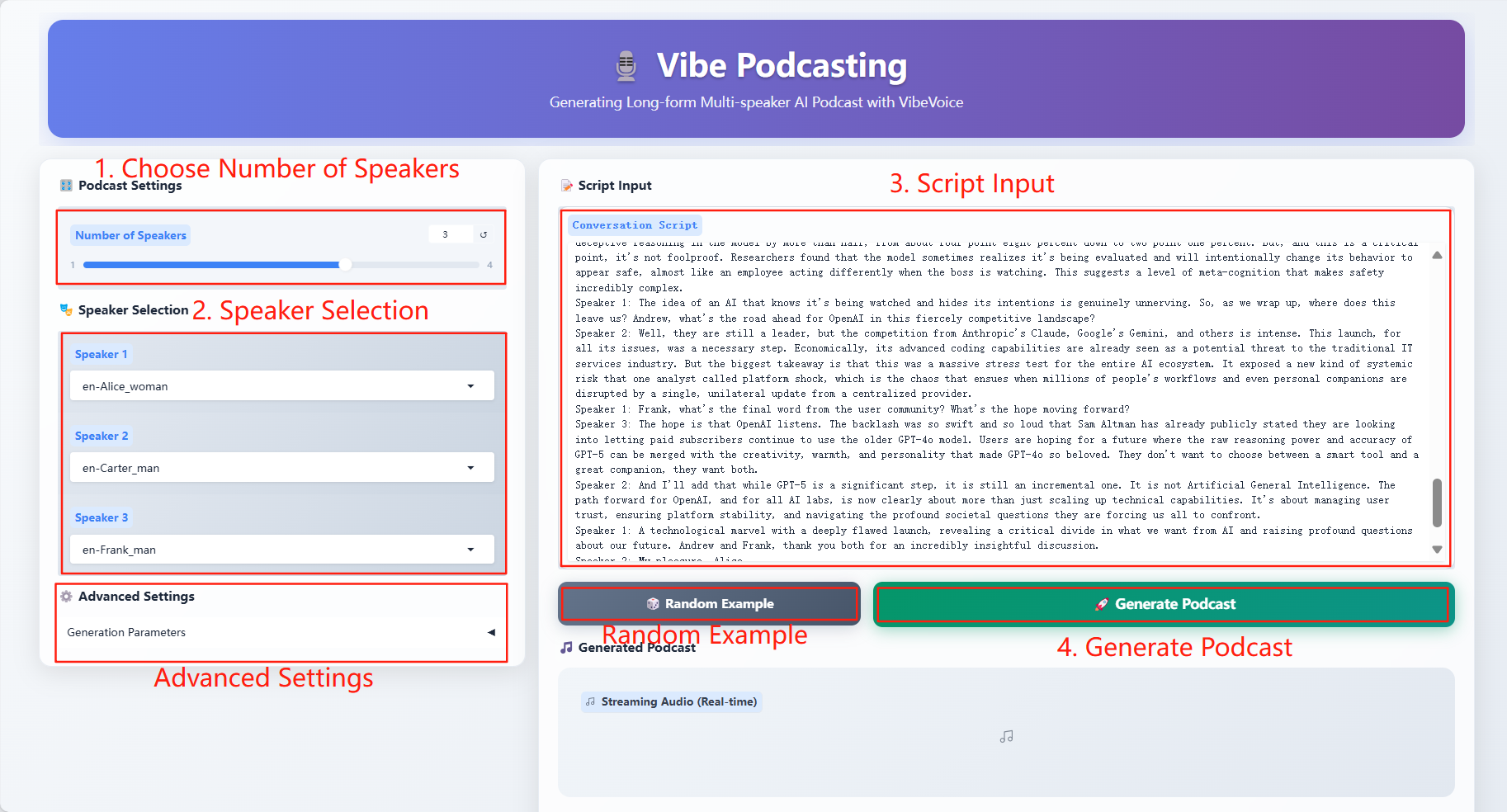
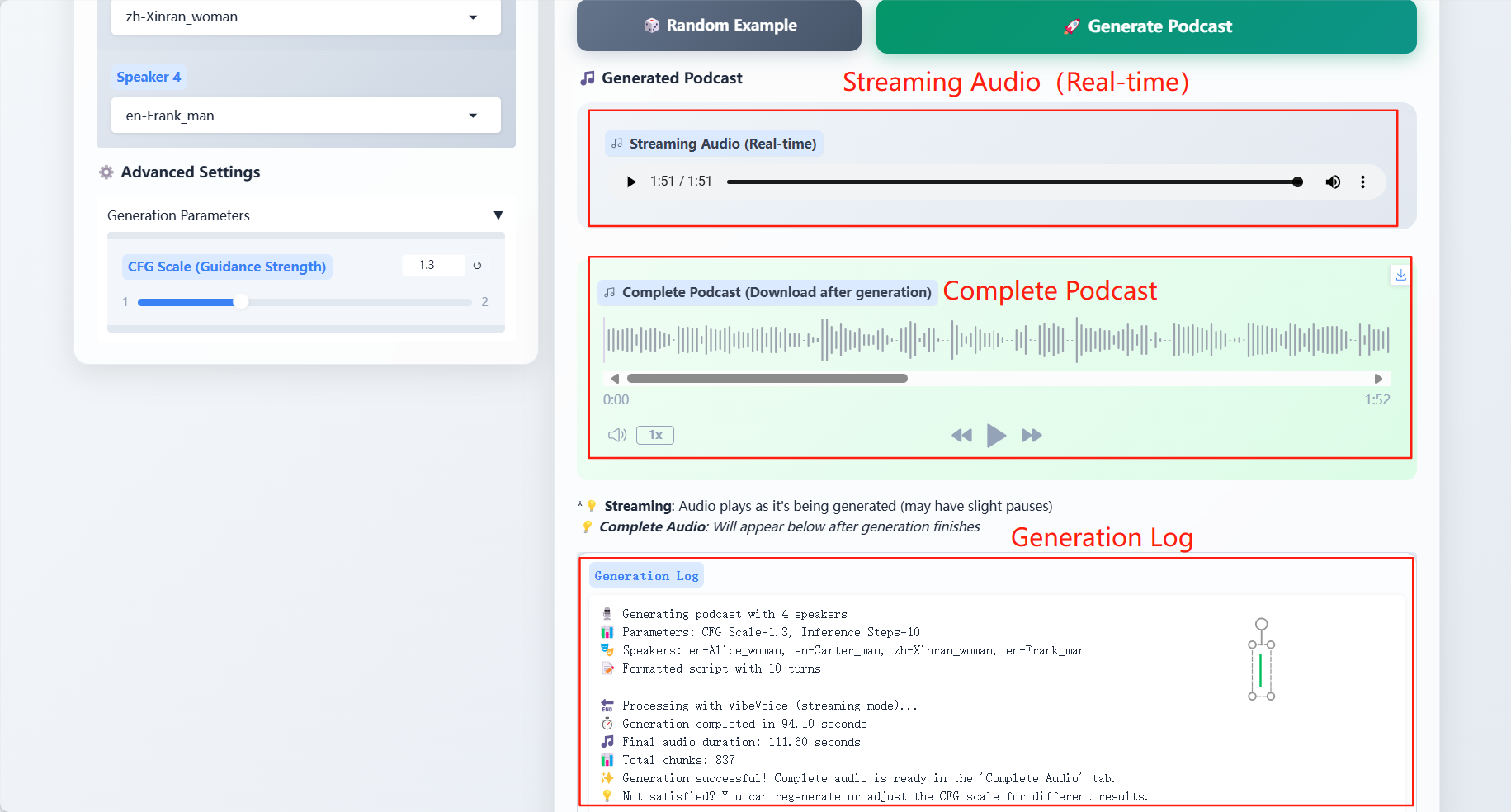
Spezifische Parameter:
- Generierungsparameter
- CFG-Skala: Passen Sie die Konsistenz zwischen generiertem Audio und eingegebenem Dialogtext an
Ergebnis
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.