Command Palette
Search for a command to run...
Beschreiben Sie Alles Modelldemo
Datum
Größe
776.37 MB
Lizenz
Apache 2.0
GitHub
Paper-URL
Projektübersicht

Das Describe Anything Model (DAM) ist ein innovatives Bild- und Videobeschreibungsmodell, das von Teams von NVIDIA, UC Berkeley und UCSF gemeinsam entwickelt und 2025 veröffentlicht wurde. Dieses Modell generiert detaillierte Beschreibungen auf Basis von benutzerdefinierten Bereichen (Punkte, Kästchen, Kritzeleien oder Masken). Bei Videoinhalten lässt sich eine vollständige Beschreibung durch einfaches Annotieren von Bereichen in beliebigen Frames erzielen. Zugehörige Forschungsarbeiten sind verfügbar. Beschreiben Sie alles: Detaillierte lokalisierte Bild- und Videountertitel .
Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte.
Projektbeispiele
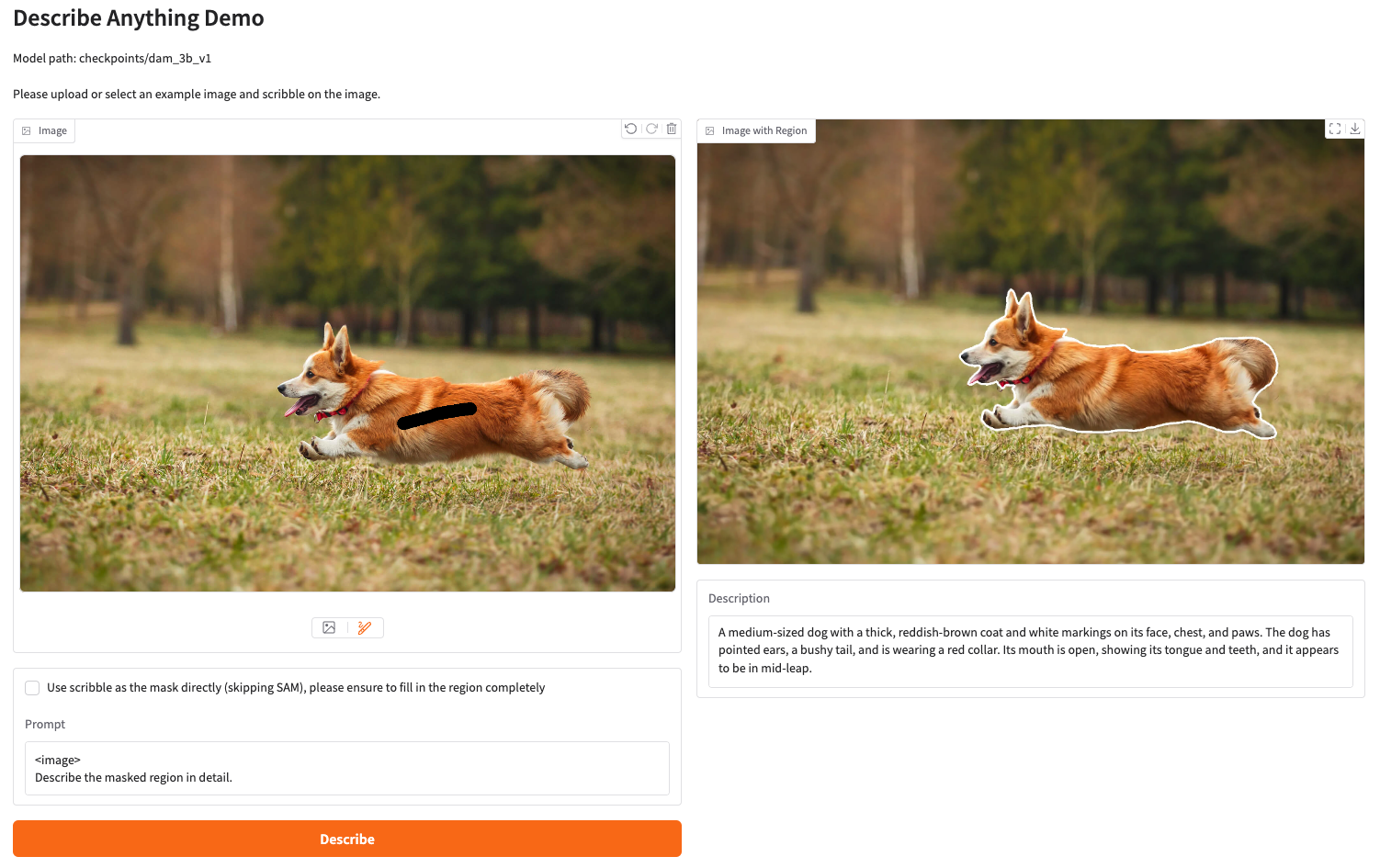
Schritte ausführen
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
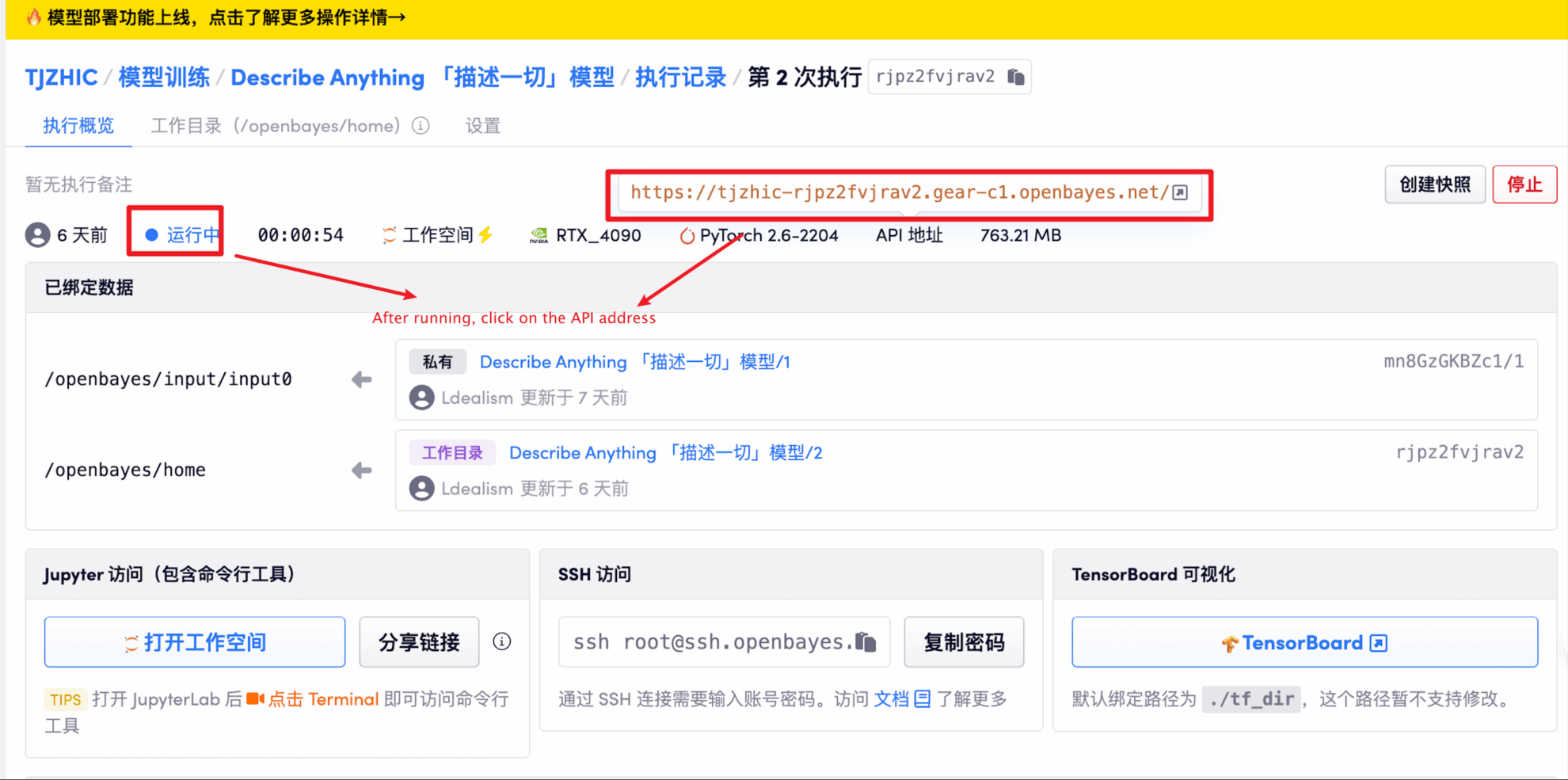
2. Sobald Sie die Webseite betreten, können Sie mit dem Modell interagieren
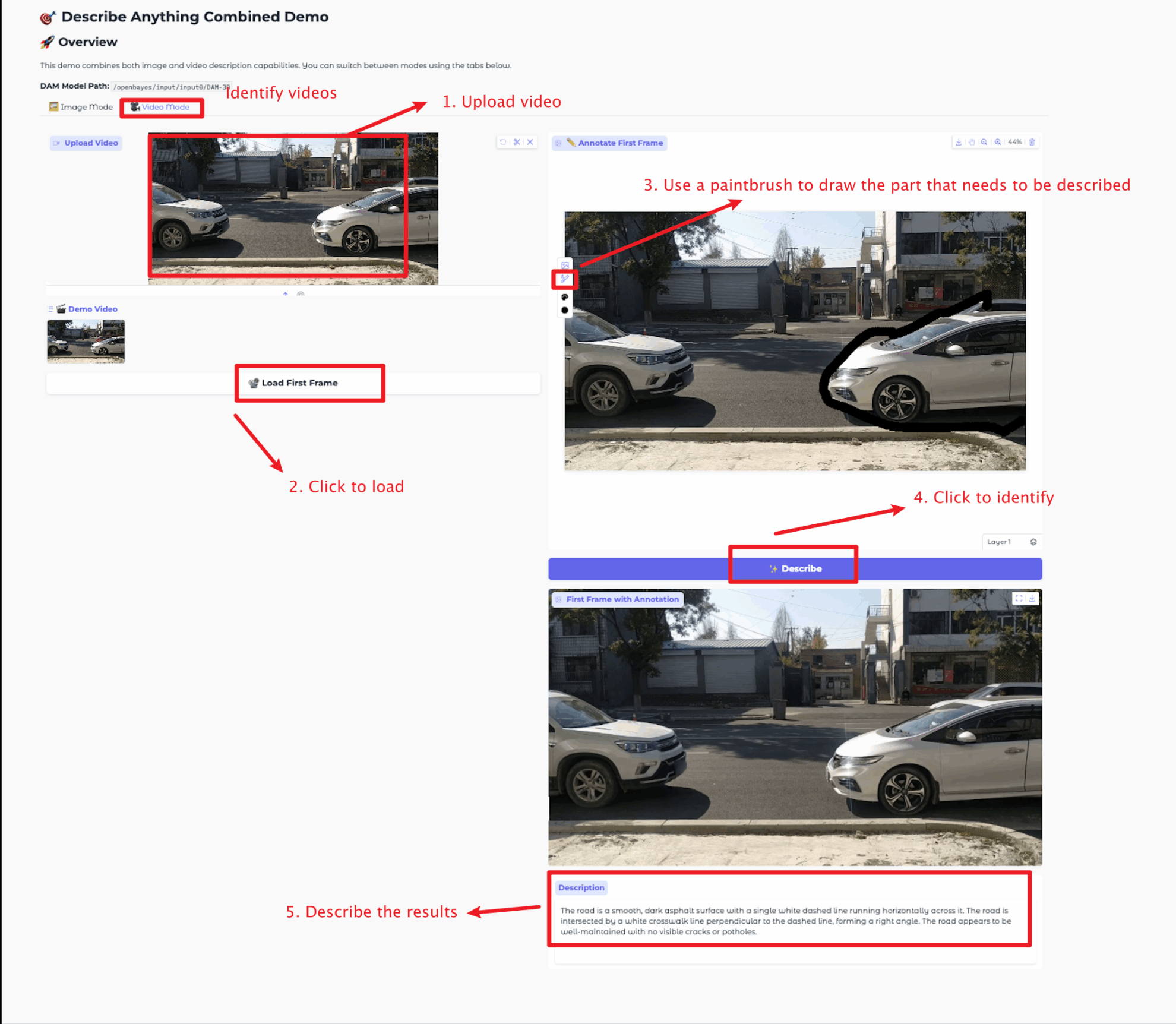
Die Bildgröße sollte 5 MB nicht überschreiten, die Videolänge 20 Sekunden und die Videogröße 5 MB nicht überschreiten. Andernfalls kann es zu einer Verlangsamung des Modells oder einer Fehlermeldung kommen. Bitte wählen Sie den Bereich für die Beschreibung mit Bedacht aus.
Dieses Tutorial bietet zwei Modultests: Bildmodus- und Videomodusmodule.
Die Funktionen der einzelnen Module sind wie folgt:
Bildmodus
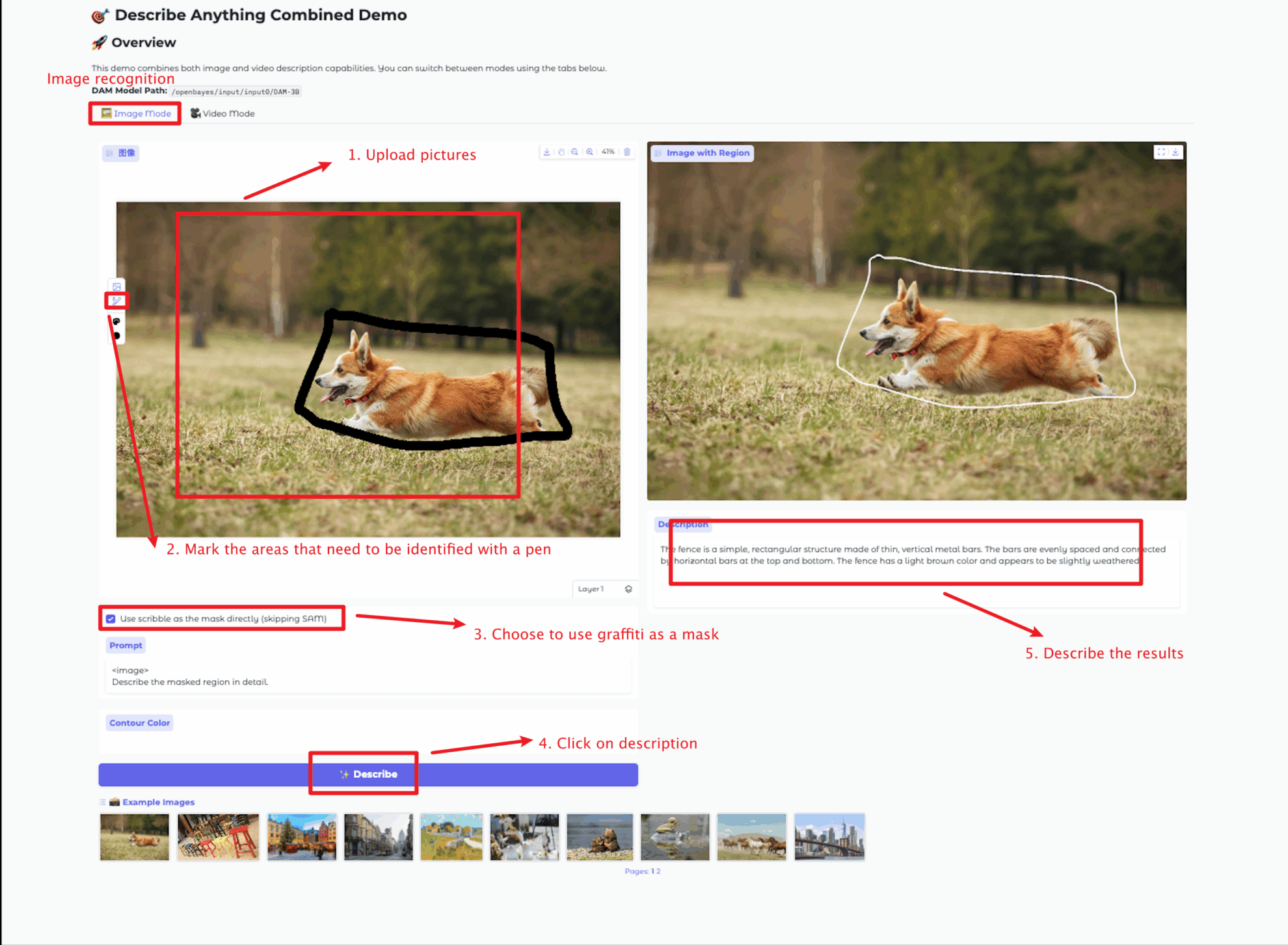
Videomodus
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Dank an den Github-Benutzer zhangjunchang Für die Bereitstellung dieses Lernprogramms lauten die Projektreferenzinformationen wie folgt:
@article{lian2025describe,
title={Describe Anything: Detailed Localized Image and Video Captioning},
author={Long Lian and Yifan Ding and Yunhao Ge and Sifei Liu and Hanzi Mao and Boyi Li and Marco Pavone and Ming-Yu Liu and Trevor Darrell and Adam Yala and Yin Cui},
journal={arXiv preprint arXiv:2504.16072},
year={2025}
} GitHub Stars arXiv KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.